
Interpretable Machine Learning for Antepartum Prediction of Pregnancy-Associated Thrombotic Microangiopathy Using Routine Longitudinal Laboratory Data
Source: arXiv:2605.13786 · Published 2026-05-13 · By Chuanchuan Sun, Zhen Yu, Qin Fan, Qingchao Chen, Feng Yu
TL;DR
This study addresses the difficult problem of early antepartum prediction of pregnancy-associated thrombotic microangiopathy (P-TMA), a rare but life-threatening syndrome characterized by microvascular thrombosis and renal damage in pregnancy. Early prediction is challenging due to the subtle, multidimensional, and physiologically confounded laboratory abnormalities that precede overt clinical symptoms. The authors propose an interpretable machine learning framework leveraging routine longitudinal clinical laboratory data collected across gestational weeks 6–32 to extract latent time-dependent risk signatures not visible to traditional rule-based or univariate methods.
Using a retrospective cohort of 300 pregnancies (142 P-TMA cases, 158 controls) and 146 longitudinal laboratory predictors, they evaluated multiple machine learning models with gradient boosting selected as the final model based on cross-validated AUROC on the training set. The gradient boosting model achieved strong performance in a held-out test cohort (AUROC 0.872, AUPRC 0.883) with balanced sensitivity (0.75) and specificity (0.812). Interpretability analyses highlighted a clinically coherent temporal cascade of predictors including early gestational cystatin C and uric acid (renal markers), second-trimester neutrophil counts (inflammatory shifts), biochemical injury markers like LDH, and late gestational hemoglobin and creatinine (renal impairment and anemia). This suggests that routine antenatal lab data contain actionable early signals for P-TMA risk, and cystatin C at week 6 emerged as a particularly promising early marker. The study establishes a methodological foundation for earlier identification of high-risk pregnancies before clinical deterioration, which could enable better surveillance and intervention strategies.
Key findings
- Gradient boosting model achieved AUROC of 0.872 (95% CI: 0.769–0.952) and AUPRC of 0.883 (95% CI: 0.780–0.959) on held-out test cohort.
- Model sensitivity was 0.750 and specificity was 0.812 at threshold selected by Youden index on training folds.
- Top predictor was cystatin C at gestational week 6 (CysCVI), with highest normalized importance (0.157) and significant upward shift in P-TMA cases (p < 0.001).
- Other key predictors included uric acid at week 6 (UAVI, importance 0.119), hemoglobin at week 32 (HbXXXII, importance 0.068), neutrophils at week 16 (NeuXVI, importance 0.038), lactate dehydrogenase at week 6 (LDHVI, importance 0.031), and creatinine at week 24 (CrXXIV, importance 0.030).
- Bootstrap 95% confidence intervals show robust performance metrics despite relatively small sample size of 60 in test set.
- Decision curve analysis demonstrated net clinical benefit across relevant risk thresholds compared to treat-all or treat-none strategies.
- Extra trees model achieved numerically higher AUROC (0.896) and AUPRC (0.914) but gradient boosting was selected a priori.
- The model integrated multi-timepoint longitudinal predictors spanning renal, hematologic, inflammatory, and biochemical domains capturing temporal risk trajectories not apparent to univariate rules.
Threat model
n/a (this is a clinical prediction and diagnostic research study focusing on early detection of P-TMA in pregnant women, not a cybersecurity or adversarial setting).
Methodology — deep read
Threat model & assumptions: The adversary context is clinical rather than security-focused: predicting rare P-TMA among pregnant women before symptoms emerge using routinely collected lab data. The model must separate subtle pathological signals from physiological pregnancy changes and overlapping benign conditions. There is no explicit adversarial attempt to deceive but the challenge stems from noisy, confounded EHR data.
Data: The retrospective data cohort consisted of 300 pregnancies from a single center, including 142 P-TMA cases and 158 controls. Data included 146 longitudinal laboratory predictors after preprocessing to remove identifiers, redundant variables, and those with potential label leakage. The labs spanned hematology, renal function, liver injury, urinalysis, inflammatory, and biochemical markers collected at gestational weeks 6, 12, 16, 24, 28, 30, and 32. The cohort was split 80:20 into training (240) and held-out test set (60) using stratified sampling to preserve prevalence.
Preprocessing involved median imputation and standardization for continuous variables and mode imputation plus one-hot encoding for categoricals, performed within training folds for no data leakage.
- Architecture / algorithm: Five canonical classifiers were evaluated: logistic regression, support vector machine with RBF kernel, random forest, extra trees, and gradient boosting (likely an implementation like XGBoost or LightGBM, though not explicitly stated). Gradient boosting was preselected for reporting based on highest mean cross-validated AUROC on training data.
Input features were flattened longitudinal lab values with feature names encoding weeks (e.g., CysCVI for cystatin C at week 6). The model automatically learned nonlinear interactions and temporal patterns.
Training regime: Hyperparameter tuning was performed via randomized search with five-fold stratified cross-validation on the training set. Exact hyperparameter values and number of epochs are not stated (typical gradient boosting models do not use epochs but number of trees and learning rate). Batch size is not applicable. Training hardware and random seeds are not specified.
Evaluation protocol: The model was retrained on the full training cohort with tuned hyperparameters and evaluated once on the held-out 20% test set. Performance metrics included AUROC, AUPRC, accuracy, sensitivity, specificity, PPV, NPV, F1, Brier score, and expected calibration error (ECE). Confidence intervals were estimated using 1000-bootstrap resampling of the test cohort. Calibration curves and decision curve analysis evaluated clinical utility.
No external validation or distribution shift testing was performed. No adversarial robustness tests.
- Reproducibility: The authors provide a reproducible modeling pipeline implemented in Python. Data are not publicly available but may be requested. Code availability is implied but not explicitly confirmed. No pretrained weights are applicable as this is tabular data.
Example end-to-end flow: A given patient's longitudinal labs (e.g., cystatin C at week 6, uric acid at week 6, neutrophils at week 16, etc.) are fed as numerical features into the trained gradient boosting model, which outputs a risk probability for P-TMA. A threshold determined from training Youden index classifies the patient as high or low risk. Global feature importance and SHAP-like analyses allow clinicians to interpret which labs and time points drove the prediction, enabling trust and clinical insight.
Technical innovations
- Use of comprehensive longitudinal antenatal laboratory data from multiple gestational timepoints to model multi-axis temporal risk trajectories for P-TMA, going beyond cross-sectional or single timepoint approaches.
- Application of interpretable gradient boosting models with temporal feature encoding to extract latent nonlinear interactions obscured by physiological pregnancy changes.
- Integration of explainability analyses linking model decisions to clinically plausible multistage pathophysiological markers (renal, inflammatory, hematologic) aligned with P-TMA progression.
- Rigorous modeling workflow preserving test set integrity by preselecting final model on training folds to avoid test-set-driven model selection bias.
Datasets
- Pregnancy-associated thrombotic microangiopathy cohort — 300 pregnancies (142 cases, 158 controls) — single-center retrospective clinical dataset from Peking University International Hospital
Baselines vs proposed
- Logistic regression: AUROC = 0.834 vs Gradient boosting: 0.872 (held-out test)
- SVM (RBF kernel): AUROC = 0.798 vs Gradient boosting: 0.872
- Random forest: AUROC = 0.863 vs Gradient boosting: 0.872
- Extra trees: AUROC = 0.896 vs Gradient boosting: 0.872 (Extra trees had higher AUROC but gradient boosting was chosen a priori)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13786.
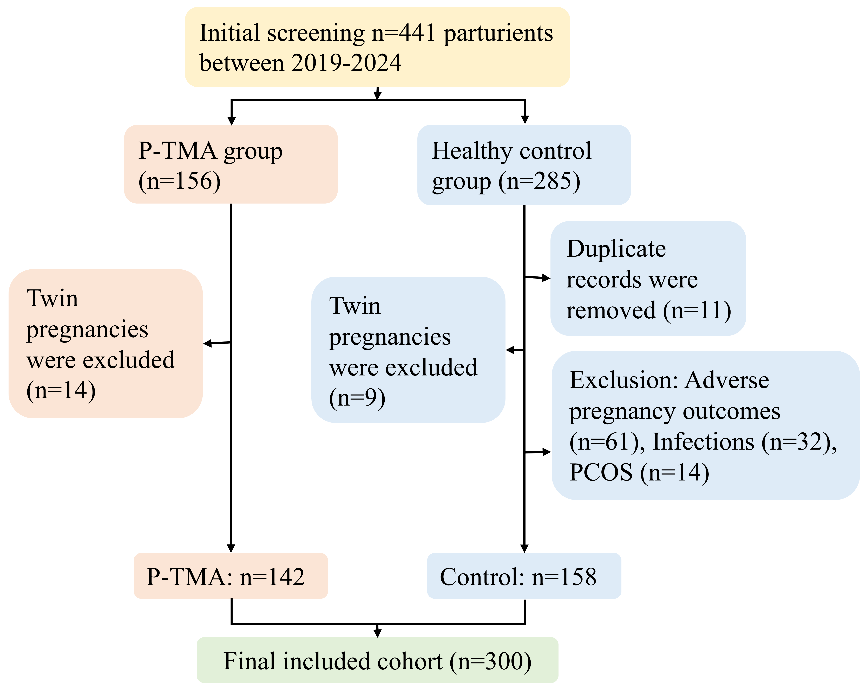
Fig 1: Flow diagram of study participant selection. The final analytic cohort included 142 P-
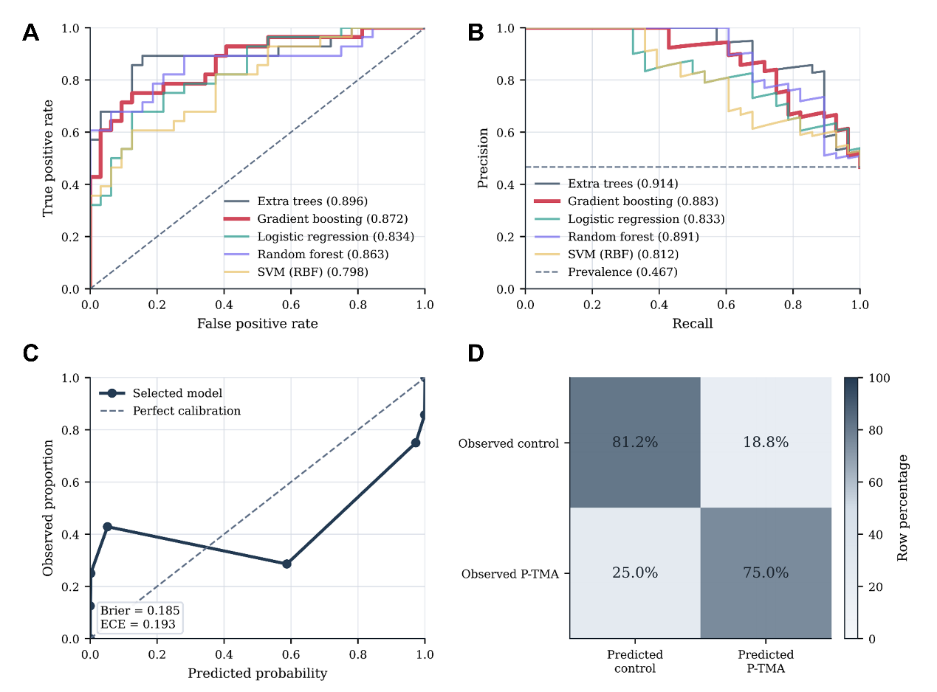
Fig 2: summarizes test-cohort discrimination, precision-recall performance, calibration,
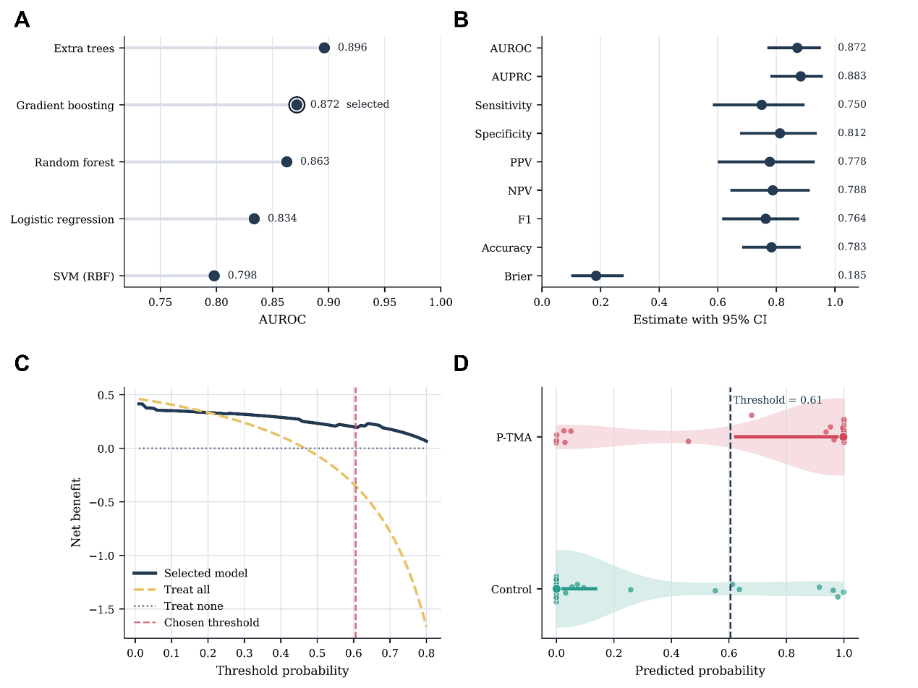
Fig 3: Held-out test utility and selected-model performance. (A) Held-out test AUROC across
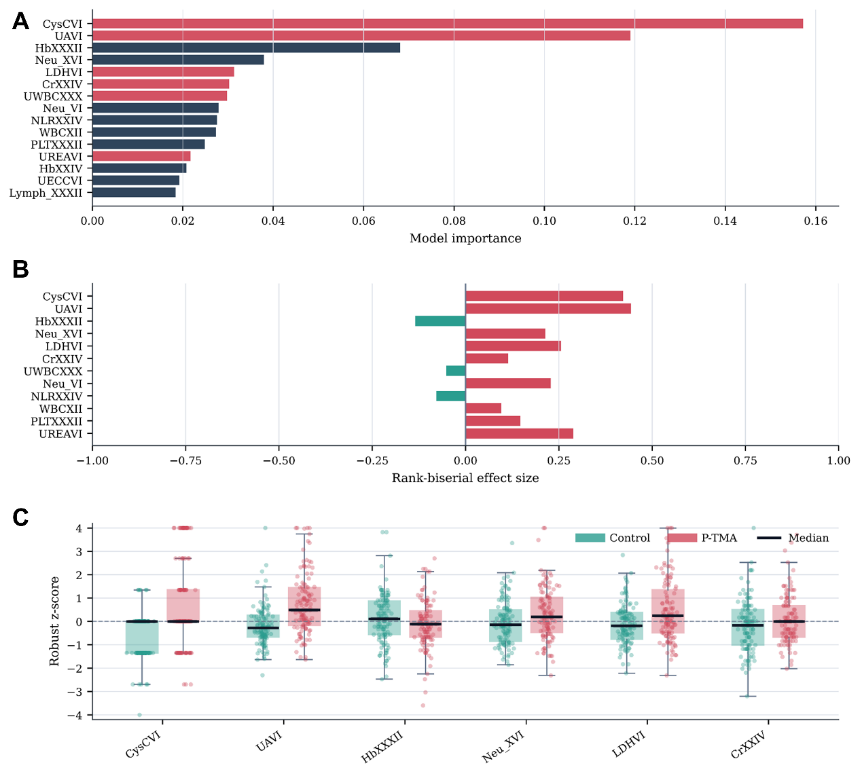
Fig 4: Model interpretation and leading laboratory signatures. (A) Top predictors of the selected
Limitations
- Single-center retrospective study limits generalizability; external and prospective validation needed.
- Sample size, while comparatively large for a rare disease, is still modest (300 total, 60 held-out test), which constrains confidence in rare P-TMA subtype predictions.
- Calibration performance shows room for improvement and needs evaluation on external cohorts due to risk of calibration drift across institutions.
- The model uses fixed, discrete gestational week snapshots and does not fully leverage temporal data irregularity or dynamics; sequential models like LSTMs or Transformers could improve this.
- No assessment was made of model robustness to missingness variations or perturbations nor adversarial attacks.
- The dataset is not publicly available, limiting reproducibility and independent benchmarking.
Open questions / follow-ons
- How will the model generalize across diverse populations, institutions, and laboratory platforms? Prospective external validation is required.
- Can dynamic temporal models (e.g., LSTMs, Transformer-based architectures) better capture irregular sampling and complex longitudinal trajectories to improve prediction?
- What is the clinical impact on maternal-fetal outcomes if the model is integrated into decision-support workflows for early risk surveillance and intervention?
- Can federated privacy-preserving learning approaches leverage multicenter data to improve model robustness without exposing patient-level data?
Why it matters for bot defense
While this work focuses explicitly on clinical prediction for a rare pregnancy complication using longitudinal health data, the principles are relevant to bot-defense and CAPTCHA contexts insofar as they demonstrate how interpretable machine learning can extract subtle, distributed signals from high-dimensional longitudinal features. The emphasis on preserving temporal ordering and resolving confounders could inspire bot detection algorithms that analyze behavioral timelines or multi-modal telemetry instead of static snapshots. Interpretability methods used to relate model decisions back to domain-understandable variables are relevant to transparent bot-detection models. Finally, the rigorous evaluation and avoidance of data leakage pitfalls underscore best practices applicable to presentation attack detection and other adversarial settings. However, direct technical overlap is limited, and bot-defense engineers would need to adapt the approach from clinical labs to richer behavioral or network data.
Cite
@article{arxiv2605_13786,
title={ Interpretable Machine Learning for Antepartum Prediction of Pregnancy-Associated Thrombotic Microangiopathy Using Routine Longitudinal Laboratory Data },
author={ Chuanchuan Sun and Zhen Yu and Qin Fan and Qingchao Chen and Feng Yu },
journal={arXiv preprint arXiv:2605.13786},
year={ 2026 },
url={https://arxiv.org/abs/2605.13786}
}