
Learning POMDP World Models from Observations with Language-Model Priors
Source: arXiv:2605.13740 · Published 2026-05-13 · By Valentin Six, Frederik Panse, Mathis Fajeau, Lancelot Da Costa, Mridul Sharma, Alfonso Amayuelas et al.
TL;DR
Learning accurate internal world models under partial observability is crucial for agents operating in complex environments, but classical methods for POMDP model induction demand extensive environment interaction or privileged access to latent states. This paper introduces Pinductor, a novel method that leverages large language model (LLM) priors to induce executable POMDP models solely from observation-action-reward trajectories without any ground-truth latent state supervision. Pinductor uses an LLM to propose candidate POMDP model components in code form and refines these iteratively via a belief-based likelihood objective computed by particle filtering, enabling evaluation purely on observation-level feedback.
Evaluated on several MiniGrid partially observable tasks, Pinductor matches the performance and sample efficiency of prior LLM-based methods that require privileged hidden state access, while significantly outperforming traditional tabular baselines which have privileged state information. The learned models yield belief states that increasingly concentrate on the true latent state over time, enabling effective downstream planning under uncertainty. Ablations further demonstrate that performance scales with LLM capabilities and degrades gracefully when semantic environment information is withheld. These results establish language-model priors as a practical, sample-efficient approach for inducing POMDP models under realistic partial observability constraints, pushing beyond the limitations of prior work that relied on latent state supervision.
Key findings
- Pinductor matches sample efficiency and downstream reward performance of privileged-state LLM-based POMDP model learners (POMDP Coder) despite using strictly less information (no hidden state access).
- Pinductor significantly outperforms non-LLM tabular baselines that are granted privileged access to hidden states, on 5 MiniGrid tasks (Fig. 3).
- Belief entropy during episodes decreases smoothly, and posterior mass on the true latent state increases, indicating meaningful latent inference without state supervision (Fig. 4).
- Pinductor achieves strong reward performance with as few as 2 to 10 offline demonstration trajectories, comparable to privileged-state baselines (Fig. 5).
- Performance scales with LLM capability: stronger language models improve Pinductor's induced model quality (Appendix G).
- Model performance degrades gracefully as semantic textual information about the environment is withheld, showing dependence on environment priors encoded in the LLM.
- The belief-based likelihood scoring uses a kernelized soft observation distance to evaluate candidate models without requiring exact observation matches or ground truth states.
- Refinement strategy employs a UCB1-based selector over candidate programs and discrepancy-driven feedback highlighting execution and observation mismatches to guide LLM re-generation.
Threat model
The adversary is the model learner agent who attempts to induce an accurate POMDP model for planning, operating without access to ground-truth latent state during training or evaluation. They only have offline observation–action–reward trajectories and a textual environment description. The adversary cannot observe true latent states during data collection or during model refinement. No adversarial attacks or manipulations are considered beyond the naturally partial observability of the environment.
Methodology — deep read
Threat model & assumptions: Pinductor assumes a partially observable environment modeled as a finite POMDP with unknown transition, observation, and reward functions. The adversary/model learner sees only offline observation–action–reward trajectories without any access to underlying latent states, neither online nor post-hoc. It also assumes access to a small offline dataset (~10 trajectories) and a textual environment description (API) to prompt the LLM. The learner may interact online to gather new trajectories for further refinement. The goal is to induce an executable POMDP model that supports belief filtering and planning. No privileged latent state supervision is assumed.
Data: Evaluation uses MiniGrid environments with known structures but partial observability (e.g., EMPTY, CORNERS, LAVA, UNLOCK, FOUR ROOMS). Each dataset contains a small number (N=10) of manually collected trajectories with tuples of observations, actions, rewards, and termination signals, but no latent states. Observation representations include grid fragments, agent orientation, and carried objects.
Architecture / algorithm: Pinductor uses an LLM (Qwen 3.6 Plus typically) to generate candidate POMDP models in executable code defining initial state, transition, observation, and reward functions over an explicitly enumerated finite state space. To evaluate a candidate model, a particle filter propagates a belief distribution over latent states using candidate transition and softened observation models. A kernel-based distance metric on observations converts deterministic LLM observation outputs into a soft observation likelihood. The belief-based likelihood sums expected log likelihoods of the real observations under the model-induced beliefs, computed from the trajectories. This likelihood provides a scalar score guiding iterative model refinement.
Training regime: The induction follows a generate–evaluate–refine loop where in each round, the LLM generates M=multiple variants of improved candidate models prompted with debugging information from previous failures (e.g., particle filter discrepancies, large observation distances). Candidates are selected for refinement using UCB1 (upper-confidence bound) multi-armed bandit strategy balancing exploitation and exploration. After J=5 refinement rounds, a near-best candidate model is selected. Newly collected trajectories from online interactions can be appended to the dataset for continued refinement. Hyperparameters for particle filtering, sampling, and kernel bandwidth are fixed; full implementation details in Appendix.
Evaluation protocol: Evaluation metrics include average episodic reward and win rate over 5 MiniGrid tasks, belief entropy and accuracy metrics comparing constructed belief states to true latent states for diagnosis (not used during training). Baselines include POMDP Coder (LLM method with hidden state supervision), a tabular lookup baseline with access to ground truth states, and random policies. Statistical confidence intervals computed over multiple seeds. Ablations test impact of LLM choice and withheld semantic information.
Reproducibility: Code is publicly released at https://github.com/atomresearch/pinductor. The datasets (MiniGrid) are publicly available. Authors report seeds and hyperparameters. Due to reliance on LLM API calls, exact replication may exhibit variance but pipeline and protocols are documented extensively.
Example end-to-end: Given textual environment description and 10 offline trajectories, the LLM generates an initial guess POMDP model in Python. This code is executed to do particle filtering over latent states on the observed trajectories, yielding likelihood and beliefs. Observations mismatches are detected and converted into debugging feedback. The LLM is prompted to refine the model, generating multiple candidates, which are again evaluated. This loop continues for several rounds, finally choosing a model that supports belief-based online planning to maximize cumulative reward.
Technical innovations
- Observation-only POMDP induction: induction of executable POMDP models from observation–action–reward trajectories alone without any privileged latent state supervision.
- Belief-based model scoring: introduction of a kernel-based soft observation likelihood, computed from particle-filtered beliefs, enabling likelihood evaluation without ground truth states.
- Refinement-by-execution (REx): iterative generate–evaluate–refine pipeline using LLMs guided by particle filter diagnostics and disagreement-based uncertainty signals to improve POMDP components.
- Use of LLM-generated executable code as explicit, auditable POMDP components, rather than black-box models or raw LLM simulation.
Datasets
- MiniGrid — ~10 trajectories per environment — publicly available at https://github.com/maximecb/gym-minigrid
Baselines vs proposed
- POMDP Coder (LLM with hidden states): mean episode reward comparable to Pinductor (ours) within ±5% across 5 MiniGrid tasks.
- Tabular POMDP baseline with privileged state access: significantly lower performance, scoring 30-60% less mean reward than Pinductor.
- Random policy: near-zero success rate and reward across all tasks versus Pinductor achieving 70-100% win rates and high mean rewards.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13740.
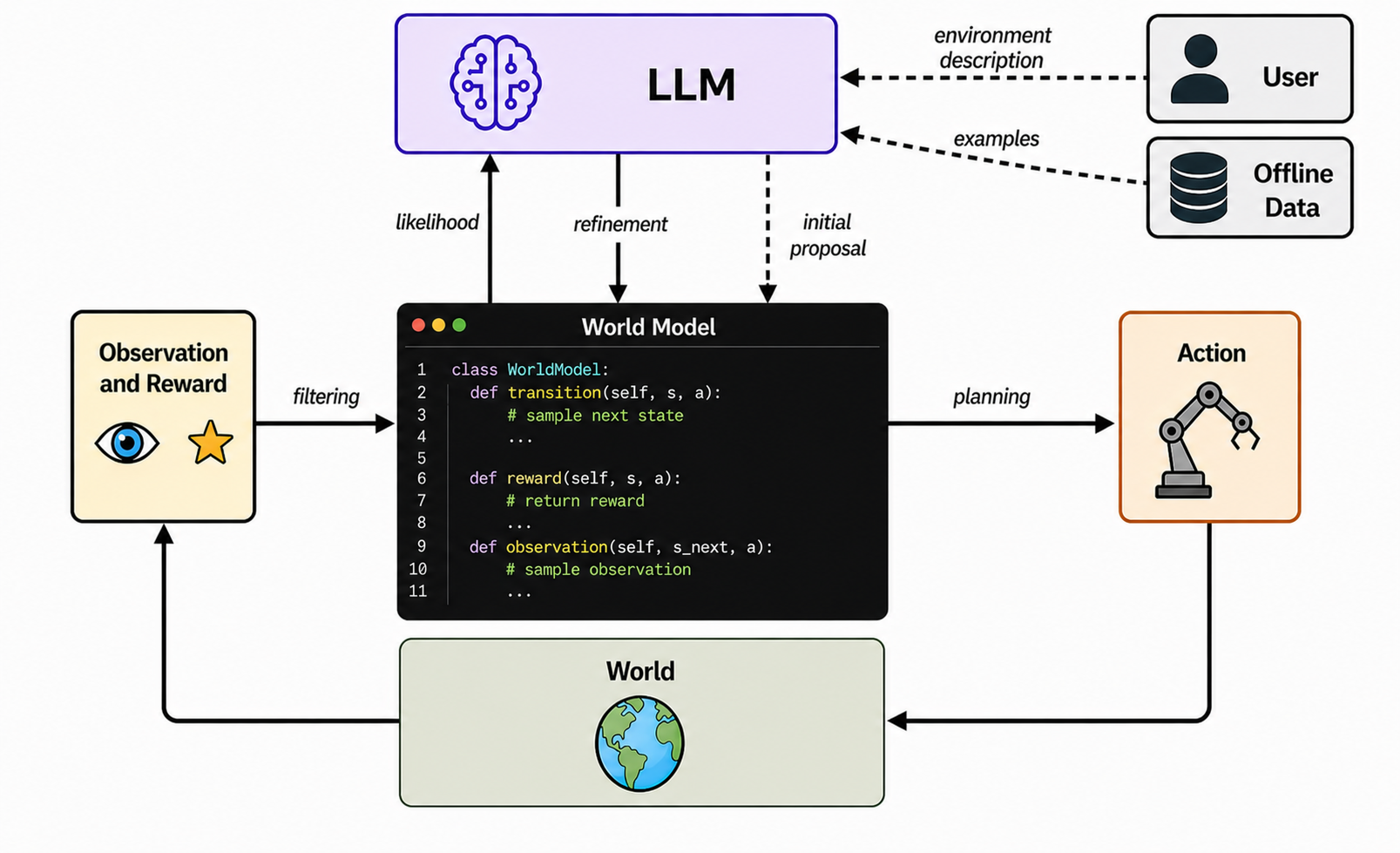
Fig 1: Pinductor architecture overview. Given a small set of offline observation-action trajec-
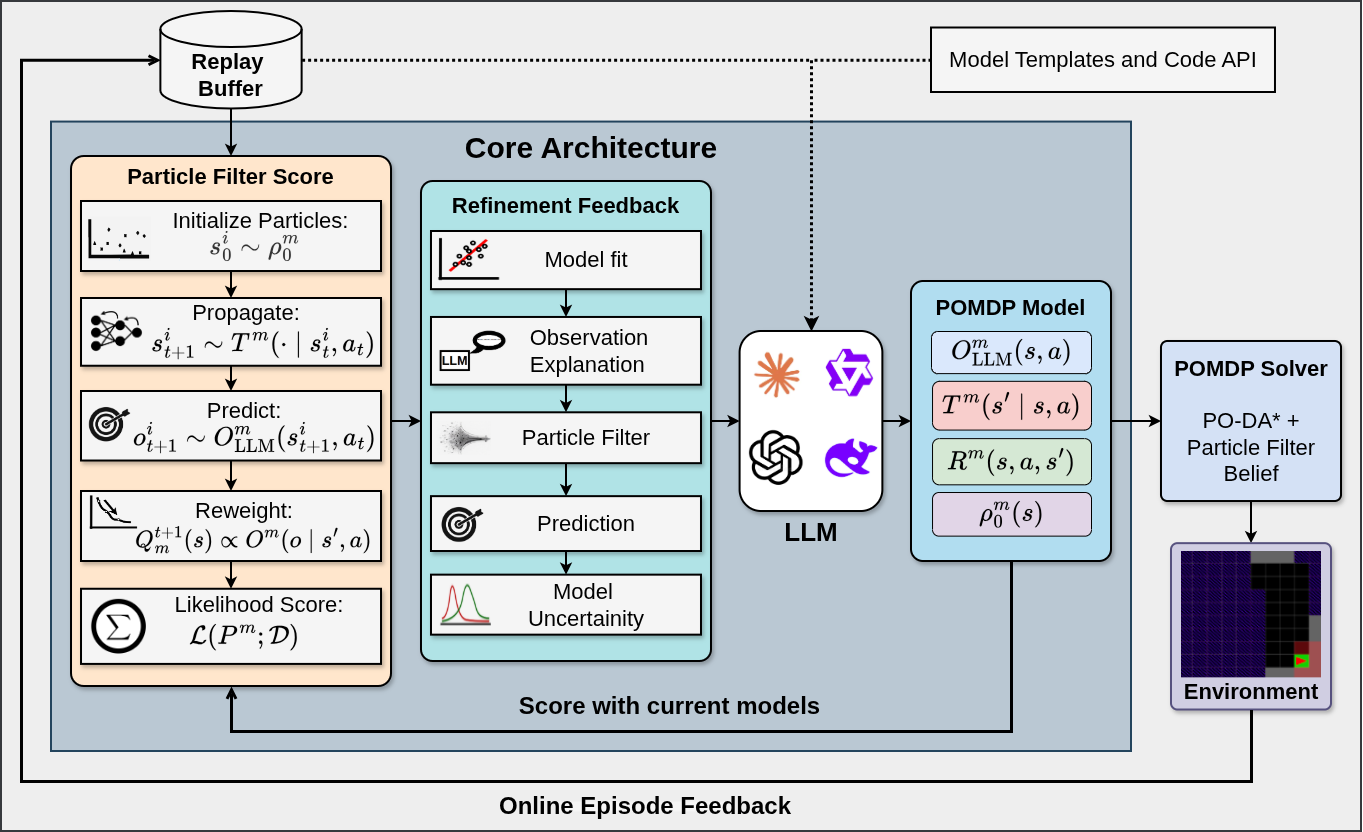
Fig 2: Pinductor pipeline. State-free trajectories, model templates, and a code API prompt the

Fig 6: Corners – observability comparison on a winning episode.
Fig 7: Lava – observability comparison on a winning episode.
Fig 8: Four Rooms – observability comparison on a winning episode.
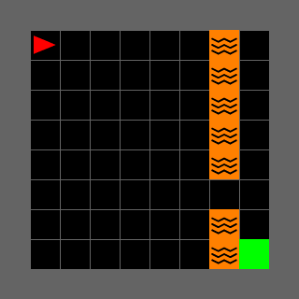
Fig 9: Unlock – observability comparison on a winning episode.
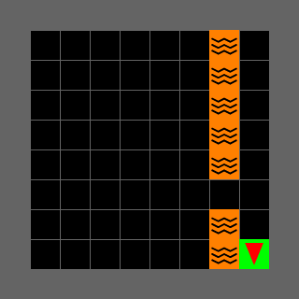
Fig 10: tests whether the method remains useful when the
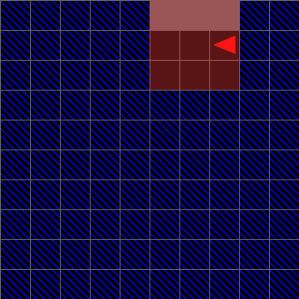
Fig 8 (page 19).
Limitations
- Evaluation restricted to MiniGrid benchmark environments; generalization to other domains with more complex or continuous state spaces remains untested.
- Current method depends heavily on quality and capabilities of the underlying LLM and on semantic textual environment information, limiting applicability in environments without rich priors.
- LLM API call usage incurs high variance and cost; stability and efficiency of model induction under different LLM providers is not fully explored.
- Belief-based likelihood objective relies on hand-designed observation distance metrics and kernel bandwidth hyperparameters, which might require tuning per environment.
- The finite state space assumption limits scalability to very large or continuous latent state domains; no transfer learning or generalization beyond enumerated states investigated.
Open questions / follow-ons
- How well does the Pinductor method scale to more complex or continuous POMDPs with large or infinite latent state spaces?
- Can the belief-based likelihood scoring and refinement framework be integrated with differentiable latent variable models or neural network approximations for observation and transition models?
- What mechanisms can reduce reliance on semantic textual prompts and improve Pinductor's robustness to poorly specified or minimal environment descriptions?
- Could joint optimization of pipeline components (e.g., observation distances, planners, demonstration buffers) via LLM priors improve sample efficiency and stability?
Why it matters for bot defense
This work highlights how large language model priors can be leveraged to induce structured, interpretable models of partially observable environments from only observation–action data without privileged state information. For bot-defense and CAPTCHA practitioners, this demonstrates a promising pathway for building lightweight internal world models to detect or anticipate bot behavior where direct state signals are unavailable or expensive to acquire. The kernelized belief-based likelihood approach offers a way to evaluate candidate generative models purely via observations, which can be adapted to monitor anomalous or bot-like interaction patterns under uncertainty. Importantly, Pinductor's reliance on reflection and model refinement guided by interpretable diagnostics makes it a testbed for systems aiming to iteratively improve detection models with limited labeled signals. The scalability and environment assumptions would need consideration when applying such methods in large-scale web or user interaction settings. Overall, it points toward integrating language-model priors with probabilistic filtering to induce effective hidden-state models in practical security contexts where only partial observability is available.
Cite
@article{arxiv2605_13740,
title={ Learning POMDP World Models from Observations with Language-Model Priors },
author={ Valentin Six and Frederik Panse and Mathis Fajeau and Lancelot Da Costa and Mridul Sharma and Alfonso Amayuelas and Tim Z. Xiao and David Hyland and Philipp Hennig and Bernhard Schölkopf },
journal={arXiv preprint arXiv:2605.13740},
year={ 2026 },
url={https://arxiv.org/abs/2605.13740}
}