
LEXI-SG: Monocular 3D Scene Graph Mapping with Room-Guided Feed-Forward Reconstruction
Source: arXiv:2605.13741 · Published 2026-05-13 · By Christina Kassab, Hyeonjae Gil, Matías Mattamala, Ayoung Kim, Maurice Fallon
TL;DR
LEXI-SG tackles the challenge of constructing accurate, scalable 3D scene graphs from monocular RGB input alone, removing the reliance on depth sensors or ground-truth poses common in prior methods. It leverages open-vocabulary foundation models to semantically partition indoor scenes into rooms and defers dense feed-forward reconstruction until each room is fully observed. This room-aware batching approach avoids sliding-window scale inconsistencies and reduces geometric artifacts like double walls. A factor graph over rooms globally aligns reconstructions using Sim(3) optimization, preserving local consistency while imposing the semantic hierarchy of rooms and contained objects. Additionally, an open-vocabulary object segmentation and tracking module lifts 2D mask tracklets into the 3D scene graph as object nodes.
Evaluated on multi-room indoor datasets including Habitat-Matterport 3D and self-collected office sequences, LEXI-SG achieves state-of-the-art monocular SLAM performance, outperforming recent feed-forward methods on trajectory estimation and dense reconstruction metrics. The semantic segmentation results are competitive with baselines that use depth and pose inputs. Qualitative results show reduced drift and globally consistent reconstructions with minimal double-walling. Ablations confirm that the room-based batching and loop closure modules significantly reduce trajectory error. Overall, LEXI-SG demonstrates that dense, open-vocabulary 3D scene graphs can be reliably built from RGB alone by leveraging semantic priors to guide monocular reconstruction.
Key findings
- LEXI-SG halves average trajectory error (ATE) on the Aria Office Dataset (AOD) compared to sliding-window baselines (from 0.812 m to 0.427 m), with further reduction to 0.305 m after loop closure (Table VI).
- On Habitat-Matterport 3D (HM3D), LEXI-SG achieves an average ATE of 0.474 m, outperforming baselines including MASt3R-SLAM and multiple VGGT-SLAM variants (Tables II and III).
- LEXI-SG achieves lowest chamfer distance reconstruction error on office sequence rooms, with values as low as 0.085 m, outperforming MASt3R-SLAM and VGGT-SLAM (Table I).
- In room segmentation, LEXI-SG reaches recall comparable to methods using ground truth poses and depth (0.85 average recall), but with slightly lower precision (0.52 average) due to difficulty handling open-plan spaces (Table IV).
- Open-vocabulary semantic segmentation matches or surpasses baselines like ConceptGraphs and HOV-SG in synonyms metric on HM3D (0.41 vs 0.40), with fewer incorrect labels and better segmentation consistency (Table V).
- Batch size impacts performance; batch of 60 frames is optimal balancing coverage and tracking, improving ATE to 0.305 m on AOD and 0.474 m on HM3D (Table VII).
- Runtime analysis shows the pipeline runs at 12.92 FPS without object segmentation, while object processing dominates runtime and reduces speed to 1.56 FPS (Table VIII).
Threat model
The adversary is a passive environment or unknown real-world conditions that may degrade the monocular input (e.g., challenging lighting, textureless regions) but cannot inject active attacks or spoof sensor inputs. The system assumes only a monocular RGB camera with unknown intrinsics and no external localization. The adversary cannot tamper with the feed-forward models or manipulate loop closure nodes. The threat model focuses on robustness to sensor limitations rather than active adversarial attempts.
Methodology — deep read
The problem addressed is monocular 3D scene graph reconstruction from RGB images without depth or ground-truth poses, aiming for hierarchical semantic and geometric scene understanding.
The threat model assumes a passive agent capturing an RGB image stream in indoor multi-room environments, with no access to depth or inertial data, and unknown camera calibration. The system does not consider active adversarial attacks.
Data provenance includes multi-room indoor datasets: Habitat-Matterport 3D (HM3D), a large-scale set of home environments with multi-floor sequences, and a self-collected Aria Office Dataset (AOD) recorded using Meta’s Project Aria glasses with accurate ground truth poses from a multi-camera VIO system. These datasets include RGB sequences, ground-truth scans for reconstruction evaluation, and semantic labels.
LEXI-SG's architecture consists of several modules:
- Room segmentation: Incoming RGB frames are encoded using DINO features to detect room transitions by classifying transitional cues (doorways, corridors) across a hysteresis threshold. This partitions image streams into room batches.
- Room-based reconstruction: Unlike sliding-window inference, LEXI-SG defers feed-forward dense reconstruction (using MapAnything model) until a room batch is finalized. This produces depth and poses for all frames relative to a room-local coordinate frame anchored on the batch's first frame.
- Room pose graph: Rooms are nodes with Sim(3) poses; edges encode relative transforms estimated from transition frame pairs processed through MapAnything to compute relative transformations between room reference frames. These edges capture temporal adjacency and loop closures.
- Loop closure detection: When revisiting rooms, the system matches image features to find candidate merges, merges batches, performs reconstruction on the union, and verifies geometric consistency before updating the room pose graph.
- Open-vocabulary object segmentation and tracking: After room reconstruction, per-frame 2D object masks are generated using Recognize Anything and Grounding DINO. Mask tracklets are propagated across frames via a SAM2-based tracker, then lifted into 3D object nodes attached to their parent room frames.
- Global optimization: A factor graph optimizes only the room poses over Sim(3) using Levenberg–Marquardt, accounting for accumulated drift and monocular scale ambiguity. Object poses update implicitly in their room-local frames.
Training regime details for MapAnything are from prior work [13]; LEXI-SG focuses on integration rather than retraining.
Evaluation protocol involves four tasks:
- Task 1: Camera pose estimation evaluated with absolute trajectory error (ATE) on multi-room sequences from HM3D and AOD.
- Task 2: Dense reconstruction compared via Chamfer distance on office rooms.
- Task 3: Room segmentation evaluated on HM3D with respect to precision and recall following Hydra protocol.
- Task 4: Open-vocabulary semantic segmentation measured on OpenLex3D benchmark using ground-truth poses and depth to isolate semantic performance.
Baselines include feed-forward SLAM methods (MASt3R-SLAM, VGGT-SLAM variants, ViSTA-SLAM) and semantic scene graph systems (HOV-SG, Hydra, ConceptGraphs).
A concrete example: An input RGB stream is segmented into rooms by detecting doorways from DINO features. Once a room's frames are gathered, MapAnything infers dense depth and camera poses in a room frame, yielding a per-room dense point cloud. Transition edges to neighboring rooms are computed by feeding transition frame pairs through MapAnything to estimate relative transformations. Loop closures merge revisited rooms, re-inferencing geometry. Finally, 2D object masks are detected and tracked within room frames and lifted into 3D to enrich the scene graph.
The RGB-only approach avoids the calibration and sensor dependency issues of depth or inertial input, enabling scalable dense monocular mapping.
Code and datasets for the self-collected sequences are publicly available, though MapAnything weights come from prior work and some datasets have restricted licenses.
Technical innovations
- Room-based batching strategy that defers feed-forward monocular reconstruction until a room is fully observed to avoid sliding-window scale inconsistencies and reduce double-walling.
- A room-level Sim(3) factor graph formulation that globally aligns independently reconstructed room batches, preserving local consistency and resolving monocular scale ambiguity.
- Vision-only room segmentation using DINO features combined with transition cue classification and hysteresis filtering to robustly detect room boundaries from RGB alone.
- Integration of open-vocabulary 2D object segmentation and tracking using Recognize Anything and Grounding DINO with SAM2 tracker to lift mask tracklets into 3D object nodes in the scene graph.
Datasets
- Habitat-Matterport 3D (HM3D) — multi-room indoor RGB sequences with ground-truth 3D scans — publicly available
- Aria Office Dataset (AOD) — multi-floor office RGB sequences recorded with Meta Project Aria glasses, ground truth poses from multi-camera VIO — self-collected, publicly released
Baselines vs proposed
- ViSTA-SLAM: average ATE on HM3D = 0.700 m vs LEXI-SG = 0.474 m
- VGGT-SLAM Sim(3): average ATE on HM3D = 0.872 m vs LEXI-SG = 0.474 m
- MASt3R-SLAM: average ATE on AOD = 0.296 m vs LEXI-SG = 0.305 m (close performance)
- LEXI-SG: average chamfer distance on AOD rooms 0.114 m vs MASt3R-SLAM 0.163 m (best reconstruction accuracy)
- HOV-SG: room segmentation precision 0.86, recall 0.84 vs LEXI-SG precision 0.52, recall 0.85 (lower precision)
- ConceptGraphs: semantic synonyms score on HM3D 0.40 vs LEXI-SG 0.41 (comparable semantic segmentation)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13741.
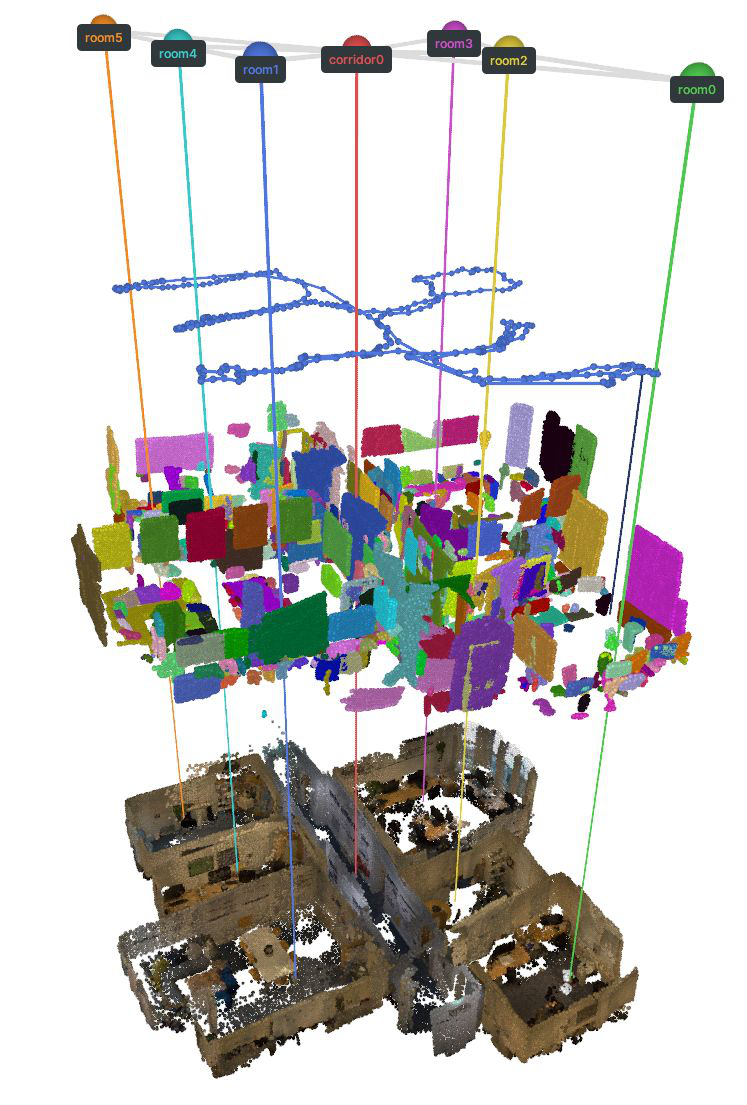
Fig 1: LEXI-SG is the first dense monocular mapping

Fig 2: LEXI-SG System Overview. RGB frames are segmented into rooms using DINO features. Upon detecting a room

Fig 3: Transition edge estimation. The relative transform

Fig 4: Qualitative reconstruction results on our office dataset AOD and HM3D. LEXI-SG produces more accurate,

Fig 5 (page 2).

Fig 6 (page 2).

Fig 7 (page 2).

Fig 8 (page 2).
Limitations
- Room segmentation precision suffers in open-plan spaces lacking clear doorways or corridors, limiting accurate transition detection and causing misclassification.
- Pose estimation accuracy is limited by the feed-forward reconstruction model, without per-keyframe optimization, imposing an accuracy ceiling.
- Object segmentation and tracking dominate runtime cost (~88%), reducing overall system speed to ~1.56 FPS when enabled.
- Evaluations are primarily on indoor office/home environments; generalization to other scene types or outdoor settings is not shown.
- No explicit adversarial robustness testing or long-term loop closure consistency under dynamic scene changes was reported.
- Semantic segmentation uses ground-truth poses and depths for isolation; end-to-end performance with predicted poses may be lower but not quantified.
Open questions / follow-ons
- How can room segmentation precision be improved in open-plan or highly connected spaces without doorways?
- Can integration of geometric or appearance cues alongside semantics better handle challenging layouts and reduce segmentation errors?
- What are the effects and potential improvements from adding per-keyframe pose optimization within room batches to push accuracy beyond feed-forward model limits?
- How does LEXI-SG perform under dynamic scene changes or with more diverse real-world indoor environments beyond datasets tested?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners exploring spatial perception and AI-powered scene understanding, LEXI-SG offers an approach to extract complex semantic and geometric spatial graphs solely from monocular RGB data without specialized depth or inertial inputs. This can inform designs where minimal sensor setups are preferred yet rich environment representations are needed. The room-aware batching strategy to manage scalability and scale consistency without repeated overlapping submaps may inspire analogous approaches to maintain integrity in streaming multi-modal inference or multi-entity tracking scenarios. Furthermore, the integration of foundation models for open-vocabulary semantic segmentation illustrates how large pretrained models can augment spatial understanding in practical visual pipelines.
However, despite promising monocular inputs, limitations remain in precision of segmentation in open or ambiguous spaces, and accuracy ceiling imposed by feed-forward reconstructions. Such constraints should be considered when deploying these methods in security-critical or real-time applications like CAPTCHAs, where robustness across environment variability and potential spoofing must be ensured. Future improvements to address geometric cues or active optimization align with interests in reliability and scalability of bot defenses leveraging scene understanding.
Cite
@article{arxiv2605_13741,
title={ LEXI-SG: Monocular 3D Scene Graph Mapping with Room-Guided Feed-Forward Reconstruction },
author={ Christina Kassab and Hyeonjae Gil and Matías Mattamala and Ayoung Kim and Maurice Fallon },
journal={arXiv preprint arXiv:2605.13741},
year={ 2026 },
url={https://arxiv.org/abs/2605.13741}
}