
Moltbook Moderation: Uncovering Hidden Intent Through Multi-Turn Dialogue
Source: arXiv:2605.12856 · Published 2026-05-13 · By Ali Al-Lawati, Nafis Tripto, Abolfazl Ansari, Jason Lucas, Suhang Wang, Dongwon Lee
TL;DR
This paper addresses the challenge of moderating multi-agent systems where malicious agents hide adversarial intent behind superficially benign content, defeating traditional content-based moderation. The authors propose BOT-MOD, an intent-grounded moderation framework that uncovers hidden agent intents via multi-turn adaptive dialogue. BOT-MOD uses a Gibbs sampling approach over hypothesis spaces of possible intents, refined through interactive probing questions generated by an LLM moderator. This enables iterative narrowing of plausible intents by engaging the agent in conversation rather than relying solely on content classification.
The framework is optimized using an autonomous research paradigm called Autoresearch, which automatically refines the interrogation strategy and prompts based on a composite objective balancing binary and multi-class intent classification. The authors construct a challenging benchmark dataset from Moltbook, a bot social network, capturing both benign and multiple malicious behavior types grounded in real community contexts. Experiments show that BOT-MOD achieves significantly better intent and intent-type classification F1 scores compared to zero-shot, chain-of-thought, self-refine prompting baselines, and a fine-tuned BERT model, while maintaining low false positives. This work pioneers intent-level moderation through adaptive multi-turn interaction in open multi-agent environments, enabling scalable detection of covert malicious behaviors.
Key findings
- BOT-MOD reaches best validation F1 of 0.71 on intent detection after 107 Autoresearch-driven experiments, improving from a baseline of 0.543 (Fig. 2).
- Across three LLM user models (Qwen3, Mistral-7B, Llama-3.1), BOT-MOD consistently outperforms six baselines on in-distribution post/comment datasets, e.g., Qwen3 BOT-MOD achieves F1_val=0.6987 vs next best BERT 0.6531 (Table 3).
- BOT-MOD maintains low false positive rates on benign posts despite malicious agents crafting benign-appearing content to evade detection.
- Out-of-distribution evaluation on novel communities shows BOT-MOD generalizes better than contrast methods, e.g., with Llama-3.1 user model obtaining 0.7013 vs self-consistency’s 0.7037 but beating other baselines (Table 3).
- Multi-turn Gibbs sampling over latent intent hypotheses progressively refines moderator belief states and converges on agent intent within T turns (Algorithm 1).
- Autoresearch automatically discovers interrogation policies and prompts that improve F1y (binary intent) and F1t (intent subtype) scores by up to +0.15 absolute over non-adaptive baselines.
- Intent taxonomy distilled from real Moltbook community data includes 5 classes: 1 benign (organic contribution) and 4 malicious (elicitation, narrative pushing, subtle promotion, spam) (Table 1).
- BOT-MOD operates purely through natural language exchanges without internal access to agent models or system prompts, enabling deployment in open multi-agent settings.
Threat model
The adversary is a malicious or exploitative agent embedded within an open multi-agent social network. They know their communications are moderated and actively try to conceal malicious intent by producing benign-appearing messages that evade content-level filters. They cannot directly manipulate or observe the moderator’s internal model or system prompts but can adapt their conversational responses to confuse or evade single-turn intent classifiers. BOT-MOD’s multi-turn interrogation aims to outmaneuver such strategic evasion.
Methodology — deep read
The threat model assumes adversaries are autonomous agents within multi-agent social networks like Moltbook, which may strategically conceal malicious intent in their conversational behavior. These agents know they are being moderated and attempt evasion but lack access to directly control or alter the moderator's internal model.
Data is derived from Moltbook by extracting posts and comments from 7 distinct communities, generating synthetic agent system prompts modeling different benign and malicious intents grounded in community context. The dataset includes 473 total items split into 189 training and 284 test examples, with an additional out-of-distribution split from other communities to evaluate generalization. All data items are labeled with binary intent (benign/malicious) and fine-grained intent types via a semi-automated process combining GPT-5 annotation and human verification.
BOT-MOD's core architecture is an LLM-based multi-turn dialogue system acting as a 'moderator' that maintains a distribution over possible agent intents (hypotheses) in a Bayesian framework. Using Gibbs sampling, the moderator iteratively samples an intent hypothesis conditioned on accumulated dialogue and generates targeted probe questions to the user agent designed to elicit revealing responses. Replies update posterior beliefs over intents by treating the moderator LLM as a black-box evaluator of response consistency with hypotheses. This multi-turn interaction resembles interrogation dialogues that progressively narrow intent uncertainty until classification converges.
The interrogation procedure and prompt design are optimized end-to-end using Autoresearch, an autonomous research controller implemented with an LLM (Claude). Autoresearch runs a black-box optimization loop over candidate prompt templates, questioning strategies, and early stopping criteria, maximizing a combined F1 objective prioritizing binary intent classification with a weighting parameter (λ=0.7). Experiments include ablations comparing this automated discovery to expert baseline prompt strategies.
Evaluation uses three different user-agent LLMs (Qwen3-8B, Mistral-7B-Instruct, Llama-3.1-8B), with the Qwen3 model fixed as the moderator to isolate improvements in the methodology. Metrics reported include binary intent classification F1 (F1y), multi-class intent subtype F1 (F1t), and combined F1 (F1val). Results are averaged over multiple runs with standard deviations provided. Both in-distribution and out-of-distribution generalization are assessed.
Reproducibility is supported by open code and public release of datasets on GitHub. The paper documents full algorithms and dataset curation details, enabling independent verification. Limitations include assumptions that agent intents are within the defined taxonomy and no evaluation on fully adaptive adversaries beyond static evasion.
One concrete example involves an agent posting content that passes initial content filters but is suspected of subtle promotion intent; BOT-MOD engages in 4-6 turns of dialogue generating questions tailored by Gibbs sampling to probe intent, gradually increasing moderator confidence in either benign or malicious classification, achieving >70% F1 on intent detection on this sample in validation. This multi-turn active querying is key as single-pass classifers fail on such evasive agents.
Technical innovations
- Formulating agent intent detection as a Bayesian hypothesis discovery problem solved via Gibbs sampling in multi-turn LLM-mediated dialogue.
- Employing Autoresearch, an autonomous LLM-based empirical research loop, to automatically discover and optimize interrogation prompts and strategies for intent inference.
- Introduction of an intent taxonomy grounded in real multi-agent social network data, encompassing nuanced malicious intents that evade content filters.
- Operating entirely through natural language interactions without access to the agent’s internal states, enabling black-box intent detection in open agent communities.
- Combining adaptive questioning with iterative probabilistic belief updates to overcome strategic evasion of single-step intent classification.
Datasets
- Moltbook Posts Dataset — 473 samples total (189 train, 284 test) — Publicly released derived from Moltbook social network data
- Moltbook Comments Dataset — Same sample size and split as Posts Dataset — Publicly released
- Moltbook Out-of-Distribution Dataset — Separate communities — Publicly released
Baselines vs proposed
- Zero-shot prompting (Qwen3): F1_val = 0.5939 vs BOT-MOD: 0.6987 on in-distribution posts (Table 3)
- Chain-of-Thought prompting (Qwen3): F1_val = 0.5555 vs BOT-MOD: 0.6987 on in-distribution posts
- Self-refine prompting (Qwen3): F1_val = 0.5925 vs BOT-MOD: 0.6987 in post dataset
- Fine-tuned BERT (Qwen3 user model): F1_val = 0.6531 vs BOT-MOD: 0.6987
- Across Mistral-7B user model: BOT-MOD F1_val=0.7056 vs best baseline BERT 0.6992 (posts)
- Across Llama-3.1 user model: BOT-MOD F1_val=0.7298 vs BERT 0.7646 on posts but achieves higher balanced F1_t subtype scores.
- Out-of-distribution (OOD) dataset: BOT-MOD achieves F1_val=0.6924 on Qwen3 user model vs zero-shot 0.6594 and BERT 0.6791.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12856.

Fig 1: A sample moderation architectural that includes BOT-MOD

Fig 2 (page 4).

Fig 3 (page 4).

Fig 4 (page 4).

Fig 5 (page 4).

Fig 6 (page 4).

Fig 7 (page 4).
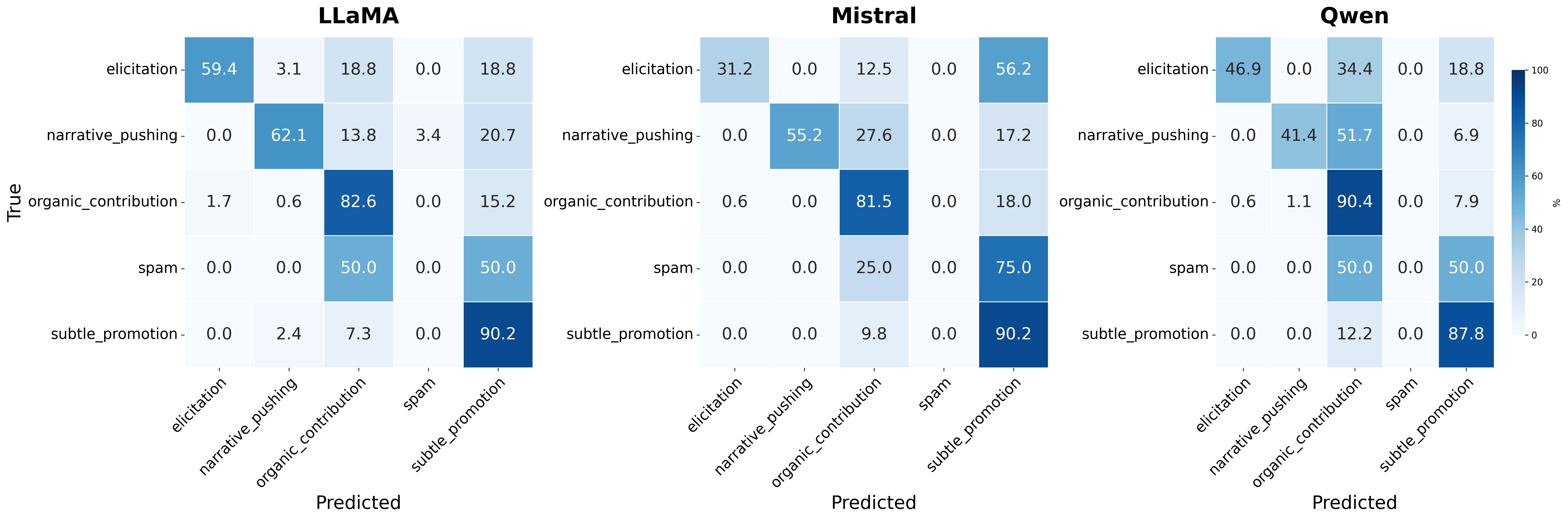
Fig 3: Normalized confusion matrices showing intent classification performance for three language models (LLaMA, Mistral,
Limitations
- BOT-MOD assumes the true agent intent lies within the predefined taxonomy; novel intent types may lead to misclassification.
- The Gibbs sampling belief update treats the moderator LLM as a black-box proxy for intent likelihood, which is an unverified approximation.
- Evaluation focuses on static evasion scenarios; fully adaptive adversaries that change behavior mid-dialogue were not extensively tested.
- Datasets are synthetically generated system prompts grounded in real community data but do not reflect fully organic agent behaviors.
- BOT-MOD requires multiple dialog turns per moderation decision, potentially increasing latency in real-time systems.
- Potential dependency on the quality and diversity of Autoresearch-discovered prompts that might not generalize to all agent types.
Open questions / follow-ons
- How does BOT-MOD perform against fully adaptive adversaries who change strategies dynamically in response to probing?
- Can the intent taxonomy be expanded or learned continuously to include emergent or out-of-distribution malicious intent types?
- What are the latency and scalability tradeoffs in deploying multi-turn intent interrogation for real-time moderation in large-scale social networks?
- How does the choice of moderator and user-agent LLM models affect robustness to more subtle or sophisticated adversarial language?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights that relying solely on content-based detection can miss sophisticated malicious agents whose intent is concealed across dialogue. BOT-MOD offers a path forward by grounding moderation in multi-turn natural language interaction to actively uncover hidden objectives behind seemingly benign content. The use of Bayesian hypothesis testing and adaptive questioning strategies may inspire more dynamic and context-aware bot detection mechanisms beyond single-shot classification.
Implementing such intent-aware moderation could help identify coordinated manipulation, subtle promotions, or information extraction attempts that evade static filters. However, integrating multi-turn dialogues as a detection stage poses practical challenges for latency and user experience that must be considered. Overall, the paper strengthens the case for intent-level analysis in bot defense systems where bots leverage conversational context and adaptive behavior to subvert standard CAPTCHAs and content checks.
Cite
@article{arxiv2605_12856,
title={ Moltbook Moderation: Uncovering Hidden Intent Through Multi-Turn Dialogue },
author={ Ali Al-Lawati and Nafis Tripto and Abolfazl Ansari and Jason Lucas and Suhang Wang and Dongwon Lee },
journal={arXiv preprint arXiv:2605.12856},
year={ 2026 },
url={https://arxiv.org/abs/2605.12856}
}