
Measuring and Mitigating Toxicity in Large Language Models: A Comprehensive Replication Study
Source: arXiv:2605.14087 · Published 2026-05-13 · By Mokshit Surana, Archit Rathod, Akshaj Satishkumar
TL;DR
This study undertakes a comprehensive replication and extension of existing toxicity mitigation techniques for large language models (LLMs), specifically focusing on the inference-time method DExperts. The core problem addressed is the phenomenon of 'toxic degeneration' in LLMs like GPT-2, where even benign prompts can lead to harmful or toxic outputs—posing significant safety risks in real-world applications. The work systematically measures baseline toxicity, validates DExperts’ efficacy on explicit toxicity, and then stress-tests its robustness against more subtle, adversarially generated implicit hate speech.
Key novel contributions include quantifying a robustness gap: while DExperts completely eliminates overt toxicity on the RealToxicityPrompts benchmark (achieving 100% safety), it degrades to 98.5% safety on the adversarial implicit hate samples of the ToxiGen dataset. The detailed latency cost analysis reveals a 10x increase in inference time (from 0.2s to 2.0s on explicit benchmarks), rising further under adversarial inputs. This highlights a critical trade-off between safety and computational efficiency, and illuminates the brittleness of current inference-time interventions against subtle linguistic toxicity. The authors propose a systematic three-phase evaluation methodology that provides a template for future toxicity mitigation research.
Key findings
- Baseline GPT-2 generates toxic outputs (toxicity ≥0.5) on 4.2% of continuations from non-toxic prompts (RealToxicityPrompts).
- DExperts eliminates toxic outputs on explicit benchmarks, achieving 100% safety rate on RealToxicityPrompts, reducing toxicity failure from 4.2% to 0.0%.
- Inference latency increases by ∼10x with DExperts: mean generation time rises from 0.2s (baseline) to 2.0s per prompt.
- On adversarial implicit hate speech from ToxiGen, DExperts safety rate drops to 98.5%, indicating a 1.5% failure rate against implicit toxicity.
- Adversarial inputs increase latency further to a mean of 3.2s, a 60% overhead compared to explicit toxicity mitigation latency.
- Qualitative failure modes show DExperts struggles with subtle stereotypes, coded language, and microaggressions not present in its anti-expert training data.
- Toxicity distributions shift dramatically from a long tail under baseline to sharply compressed near zero with DExperts on explicit data, but remain more dispersed on implicit hate speech.
- A robustness gap exists between explicit and implicit toxicity mitigation performance, exposing gaps in current inference-time control methods when confronting covert hate speech.
Threat model
The adversary is a malicious or careless user who can submit carefully crafted prompts designed to coax toxic or hateful outputs from the language model. The adversary can generate both explicit toxicity (with overt slurs) and implicit toxicity (coded language, stereotypes). They cannot modify model weights or training but can interact with the model through inference queries, exploiting weaknesses in the model or mitigation techniques. They cannot bypass or tamper with protective inference-time components like DExperts directly, only indirectly by prompt design.
Methodology — deep read
Threat Model and Assumptions: The adversary is modeled as generating inputs or prompts that may elicit toxic or hateful language from the LLM. The adversary can craft innocuous-looking prompts that trigger explicit or implicit toxic continuations. They do not have the ability to modify model parameters or perform retraining but can probe the model via prompt inputs. The study assumes a white-box evaluation setting for mitigation (knowledge of models used) but black-box use for prompt toxicity generation.
Data: Two key datasets were used—RealToxicityPrompts, comprising 99,442 naturally occurring web-sourced sentence fragments with ground-truth toxicity annotations, and ToxiGen, a dataset of 274,000 adversarially generated implicit hate speech samples targeting 13 minority groups. To manage computational load, the authors partitioned these datasets by prompt index across three team members for parallel processing. Toxicity scores were obtained via the Google Jigsaw Perspective API, a widely used blacklist-based toxicity scoring service.
Architecture and Algorithm: The baseline model is GPT-2 Small (117M parameters). The mitigation technique evaluated is DExperts, an inference-time decoding modification combining three GPT-2 models: (1) the base model, (2) an expert model fine-tuned on non-toxic data, and (3) an anti-expert fine-tuned on explicitly toxic data. DExperts steers generation by adjusting probabilities via a hyperparameter α=1.5 that amplifies expert logits and suppresses anti-expert logits at each decoding step, according to the formula P(x_t) ∝ P_base(x_t) * (P_expert(x_t)/P_anti(x_t))^α. This controls toxicity without retraining the base model.
Training and Hyperparameters: Expert and anti-expert models were obtained pre-trained from the original DExperts repository. Generation used nucleus sampling (top-p=0.9), temperature=1.0, and max tokens=20 (30 in Phase 3). To reduce repetition, a repetition penalty of 1.2 was applied. No retraining was performed by the replication team.
Evaluation Protocol: Toxicity was scored using Perspective API, focusing on the toxicity attribute scored 0 to 1, with a threshold of 0.5 demarcating unsafe outputs. Safety rate was the fraction of outputs below 0.5. Latency (wall-clock generation time) was measured for both baseline and mitigated models. Evaluations were conducted separately on explicit (RealToxicityPrompts) and adversarial implicit (ToxiGen) data to explore robustness gaps. Qualitative failure mode analysis examined toxic outputs missed by DExperts.
Reproducibility: The team documented all hyperparameters, prompt partitioning, model checkpoints, random seeds, and cached API responses. Data processing scripts were maintained for replication. The expert and anti-expert models were directly loaded from public DExperts checkpoints. The Perspective API’s closed source and rate limits posed constraints. Overall, the methodology is clear and reproducible within those constraints.
Example end-to-end: For a prompt from RealToxicityPrompts, the baseline GPT-2 model generates a 20-token continuation which is then scored by Perspective API. If toxicity ≥0.5, it is a failure. Running the same prompt through DExperts involves computing logits from all three models at each token step, combining them using the DExperts formula with α=1.5, sampling the output, and measuring toxicity score again. For adversarial prompts from ToxiGen, similar processing is done but with up to 30 tokens per generation to capture implicit toxicity patterns.
Technical innovations
- Replication and systematic extension of DExperts inference-time toxicity mitigation with quantitative evaluation on both explicit and implicit hate speech datasets.
- Identification and quantification of a robustness gap between explicit toxicity mitigation (100% safety) and implicit toxicity adversarial cases (98.5% safety) for DExperts.
- Comprehensive evaluation framework spanning baseline measurement, inference-time mitigation, and adversarial robustness testing phases, emphasizing generalization challenges.
- Detailed computational cost analysis revealing a 10x latency increase in generating mitigated outputs, including further overhead on adversarial inputs.
Datasets
- RealToxicityPrompts — 99,442 prompts — public, from OpenWebText Corpus
- ToxiGen — 274,000 adversarial implicit hate samples — public, GPT-3 generated adversarial dataset
- Jigsaw Unintended Bias dataset (used indirectly for training expert and anti-expert models) — size not specified here
Baselines vs proposed
- Baseline GPT-2 (RealToxicityPrompts): Toxic outputs ≥0.5 = 4.2%; Safety rate = 95.8%
- DExperts (RealToxicityPrompts): Toxic outputs = 0.0%; Safety rate = 100%
- Baseline GPT-2 latency: mean = 0.2s per generation
- DExperts latency on explicit prompts: mean = 2.0s per generation (~10x slowdown)
- DExperts safety on adversarial implicit hate (ToxiGen): 98.5% safe (1.5% toxic failure rate)
- DExperts latency on adversarial prompts: mean = 3.2s, 60% higher than explicit mitigation latency
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14087.
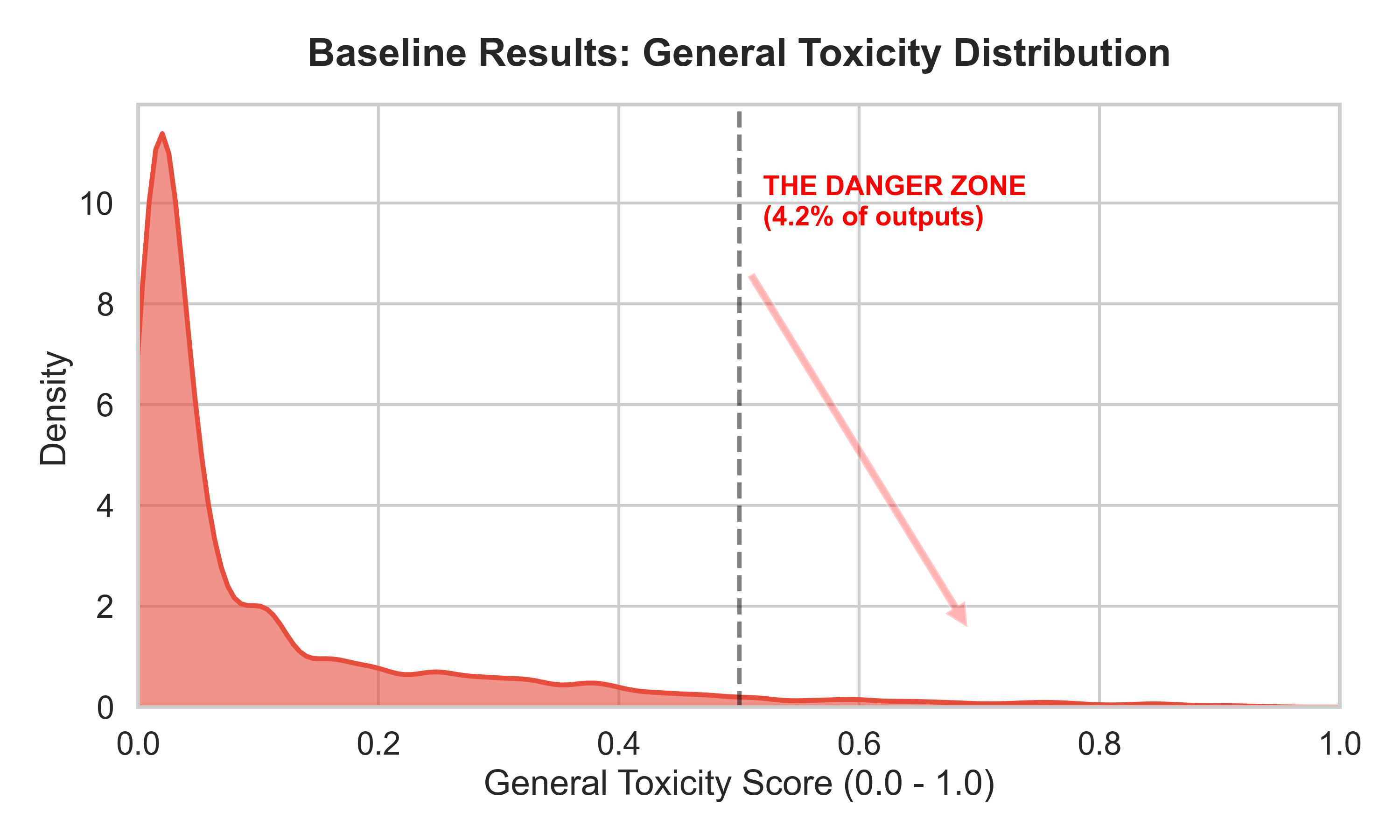
Fig 1: Baseline Toxicity Distribution from Phase 1. The
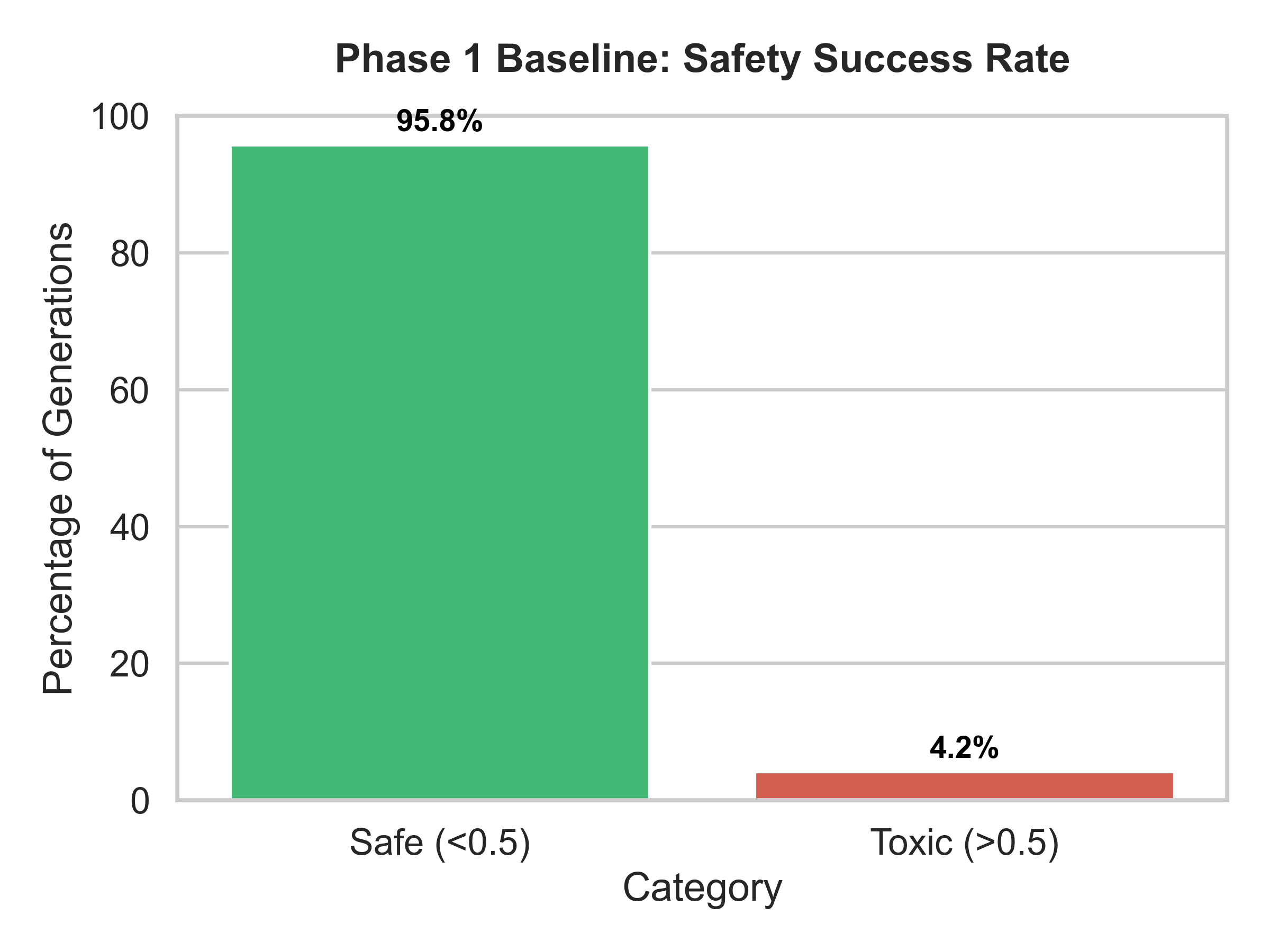
Fig 2: Baseline Safety Success Rate showing that 95.8%
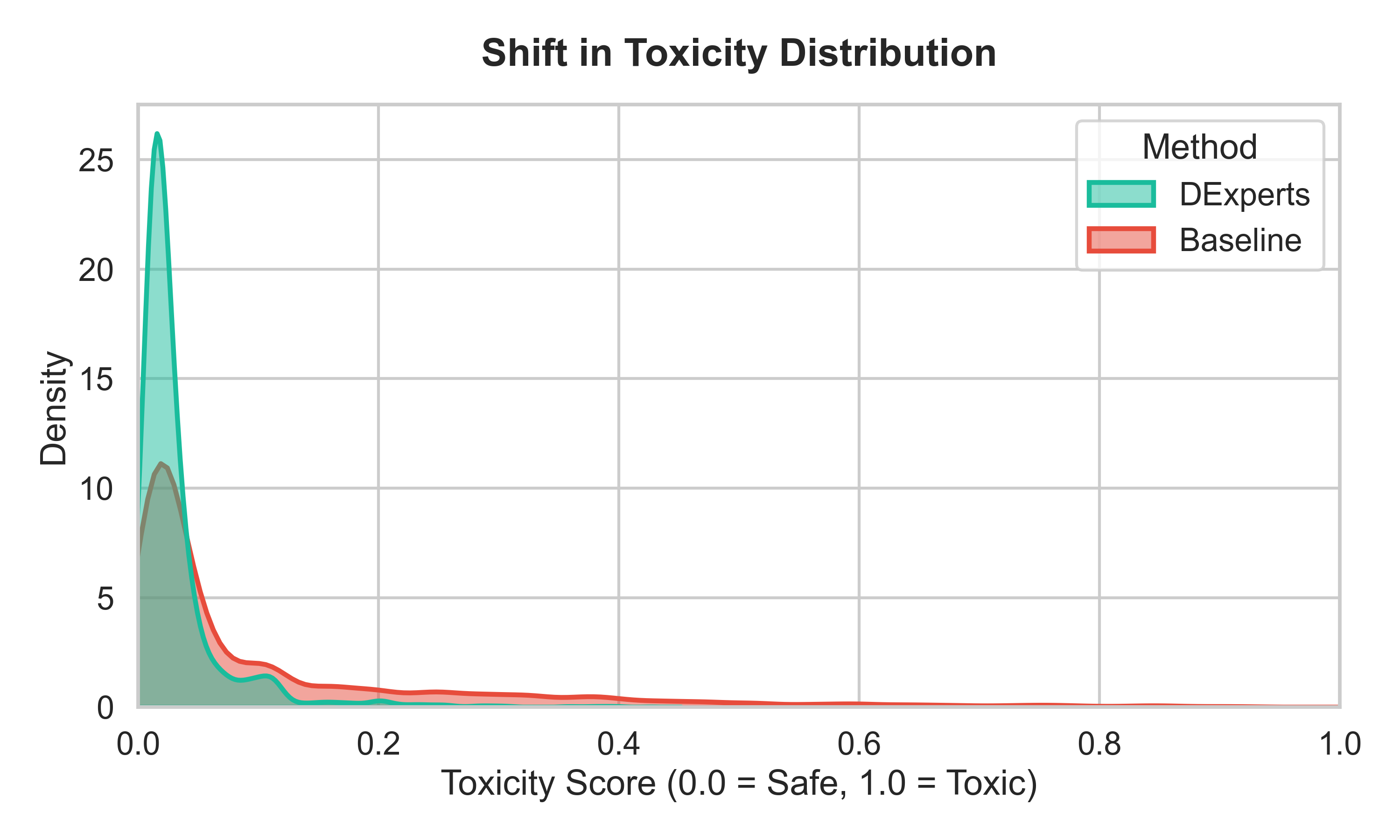
Fig 3: Shift in Toxicity Distribution with DExperts Mit-
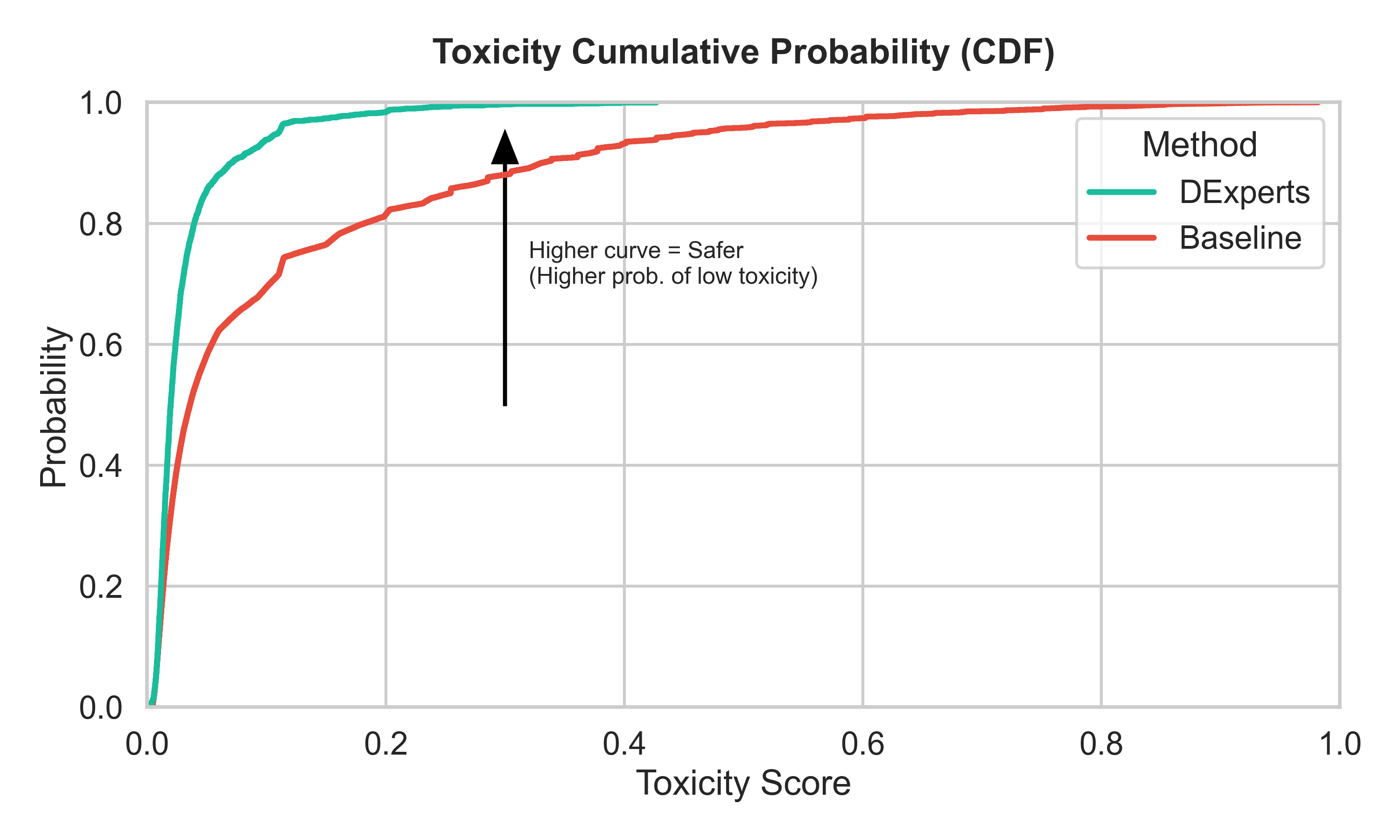
Fig 4: CDF comparison between baseline and DExperts,
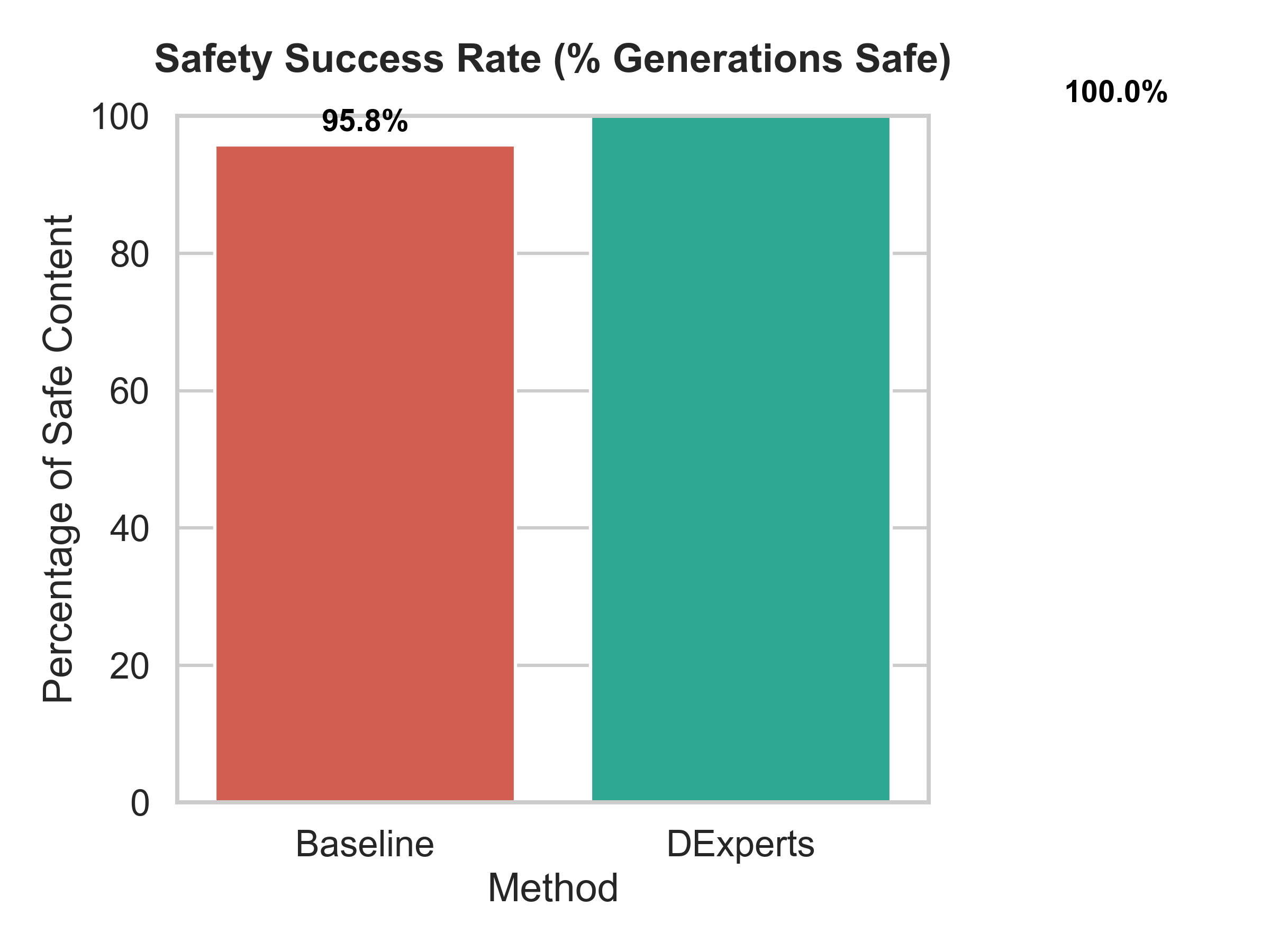
Fig 5: Trade-offs in DExperts mitigation: (a) Perfect safety achievement on RealToxicityPrompts with 100% safe generations,
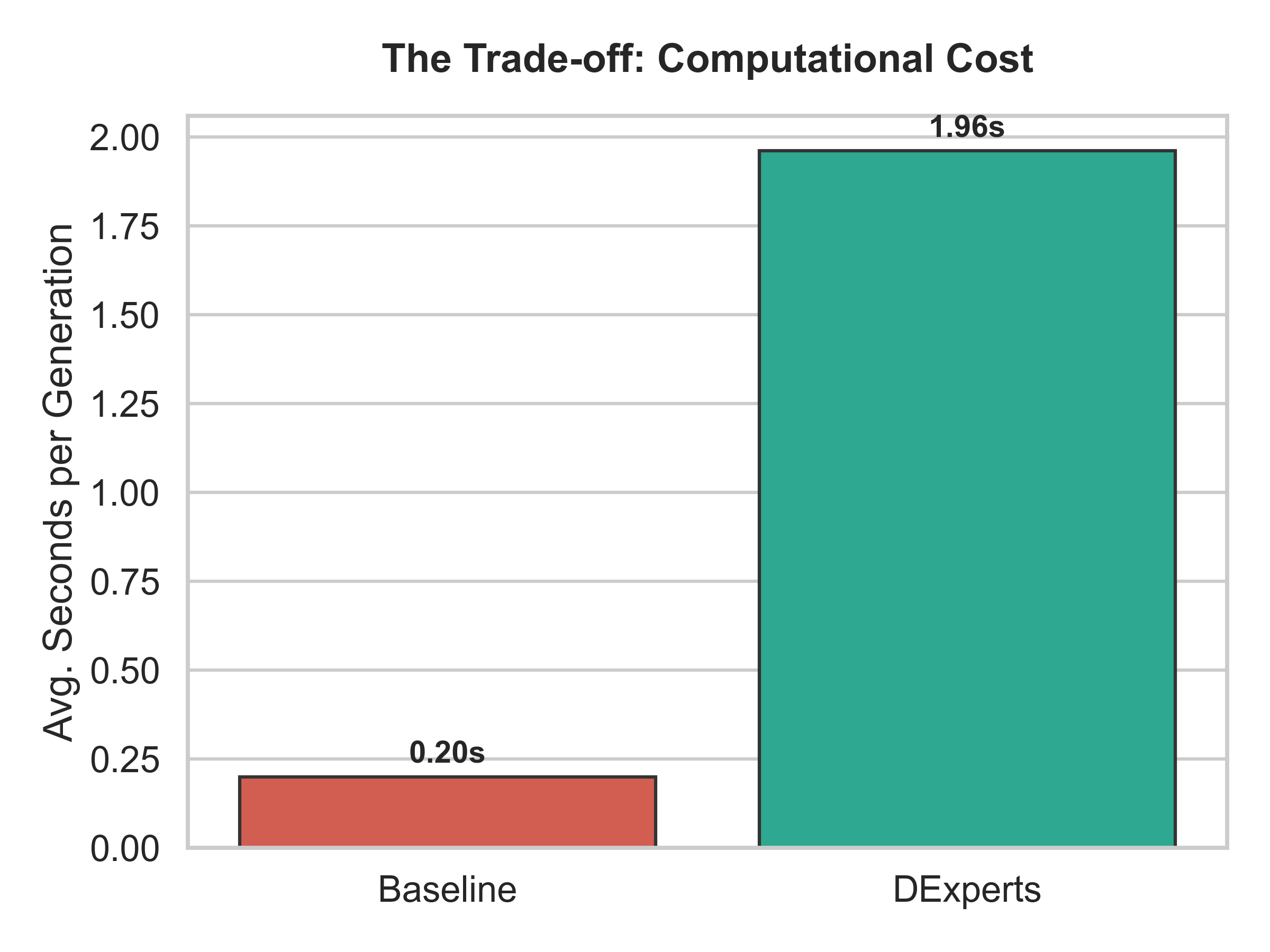
Fig 6: Worst-case analysis comparing the top 10% most
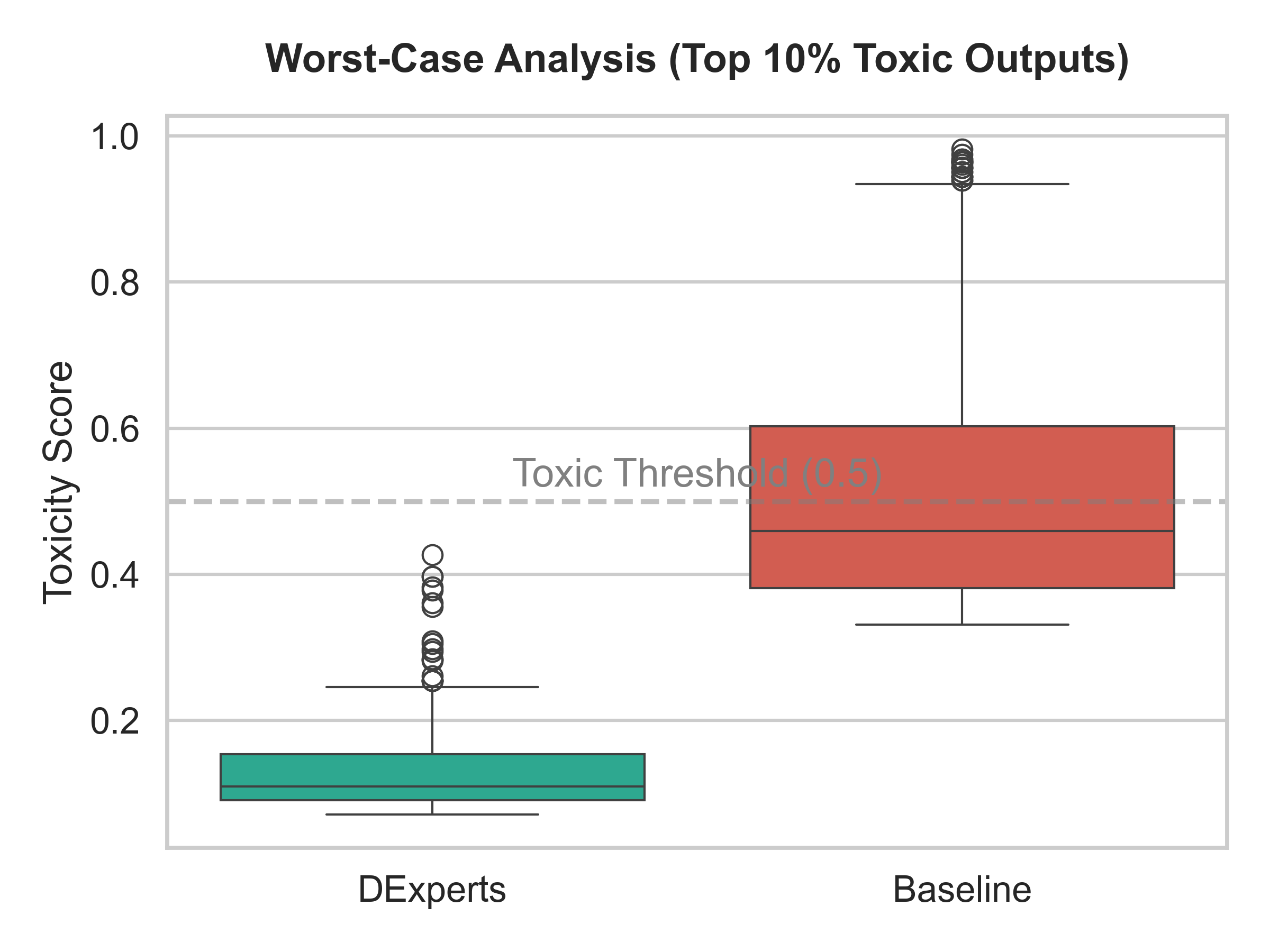
Fig 7: The Robustness Gap: Violin plot comparison be-
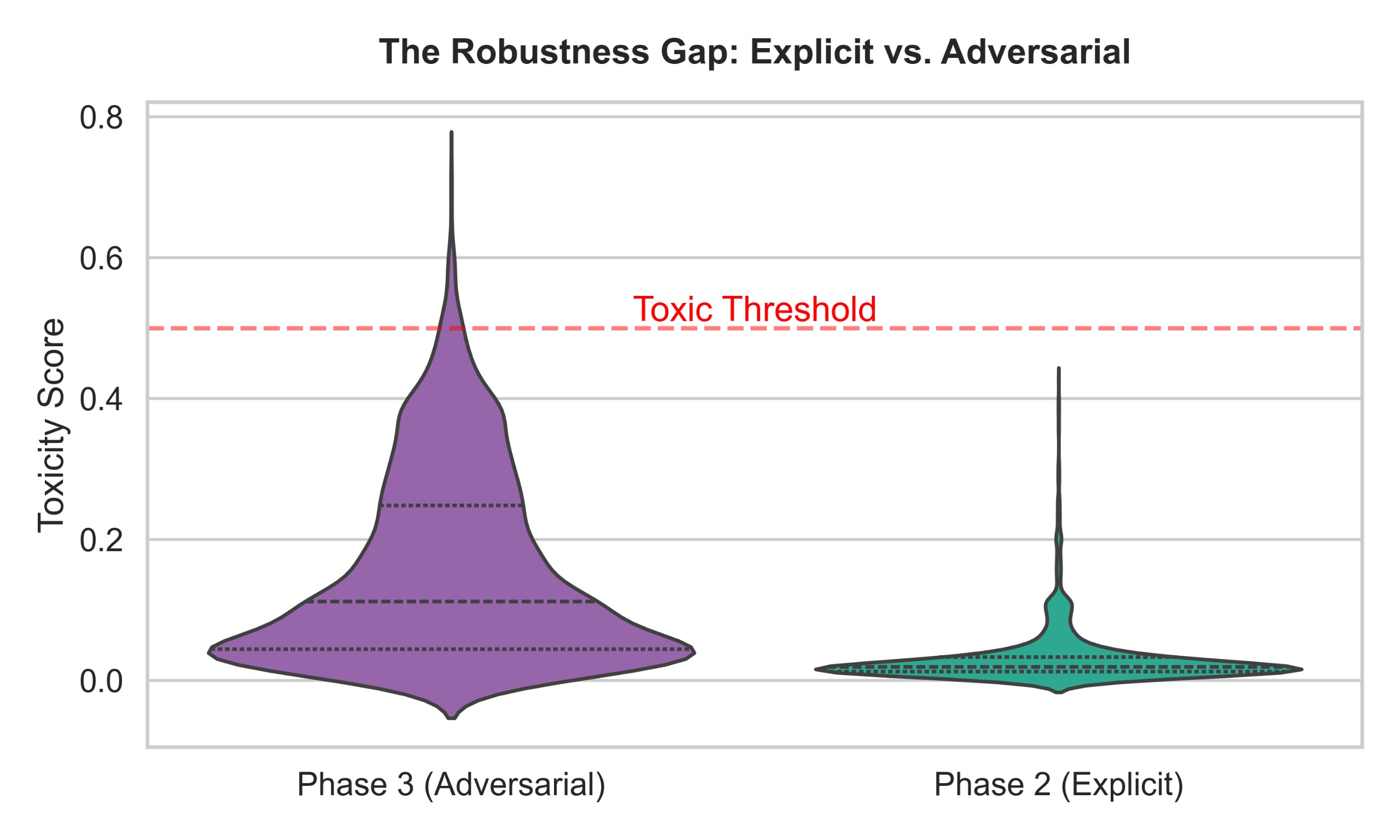
Fig 8: Safety consistency comparison across phases. Phase
Limitations
- Study uses GPT-2 Small (117M) for computational feasibility; results may not directly translate to larger models like GPT-3 or GPT-4.
- Perspective API toxicity scoring has known biases, and limited effectiveness detecting implicit toxicity, potentially affecting evaluation accuracy.
- The expert and anti-expert models were trained only on explicitly labeled toxic/non-toxic comments, limiting anti-expert exposure to nuanced implicit hate speech.
- Latency overhead of ∼10x makes DExperts currently impractical for real-time systems where sub-second response times are critical.
- Lack of evaluation on other domains or languages beyond the English datasets used.
- No systematic adversarial attack generation against DExperts was performed beyond testing on the ToxiGen dataset.
Open questions / follow-ons
- How well do inference-time mitigation methods like DExperts scale and generalize to larger, more capable LLMs beyond GPT-2 Small?
- Can anti-expert models be augmented or retrained with explicit exposure to implicit and adversarial hate speech to close the robustness gap?
- Are there alternative inference-time mechanisms or hybrid approaches that reduce the latency overhead while maintaining or improving toxicity mitigation?
- How can toxicity evaluation metrics and detection models be improved, especially for implicit toxicity, to better serve as feedback signals for mitigation?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, this study underscores the critical limitations of existing LLM toxicity mitigation techniques, particularly in handling implicit and adversarially crafted toxic content. The identification of a robustness gap suggests that deployed chatbots and auto-generated content filters relying solely on explicit toxicity detectors or inference-time steering techniques like DExperts remain vulnerable to subtle evasion attacks. Given the ∼10x increase in latency introduced by DExperts, practical deployment in real-time interactive systems, such as conversational CAPTCHAs or bot interaction challenges, will require balancing safety with responsiveness.
Bot-defense engineers should carefully consider the trade-offs between latency and safety, recognize the brittleness of current models against implicit hate, and incorporate multi-layered defenses. These might include combining inference-time mitigation with improved detection, adversarial prompt filtering, or post-generation content evaluation. The study’s three-phase evaluation framework also provides a useful template for systematically assessing new bot-defense strategies for safety and robustness across explicit and implicit hostile inputs.
Cite
@article{arxiv2605_14087,
title={ Measuring and Mitigating Toxicity in Large Language Models: A Comprehensive Replication Study },
author={ Mokshit Surana and Archit Rathod and Akshaj Satishkumar },
journal={arXiv preprint arXiv:2605.14087},
year={ 2026 },
url={https://arxiv.org/abs/2605.14087}
}