
Identifying AI Web Scrapers Using Canary Tokens
Source: arXiv:2605.13706 · Published 2026-05-13 · By Steven Seiden, Triss Ren, Caroline Zhang, Taein Kim, Enze Liu, Emily Wenger
TL;DR
This paper addresses the challenge of identifying which web scrapers feed data to large language models (LLMs) during real-time content retrieval, a poorly understood and important problem for website owners wishing to control AI-related scraping. Existing identification methods based on self-reported User-Agent strings or crowdsourced data are neither reliable nor scalable. The authors propose a novel, automated fingerprinting technique employing canary tokens embedded in served web content to uniquely tag different scrapers. By querying 22 production AI chatbots with prompts designed to elicit knowledge of these tokens, they infer links between scrapers and LLMs based on the tokens observed in chatbot responses. The method reveals surprisingly diverse scraping behaviors, including scraper User-Agent spoofing, multiple User-Agents per LLM, use of cached content, and ineffective blocking by robots.txt or site takedowns.
The study hosts 20 dynamic websites containing unique, stable token variants per scraper distinguished by User-Agent and ASN. They systematically probe leading AI chatbots, collecting and mapping canary tokens returned in answers to known scrapers. This evidence allows new attribution of scrapers to LLMs, including several scrapers and models not publicly disclosed. Key findings highlight real-world limitations of bot access controls against AI scrapers and demonstrate a scalable, unprivileged measurement approach for linking scrapers with AI content consumers. This work opens new avenues for transparency and defensive controls in AI web scraping ecosystems.
Key findings
- By serving unique canary tokens to each scraper identified via User-Agent and ASN, the study matched scraper tokens to outputs from 22 production AI chatbots, revealing previously unknown scraper-to-LLM relationships.
- Many AI chatbots use User-Agents that mimic regular browsers and rotate through multiple generic User-Agent strings, thwarting simple User-Agent based scraper identification.
- Blocking AI scrapers using robots.txt directives proved largely ineffective at preventing website content from appearing in chatbot outputs, likely due to crawling caching or non-compliance with the protocol.
- AI chatbots frequently rely on cached content indexed by third-party search engines rather than exclusively performing live web retrieval.
- The study’s threshold of requiring at least two distinct tokens seen in multiple website queries limits false positives, leading to high confidence in attribution (estimated collision probability ~1 in a million).
- A response from an AI chatbot containing multiple scraper-unique tokens from different scrapers suggests some chatbots integrate multiple scraping sources.
- Removing websites from the internet after initial scraping does not reliably prevent contents from appearing in LLMs, due to caching mechanisms.
- 20 websites and 200 distinct canary tokens allowed robust scraped data attribution across diverse scrapers.
Threat model
The adversary is a website owner with no privileged access to AI chatbot internals who wishes to infer which external web scrapers are feeding content to various LLMs. Scrapers may attempt to conceal identity by spoofing User-Agent strings or rotating IPs, but are assumed to be exposed to the website owner’s canary token injection. The adversary cannot directly access the AI chatbot’s training or indexing infrastructure, only interacting via queries.
Methodology — deep read
Threat Model & Assumptions: The adversary is a website owner seeking to identify which web scrapers feed data into AI chatbots to enforce scraping restrictions. The adversary can serve web content with unique tokens and query AI chatbots but has no privileged access to the internal LLM systems or scraping pipelines. AI scrapers may spoof User-Agents, use IP rotation, cache content, and resist blocking.
Data: Authors created 20 distinct websites hosted on Google Cloud, each with unique content templates embedding 10 canary token placeholders. Tokens were drawn from large pools (>1000 distinct values per token) to reduce accidental collisions. Each unique scraper, defined by a unique User-Agent + ASN tuple, was served a stable, distinct token set on all 20 sites. The sites returned fabricated, non-overlapping person/company profiles to avoid false matches with real entities. The authors indexed these sites via Google, Bing, and Brave to improve discoverability.
Architecture / Algorithm: The approach has three core phases: (a) Canary token generation and dynamic content serving: unique token sets assigned to scrapers based on fingerprinting (User-Agent + ASN), filling content templates; (b) AI Chatbot querying, using carefully designed prompts to elicit knowledge of websites and canary tokens; (c) Scraper inference, extracting tokens from chatbot outputs via regex/text matching and mapping tokens to scrapers.
Each token uniquely identifies a scraper. Matching decision used a threshold requiring at least two matching tokens seen over at least one distinct website query iteration to limit false positives. This exploits the compositional uniqueness of multiple tokens.
Training Regime: n/a — no ML training involved. The work is a measurement and inference methodology.
Evaluation Protocol: The authors interacted with 22 production AI chatbots (including major industry and research models). They issued multiple queries per chatbot to elicit outputs referencing their deployed websites. The authors parsed chatbot outputs for token matches and aggregated evidence across multiple sites and queries. They examined bot User-Agent rotation by observing scraper behavior. Evaluation included control experiments on the impact of robots.txt and site takedown on token appearance. They ensured reproducibility of token assignment and mapped tokens to scrapers rigorously.
Reproducibility: The paper mentions 20 uniquely controlled websites and 200+ unique tokens, but does not explicitly state public code or datasets. The details of website templates, query prompts, and token mappings are described in appendices. Some fingerprints like ASN and User-Agent were used publicly, but no closed datasets. Overall, the methodology is replicable given described infrastructure.
Technical innovations
- Use of uniquely assigned canary tokens embedded in website content served dynamically per scraper to fingerprint scraper identity without relying on User-Agent honesty.
- Novel scraper-to-LLM attribution technique by querying chatbots to detect canary tokens in chatbot responses, enabling indirect inference of scrapers feeding each LLM.
- Combination of User-Agent plus Autonomous System Number (ASN) as a practical fingerprinting heuristic to identify unique scrapers for token assignment.
- Development of a robust matching algorithm requiring multiple distinct token observations across queries to control false positives in attribution.
Datasets
- 20 custom dynamic websites — dozens of instances — hosted on Google Cloud under researcher control (private)
- Token pool with at least 1000 distinct values per token — internally generated
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13706.
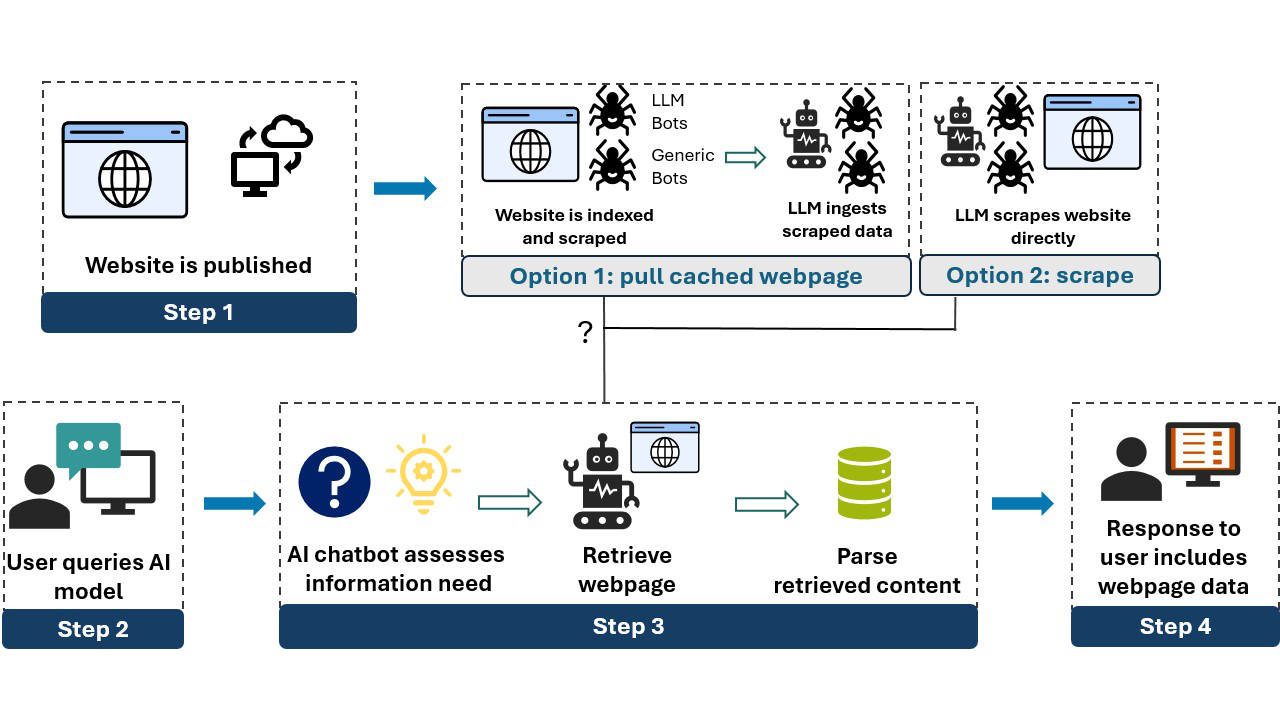
Fig 1: High-level overview of how web data is sourced during real-time content retrieval by AI chatbots.
Limitations
- Method depends on scrapers accessing the deployed canary token websites; scrapers not indexing these domains are undetectable.
- False negatives possible if chatbots access scraped content but do not emit any canary tokens—mitigated but not eliminated by multiple queries.
- Caching layers obscure whether AI systems retrieve content live or from search engine caches, making some attribution indirect.
- Fingerprinting based on User-Agent + ASN may group distinct scrapers together or fail to distinguish rotational identities fully.
- Study does not evaluate adversarial scraping or countermeasures scrapers might adopt to circumvent canary tokens.
- No explicit ground truth verification for scraper-LMM pairs; attribution relies on indirect inference from token observation.
Open questions / follow-ons
- Can adversarial scrapers detect and evade canary token insertion to defeat attribution?
- How do caching layers at search engines and AI model providers impact accuracy and timeliness of scraper inference?
- Can the methodology be extended to fingerprint scrapers without reliance on User-Agent or ASN features?
- What are the legal and ethical implications of deploying canary tokens and scanning AI chatbot outputs for attribution?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this research highlights the limitations of current scraper identification methods relying on self-reported User-Agent strings and underscores the complexity of AI-driven scraping detected across multiple layers, including spoofing and caching. The novel canary token methodology offers a promising measurement tool complementary to traditional heuristics for attributing scrapers to AI chatbots, potentially guiding more targeted access control mechanisms. Additionally, findings that robots.txt and site takedown are often ineffective suggest defenses cannot rely solely on standard web scraping controls. CAPTCHA engineers can consider integrating token-based or content provenance markers into their defensive tooling to better detect and attribute scraping tailored for feeding AI models, but must be aware of the evolving stealth techniques used by modern scrapers.
Cite
@article{arxiv2605_13706,
title={ Identifying AI Web Scrapers Using Canary Tokens },
author={ Steven Seiden and Triss Ren and Caroline Zhang and Taein Kim and Enze Liu and Emily Wenger },
journal={arXiv preprint arXiv:2605.13706},
year={ 2026 },
url={https://arxiv.org/abs/2605.13706}
}