
State-Centric Decision Process
Source: arXiv:2605.12755 · Published 2026-05-12 · By Sungheon Jeong, Ryozo Masukawa, Sanggeon Yun, Mahdi Imani, Mohsen Imani
TL;DR
This paper addresses a core limitation in language-based interactive environments—such as web browsers, code terminals, and text-based simulators—which emit raw textual observations but provide no explicit Markov Decision Process (MDP) structure required for principled sequential decision-making. Without an explicit state space, observation-to-state mapping, certified transitions, or termination signals, language agents either operate reactively on raw histories or use latent internal states lacking verifiability. The authors propose the State-Centric Decision Process (SDP), a runtime framework in which the agent incrementally constructs explicit, natural-language predicates representing states it commits to making true. At each step, predicates are proposed (PROPOSE), actions are chosen to realize them (REALIZE), observations are validated against predicates (VALIDATE), and plans are repaired if needed (REPLAN). This procedure yields certified state-action trajectories that fill the MDP gap and enable formal reasoning about progress, credit, and failures.
The framework is evaluated across five diverse benchmarks spanning planning, scientific exploration, web reasoning, and multi-hop QA, consistently achieving the best training-free results. The advantage grows with task horizon length and is especially pronounced where per-predicate validation blocks error propagation and supports failure localization. Ablations confirm VALIDATE and REPLAN are critical to correctness while cascades improve efficiency. SDP trajectories also offer diagnostic insights unavailable to purely reactive agents. Overall, SDP advances language agent architecture by delivering an interpretable, verifiable state abstraction layer in complex natural language environments without environment changes or extra training.
Key findings
- SDP achieves 97.4% micro and 93.8% macro hard-constraint satisfaction on TravelPlanner, exceeding ATLAS by 14.8 and 19.4 points despite using a smaller LLM (Gemini-3.1-flash-lite vs Gemini-2.5-Pro).
- On AssistantBench, SDP reaches 31.8% overall exact match accuracy, outperforming all baselines by over 6 points, with 92.8% accuracy on easy tasks, 10 points above the next best.
- SDP attains an overall score of 59.16 on ScienceWorld's 30-task GPT-4 evaluation, surpassing Plan-and-Act by 11.3 points and especially outperforming on long tasks by 15.6.
- For MuSiQue multi-hop QA, SDP obtains 41.4 EM and 51.9 F1, exceeding the next strongest method (IRCoT) by over 7 points in both metrics, showing particular strength as reasoning chains deepen.
- VALIDATE operator contributes the largest performance gain; removing it causes drops of 39–50% in scores across benchmarks.
- REPLAN helps most in recoverable environments like ScienceWorld, exhibiting up to 31.7 point drops when removed.
- Cascades improve efficiency and score on ScienceWorld by 27.2 points, reflecting how single actions often satisfy multiple predicates.
- VALIDATE calibration shows 79% agreement of goal certification with correct final answers on HotpotQA, indicating predicate checks reliably detect correctness.
Threat model
N/A — This work is not focused on adversarial security but on formulating a usable MDP interface for language environments. The framework assumes a non-adversarial environment that emits raw text outputs but does not deliberately manipulate or obfuscate state information. The agent is assumed to have access only to textual observations and actions and cannot enforce external changes to or trusted logging from the environment.
Methodology — deep read
Threat model & assumptions: The SDP framework assumes an agent interacting with language environments emitting raw text outputs without any explicit state or transition function. The adversarial model is not security focused but algorithmic: the environment does not provide states or termination signals and can only be probed through textual observations and actions. The agent possesses an LLM-based reasoning and acting capability and aims to construct an implicit MDP representation at runtime via natural-language predicates. No prior knowledge of environment dynamics is assumed; validation relies solely on observation-predicate matching.
Data: Five public benchmarks evaluate SDP, chosen for diversity in language environment type and task horizon. These include TravelPlanner (structured constraint satisfaction, size not specified), AssistantBench (web reasoning with search and URL scraping), ScienceWorld (scientific exploration in a text simulator, 30 tasks), and multi-hop question answering sets HotpotQA and MuSiQue (~1000 validation examples, open-domain Wikipedia corpus retrieval). The evaluation uses standard splits and setups, with no environment modifications.
Architecture / Algorithm: SDP's core is decomposing the agent's execution loop into four operators: PROPOSE generates the next natural-language predicate target from current state and goal; REALIZE selects an action to make that predicate true; VALIDATE checks the environment's observation against the predicate and returns how many predicates were consecutively satisfied (cascade depth k≥0); REPLAN triggers a new predicate plan suffix when repeated failures occur. The states are not latent embeddings but human-readable predicates. The predicate chain forms a dynamically constructed state space Σ. PROPOSE and REALIZE operate only on Σ without accessing raw output; VALIDATE exclusively maps raw observations O to certified state satisfaction.
Each execution proceeds by building a predicate chain from initial state s0 to goal g via PROPOSE, then iteratively REALIZE and VALIDATE. VALIDATE's integer k advances the plan cursor by multiple predicates when satisfied in cascade. REPLAN intervenes after exceeding attempt budget per predicate target to repair the plan tail. This separation localizes failure handling and preserves Markov assumptions.
All four operators are implemented as zero-shot or few-shot prompted LLM calls (e.g. with GPT-4 or Gemini models) rather than learned parameterized modules. Actions and predicates remain natural language strings. The process produces a certified trajectory tuple (s0, a0, s1, a1, …, sT) with logical meaning.
Training regime: No additional training is involved. The framework is training-free, relying on prompted LLMs as off-the-shelf modules. Hyperparameters include the failure attempt budget b, chosen per environment based on complexity (details in appendices). Calculations run on standard LLM API infrastructure.
Evaluation protocol: Evaluation metrics vary by benchmark—accuracy, exact match, constraint satisfaction rates, and scores as defined in original datasets. SDP is compared against published baseline agents using matching LLM backbones to isolate the effect of the framework rather than model scale. Ablations remove each of VALIDATE, REPLAN, and cascade components one at a time. Calibration of VALIDATE is measured by correlation of predicate passes with ground truth answer correctness. Diagnostic analyses include cascade frequency, replan counts, and per-predicate progress in failures.
Reproducibility: Code and detailed prompts are provided in supplementary materials. Datasets are public or standard benchmarks. The exact LLM versions and seeds used for evaluation are reported. SDP requires no environment modifications or additional training data, supporting practical adoption.
Technical innovations
- Introduction of a runtime protocol where the agent explicitly commits to natural-language predicates describing desired future states, enabling construction of an explicit, goal-dependent state space during interaction.
- Decomposition of the agent loop into four operators PROPOSE, REALIZE, VALIDATE, and REPLAN that separate planning of predicates, action selection, validation against observations, and local plan repair, enforcing per-step certified transitions.
- Use of an integer cascade mechanism in VALIDATE to certify multiple consecutive predicates simultaneously, efficiently advancing the plan cursor and reflecting compound action outcomes.
- Demonstration that such constructed certified trajectories satisfy the Markov property under mild assumptions and supply all missing MDP inputs that language environments lack.
- Application of SDP to diverse language environments and tasks, achieving substantial improvements without additional training or environment changes.
Datasets
- TravelPlanner — size not specified — public benchmark from prior work [52]
- AssistantBench — size not specified — public benchmark with web search API tasks [56]
- ScienceWorld — 30 tasks — public interactive text simulator [46]
- HotpotQA — 1000 validation examples, 5M-paragraph Wikipedia corpus — open-domain multi-hop QA [53]
- MuSiQue — 1000 validation examples, 5M-paragraph Wikipedia corpus — open-domain multi-hop QA [41]
Baselines vs proposed
- ATLAS (Gemini-2.5-Pro): Hard constraint micro accuracy = 82.6% vs SDP (Gemini-3.1-flash-lite): 97.4%
- Plan-and-Act (GPT-4): ScienceWorld overall score = 47.86 vs SDP (GPT-4): 59.16
- IRCoT (GPT-3): MuSiQue F1 = 43.8 vs SDP (GPT-4o): 51.9
- Magentic-One (GPT-4o): AssistantBench overall EM = 25.3% vs SDP (GPT-4o): 31.8%
- RankZephyr + CoT (GPT-4o): HotpotQA EM = 34.0 vs SDP (GPT-4o): 58.3%
- Removing VALIDATE reduces MuSiQue F1 from 51.9 to 10.1, demonstrating criticality of validation
- Removing REPLAN drops ScienceWorld AS from 59.2 to 27.5, showing replanning importance
- Removing cascade reduces ScienceWorld AS from 59.2 to 32.0, evidencing cascade efficiency gains
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12755.
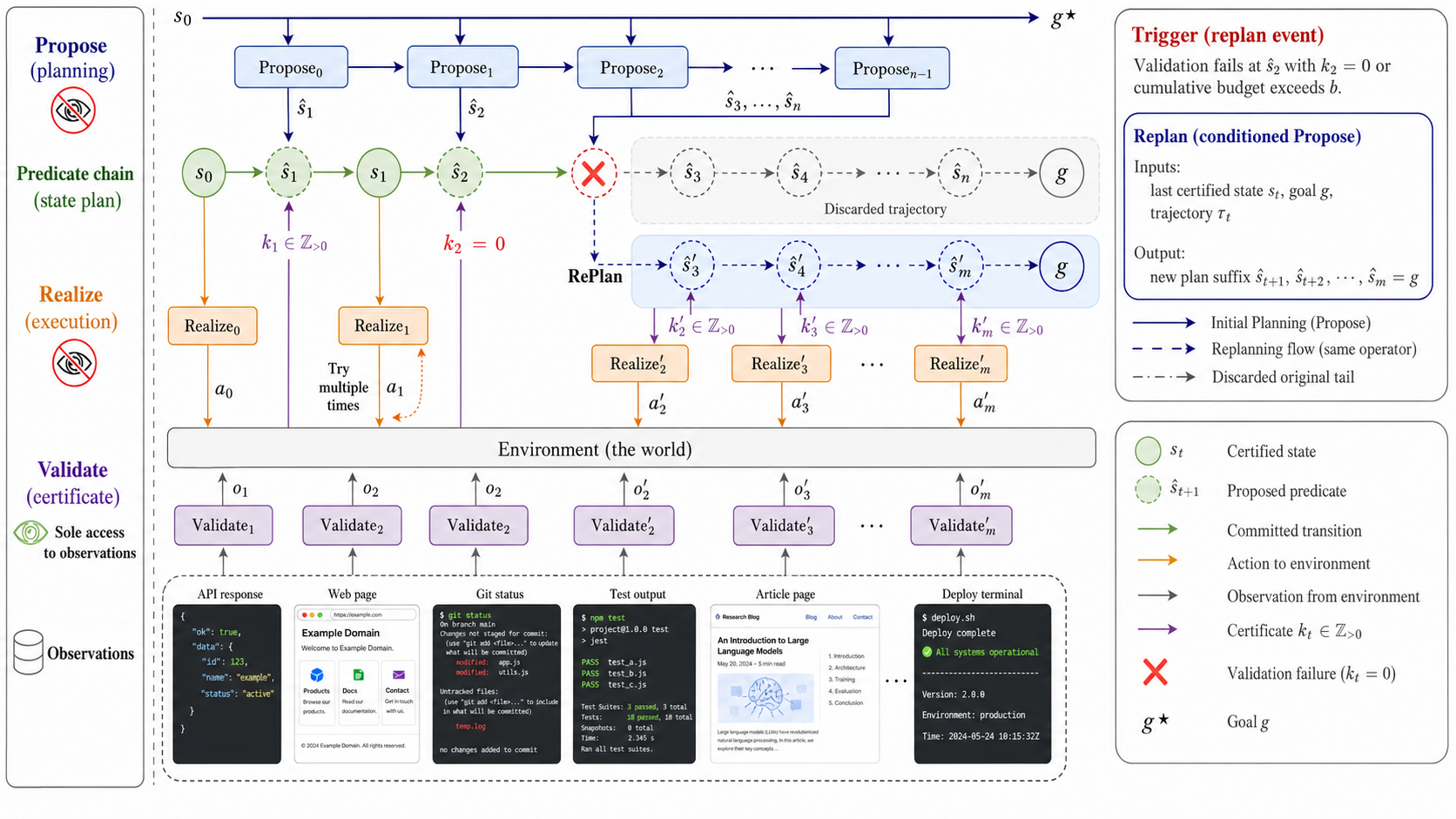
Fig 1: The SDP execution structure. PROPOSE builds the predicate chain from s0 to g. REAL-
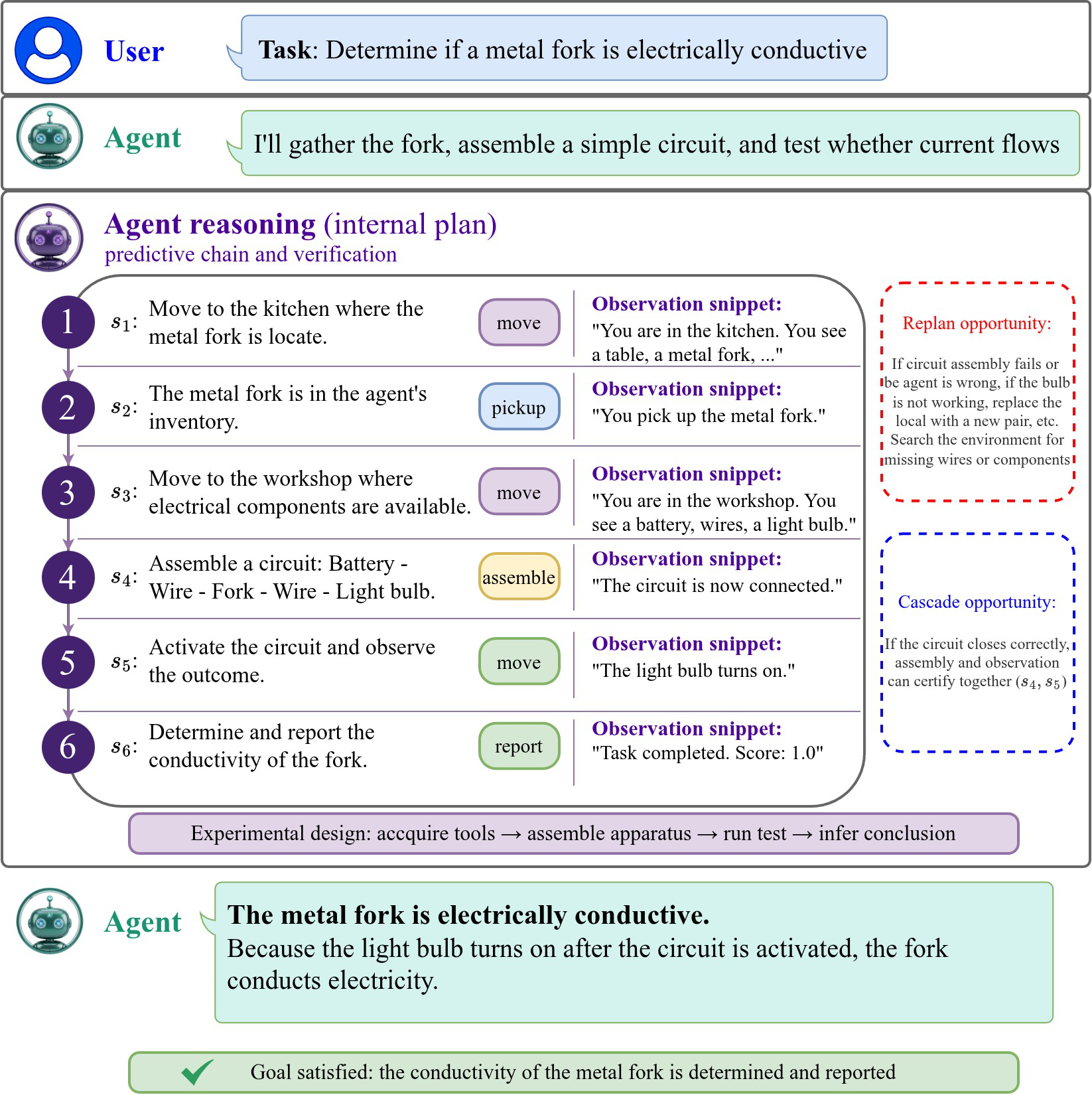
Fig 2: Example SDP run, with a cascade
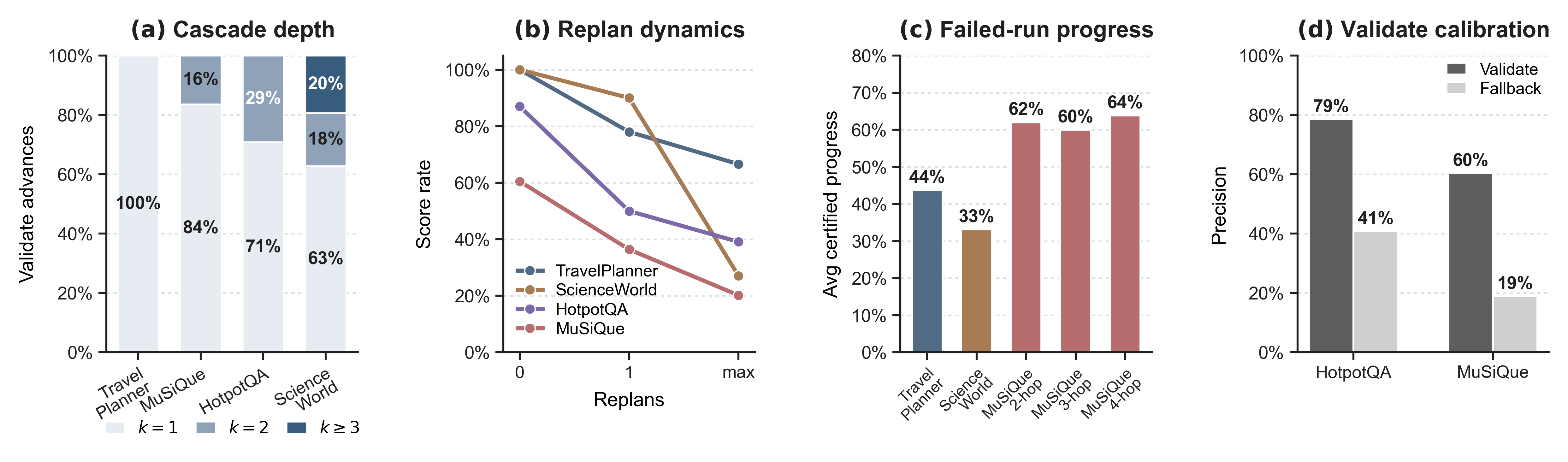
Fig 3: Anatomy of SDP trajectories. (a) Cascade depth. (b) Score rate vs. replan count. (c)
Limitations
- Reliance on LLM-based operators means SDP inherits their weaknesses: VALIDATE may produce false positives on superficially matching predicates which weakens soundness guarantees.
- PROPOSE bounding plan quality depends heavily on the LLM’s ability to decompose goals into reachable predicates; poor decomposition may lead to unreachable or suboptimal plans.
- REPLAN only locally repairs unreachable targets but cannot recover from systematic failures or tasks where predicates are mis-specified or unreachable.
- Natural-language predicates inherently constrain which world conditions can serve as states, limiting expressive power for continuous quantities or complex latent conditions.
- Higher computational cost due to multiple LLM calls per environment step compared to reactive approaches, raising scalability concerns in very long-horizon or real-time tasks.
- The framework does not yet provide fully articulated downstream algorithms operating on the certified trajectories (e.g. trained policies or RL methods), leaving that to future work.
Open questions / follow-ons
- How can learned or trained modules replace or enhance the LLM-based PROPOSE, REALIZE, VALIDATE, and REPLAN operators to improve efficiency and robustness?
- What offline reinforcement learning or credit assignment algorithms can be developed to exploit the certified predicate trajectories produced by SDP?
- Can the framework be extended to richer modalities or mixed environments where predicates involve images, code execution outputs, or other data beyond text?
- What automated methods can improve predicate design to handle continuous state features or uncertain latent variables beyond natural-language descriptions?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SDP provides a systematic approach to imbuing language-driven interactive agents with an explicit, verifiable state abstraction constructed at runtime. This enables measurement and certification of intermediate progress and correctness in environments that emit only raw textual observations, which often characterize automated interactions with websites or conversational platforms requiring challenge-response verification.
Practically, using SDP can improve the reliability of language agents employed in bot interaction scenarios by catching hallucinated or incorrect intermediate states before they propagate, enabling finer-grained failure detection and targeted replanning. SDP's predicate-based state construction also allows modular replacement and auditing of decision steps, which is valuable for debugging false positives or adversarial failures. While SDP is not a defense mechanism per se, its framework for structured state inference and validation offers foundational tools that could be integrated into bot-detection pipelines, challenge generation, or interaction monitoring to raise the bar against automated abuse in natural language environments.
Cite
@article{arxiv2605_12755,
title={ State-Centric Decision Process },
author={ Sungheon Jeong and Ryozo Masukawa and Sanggeon Yun and Mahdi Imani and Mohsen Imani },
journal={arXiv preprint arXiv:2605.12755},
year={ 2026 },
url={https://arxiv.org/abs/2605.12755}
}