
An LLM-Based System for Argument Reconstruction
Source: arXiv:2605.13793 · Published 2026-05-13 · By Paulo Pirozelli, Victor Hugo Nascimento Rocha, Fabio G. Cozman, Douglas Aldred
TL;DR
This paper addresses the challenge of reconstructing structured argument graphs from natural language text by leveraging large language models (LLMs). Argument reconstruction is critical for applications in reasoning, decision support, and debate analysis, but prior methods often struggle to bridge formal argumentation theory with noisy, implicit, and context-dependent natural language arguments. The authors propose a novel multi-stage pipeline that harnesses LLM capabilities in a controlled manner to identify argumentative components (premises and conclusions), merge and rewrite them for clarity, and recursively detect their logical relations—support, attack, and undercut. This pipeline produces directed acyclic graphs representing abstract argument structures enriched with implicit premises and nuanced argumentation relations.
Two complementary evaluations were performed: a manual, detailed analysis on 42 textbook-derived arguments, and a quantitative evaluation on established benchmarks (AAEC and AbstRCT). The manual evaluation showed strong performance in detecting main conclusions (92.5% accuracy), reasonable span detection (F1 75.7%), and relation detection (accuracy 80.6%), alongside high scores for structural elements like implicit premises and undercuts. The global argument graphs were rated highly for completeness and faithfulness, demonstrating effective argument capture with limited hallucination. The external evaluation showed the pipeline can be adapted to varied annotation schemes but leaves room for improvement compared to dedicated argument mining systems. Overall, this work highlights the potential for LLM-based modular pipelines to provide scalable, theoretically grounded argument reconstructions integrating natural language fluency with formal graph constraints.
Key findings
- Conclusion detection accuracy of the system reaches 92.5% on a textbook argumentation dataset.
- Span detection achieves precision 80.31%, recall 72.87%, and F1-score 75.70%, indicating moderate component identification.
- Relation detection—matching directed links between premises and conclusions—attains 80.57% accuracy.
- Annotator-rated quality scores for structural aspects were high: Implicit Premises (mean 2.86/3, EA 0.95), Undercuts (2.90/3, EA 0.88), Convergent/Linked Premises (2.85/3, EA 0.80).
- Global evaluation rated generated argument graphs as nearly complete (mean 2.96/3) and faithful (mean 2.92/3) with strong annotator agreement.
- External evaluation on AAEC and AbstRCT datasets shows the system achieves lower but reasonable F1 scores compared to specialized models; exact numbers were truncated but showed adaptability to multiple schemas.
- The multi-stage pipeline design and recursive premise relation detection enforce a directed acyclic graph structure to maintain logical coherence.
Methodology — deep read
The authors propose a modular, multi-stage pipeline to reconstruct argument graphs from natural language using LLMs, executed via targeted prompting at each step:
Threat Model & Assumptions: The adversary is not explicitly defined since the application is argument reconstruction rather than security. The system assumes input texts with coherent argumentative structure and focuses on natural language texts where arguments may contain implicit premises and complex relations.
Data: Three datasets were used. A custom small dataset from an argumentation theory textbook with 42 annotated short arguments (~332 characters each), manually labeled by the textbook author. Two public benchmark datasets, AAEC (student persuasive essays) and AbstRCT (biomedical abstracts with randomized controlled trial arguments), providing diverse argument types and annotation styles. Data preprocessing involved mapping the datasets’ component labels (major claim, claim, premise) into a unified scheme (conclusion and premise) consistent with the system’s graph approach.
Architecture/Algorithm: The pipeline consists of optional and mandatory steps implemented as separate LLM prompt modules: (1) identifying argumentative components (premises/conclusions) and filtering irrelevant text; (2) merging semantically redundant components; (3) rewriting components for clarity; (4) identifying the main conclusion; (5) recursively detecting support, attack, and undercut relations while enforcing a DAG constraint to avoid cycles; (6-11) optional modules adding implicit premises, nuanced premise relations (linked/convergent), and transitive reductions to simplify graphs. Relations are represented as directed edges between nodes (components) forming a directed acyclic graph.
Training Regime: Rather than conventional training, the system relies on LLM prompting (GPT-4.1, GPT-5, and GPT-5-mini). A single pass per model with a fixed random seed was used. Multiple candidates were suggested as a future robustness improvement.
Evaluation Protocol: Two evaluations were run. Internal (manual) evaluation on textbook data with three levels: component-level (span, conclusion, relation detection measured with precision, recall, F1, and accuracy), structure-level (qualitative ratings by two annotators on implicit premises, undercuts, and premise structure), and global-level (completeness and faithfulness scored 1-3). External evaluation on public datasets using standard argument mining metrics: span identification (F1), component classification (F1 & macro-F1), and relation classification (link existence and type F1). Ablation of optional pipeline modules was done to align output format with benchmark schemes.
Reproducibility: Code and the annotated textbook-derived dataset are publicly released at their GitHub repository. Benchmarks datasets are public but proprietary annotation schemes mean exact replication requires adaptation. No frozen weights involved as the approach is prompt-based on commercial LLM APIs. Some variability in output across runs was noted.
Concrete Example End-to-End: Given a natural language argument on college policy, the pipeline identified key components, labeled the financial priority argument as conclusion, mapped support and attack relations involving implicit premises (like assumed financial incentives), inserted intermediate nodes for linked premises and undercuts, and produced a directed acyclic graph visually consistent with textbook standards. This graph visually distinguishes explicit vs implicit premises, supporting vs attacking edges, convergent vs linked components, and undercutting attacks, demonstrating the system’s full pipeline capability.
Technical innovations
- A multi-stage, modular LLM-prompting pipeline that incrementally reconstructs argument graphs enforcing formal argumentation theory constraints.
- Recursive, breadth-first expansion of support and attack relations with DAG enforcement preventing cyclic argument structures.
- Incorporation of nuanced argumentation concepts such as implicit premises, linked/convergent premises, and undercut attacks within the graph generation.
- Graph transitive reduction technique to remove redundant edges enhancing clarity of logical argument structure.
Datasets
- Argumentation Theory Textbook Dataset — 42 short arguments (~332 characters each) — manually annotated and publicly released by authors
- AAEC (Stab & Gurevych, 2017) — student persuasive essays — public
- AbstRCT (Mayer et al., 2020) — biomedical abstracts of randomized controlled trials — public
Baselines vs proposed
- Morio et al. (2022) on AbstRCT: Span F1 = 70.93 vs proposed system full pipeline Span F1 = 59.65
- Morio et al. (2022) on AbstRCT: Component Classification F1 = 64.78 vs proposed system full pipeline = 27.64 (Macro F1 19.26)
- Morio et al. (2022) on AbstRCT: Relation Link F1 = 44.5 vs system full pipeline = 20.82
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13793.
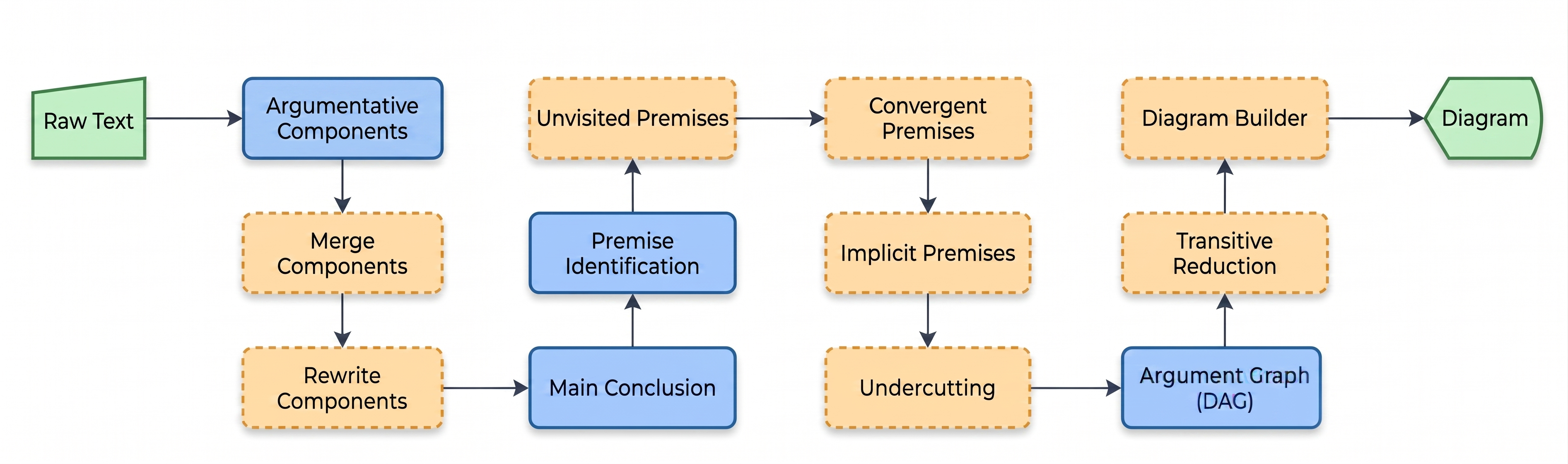
Fig 1: Overview of the system pipeline. The model converts natural language text into an ar-
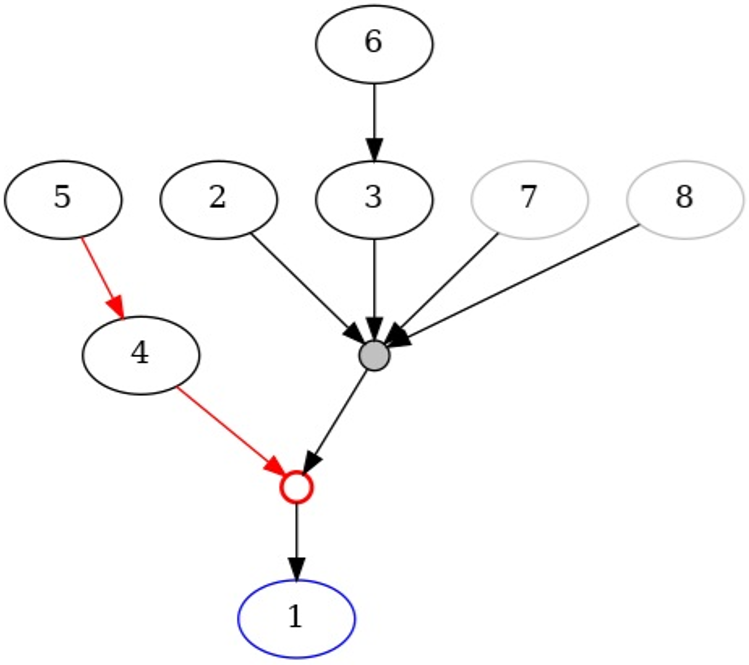
Fig 2: Diagram of the Teacher argument. Explicit premises are shown as black nodes, and
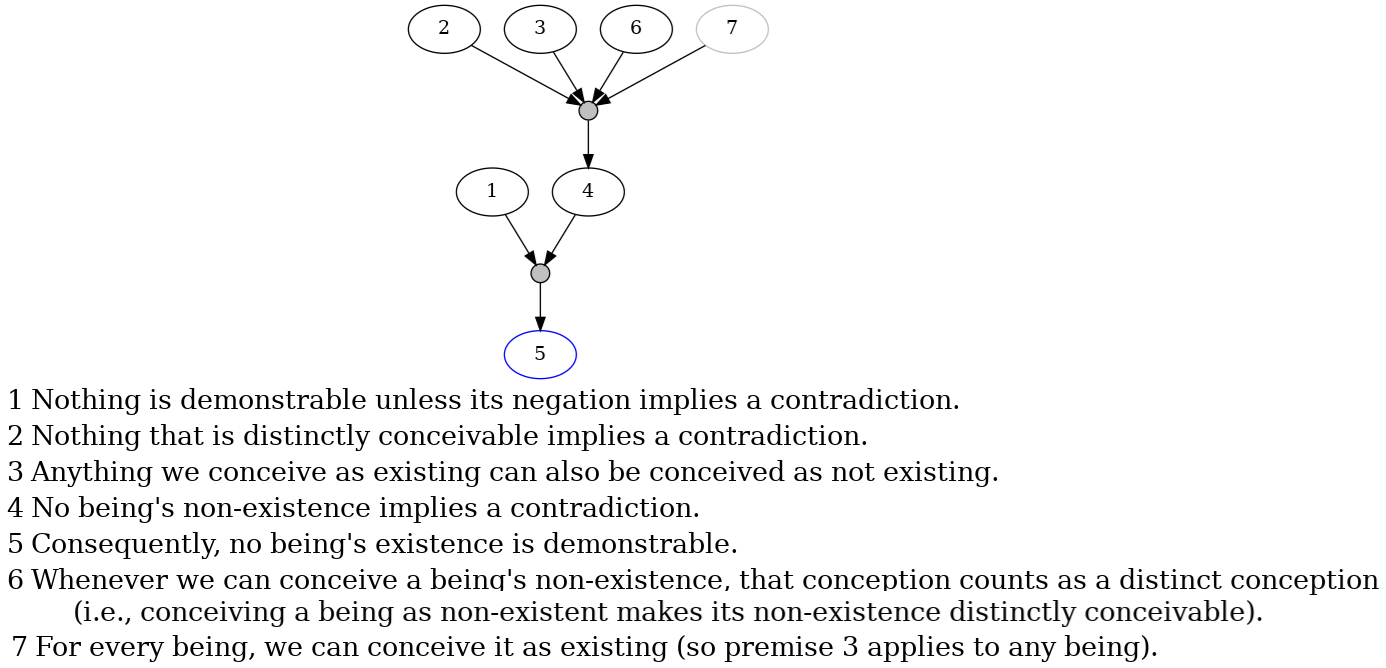
Fig 3: Text: “Nothing is demonstrable, unless the contrary implies a contradiction. Nothing, that
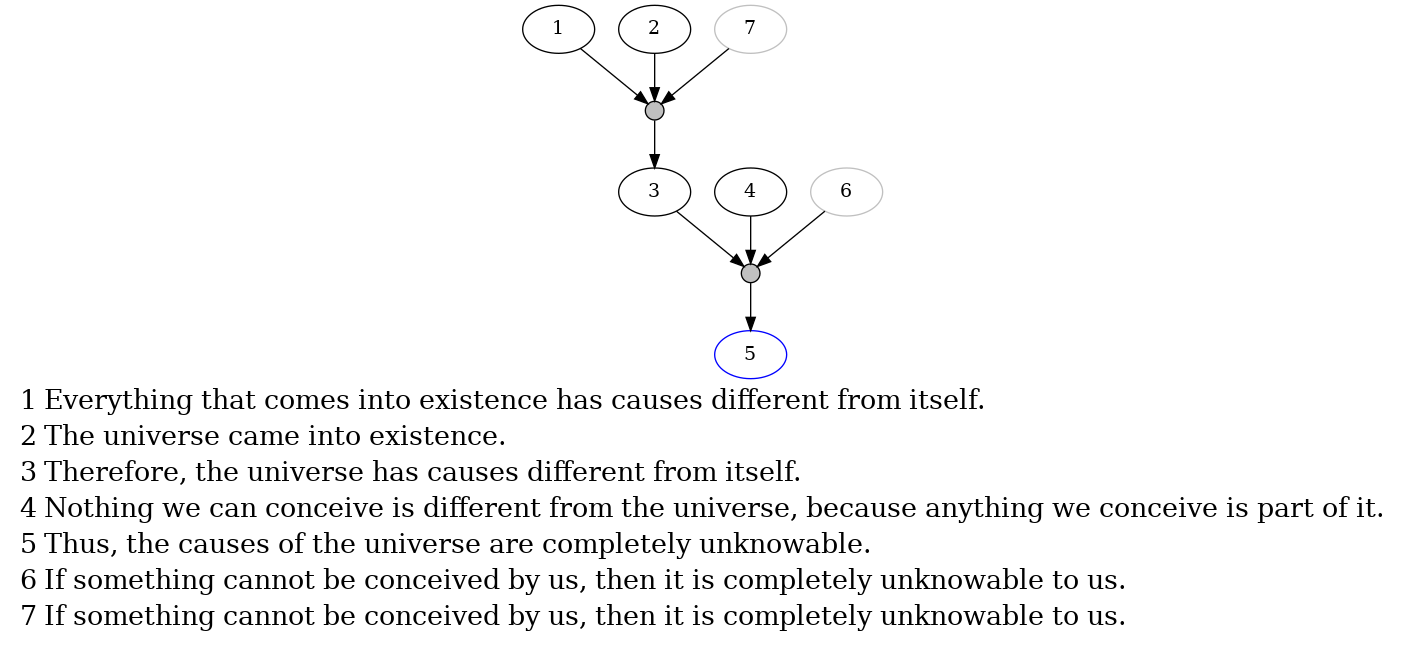
Fig 4: Text: “Everything that comes into existence has causes different from itself. The universe
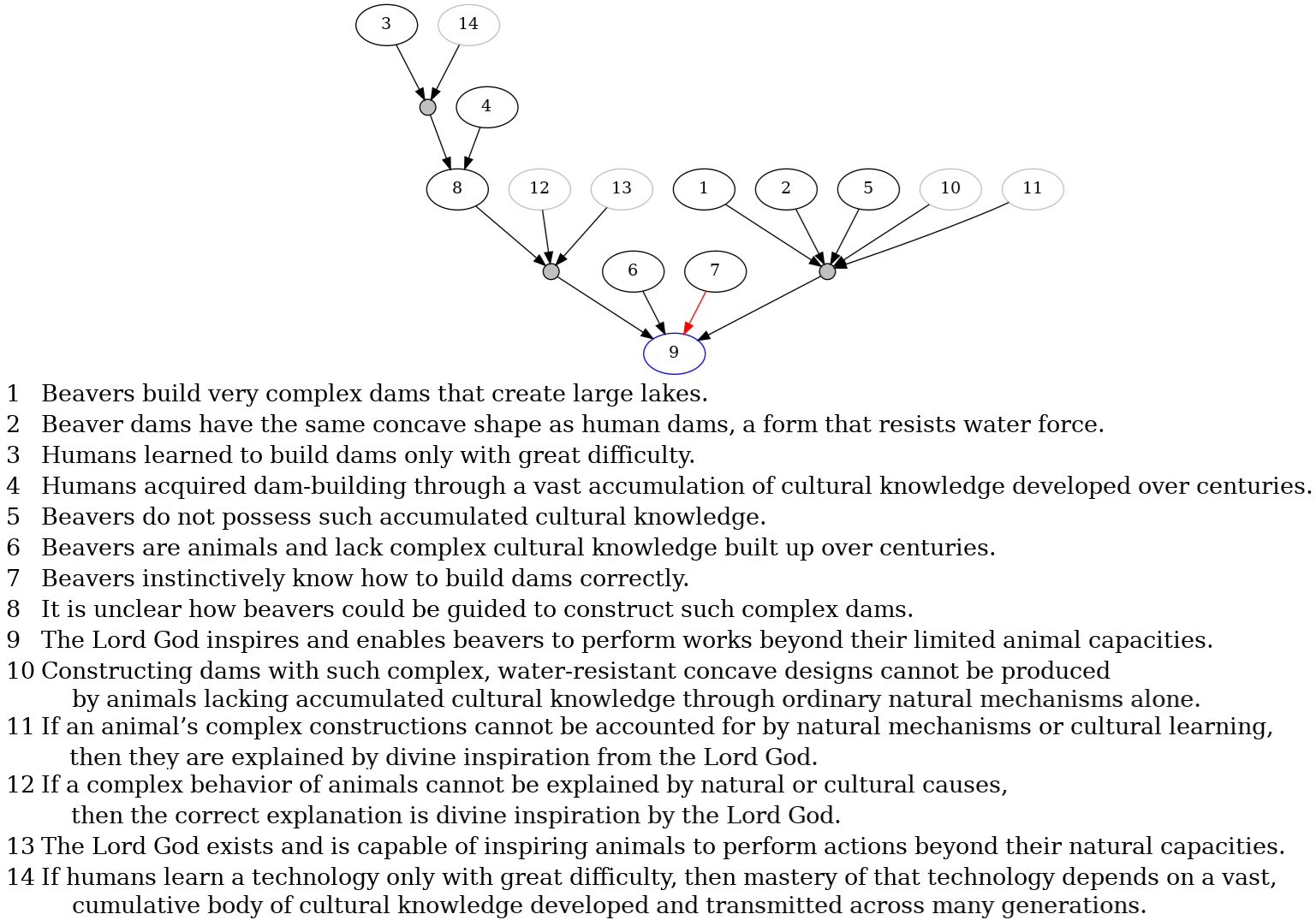
Fig 5: Text: “Beavers build very complex dams that create large lakes. These dams are built
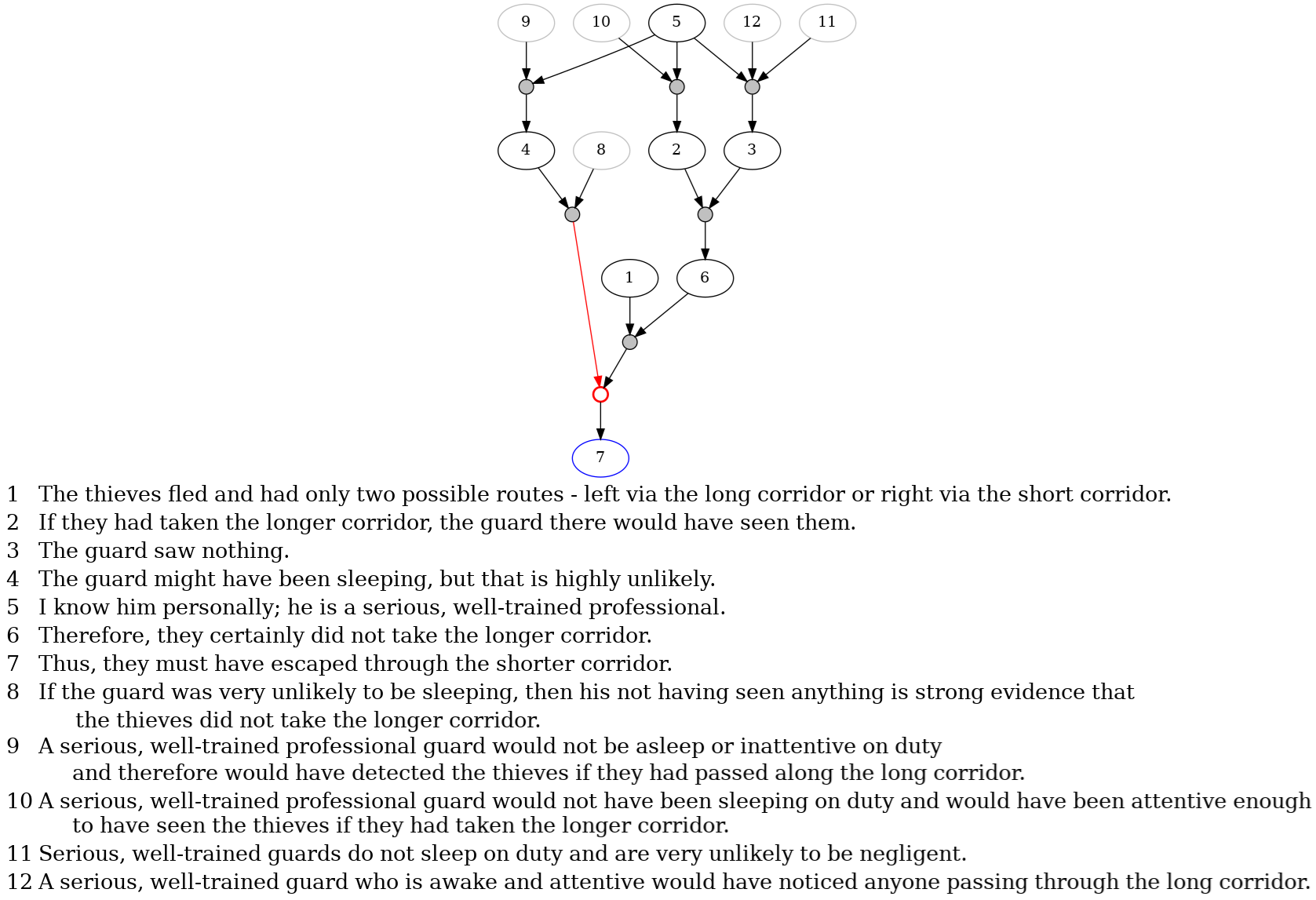
Fig 6: Text: “The thieves fled and there are only two paths they could have taken — to the left,
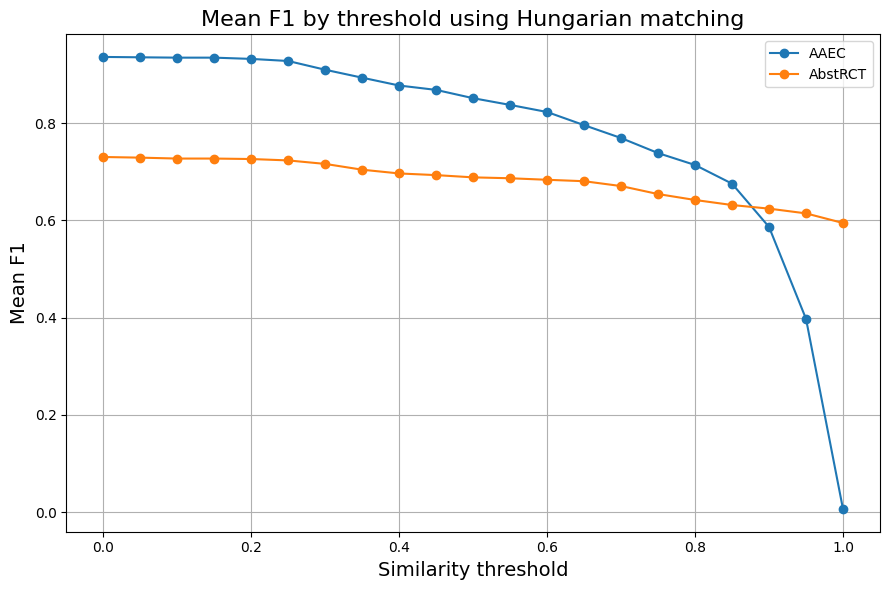
Fig 7: Mean F1-score as a function of the similarity threshold between predicted and gold com-
Limitations
- Small internal dataset size (42 arguments) limits generalization claims for complex real-world arguments.
- Output variability across runs due to reliance on LLM prompting with a fixed random seed; needs multi-candidate selection for robustness.
- External evaluation performance notably below specialized supervised argument mining models, indicating room for accuracy improvements.
- Fine-grained argument features like rebuttals and implicit premise detection may introduce trivial or self-evident additions requiring manual filtering.
- No adversarial robustness or distribution shift evaluation reported; generalization to noisy or adversarially crafted arguments is uncertain.
- Relies on off-the-shelf LLMs without fine-tuning, constraining customization for domain-specific argument styles.
Open questions / follow-ons
- How can multiple candidate generations be effectively ranked or combined to reduce variability and improve output robustness?
- Can the pipeline be fine-tuned or adapted to improve detection of less explicit argumentative components, especially implicit premises?
- What are the impacts of adversarial or noisy text inputs on the system’s ability to reconstruct valid argument graphs?
- How to better align argument diagram representations with diverse annotation schemes to facilitate benchmarking and dataset interoperability?
Why it matters for bot defense
This work clarifies how large language models, when combined with formal argumentation structures and controlled modular prompting, can automatically extract interpretable, richly structured argument graphs from natural language. For bot-defense and CAPTCHA practitioners, argument reconstruction informs methods to assess user-generated content’s rationality or coherence, potentially distinguishing between human logical argumentation and generated or shallow responses by bots. Techniques that identify implicit premises, attacks, and undercuts could enhance detection of manipulation or inconsistencies in automated dialogue. However, the pipeline’s complexity and moderate external benchmark performance suggest integration must be carefully tailored and validated for security-critical applications. The formal DAG constraints preventing cycles also underscore the importance of structural validity checks when parsing dialogues or interactive sessions involving argument exchanges.
Cite
@article{arxiv2605_13793,
title={ An LLM-Based System for Argument Reconstruction },
author={ Paulo Pirozelli and Victor Hugo Nascimento Rocha and Fabio G. Cozman and Douglas Aldred },
journal={arXiv preprint arXiv:2605.13793},
year={ 2026 },
url={https://arxiv.org/abs/2605.13793}
}