
Task-Adaptive Embedding Refinement via Test-time LLM Guidance
Source: arXiv:2605.12487 · Published 2026-05-12 · By Ariel Gera, Shir Ashury-Tahan, Gal Bloch, Ohad Eytan, Assaf Toledo
TL;DR
This paper studies a simple but important problem: how to make dense embedding models behave more like flexible instruction-following systems on zero-shot search and classification tasks, without paying the full cost of running an LLM over an entire corpus. The core idea is to use an LLM only as a test-time teacher on a small set of candidate documents, then refine the query embedding itself by gradient descent so that the embedding model’s ranking better matches the teacher’s pairwise judgments. In other words, the query vector is adapted per task/query at inference time, while the document embeddings and the model weights remain fixed.
The main result is that this LLM-guided query refinement consistently improves mean average precision across several embedding models and four task families: literature search, intent detection, key-point matching, and nuanced query-instruction following. The gains are largest on harder settings, with reported relative MAP improvements up to +25.7% on ARGKP-21 for Llama-Embed-Nemotron-8B and +25.5% on CLINC150 for Qwen3-Embedding-0.6B. The authors also show that the refined query usually does better than simply reranking the initial top-K items with the LLM scores, suggesting the benefit is not just local reranking but an actual movement of the query representation into a more discriminative region of embedding space.
Key findings
- Across all evaluated models and datasets, LLM-guided query refinement improved MAP over the original embedding query; averaged over all models and tasks, MAP rose from 0.59 to 0.66 for Qwen3-Embedding-0.6B and from 0.55 to 0.65 for E5-Mistral-7B in Table 1.
- On CLINC150, Qwen3-Embedding-0.6B improved from MAP 0.59 to 0.74 with optimization (+25.5% relative), while rerank-only reached 0.60 (+1.3%).
- On ARGKP-21, Llama-Embed-Nemotron-8B improved from MAP 0.59 to 0.74 (+25.7% relative), compared with rerank-only at 0.67 (+13.8%).
- On REALSCHOLARQUERY, E5-Mistral-7B improved from MAP 0.48 to 0.60 (+24.5% relative), versus rerank-only at 0.55 (+15.1%).
- On FOLLOWIR, Qwen3-Embedding-0.6B improved from MAP 0.41 to 0.46 (+11.3%), while Llama-Embed-Nemotron-8B improved from 0.45 to 0.47 (+5.1%).
- The authors report a representative precision-recall curve where a CLINC150 query’s AP increases from 0.370 to 0.724 after optimization (Fig. 2a).
- The online optimization overhead is modest: for Qwen3-Embedding-8B on CLINC150, query embedding took 86.32 ms, initial ranking 1.42 ms, and the optimization loop 79.20 ms excluding LLM calls (Table 2).
- Performance gains correlate positively with teacher feedback quality, and the paper reports the correlation as modest but statistically significant (Appendix Table 10), though the exact coefficient is not in the provided excerpt.
Threat model
The system assumes an honest-but-limited retrieval stack facing zero-shot user queries over a large offline-indexed corpus. The adversary is effectively task mismatch: the query expresses a nuanced relevance criterion that the base embedding model cannot capture well. The teacher LLM can inspect only a small set of top-K candidate documents and return pairwise match scores; it cannot alter the corpus, retrain the embedder, or exhaustively score the whole corpus. The method does not address malicious prompt injection, adversarial documents, or poisoning.
Methodology — deep read
The threat model is implicit rather than adversarial in the classic security sense: the system faces a user issuing an ad-hoc query against a large corpus, while the expensive teacher is a general-purpose LLM used only at test time. The embedding model is assumed fixed and publicly available; the corpus is offline-indexed; the teacher can score only a small candidate set. The method does not assume labeled training data for the target query/class and does not update model weights. The adversary is not a malicious attacker so much as the problem of task mismatch: a generic embedding model that under-specifies nuanced user intent, especially for zero-shot full-corpus separation tasks.
The data setup spans four main benchmarks and two additional ones in the appendix. REALSCHOLARQUERY is used for literature search over a large arXiv computer-science corpus, with expert annotations and multiple matches per query. CLINC150 is used in a nonstandard way: each intent label is treated as a query, and the task becomes separating utterances expressing that intent from all others across the corpus. ARGKP-21 comes from the 2021 KPA shared task and contains key-point matching pairs. FOLLOWIR is derived from TREC relevance narratives and emphasizes nuanced instructions with constraints and negation. The paper also mentions BANKING77 and NFCORPUS in Appendix C. The excerpt does not provide all dataset sizes; where the paper likely gives details, it refers to Appendix A, but the sizes are not included in the provided text. The evaluation is query-level MAP over all queries, which matches the binary separation framing.
Algorithmically, the method is a two-stage test-time optimization loop. First, the embedding model encodes the query q and all documents d into a shared vector space, and the initial ranking πq,D is produced using cosine similarity. Second, the top-K documents from that ranking are sent to a teacher LLM, which jointly reads each query-document pair and emits a match score. In the main setup, K=20. Those teacher scores are converted into a softmax distribution p_mt(q) over the top-K documents. The embedding model’s current query vector z(t), initialized as me(q), is then optimized so that the embedding-model distribution p_me(z(t)) over the same top-K set matches the teacher distribution by minimizing KL(p_mt || p_me). The optimization uses Adam with learning rate 1e-4 and 100 steps. After optimization, the refined query embedding z(T) is used to rescore the full corpus, but the corpus embeddings remain fixed. A concrete example is given in Fig. 2a: for a CLINC150 intent query and Qwen3-Embedding-0.6B, the original ranking yields AP=0.370, while the optimized query yields AP=0.724. The paper’s interpretation is that the LLM’s judgments over a small candidate set define a local target distribution, and gradient descent nudges the query embedding toward a region of the space where positives and negatives are more cleanly separated.
Training is not the main story here; this is test-time adaptation. There is no fine-tuning of embedding weights, no additional supervised training set, and no epoch schedule in the usual sense. The only optimization hyperparameters reported in the excerpt are Adam, α=1e-4, T=100, and K=20. The authors state they use a single fixed configuration across all datasets, models, and settings, which is important because it means the gains are not coming from per-benchmark tuning. The teacher LLM in the main experiments is Mistral-Small-3.2-24B-Instruct-2506; Appendix C evaluates additional teachers (DeepSeek-V3.2, Qwen3.5, GPT-4.1) and reportedly finds consistent performance across teachers. For inference, each query-document pair is wrapped in a brief instruction asking whether the pair is a match, and the teacher score is derived from token logprobs of the generated response. The embedding-side query text is also placed in an instruction template: “Instruct: {instruction}\nQuery: {query}”, and the paper notes some models are sensitive to this template choice.
Evaluation is by MAP over queries, with comparisons between the original embedding ranking, a rerank-only variant, and the proposed optimized-query variant. The rerank-only condition is important because it isolates whether gains come merely from using the teacher to reorder the top-K documents or from actually changing the query representation so that documents outside the initial top-K can move upward. Fig. 2b shows that reranking alone only affects the initial top-K, whereas optimization can improve Recall@K beyond that local window. Table 1 reports results across four main datasets for five embedding models. The paper claims the improvements are statistically significant and refers to Appendix C, but the exact test details are not in the excerpt. Fig. 3 visualizes a query trajectory under 100 gradient steps via PCA, showing the query vector moving toward a more discriminative part of the embedding space relative to positive/negative labeled documents. Reproducibility is relatively strong: the authors release code on GitHub, and the method is defined with fixed hyperparameters; however, the pretrained embedding models, the teacher model, and likely some datasets remain external dependencies rather than fully bundled artifacts.
Technical innovations
- Test-time query embedding optimization with an LLM teacher, using KL divergence between teacher and embedding-model distributions over the top-K retrieved documents.
- A task-adaptive retrieval framing that treats zero-shot classification and search as full-corpus binary separation rather than standard top-1 classification or QA retrieval.
- A simple but effective hybrid pipeline that keeps the corpus embeddings fixed and adapts only the query representation online, enabling sub-second optimization before LLM scoring latency.
- An empirical demonstration that query-space refinement can outperform reranking-only feedback, implying the gain comes from representation movement rather than local list reordering.
Datasets
- REALSCHOLARQUERY — size not stated in excerpt — expert-annotated arXiv computer-science paper corpus
- CLINC150 — 150 intents / 10 domains — public dataset
- ARGKP-21 — size not stated in excerpt — 2021 KPA shared task data
- FOLLOWIR — size not stated in excerpt — derived from TREC relevance narratives
- BANKING77 — 77 intents — public dataset (appendix)
- NFCORPUS — size not stated in excerpt — public medical IR dataset
Baselines vs proposed
- Original embeddings vs proposed (Qwen3-Embedding-0.6B on REALSCHOLARQUERY): MAP = 0.54 vs 0.65
- Rerank-only vs proposed (Qwen3-Embedding-0.6B on REALSCHOLARQUERY): MAP = 0.62 vs 0.65
- Original embeddings vs proposed (Qwen3-Embedding-0.6B on CLINC150): MAP = 0.59 vs 0.74
- Rerank-only vs proposed (Qwen3-Embedding-0.6B on CLINC150): MAP = 0.60 vs 0.74
- Original embeddings vs proposed (Llama-Embed-Nemotron-8B on ARGKP-21): MAP = 0.59 vs 0.74
- Rerank-only vs proposed (Llama-Embed-Nemotron-8B on ARGKP-21): MAP = 0.67 vs 0.74
- Original embeddings vs proposed (E5-Mistral-7B on FOLLOWIR): MAP = 0.41 vs 0.46
- Rerank-only vs proposed (E5-Mistral-7B on FOLLOWIR): MAP = 0.44 vs 0.46
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12487.

Fig 1: Examples of full-corpus separation tasks over different collections of documents.
Fig 2 (page 2).

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).
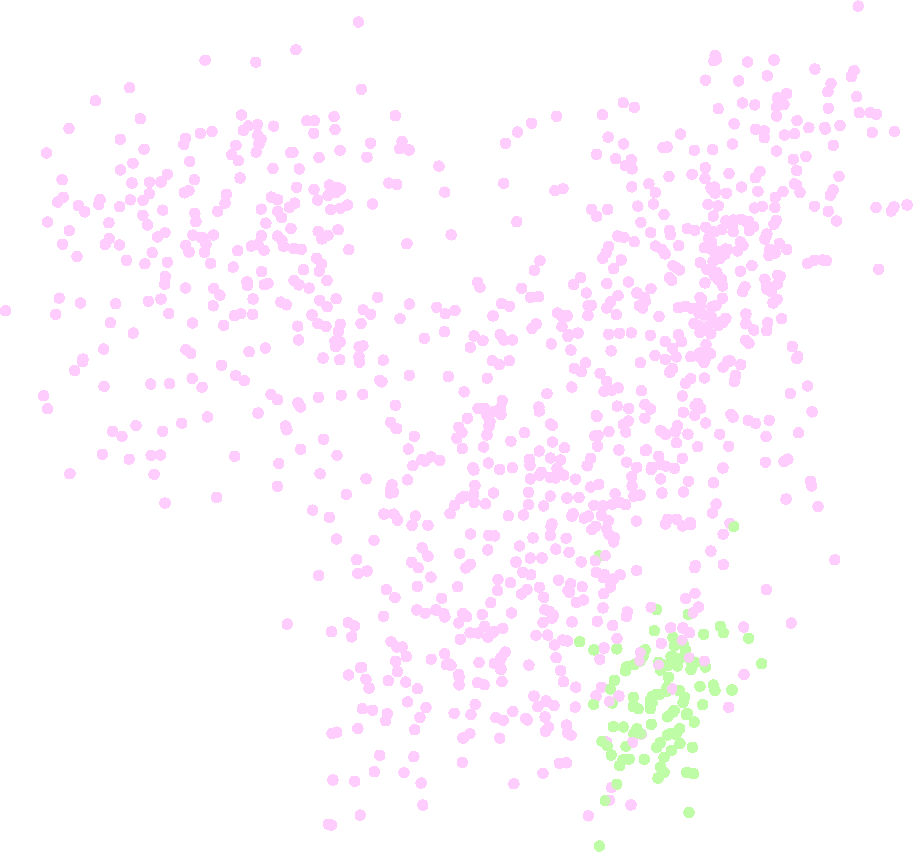
Fig 3: 2D PCA projection for a query from CLINC150. The plot depicts the trajectory of the
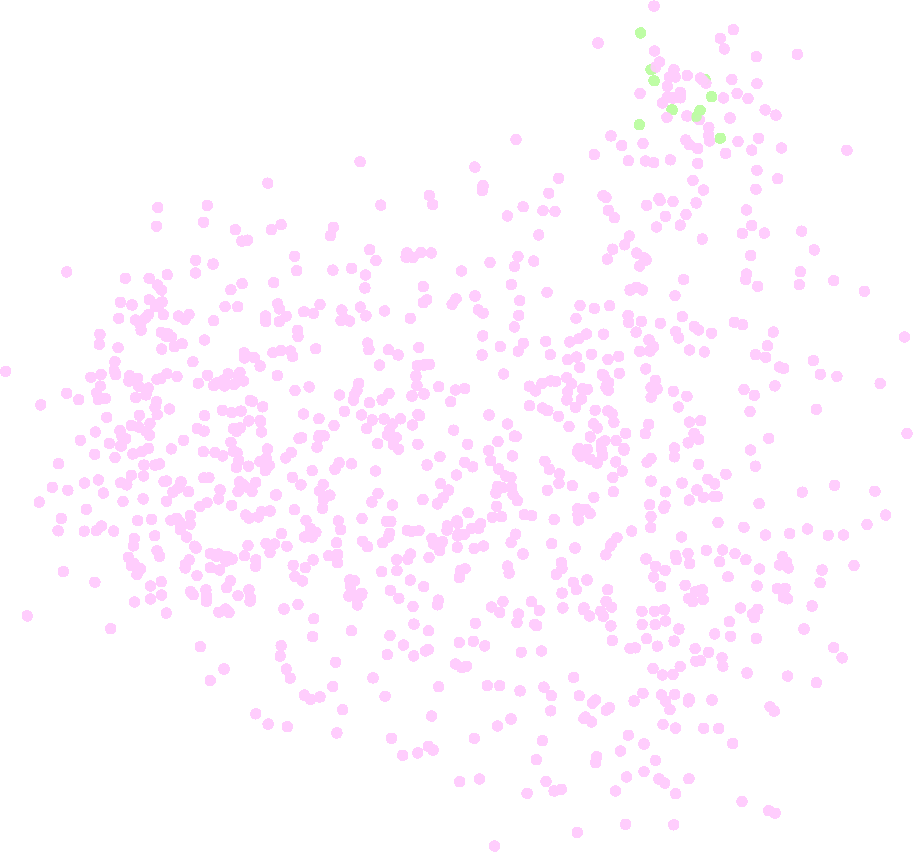
Fig 6: 2D PCA projection for example queries. The plots depict the trajectory of the query
Limitations
- The paper’s strongest claim is empirical, but the provided excerpt does not include the statistical test details, effect sizes per query, or confidence intervals; significance is mentioned but not fully inspectable here.
- The method depends on the teacher LLM’s scoring quality, so teacher bias or systematic errors can be propagated into the refined query representation.
- Top-K feedback is taken from the initial retriever’s ranking; if relevant documents are absent from the initial top-20, the method may never see them, which is especially risky under extreme class imbalance.
- The optimization uses a fixed K=20 and fixed learning rate/steps for all tasks; the paper itself notes that optimal K remains an open question.
- The excerpt does not show full dataset sizes, exact split protocols, or whether any benchmark-specific preprocessing details were applied beyond the query template.
- The method is evaluated on text tasks only; extension to other modalities is suggested but not demonstrated.
Open questions / follow-ons
- How should the candidate set DK be selected beyond naive top-K retrieval to improve feedback quality under class imbalance or early retrieval miss?
- Can listwise or setwise LLM scoring reduce the number of teacher calls without losing the benefit of query-space adaptation?
- What are the best stopping rules or thresholding strategies for turning a refined ranking into a binary decision boundary in production?
- How does the method behave under distribution shift, especially when the initial retriever is weak enough that many positives are outside the first retrieved set?
Why it matters for bot defense
For bot-defense or CAPTCHA-adjacent systems, the paper is relevant as a general pattern for low-latency test-time adaptation from a strong but expensive teacher. The most direct analogy is query or intent routing: if a user’s request, challenge response, or conversation snippet is hard to classify with a fixed embedding model, you can use an LLM to score a small candidate set and then refine the embedding-space decision boundary for that specific interaction. The practical lesson is that a lightweight retrieval model can be made more task-sensitive without full LLM-inference over the entire corpus, but only if the candidate pool is good enough to expose the relevant positives.
For CAPTCHA or abuse-detection workflows, I would treat this as a design pattern for adaptive filtering rather than a turnkey defense: use the cheaper model for broad retrieval or triage, then ask the LLM to adjudicate a small shortlist and update the query/query-like representation online. The main caution is that the method inherits the teacher’s blind spots and is vulnerable to missing evidence outside the initial shortlist, which matters a lot in adversarial settings where the first-stage model is intentionally deceived. So the right reaction is probably to borrow the optimization idea, but pair it with stronger candidate generation, adversarial hardening, and explicit monitoring for false negatives.
Cite
@article{arxiv2605_12487,
title={ Task-Adaptive Embedding Refinement via Test-time LLM Guidance },
author={ Ariel Gera and Shir Ashury-Tahan and Gal Bloch and Ohad Eytan and Assaf Toledo },
journal={arXiv preprint arXiv:2605.12487},
year={ 2026 },
url={https://arxiv.org/abs/2605.12487}
}