
Sign Language Recognition and Translation for Low-Resource Languages: Challenges and Pathways Forward
Source: arXiv:2605.12096 · Published 2026-05-12 · By Nigar Alishzade, Gulchin Abdullayeva
TL;DR
This paper presents a comprehensive systematic review of the challenges and emerging solutions in sign language recognition (SLR) and translation (SLT) for low-resource languages, illustrated through Azerbaijan Sign Language (AzSL). It thoroughly documents how limited data, poor annotation (especially of non-manual features), and low generalization create a self-reinforcing cycle that hampers technology development for these languages. The authors analyze global projects and identify best practices such as community co-design, multi-dialect representation, privacy-preserving pose-based models, and transfer learning among linguistically related Turkic sign languages.
Technically, they propose three paradigm shifts critical for low-resource sign languages: moving from architecture-centric to data-centric AI, from signer-independent to signer-adaptive systems, and from reference-based to task-specific evaluation metrics. Leveraging lessons from Kazakh and Turkish sign language research, they outline a practical roadmap for AzSL that relies on lightweight, MediaPipe-based architectures with community-validated annotations and offline deployment to address infrastructural constraints. The work situates sign language technology as integral to multiple UN Sustainable Development Goals, advocating for Deaf community leadership and interdisciplinary collaboration to ensure ethical, culturally authentic, and useful assistive communication technologies.
Key findings
- Low-resource sign languages exhibit 10-30% higher error rates compared to high-resource benchmarks in SLR, with continuous recognition WER often exceeding 30%.
- Non-manual features (facial expressions, eye gaze) carry up to 30% of sign meaning; incorporating them reduces confusion in AzSL sign pairs from 37% to 11%, a relative 70% improvement in disambiguation.
- Cross-signer accuracy drops 10-30% due to overfitting on small homogeneous datasets, limiting generalization in real-world deployment.
- Kazakh Sign Language (KSL) achieved up to 97.8% accuracy on static signs using lightweight MobileNet CNNs that cut parameters by 80% with minor accuracy tradeoff (94%).
- Yerimbetova et al.'s MediaPipe-based dynamic KSL recognition system runs with under 200ms latency, removes costly pose annotation needs, and adapts to uncontrolled environments through multi-frame interpolation.
- Cross-language transfer learning from Turkish Sign Language (TİD) to KSL yields 70-75% accuracy with zero KSL-specific training, outperforming distant ASL pre-training (55-60%).
- Global corpora with multi-regional and multi-signer diversity (e.g., Mexican LSM corpus, PUCP Iconicity project) enhance dialect capture and annotation quality.
- Offline-first, lightweight apps like Tanzania’s Kalimani reach thousands of users in low-connectivity settings, emphasizing deployment robustness over peak lab accuracy.
Threat model
n/a — The paper does not explicitly consider adversarial threats but rather focuses on natural challenges posed by low-resource, noisy, and contextually diverse environments faced by sign language recognition systems.
Methodology — deep read
Threat Model & Assumptions: The review assumes adversaries are not directly examined; focus is on typical low-resource challenges—scarce annotated data, signer variability, environmental variability, and linguistic diversity impacting model robustness and fairness. Assumes limited computational, annotation, and community involvement resources.
Data: Systematic review sourced from 5 databases (IEEE, ACM, arXiv, Scopus, ACL Anthology) spanning 2019-2026. Initial 412 records filtered by PRISMA guidelines down to 34 studies meeting criteria for primary focus on low-resource SLR/SLT with detailed methodology. Data extracted included dataset sizes, sign languages, annotation detail, model types, and evaluation protocols. AzSL data limited to 30k isolated sign videos without continuous signing sequences.
Architecture/Algorithm: Review covers methods like 3D CNNs, Vision Transformers, graph neural networks; highlights lightweight CNNs (MobileNet) with MediaPipe hand/body landmark extraction to reduce annotation overhead and computational cost. Emphasizes the neglect of non-manual markers in most systems and the use of pose-based anonymized skeleton representations for privacy and efficiency.
Training Regime: Individual reviewed papers’ training procedures vary; Yerimbetova et al.'s KSL system reports real-time single-frame inference under 200ms. Transfer learning setups utilize datasets from linguistically related languages to reduce labeling burden. Evaluation datasets often small, with limited signer diversity and multi-dialect coverage.
Evaluation Protocol: Metrics include accuracy for isolated signs and word error rate (WER) for continuous recognition; BLEU scores for translation but criticized for poor correlation to communicative adequacy. Many datasets lack task-specific evaluation or user-centered metrics. Cross-signer testing reveals significant performance drops. Deployment studies report accuracy degradation (e.g., 40% drop in rural classroom settings) due to environmental factors.
Reproducibility: Sparse open code and datasets hinder reproducibility; AzSL datasets limited in availability and scope. MediaPipe-based approaches offer accessible baseline frameworks. The review does not mention fully public benchmark releases for many low-resource sign languages but highlights community-driven datasets (e.g., PUCP, IPOACISIA).
Concrete example: The AzSL 'TOURIST' vs 'TRAVEL' example demonstrates a 3D CNN trained on hand landmarks only achieves 63% accuracy, with 37% confusion, whereas adding facial features reduces confusion to 11%. This underscores the strong empirical impact of including non-manual markers and motivates annotation complexity for improved recognition.
Overall, the review triangulates literature across fifteen distinct initiatives worldwide, synthesizing challenges, datasets, and solutions to build a technically grounded, culturally sensitive roadmap for AzSL and similar low-resource sign languages.
Technical innovations
- Paradigm shift proposal from architecture-centric to data-centric AI research for low-resource sign languages, emphasizing annotation completeness and community representation over novel models.
- Introduction of signer-adaptive personalization techniques requiring only 5-10 samples for user-specific adaptation, contrasting with conventional signer-independent training.
- Use of MediaPipe-based lightweight landmark extraction removing expensive pose annotation infrastructure, enabling real-time inference (<200ms) on resource-constrained devices.
- Cross-lingual transfer learning within Turkic sign languages to leverage phonological and cultural proximity, achieving significantly higher accuracy on related low-resource languages than transfer from distant languages like ASL.
- Adoption of privacy-preserving 3D pose/skeleton representations to anonymize signers and reduce data storage and computational resource demands, as demonstrated by Kenya's KSL Pose Dataset.
Datasets
- AzSLD (Azerbaijan) — 30,000 isolated sign videos — limited public availability
- LSM Corpus (Mexico) — 90,000 samples, 570 signs, 150 signers — multi-regional with RGB-D + skeleton
- KSL Dataset (Kazakhstan) — 42–200 signs/videos — unspecified public status
- TİD Dataset (Turkey) — 15,000–20,000 annotated clips — research group data
- PUCP Iconicity Project (Peru) — pilot scale — community co-designed video corpus
- KSL Pose Dataset (Kenya) — 20,000 videos converted to 3D pose sequences — privacy-preserving
- Kalimani App (Tanzania) — 5,600+ users, 150+ teachers — offline video + avatars
- IPOACISIA (Italy) — domain-specific with 100+ vocab items — crowdsourced video
- Kara Digital Library (New Zealand) — 10,000+ motion-captured signs — community validated
- ASL Citizen Dataset (USA) — 83,399 videos, 2,731 signs, 52 signers — crowdsourced RGB video
- NMFs-CSL (China) — 1,067 words — large-vocabulary RGB video
- Global Signbank (Belgium) — 3,512 signed glosses — lexical resource
Baselines vs proposed
- 3D CNN on AzSL hand landmarks only: 63% accuracy vs with non-manual facial features: 89% accuracy on 'TOURIST'/'TRAVEL' pair
- KSL ResNet/VGG/MobileNet CNNs: up to 97.8% accuracy, MobileNet achieves 94% with 80% fewer parameters
- Transfer learning from TİD to KSL: 70–75% accuracy vs transfer from ASL to KSL: 55–60% accuracy without KSL-specific training
- Kalimani App models: 40% accuracy drop in rural deployment compared to studio conditions, mitigated with data augmentation and on-device fine-tuning
- Kenyan stickman pose-based model: 72% accuracy at 25 fps inference on mobile devices
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12096.
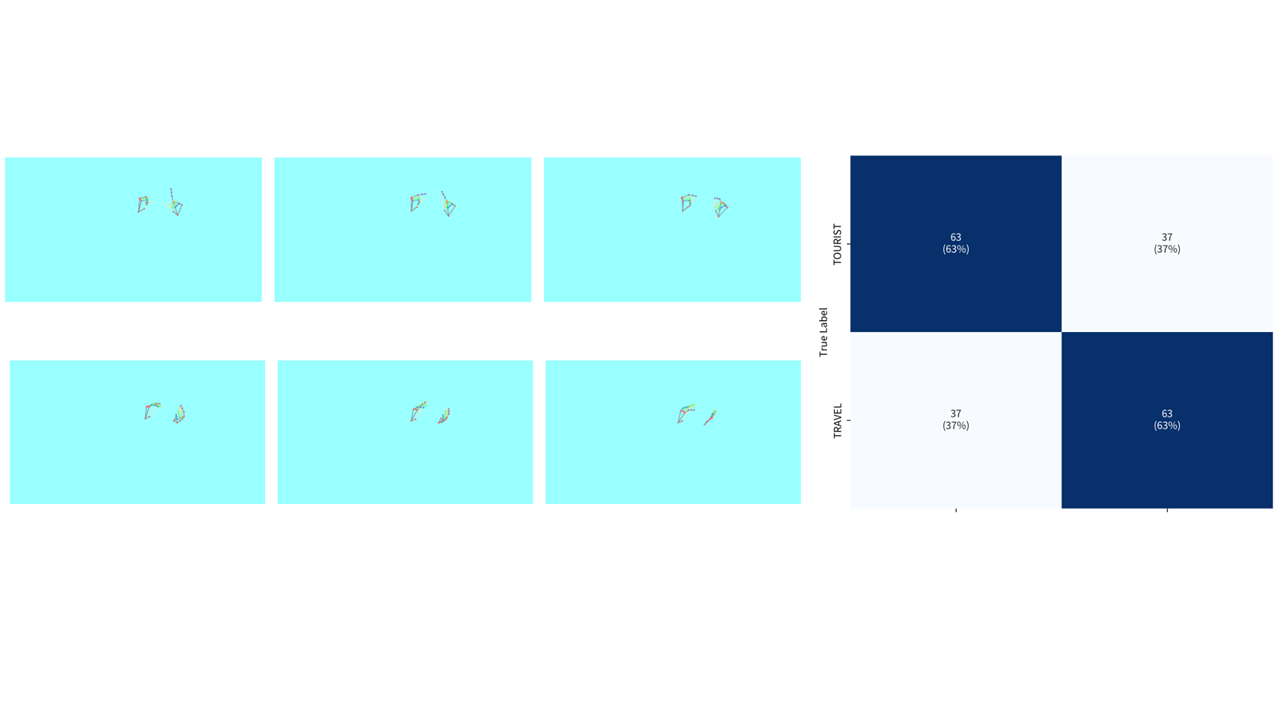
Fig 3: Confusion matrix for the signs “TOURIST” and “TRAVEL” using hand landmarks only. A 3D
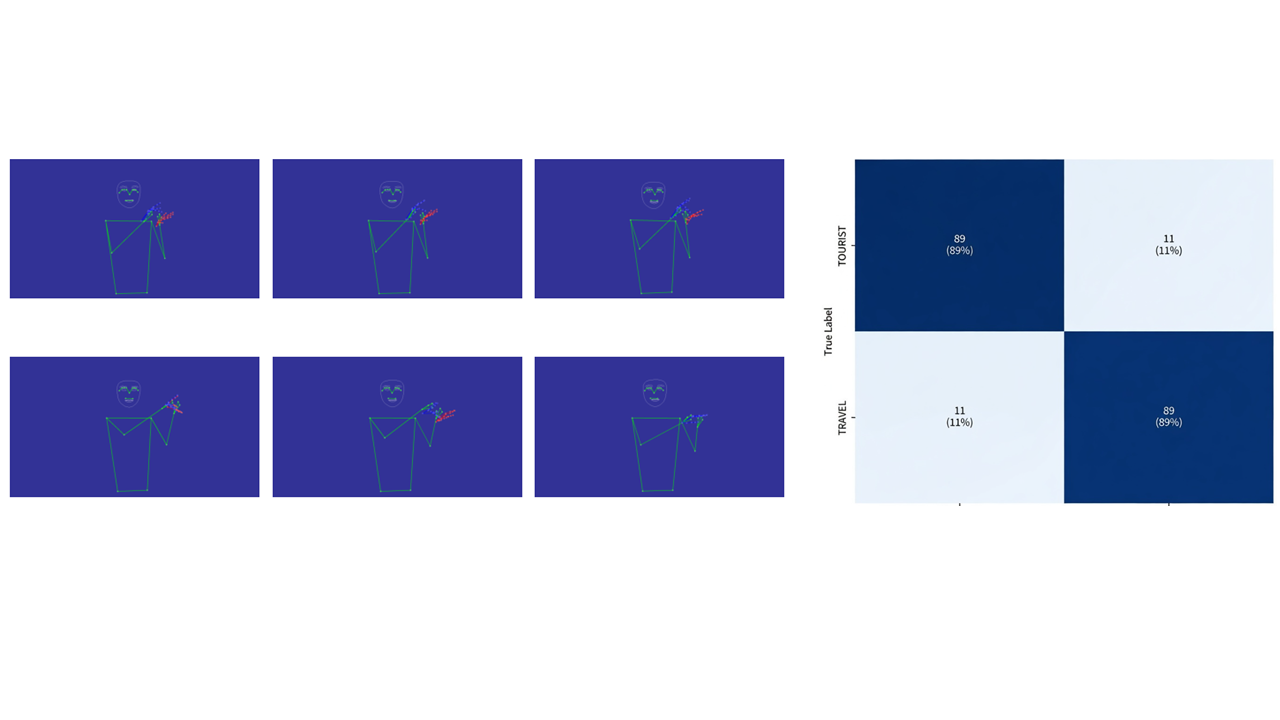
Fig 4: Confusion matrix for the same sign pair after incorporating facial features. The confusion drops
Limitations
- Existing datasets for low-resource languages are small, lacking continuous signing sequences and multi-dialectal diversity (e.g., AzSLD limited to isolated signs).
- Annotation of non-manual markers remains sparse due to cost and required linguistic expertise, limiting model ability to disambiguate confusable signs.
- Evaluation metrics (WER, BLEU) inadequately reflect real communicative adequacy or user satisfaction; task-specific metrics remain underdeveloped.
- Models suffer significant cross-signer generalization degradation due to limited signer diversity in training data, impeding field deployment.
- Real-world environmental factors (lighting, backgrounds, occlusions) cause substantial accuracy drops not reflected in lab benchmarks.
- Limited reproducibility attributable to scarce open-source code and publicly available datasets, especially for Turkic languages outside ASL.
- Ethical, cultural, and privacy considerations complicate data sharing and deployment frameworks in multi-community, multi-country Turkic collaborations.
Open questions / follow-ons
- How to design scalable, socio-linguistically informed annotation workflows that efficiently capture both manual and non-manual sign components in low-resource languages?
- What are effective few-shot personalization algorithms that adapt signer-independent models to diverse signer styles with minimal data and computational overhead?
- How to develop and validate task-specific evaluation metrics that better correlate with real-world communication effectiveness and user satisfaction?
- What institutional structures and governance models best enable cross-border Turkic sign language collaboration while preserving data sovereignty and community trust?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners can draw important parallels to the challenges highlighted here: scarcity of labeled data, signer or user variability, privacy concerns, and deployment robustness in uncontrolled environments directly relate to building reliable bot detection systems under adversarial and data-constrained conditions. The emphasis on pose-based, privacy-preserving input representations offers a promising avenue for CAPTCHA designs that balance usability with anonymity. Moreover, the paradigm shifts toward data-centric approaches and user-adaptive personalization resonate with needs in bot/abuse detection models to better generalize across diverse populations and attack strategies. The clear articulation of annotation bottlenecks and community involvement stresses the importance of domain expert incorporation and iterative evaluation in security system design, mirroring CAPTCHA test evolution. Lastly, multidialect and cross-lingual transfer learning insights suggest transferability of defenses across related user groups or attack types, informing strategies for scaling and updating bot defense modules.
Cite
@article{arxiv2605_12096,
title={ Sign Language Recognition and Translation for Low-Resource Languages: Challenges and Pathways Forward },
author={ Nigar Alishzade and Gulchin Abdullayeva },
journal={arXiv preprint arXiv:2605.12096},
year={ 2026 },
url={https://arxiv.org/abs/2605.12096}
}