
Force-Aware Neural Tangent Kernels for Scalable and Robust Active Learning of MLIPs
Source: arXiv:2605.13788 · Published 2026-05-13 · By Eszter Varga-Umbrich, Zachary Weller-Davies, Paul Duckworth, Jules Tilly, Olivier Peltre, Shikha Surana
TL;DR
This paper addresses crucial practical challenges in offline active learning for machine-learning interatomic potentials (MLIPs): scalability to large unlabeled candidate pools (~200k+ structures), leveraging both energy and force supervision in acquisition, and robustness to distributional bias in candidate pools. The authors introduce a novel acquisition pipeline combining a chunked feature-space posterior variance scoring to achieve linear scaling with candidate and training set sizes, alongside a Largest Cluster Maximum Distance (LCMD) diversity selection step. They extend Neural Tangent Kernels (NTKs) to be force-aware by incorporating mixed parameter-coordinate derivatives, yielding a force NTK and a joint energy-force NTK. Evaluations on the large-scale OC20 catalyst dataset show that the joint energy-force NTK acquisition significantly outperforms baseline approaches, including committee-based acquisition, achieving the lowest energy and force MAE/RMSE on both in-distribution and challenging out-of-distribution splits. Additional experiments across reactive molecular benchmarks T1x, PMechDB, and RGD confirm the competitive accuracy of force-aware NTKs while highlighting that force information is most critical in chemically diverse domains like OC20. Controlled candidate-pool bias studies demonstrate that representation-based NTK acquisition remains robust under distribution shifts where committee methods degrade. Finally, the paper analyzes the computational cost and memory footprint, showing the chunked feature-space method enables scalable acquisition with tractable resource requirements.
Key findings
- The chunked feature-space posterior variance acquisition scales linearly with candidate pool size nP and training set size nT, enabling screening of ∼200k candidate structures within hours on a single H100 GPU.
- The joint energy-force NTK acquisition achieves the lowest test energy and force MAE and RMSE on the large OC20 dataset across all distribution splits (in-distribution and three distinct out-of-distribution subsets).
- Energy-only NTK acquisition suffers degraded performance on some OC20 out-of-distribution splits (e.g., val_oos_ads), evidencing the importance of incorporating force information in heterogeneous chemical settings.
- On reactive benchmarks T1x, PMechDB, and RGD, force-aware NTKs remain competitive but do not consistently outperform energy-only NTKs; energy-based acquisition captures much of the informative variance in these less chemically diverse pools.
- Committee-based acquisition methods, including force-disagreement ensembles, exhibit higher variance and weaker average performance compared to NTK-based kernel methods on OC20 and reactive benchmarks.
- Under controlled candidate-pool shift experiments on T1x, NTK and pretrained embedding-based acquisition remain robust, whereas committee disagreement methods show increased variance and degraded robustness.
- Acquisition methods that combine posterior variance shortlisting with LCMD diversity outperform posterior variance alone, which otherwise performs near random selection at large pool sizes.
- Memory requirements for naive kernel-based methods grow quadratically with pool size, but chunked feature-space approaches maintain memory growth roughly linear in both pool size and feature dimension, shifting the bottleneck from dataset size to embedding dimension.
Threat model
n/a — This paper does not study adversarial threats or attacks on active learning but instead focuses on improving the practical reliability, scalability, and robustness of active learning acquisition in scientific ML for interatomic potentials.
Methodology — deep read
The authors study offline pool-based active learning (AL) with a fixed large unlabeled candidate set P(0) and a small labeled training set T(0). At each round t, a batch of size B candidates is selected for labeling and added to the training set, with the goal to minimize test errors after T rounds.
The primary challenges addressed are: (1) scaling acquisition to large candidate pools (~200k structures), (2) incorporating energy-force supervised signals from labels that include total energies and per-atom forces, and (3) maintaining robustness to distribution shift between candidate pool and test distribution.
The key algorithmic innovations include developing force-aware Neural Tangent Kernels (NTKs) by considering mixed parameter-coordinate derivatives (∇θ∇rEθ), enabling kernel similarity metrics sensitive to vector field (force) predictions. They define separate energy NTKs (NTK-E), force NTKs (NTK-F), and a combined energy-force NTK (NTK-EF) through weighted concatenation of embeddings. This yields kernels that capture both scalar energy and vector force sensitivities.
For acquisition, they estimate Gaussian posterior variance (PV) uncertainty in feature space (via explicit embeddings) instead of kernel matrices, allowing MV and test scores to be computed without materializing O(nP²) candidate candidate kernel matrices. They incrementally compute feature-space precision matrices MT = (ΦTᵀΦT + λI)^{-1} and score candidates in chunks, maintaining a running top-K shortlist.
Diversity is enforced post-shortlisting using Largest Cluster Maximum Distance (LCMD), a greedy farthest-point sampling method that selects diverse points from the top uncertainty subset to avoid redundant or outlier candidates.
Models are pretrained MACE neural MLIPs trained on large datasets (e.g., MPTraj). Fine-tuning occurs after each acquisition on the accumulated labeled data. The acquisition assembly thus combines pretrained learned representations with kernel-based uncertainty to select the next batch for labeling.
Evaluation is performed on multiple benchmarks: the large-scale OC20 catalyst dataset (~200k pool), smaller reactive chemical datasets T1x, PMechDB, and RGD, with both in-distribution and out-of-distribution splits to study distribution shift robustness. Metrics include energy and force MAE and RMSE, area under the acquisition curve (AUC), and final round errors averaged over multiple seeds. Ablations explore different parameter subsets for NTK embeddings and weighting of energy vs force signals.
Run-times and memory footprints are measured on a single H100 GPU, comparing to committee-based and fixed-descriptor baselines. Detailed kernel derivations and acquisition pseudocode are provided.
One end-to-end example: On OC20, with a 200k candidate pool and 2k initial labeled points, feature-space PV scores are computed chunkwise. The top 50k candidates form the shortlist, and LCMD selects a diverse batch of 1250 candidates for DFT labeling and model fine-tuning. Iterations continue for six rounds with evaluation on a 20k test set. The joint energy-force NTK combined with shortlist+LCMD achieves the lowest test errors across all splits, demonstrating scalability and robustness.
Technical innovations
- Extension of Neural Tangent Kernel to force prediction using mixed parameter-coordinate derivatives, allowing force-aware and joint energy-force NTK embeddings for vector field similarity.
- Chunked feature-space posterior variance acquisition method that avoids quadratic kernel matrix computations and scales linearly with candidate pool and training set sizes.
- Combining posterior variance-based uncertainty shortlisting with Largest Cluster Maximum Distance (LCMD) diversity selection to efficiently pick diverse and informative batches from large candidate pools.
- Demonstration that pretrained MLIP embeddings can serve as a robust, scalable foundation for active learning acquisition signals across diverse datasets and distribution shifts.
Datasets
- OC20 — Candidate pool ~200,000 structures — large-scale heterogeneous catalyst structures
- T1x — 100 reaction pathways, reactive molecular benchmark — public literature
- PMechDB — 10,000 candidate structures (HCNO-filtered) — molecular reactivity curated dataset
- RGD — 5,000 candidate structures — reactive molecular database subset
Baselines vs proposed
- Random: baseline MAE/RMSE as reported in Table 1 and Fig. 1
- Committee-E (energy disagreement ensemble): consistently weaker than NTK-EF on OC20, with higher variance
- Committee-F (force disagreement ensemble): also underperforms NTK methods, notably less robust under distribution shift
- Activation PV baseline: competitive on in-distribution splits but degrades on OC20 out-of-distribution splits compared to NTK-EF
- NTK-E (energy only): good baseline on reactive benchmarks but performs worse than NTK-EF on OC20 OOD splits
- NTK-F (force only): slightly behind NTK-EF but closely tracks performance, particularly helpful on chemically heterogeneous datasets
- NTK-EF (joint energy-force): lowest energy and force MAE / RMSE across all OC20 splits and competitive or better than baselines on reactive benchmarks
- Feature-space PV + LCMD batch selection outperforms PV alone which performs near random at large pool sizes
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13788.
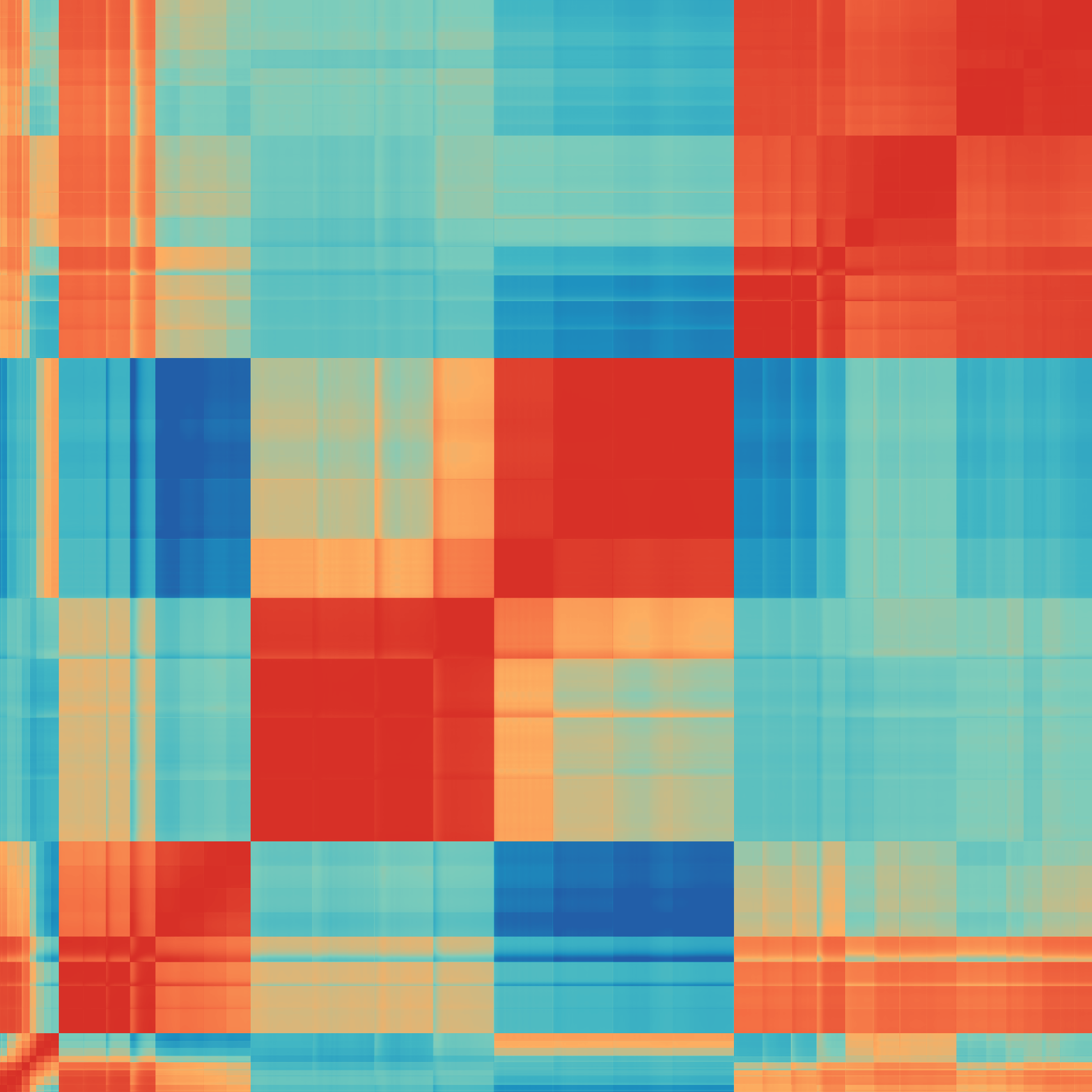
Fig 9: hints at the importance of how energy and force representations are combined in joint
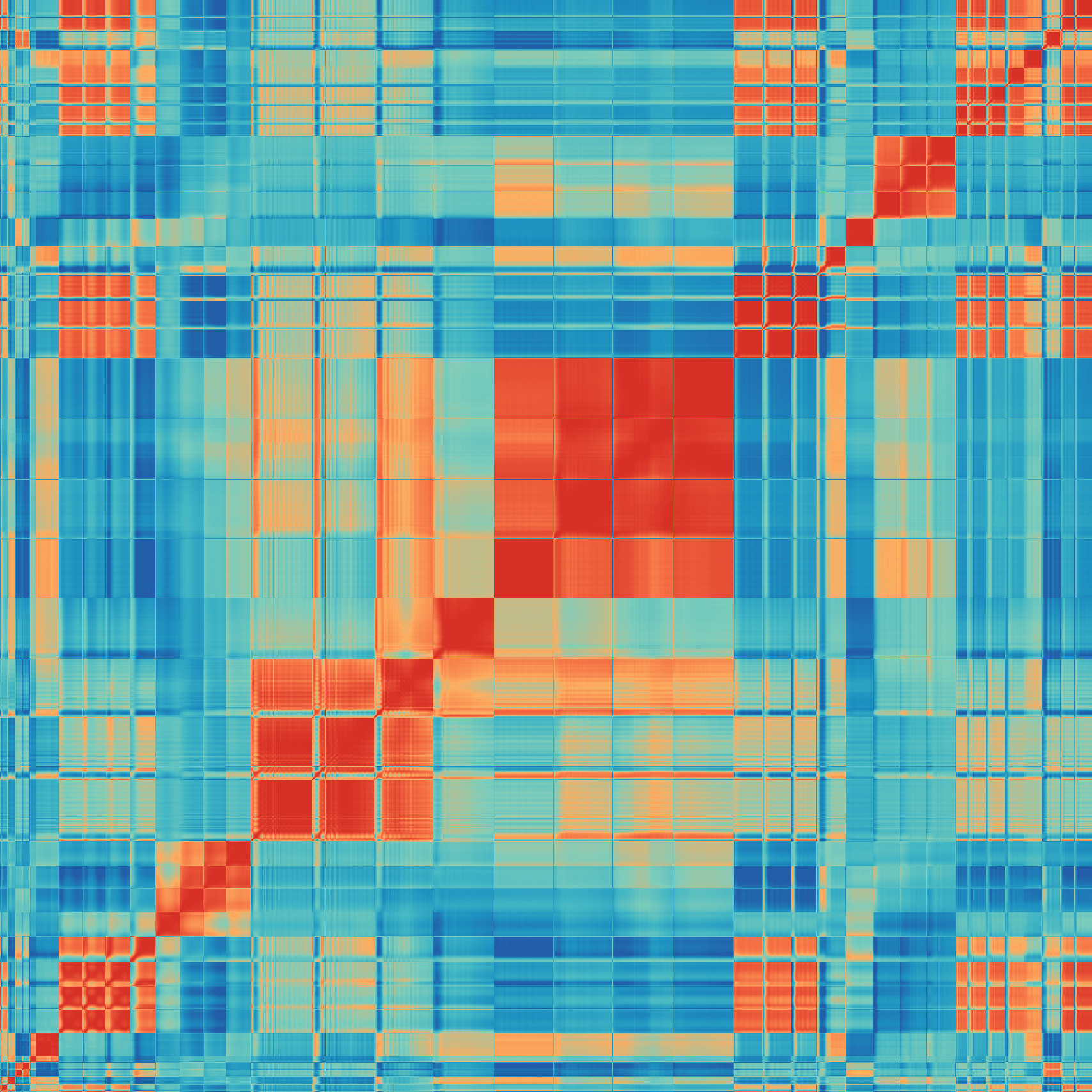
Fig 10: shows the AL learning curves on the 20,000-structure test set for the headline method
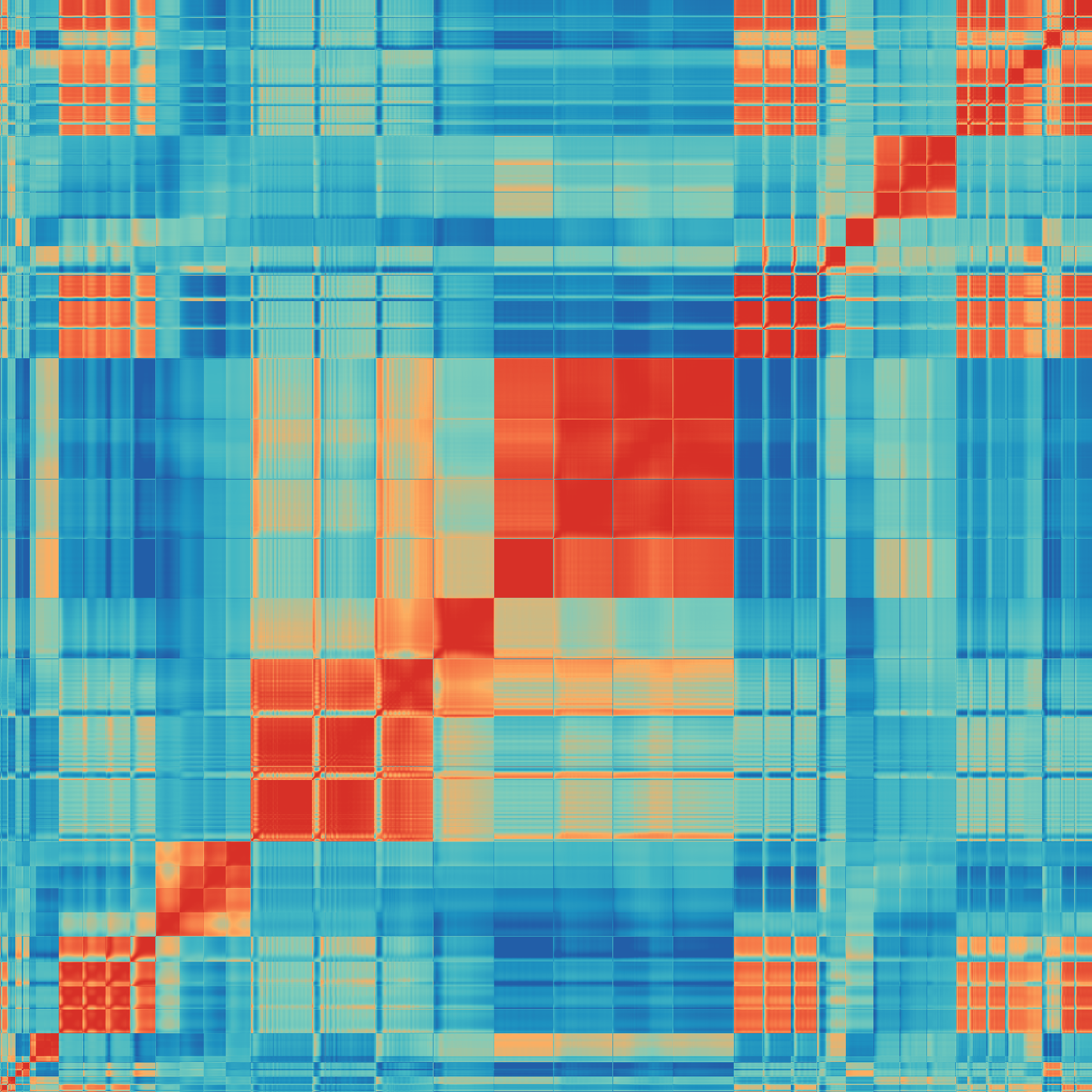
Fig 11: resolves the final-round test errors of Figure 1 into all four OC20 splits, rather than
Limitations
- Force-aware acquisition benefits are dataset-dependent; on reactive benchmarks force information adds limited improvement over energy-only acquisition.
- Though they tested robustness to candidate-pool bias, no adversarial or worst-case distribution shifts were considered.
- Force label noise is an unresolved factor — force component errors in underlying data can degrade force-aware acquisition reliability.
- NTK acquisition is constrained to lightweight parameter subsets to limit feature dimension; richer embeddings could improve but come at higher computational cost.
- The work focuses on pretrained MLIP backbones; performance and methods may not transfer straightforwardly to other architectures or training protocols without further validation.
- Committee-based ensemble baselines are limited to M=3 with simple initialization; advanced uncertainty methods (e.g., multi-head or Bayesian ensembles) were not evaluated.
Open questions / follow-ons
- Under which precise chemical or structural regimes does force-aware acquisition provide significant gains over energy-only acquisition?
- How can force and energy signals be optimally normalized or weighted for best acquisition performance?
- Can richer or deeper NTK embeddings incorporating more model parameters improve acquisition without prohibitive cost?
- How do advanced uncertainty quantification methods (e.g., Bayesian deep ensembles or multi-head models) compare to NTK-based acquisition in terms of robustness and scalability?
Why it matters for bot defense
While this paper addresses active learning in scientific machine learning for molecular potentials rather than bot detection or CAPTCHA design, several insights could be relevant to CAPTCHA practitioners who employ large-scale sampling and model uncertainty for challenge generation or selection. The scalable feature-space posterior variance acquisition coupled with diversity-aware batch selection is a scalable approach to select informative instances from large unlabeled pools, which parallels challenges in CAPTCHA challenge curation from massive candidate sets. The introduction of force-aware NTKs demonstrates the utility of incorporating richer, vector-valued supervisory signals into representation and acquisition design, suggesting analogous approaches could benefit bot detection systems that consider multiple correlated features or behaviors. Furthermore, the demonstrated robustness of representation-based acquisition under distribution shifts highlights the advantage of learned-embedding kernels over simple disagreement or uncertainty heuristics, which could inform bot-defense strategies resilient to evolving adversarial tactics. However, direct application requires adaptations to the bot defense domain, as the data modalities and threat models differ fundamentally.
Cite
@article{arxiv2605_13788,
title={ Force-Aware Neural Tangent Kernels for Scalable and Robust Active Learning of MLIPs },
author={ Eszter Varga-Umbrich and Zachary Weller-Davies and Paul Duckworth and Jules Tilly and Olivier Peltre and Shikha Surana },
journal={arXiv preprint arXiv:2605.13788},
year={ 2026 },
url={https://arxiv.org/abs/2605.13788}
}