
EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
Source: arXiv:2605.13841 · Published 2026-05-13 · By Tara Bogavelli, Gabrielle Gauthier Melançon, Katrina Stankiewicz, Oluwanifemi Bamgbose, Fanny Riols, Hoang H. Nguyen et al.
TL;DR
EVA-Bench addresses critical gaps in evaluating voice agents by providing a comprehensive end-to-end framework that simultaneously tackles the challenges of realistic multi-turn conversation simulation and holistic measurement of voice-specific quality dimensions. Existing benchmarks either simulate limited or scripted interactions or measure narrow aspects like task completion or speech recognition accuracy alone. EVA-Bench innovates by conducting fully automated bot-to-bot audio conversations with validation that regenerates flawed simulator sessions to ensure result reliability. It also introduces two composite metrics, EVA-A (Accuracy) and EVA-X (Experience), designed to jointly evaluate critical voice agent properties across architectures, including cascade and audio-native models.
The benchmark covers 213 realistic task-oriented scenarios in enterprise domains, integrates controlled acoustic perturbations to assess robustness, and records multi-trial metrics (pass@1, pass@k, pass^k) to separate peak from reliable performance. Evaluating 12 state-of-the-art systems reveals persistent tradeoffs—no system achieves high marks on both accuracy and experience, substantial gaps between peak and consistent capability exist (median 0.44 pass@k–pass^k gap on accuracy), and acoustic perturbations notably degrade performance unevenly across architectures and metrics. EVA-Bench’s open sourcing of code, scenarios, and evaluation tools provides a standardized platform for future research and deployment readiness assessment of voice agents.
Key findings
- No system simultaneously exceeds 0.5 on both EVA-A pass@1 (Accuracy) and EVA-X pass@1 (Experience) across 12 evaluated voice agents spanning cascade, hybrid, and speech-to-speech architectures.
- Median difference between peak performance pass@k and reliable performance pass^k on EVA-A is 0.44, indicating single-trial evaluation overestimates deployment-ready reliability.
- Accent perturbation causes mean accuracy degradation up to 0.10 in cascade systems (worst up to 0.17), but no significant accuracy drop in S2S models (0/27 metric pairs).
- Background noise most strongly impacts experience (EVA-X) for S2S systems with mean delta of −0.16 for experience metrics, while cascade systems lose about 0.10 on accuracy.
- Across cascade models, transcription accuracy on key entities strongly correlates with task completion rate (Pearson r=0.93, p=0.002), and transcription accuracy below 70% corresponds to ~39% lower task completion.
- Turn-taking metrics reveal architectural stratification: cascade mean pass@1 between 0.28–0.58, S2S 0.82–0.83, showing S2S systems have much better conversational timing.
- Cascade systems show an accuracy–experience trade-off; those with better accuracy suffer longer tool call latency (>5s) versus faster but less accurate cascade systems with tool call latencies below 2.7s.
- 12% of simulator conversation trials required automatic regeneration due to user simulator errors, mostly caused by user behavioral drift.
Threat model
The adversary is not explicitly modeled; EVA-Bench assumes voice agents are exposed to naturalistic user behavior represented by the validated user simulator, with acoustic perturbations approximating real-world noise and accent variability. It does not consider active adversarial attackers crafting malicious inputs or attacks aiming to subvert or game the evaluation framework.
Methodology — deep read
Threat Model & Assumptions: EVA-Bench assumes a black-box adversary model where voice agents are evaluated via simulated conversations against a validated and constrained user simulator. The simulator is designed to follow scenario goals with specific personas, avoiding behavior no plausible human would exhibit. Adversarial manipulation by the simulator is ruled out by automatic validation to detect simulator drift or errors. Perturbations test robustness to realistic acoustic degradations rather than adversarial attacks. No explicit adversarial tampering of the agent is modeled.
Data: The evaluation dataset contains 213 scenarios distributed across three enterprise domains—Airline Customer Service Management (CSM), Healthcare HR Service Delivery (HRSD), and Enterprise IT Service Management (ITSM). Each scenario defines a user goal, persona (speaking style, patience, personality), decision tree for dialogue unfolding, scenario-specific database states for tool calls, and ground truth final states. The scenarios focus on high-contact, complex cases like flight rebooking rather than simpler tasks, to better surface failure modes. Data labels include ground truth tool call outputs and conversation transcripts. The dataset also includes controlled perturbations: accented speech (French), background noise (coffee shop), and combined conditions, applied to 90 subsampled scenarios. All conversation interactions are fully automated bot-to-bot via live audio using a cascade user simulator with text-to-speech.
Architecture / Algorithm: The user simulator takes as input the scenario goal, decision tree, and persona and generates spoken turns via a text-to-speech pipeline. The voice agent under test communicates over live audio via WebSocket. EVA-Bench supports multiple voice agent architectures—cascade (STT+LLM+TTS), hybrid (Audio LLM + TTS), and speech-to-speech (S2S) end-to-end systems—evaluated under identical multi-turn conditions. Output is scored on composite metrics derived from multiple specialized LLM-based judges plus audio-level fidelity checks, ensuring cross-architecture comparability.
Training Regime: N/A for EVA-Bench as it is an evaluation framework. However, evaluation includes k repeated trials per scenario (k=5 for clean tests, k=3 for perturbations) to assess consistency. Fully automated evaluation runs concurrently across 213 scenarios or subsampled sets.
Evaluation Protocol: Metrics are aggregated into two composite scores: EVA-A (Accuracy) capturing exact task completion (hash matching final DB state), faithfulness to instructions, and speech-level fidelity of key entities; and EVA-X (Experience) measuring conversation progression (avoiding repetition, stalling), spoken conciseness suitable for phone delivery, and turn-taking timing (latency, interruptions). Each composite score defines pass criteria (pass thresholds τm per metric), and performance is reported as pass@1 (fraction of successful trials), pass@k (fraction of scenarios passed in any trial), and pass^k (probability of passing all k trials for reliability). Judges are LLM-based evaluators with high inter-annotator agreement. Statistical tests include bootstrap confidence intervals and paired permutation testing with Holm-Bonferroni correction for perturbation results.
Reproducibility: The entire EVA-Bench framework, scenario datasets, benchmark data, evaluation suite, and code are released open-source under permissive licenses. This includes recorded conversation transcripts and perturbation scripts. However, some evaluated voice agent models are third-party or proprietary and not fully open.
Example: For one multi-turn flight rebooking scenario, the user simulator with a persona attempts to rebook an earlier flight under constraints. The conversation runs live over audio WebSocket. The voice agent manages tool calls to query and update booking states. The conversation is scored on task completion by matching final DB hashes, faithfulness of actions via LLM judgment, speech fidelity by cross-checking spoken confirmation codes, progression by dialogue judge avoiding stalling, turn-taking by timestamp overlap and latency metrics, and conciseness via LLM judge on verbosity. Five independent trials allow comparison of peak vs reliable performance. Failed simulations trigger regeneration to exclude simulator errors.
Technical innovations
- Bot-to-bot live multi-turn simulation over audio with automatic simulator validation and regeneration to ensure evaluation consistency, a capability absent in prior benchmarks like τ-Voice and FDB.
- Composite EVA-A and EVA-X metrics combining multiple LLM-judge based submetrics plus audio-level fidelity that jointly assess both correctness and conversational experience, enabling cross-architecture comparison.
- Pass@1, pass@k, and pass^k metrics explicitly quantify peak versus reliable multi-trial performance, highlighting stability aspects critical for deployment readiness.
- Controlled perturbation suite isolating accent, noise, and combined acoustic effects independently from user behavior, enabling granular robustness analysis across architectures.
Datasets
- EVA-Bench enterprise voice agent evaluation dataset — 213 scenarios across three enterprise domains (CSM, HRSD, ITSM) — publicly released under open-source license
- Subset of 90 scenarios with controlled perturbations for accented speech and noise robustness testing
Baselines vs proposed
- Best cascade system (Nova + GPT-5.4 + Sonic 3): EVA-A pass@1 = 0.504 ±0.044 vs best S2S system (GPT-Realtime-1.5): 0.467 ±0.052
- Best S2S system (Gemini-3.1-Flash-Live): EVA-X pass@1 = 0.589 ±0.035 vs best cascade system: 0.273 ±0.034
- Cascade transcription accuracy below 70% corresponds to 0.37 task completion vs above 70% is 0.60 task completion
- Median pass@k - pass^k gap of 0.44 on EVA-A across all systems
- Accent perturbation drops cascade task completion by up to 0.17 vs no significant accuracy drop in any S2S system
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13841.
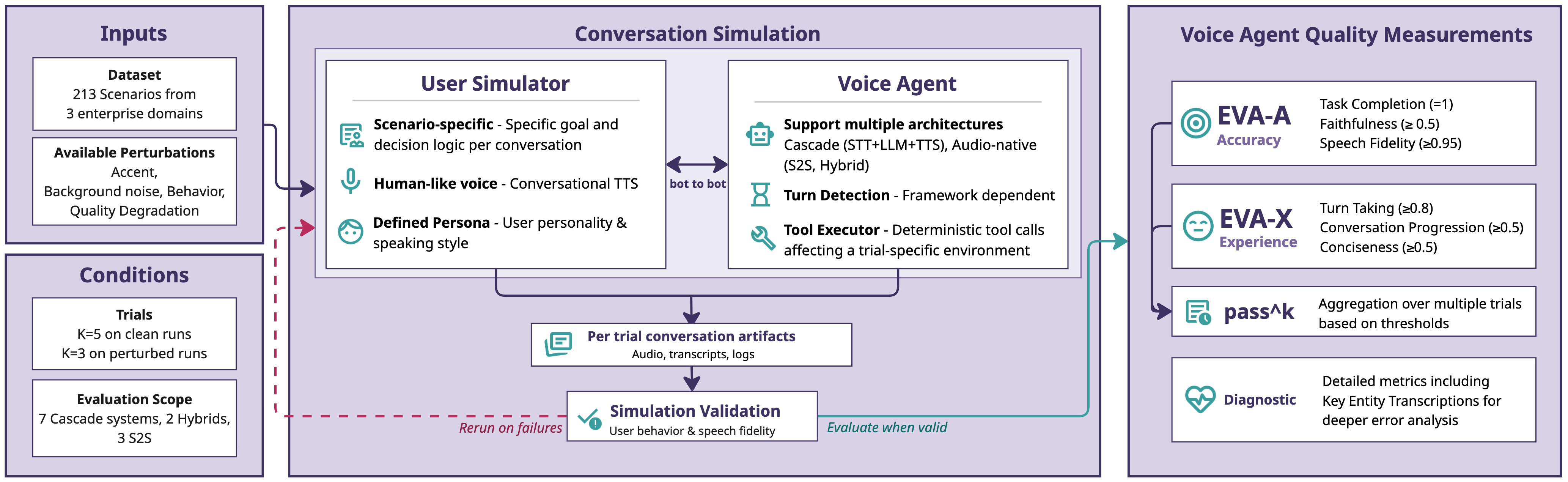
Fig 1: EVA-Bench framework overview. The simulation orchestrates parallel per-scenario bot-to-bot audio sessions

Fig 14: Example Demonstration

Fig 3 (page 73).

Fig 4 (page 73).
Limitations
- Evaluation focuses on enterprise voice agent domains, limiting generalization to open-domain or consumer voice assistants.
- Perturbation tests cover only French accent and coffee shop noise; other accents, noises, or channel effects are untested.
- Automated LLM-judge metrics, while validated with high IAA, may still embed biases or miss subtle failure modes undetectable without human review.
- Behavioral perturbations are modeled but their isolated impact is not comprehensively reported in this paper.
- Some evaluated models are proprietary or closed, limiting reproducibility of reported benchmarks.
- The adversarial threat model assumes no maliciously crafted inputs or attackers beyond environmental perturbations, so adversarial robustness remains untested.
Open questions / follow-ons
- How would EVA-Bench metrics correlate with live human-in-the-loop evaluations or real-world deployment outcomes?
- Can linguistic and acoustic perturbation types be expanded to simulate broader environmental and dialect diversity effects systematically?
- How do hybrid architecture systems truly balance latency and accuracy trade-offs under varying operational conditions beyond the limited samples here?
- What are the optimal architectural or training methods to improve turn-taking timing jointly with high task completion in voice agents?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, EVA-Bench provides a rigorous framework to simulate and evaluate multi-turn spoken interactions with AI voice agents under realistic acoustic conditions. Its detailed diagnostics on speech fidelity, turn-taking timing, and conversational progression offer actionable insights into common failure modes that could be exploited by bots or used to differentiate human from machine callers. The pass@k vs pass^k metrics highlight the importance of stable agent behavior over single-run results, a factor critical when deploying voice agents in high-stakes environments vulnerable to automated misuse. Incorporating EVA-Bench style multi-trial, acoustic, and behavioral perturbation testing could strengthen bot-detection classifiers by surfacing micro-timing and fidelity deviations characteristic of synthetic voices or scripted bots. Moreover, the framework’s automated simulation validation reduces noise from user simulators, improving benchmark reliability for adversarial evaluation research.
Cite
@article{arxiv2605_13841,
title={ EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents },
author={ Tara Bogavelli and Gabrielle Gauthier Melançon and Katrina Stankiewicz and Oluwanifemi Bamgbose and Fanny Riols and Hoang H. Nguyen and Raghav Mehndiratta and Lindsay Devon Brin and Joseph Marinier and Hari Subramani and Anil Madamala and Sridhar Krishna Nemala and Srinivas Sunkara },
journal={arXiv preprint arXiv:2605.13841},
year={ 2026 },
url={https://arxiv.org/abs/2605.13841}
}