
OxyEcomBench: Benchmarking Multimodal Foundation Models across E-Commerce Ecosystems
Source: arXiv:2605.13173 · Published 2026-05-13 · By Yong Liu, Ximan Liu, Guoqing Yang, Bing Bai, Xiaoqiang Xu, Zhen Chen et al.
TL;DR
OxyEcomBench addresses a critical gap in evaluating large language models (LLMs) and multimodal large language models (MLLMs) for e-commerce applications by introducing the first unified benchmark that comprehensively covers the entire e-commerce ecosystem. E-commerce workflows are complex due to multi-stakeholder roles (platform operators, merchants, customers), heterogeneous multimodal data (text, single/multi-image), and intricate domain knowledge including long-tail product details and platform-specific policies. Existing benchmarks were fragmented—focusing on single roles, text-only tasks, or isolated challenges. OxyEcomBench unifies 29 tasks across 6 capability aspects with about 6,300 bilingual (Chinese-English) instances, deliberately emphasizing visually salient multimodal cases and multi-turn interactions, all sourced from real platforms and rigorously verified by domain experts. A 4-level difficulty rubric ranging from surface-level extraction to expert-level judgment further adds nuance.
Benchmarking 20 state-of-the-art LLMs and MLLMs on OxyEcomBench reveals that even leading foundation models achieve modest overall accuracy (best at 69.1%), with performance compressed into a narrow range despite large architecture and training differences. This suggests that general open-domain knowledge and multimodal ability do not straightforwardly translate into real e-commerce proficiency without specialized domain knowledge infusion and fine-grained visual-text alignment. The benchmark reveals fragmented model strengths across different capability aspects and highlights common failure modes such as subtle visual discrepancies, multi-turn context confusion, and hallucinated or contradictory responses. OxyEcomBench thus provides a critical diagnostic tool to chart progress toward models that can handle the full complexity of real-world e-commerce pipelines.
Key findings
- OxyEcomBench consists of approximately 6,300 bilingual Chinese-English instances spanning 29 tasks and 6 capability aspects across platform operators, merchants, and customers.
- The benchmark enforces a four-level difficulty rubric (P0–P3) based on expert consensus to differentiate task complexity, including multi-turn dialogue and expert-level decision making.
- In evaluation of 20 mainstream LLMs and MLLMs, the top overall accuracy peaks at only 69.1% (Gemini 3 Pro), indicating a low ceiling despite strong general-purpose capabilities.
- Performance rankings compress across models with widely varying scale and architecture, highlighting that scaling alone offers modest gains compared to the gap from domain-specific knowledge infusion.
- No single model achieves top performance across all six capability aspects; strengths are fragmented by model family and role perspective.
- Visually salient tasks, such as MGC-to-Product Consistency Verification, have very low average accuracy (~20.8%), exposing critical failure in fine-grained visual-text alignment.
- Complex multi-turn reasoning tasks (e.g., E-Commerce Knowledge Q&A Multi-turn) score low (~23.3%), revealing context confusion and hallucination of product features.
- Text-only LLMs score well on text-only tasks like Compliance & Quality Control but are unable to handle multimodal challenges effectively.
Threat model
Not a security-focused paper; the adversarial context is implicit in testing model robustness to complex, multimodal e-commerce data rather than explicit malicious attackers. The 'adversary' here can be seen as the model's failure modes—hallucination, inability to integrate visual and textual evidence, or poor multi-turn reasoning—under realistic e-commerce domain challenges.
Methodology — deep read
Threat Model & Assumptions: The benchmark assumes a realistic e-commerce setting with three adversarial roles absent—platform operators, merchants, and customers—interacting through text and images. The adversary here is not explicitly defined as a malicious attacker but the models themselves, tested for robustness and ability to reason across multimodal e-commerce tasks involving complex domain knowledge and long-tail products. The models are assumed zero-shot without fine-tuning on this benchmark.
Data: OxyEcomBench curates ~6,300 high-quality bilingual (Chinese-English) instances drawn from authentic e-commerce platforms across scenarios such as advertising, transactions, search, recommendations, and compliance. Data modalities include text-only inputs, single-image, and multi-image product listings, multi-turn dialogues, and policy documents. All data is anonymized and manually verified by e-commerce domain experts. Tasks span 29 distinct real-world challenges organized into 6 capability aspects and 3 stakeholder roles.
Architecture/Algorithm: No new model architecture is proposed; instead, the benchmark evaluates existing 20 diverse LLMs and MLLMs, including proprietary and open-source models such as Gemini 3 Pro, GPT-5.2, Qwen3.5 series, and Llama3 variants. Models differ in parameter scale, multimodal capabilities, and training data. Input formats cover single-turn and multi-turn dialogue, multiple-choice, true/false, and open-ended Q&A tasks, with a designed prompt style for zero-shot evaluation.
Training Regime: The paper does not perform additional training but evaluates zero-shot model performance. Models are accessed via official APIs or local endpoints; hyperparameters for evaluation prompts are manually designed but not detailed. This is a pure benchmarking study without fine-tuning or domain adaptation.
Evaluation Protocol: Task-specific metrics include accuracy for objective tasks and an external LLM-as-judge scoring protocol for open-ended Q&A under strict grading rubrics. Aggregate scores are macro averaged by capability aspect and overall. Difficult tasks with multi-modal emphasis prevent text-only shortcuts to ensure models integrate visual evidence properly. The benchmark supports analysis by stakeholder role and task difficulty tiers. Statistical testing is not explicitly mentioned.
Reproducibility: The benchmark taxonomy, dataset statistics, evaluation protocols, and model list are detailed. It is unclear if code or data has been publicly released. Models are tested via API or local endpoints, and zero-shot prompts are publicly described. Nonetheless, lack of explicit code release limits full reproducibility.
Example: For the visually salient task of MGC-to-Product Consistency Verification, models receive multi-image plus text inputs showing merchant-generated content versus product listings. Models must detect subtle color or accessory mismatches that invalidate consistency claims. Evaluation records whether the model correctly classifies the pairs as consistent or inconsistent. Despite strong architectures, accuracy averages only about 20.8%, highlighting difficulty in cross-modal fine-grained alignment.
Technical innovations
- Creation of the first unified multimodal e-commerce benchmark covering three stakeholder roles, six capability aspects, and 29 diverse tasks integrating text, single-/multi-image inputs, and multi-turn dialogues.
- Introduction of a four-level expert-reviewed difficulty rubric (P0-P3) that quantifies task complexity by cognitive load, information integration, and domain knowledge depth across diverse task types.
- Explicit prioritization of visually salient multimodal cases where successful prediction requires fine-grained visual-textual reasoning, preventing text-only shortcutting common in multimodal benchmarks.
- Incorporation of bilingual Chinese-English data sourced from authentic real-world e-commerce platforms, ensuring ecological validity and domain specificity lacking in prior general or text-only e-commerce benchmarks.
Datasets
- OxyEcomBench — ~6,300 bilingual Chinese-English instances — sourced from authentic large-scale e-commerce platforms, manually verified by domain experts
Baselines vs proposed
- Gemini 3 Pro: Overall accuracy = 69.1% vs GPT-5.2 overall accuracy = 65.3%
- Qwen3.5-397B-A17B: Overall accuracy = 68.0% vs Kimi 2.5 overall accuracy = 67.9%
- Text-only LLM GLM-5.0: Compliance & Quality Control accuracy = 99.0% vs Gemini 3 Pro VLM score = 74.5% (not directly comparable given modality differences)
- MGC-to-Product Consistency Verification: Average accuracy across models around 20.8%, highlighting multimodal reasoning failure
- Purchase Intention Prediction (Text): Lowest task accuracy at 3.1% on average
- Highlights Understanding task achieves the highest average accuracy at 99.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13173.
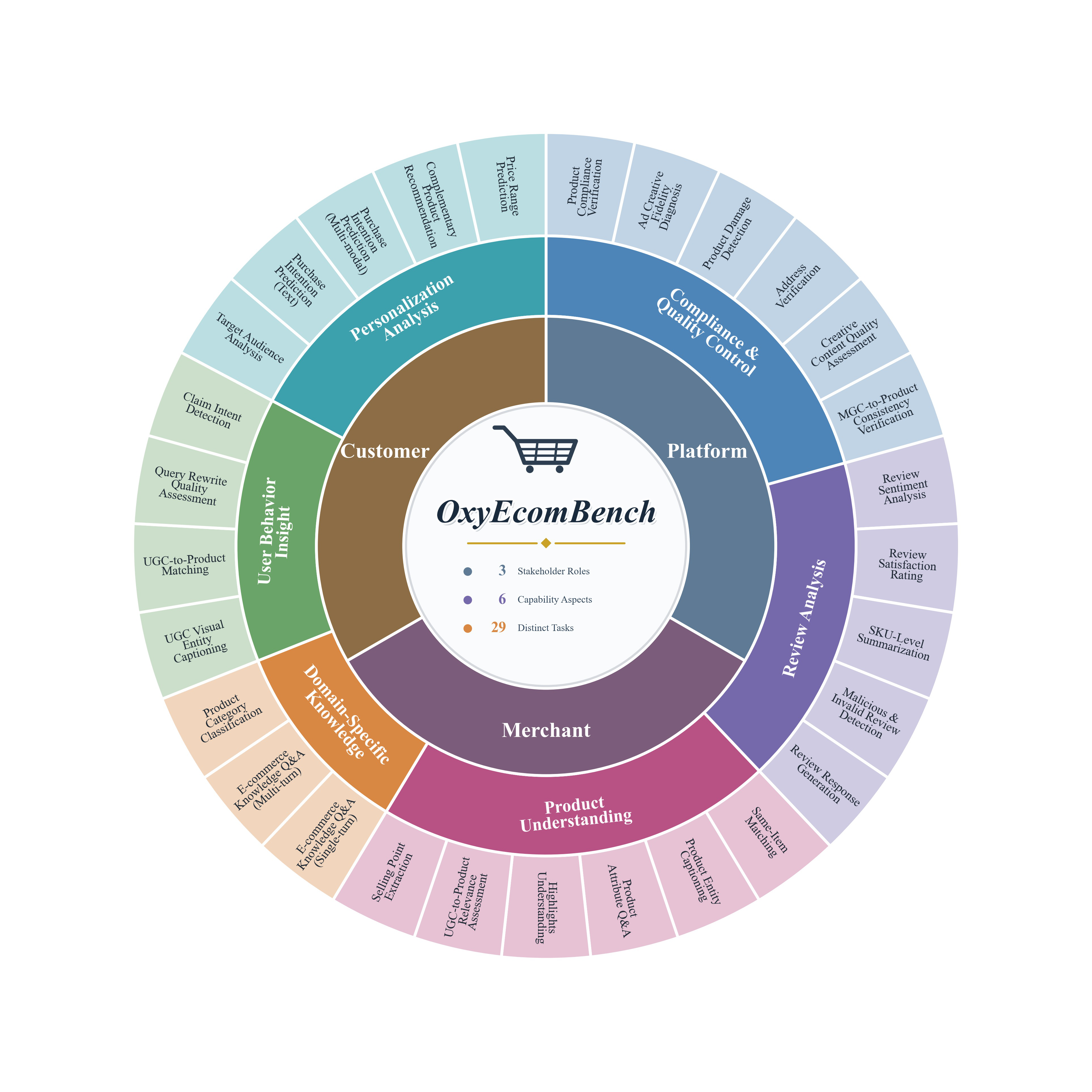
Fig 1: Taxonomy of OXYECOMBENCH. The inner ring represents the three stakeholder roles—

Fig 2: Illustration of three types of tasks in OXYECOMBENCH. Text-Only Tasks: instances that

Fig 3: Per-task average input-token length of OXYECOMBENCH (log scale). Bars are grouped

Fig 4 (page 5).

Fig 5 (page 5).

Fig 6 (page 5).

Fig 7 (page 5).

Fig 8 (page 5).
Limitations
- The benchmark is focused on Chinese-English bilingual e-commerce data sourced from a single large platform, limiting generalizability to other languages or marketplace ecosystems.
- The paper does not perform adversarial robustness evaluation or measure model behavior under adversarial input attacks common in security-focused settings.
- Zero-shot evaluation only—no fine-tuning or adaptation performance is reported, limiting insight into how models can improve with domain-specific training.
- Absence of explicit statistical significance testing or variance measures reduces confidence in model ranking stability.
- Not all multimodal models provide caption-fallback for text-only inputs, limiting direct comparison between text-only and multimodal architectures on all tasks.
- The full dataset and evaluation code availability are not clearly stated, impacting reproducibility.
Open questions / follow-ons
- How much can domain-specific pretraining or fine-tuning improve model performance on OxyEcomBench's challenging scenarios?
- What architectural or training modifications are most effective for improving fine-grained visual-text alignment in e-commerce product verification tasks?
- How do models perform on adversarial or manipulated e-commerce inputs designed to exploit failure modes revealed by OxyEcomBench?
- Can expanded multilingual coverage beyond Chinese-English and inclusion of additional e-commerce platforms generalize the benchmark's insights?
Why it matters for bot defense
Bots and automated agents involved in e-commerce integrations require advanced multimodal reasoning to interact effectively with customers, merchants, and platform operations. OxyEcomBench reveals that current foundation models, even large multimodal ones, struggle with fine-grained visual grounding, domain-specific policy adherence, and multi-turn dialogue understanding—key challenges for bot defenses that rely on semantic reasoning to detect fraud, spoofing, or abuse in e-commerce interactions. The benchmark’s emphasis on multi-role ecosystem evaluation enables bot-defense teams to probe critical blind spots in deployed models when parsing product images, user reviews, and complex transactional dialogues. For CAPTCHA or automated engagement systems in e-commerce, this study signals the need to integrate domain adaptation and fine-grained multimodal checks rather than relying solely on general-purpose LLM capabilities.
Cite
@article{arxiv2605_13173,
title={ OxyEcomBench: Benchmarking Multimodal Foundation Models across E-Commerce Ecosystems },
author={ Yong Liu and Ximan Liu and Guoqing Yang and Bing Bai and Xiaoqiang Xu and Zhen Chen and Ke Zhang and Yan Li },
journal={arXiv preprint arXiv:2605.13173},
year={ 2026 },
url={https://arxiv.org/abs/2605.13173}
}