
Routers Learn the Geometry of Their Experts: Geometric Coupling in Sparse Mixture-of-Experts
Source: arXiv:2605.12476 · Published 2026-05-12 · By Sagi Ahrac, Noya Hochwald, Mor Geva
TL;DR
This paper addresses the challenges in training Sparse Mixture-of-Experts (SMoE) models, focusing specifically on the routing mechanism that assigns tokens to experts. Traditional SMoEs often suffer from routing collapse, where routing concentrates on few experts, and auxiliary load-balancing losses, though mitigating imbalance, tend to reduce expert specialization. The authors reveal a fundamental geometric coupling between the router weights and the experts’ input-side weights: both receive gradients aligned in the same input direction for a given token, differing only in scalar factors. This shared gradient structure means that routers and their corresponding experts co-accumulate routed token histories, enabling a natural alignment of routing preferences and expert activations.
Empirically, the authors confirm that tokens with higher router scores tend to evoke stronger activations in the corresponding experts, reinforcing the geometric coupling theory. They then analyze how the commonly-used auxiliary load-balancing loss disrupts this geometric coupling by injecting gradient signals into all router directions regardless of selection, causing router weight vectors to become much more aligned and thereby reducing expert specialization. Motivated by these insights, they propose an interpretable, parameter-free online K-Means router that explicitly tracks centroids of hidden states routed to each expert and assigns tokens via cosine similarity. This centroid-based routing preserves expert-specific assignment geometry and achieves the lowest load imbalance among variants with only a modest increase in perplexity, demonstrating that the geometric coupling captures a major component of effective routing. Overall, the paper provides both theoretical and experimental foundations explaining how router–expert geometric coupling forms and why preserving it is important for stable and specialized SMoE training.
Key findings
- For each token routed to expert i, router weight vector ri and expert input-side weights W_gate_i receive gradients exactly proportional to the same input token representation x, inducing geometric coupling (Section 3).
- In a 1B parameter SMoE trained for ~50B tokens on OLMoE-mix-0924, router scores and expert gate-neuron activations (SiLU(W_gate_i x)) for routed tokens correlate with Pearson correlation ρ=0.43 (p < 1e-80), showing functional coupling (Figure 2).
- Adding an auxiliary load-balancing loss increases off-diagonal cosine similarity between router weight vectors to ~0.6, nearly tripling similarity compared to loss-free bias balancing (~0.2), indicating geometric collapse (Figure 3).
- The proposed parameter-free centroid-based K-Means router achieves the lowest load imbalance (MaxVio=0.037) compared to loss-free (0.084) and auxiliary-loss (0.526) routers on the 1B SMoE configuration (Table 1).
- K-Means router only modestly increases training perplexity by 2.6% (15.40 vs 15.01) compared to the learned loss-free router, showing centroid tracking captures much but not all of learned routing complexity.
- Loss-free bias-based balancing preserves router–expert geometric coupling by allowing router weight vectors to accumulate expert-specific routed token averages, unlike auxiliary loss which injects input-directed gradients to all router weights.
- Geometric coupling explains how router preference is mirrored functionally inside experts rather than being a purely separable mechanism, supporting stable expert specialization and effective division of labor.
Threat model
n/a — This paper is primarily a study of training dynamics and geometry of routing in SMoE models, without explicit focus on adversaries or attack scenarios.
Methodology — deep read
The paper studies the gradient and geometric structure of routing in Sparse Mixture-of-Experts (SMoE) layers used in large language models.
Threat model & assumptions: The adversary model is not explicit as this is a training dynamics investigation. The assumption is that the router is a gating network that selects a sparse subset of experts per token and routing is learned via backpropagation with or without auxiliary load balancing losses.
Data: The main empirical experiments use a 1B parameter SMoE trained on OLMoE-mix-0924, a mixture of web and curated corpora including C4 and Pile, amounting to ~50 billion training tokens. Models have 9 SMoE layers, 64 experts (top-K=6), hidden dimension 1024, and expert hidden width 512. Evaluation is on held-out C4-en and Pile slices.
Architecture/algorithm: The SMoE layer replaces standard transformer feed-forward blocks with a set of independent experts E_i and a router R. For each token hidden state x, router computes scores via z = W_r x, selects top-K experts. Expert outputs combine weighted outputs from selected experts. Experts use gated SwiGLU layers with input-side weights W_gate_i and W_up_i.
The key technical insight is that router weight vector r_i and expert input-side weights W_gate_i are updated by gradients proportional to the token input x, differing only by scalar factors, causing them to co-evolve along similar directions in hidden space. This geometric coupling accumulates routed token histories.
Training regime: Models trained with AdamW for ~50B tokens; learning rate 1e-3 decayed to 1e-4; batch size ~2.36 million tokens per step; some trained with auxiliary load balancing loss (penalizing uneven expert load), others with loss-free bias balancing update rules; proposed K-Means router uses no training/router gradients, just exponential moving averages of routed tokens per expert for centroids and bias updates.
Evaluation protocol: They evaluate router–expert coupling by correlating router scores with expert gate activations on routed tokens, analyzing pairwise cosine similarity between router weight vectors to measure geometric collapse under auxiliary load balancing, and comparing language modeling perplexity and load imbalance metric (MaxVio) across routing variants including auxiliary-loss, loss-free, loss-free+seq-aux, and K-Means routers.
Reproducibility: Code is released at https://github.com/sagearc/router-expert-geometry. The data (OLMoE-mix-0924) and 1B SMoE model setup are referenced from prior work but not included. Training details and hyperparameters are extensively described enabling replication in principle.
Example end-to-end: For a training token with hidden state x routed to expert i, the router weight vector r_i and expert input weights W_gate_i both receive gradient updates along x, accumulating these directions over training. Hence, at inference, a token well-aligned with these directions receives a high router score and strongly activates the expert’s gate neurons. Auxiliary load balancing injects gradients into all router vectors regardless of selection, causing router directions to converge and break this coupling, harming specialization. The parameter-free K-Means router explicitly maintains centroids of routed tokens per expert to preserve this geometric structure and achieves stable routing and load balance without learned parameters.
Technical innovations
- Identification and formal proof that matched router weights and expert input-side weights receive backpropagation gradients proportional to the same input token vector, creating a geometric coupling between router and expert in SMoE models.
- Empirical demonstration that router scores correlate significantly with the internal expert gate neuron activations for the routed tokens, showing functional reflection of routing decisions inside experts.
- Analysis showing that auxiliary load-balancing losses disrupt this router-expert geometric coupling by injecting input-directed gradients into all router directions, leading to near tripling of cosine similarity among distinct router weight vectors.
- Introduction of a novel parameter-free online K-Means router that replaces trainable router weights with exponential moving average centroids of routed hidden states and routes tokens based on cosine similarity, achieving superior load balancing with minimal perplexity degradation.
Datasets
- OLMoE-mix-0924 — ~50B tokens — mixture of C4, Pile, and other public corpora used in prior SMoE language model training
Baselines vs proposed
- Auxiliary-loss router: MaxVio = 0.526, training perplexity = 15.09 vs proposed K-Means router: MaxVio = 0.037, training perplexity = 15.40
- Loss-free bias balancing router: MaxVio = 0.084, training perplexity = 15.01 vs proposed K-Means router: MaxVio = 0.037, training perplexity = 15.40
- Loss-free + seq-wise auxiliary balancing router: MaxVio = 0.102, training perplexity = 15.03 vs proposed K-Means router: MaxVio = 0.037, training perplexity = 15.40
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12476.
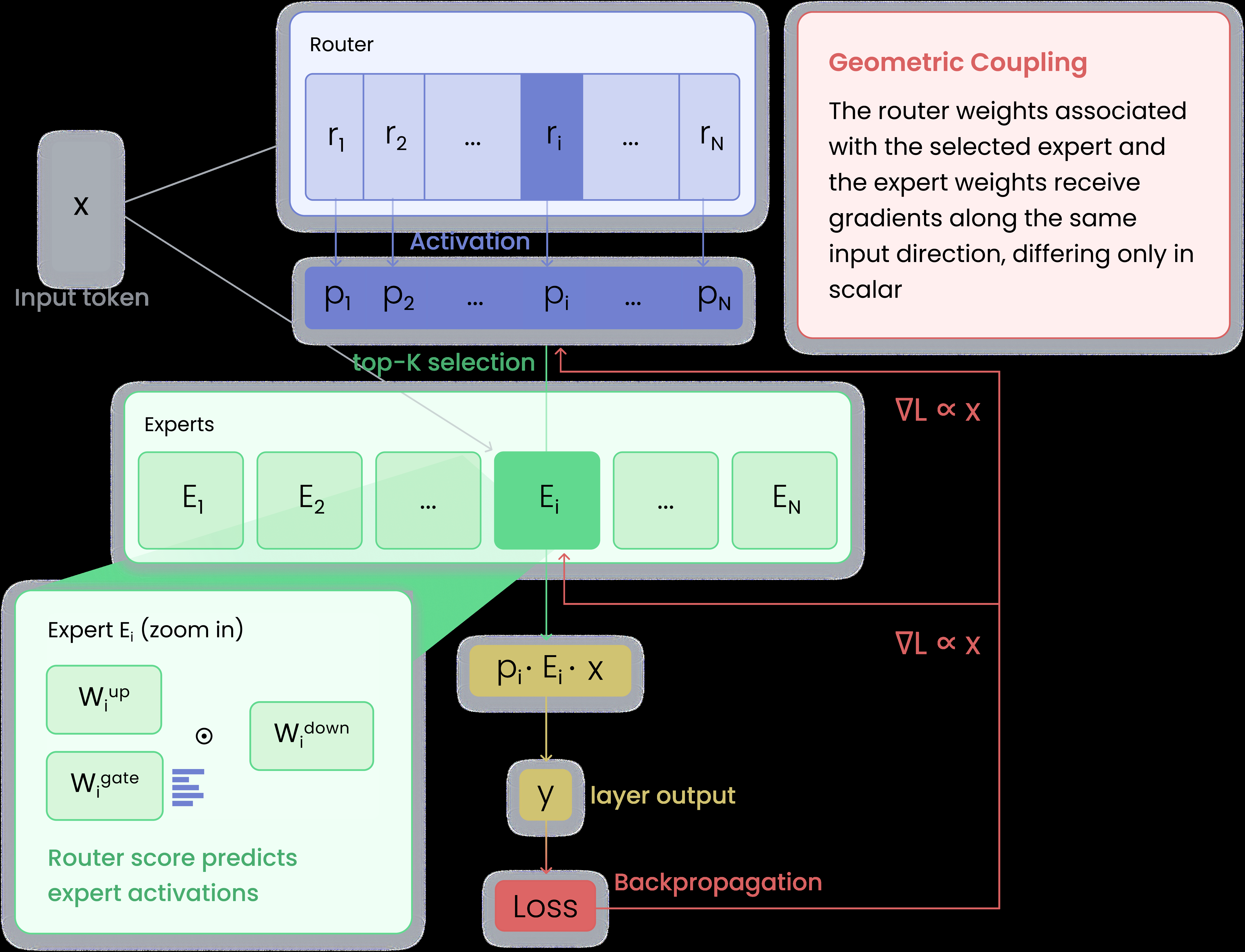
Fig 1: Router–expert geometric coupling in SMoEs. The router scores a hidden state x and
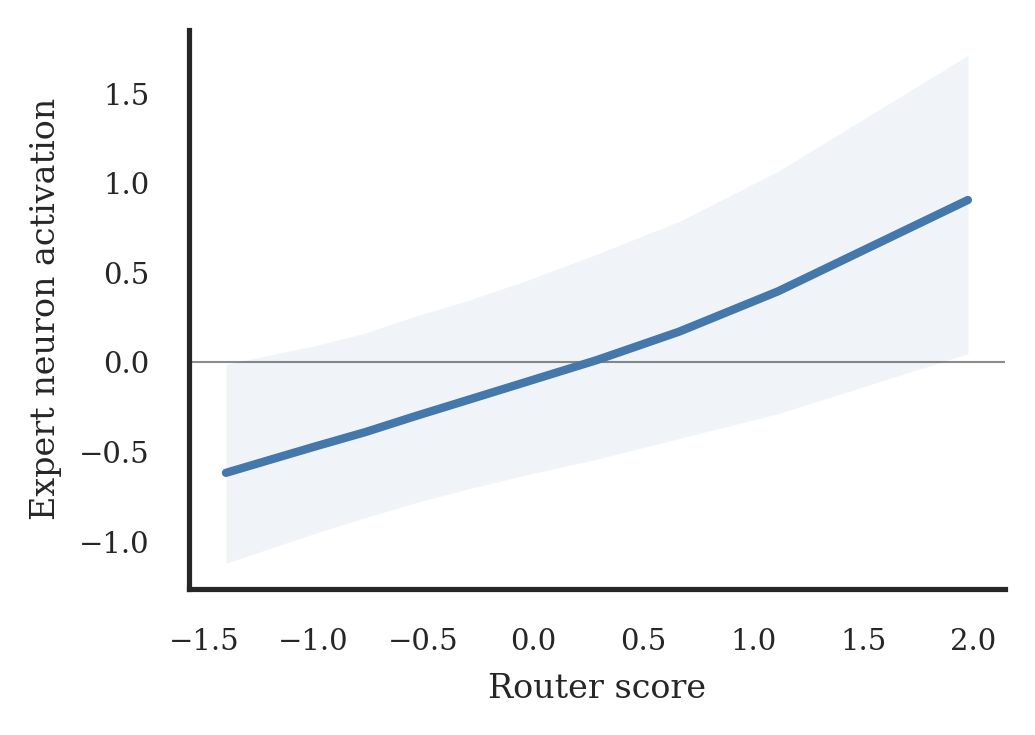
Fig 2: Expert activations increase with
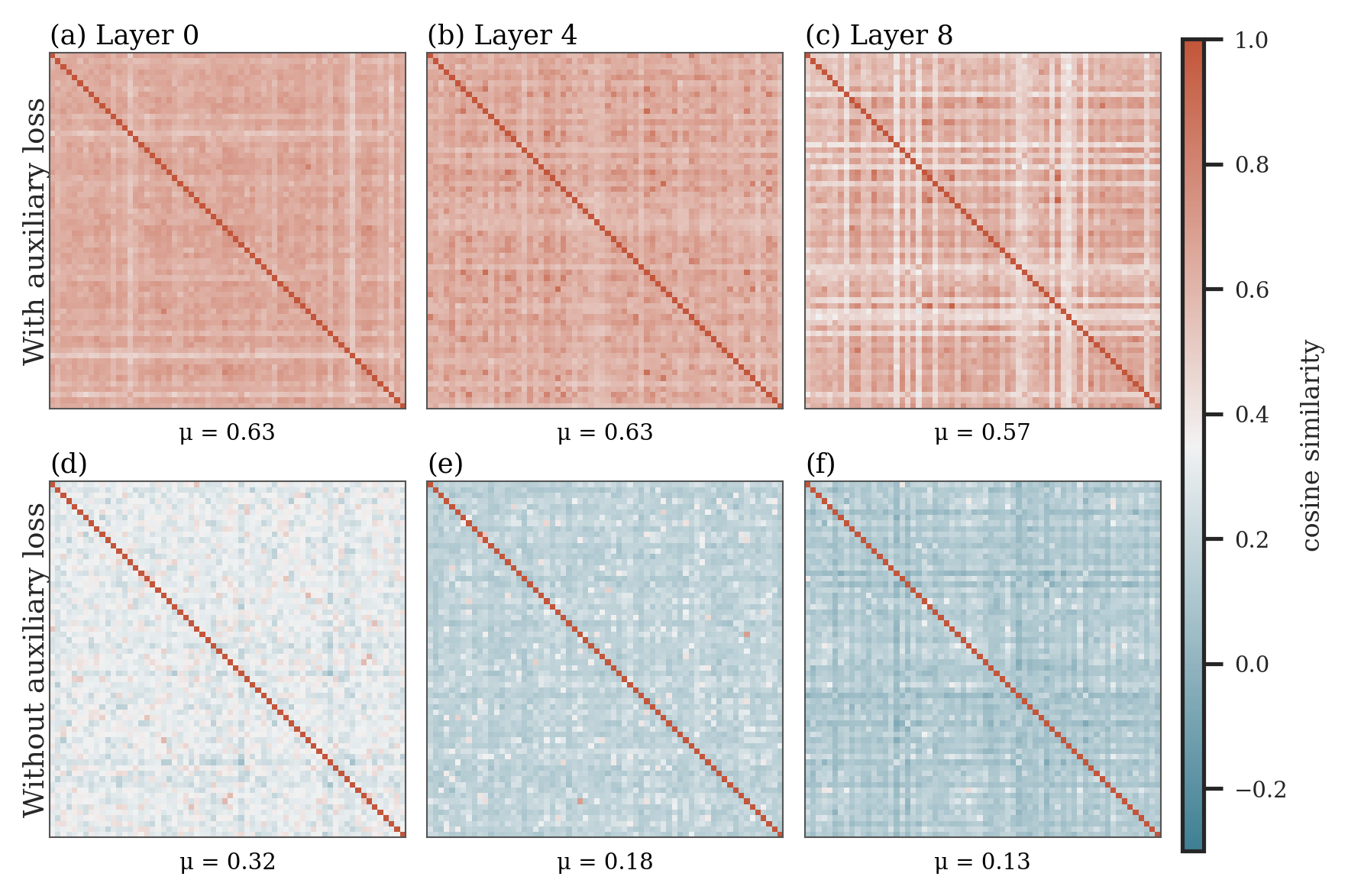
Fig 3: Auxiliary loss collapses router geometry. Each panel shows pairwise cosine similarities
Limitations
- Empirical validation is limited to a single 1B parameter SMoE model and training setup; it is unclear if geometric coupling and K-Means router advantages fully generalize to larger or different architectures.
- Analysis of geometric coupling focuses primarily on the expert gate weights (W_gate_i) and gate neuron activations; coupling effects on other expert weights (e.g., W_up_i) and broader activations remain unexamined.
- The paper does not address routing instabilities beyond load imbalance, such as expert collapse or dominance, or evaluate adversarial routing attacks or distributional shifts.
- The K-Means router, while interpretable and stable, results in a modest perplexity increase, indicating it does not fully capture all benefits of learned router weights and more flexible routing decisions.
- Auxiliary load-balancing loss effects are analyzed mainly through geometric similarity metrics, without extensive downstream language modeling or generalization impact evaluations.
- The work does not explore integration with alternative balancing methods or hybrid routers that might preserve coupling while restoring expressiveness.
Open questions / follow-ons
- Does router–expert geometric coupling hold and behave similarly in larger-scale SMoEs with tens or hundreds of billions of parameters or different expert architectures?
- How does geometric coupling manifest in other expert weight parameters beyond the input-side gating weights, and what impact does that have on specialization and routing?
- Can hybrid routing algorithms be designed combining parameter-free centroid tracking with a learned component to close the perplexity gap without breaking geometric coupling?
- What is the full impact of routing geometry distortions caused by other balancing mechanisms, representation collapse, or routing bottlenecks on SMoE performance and stability?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners engineering SMoE-based language models or modular networks, this paper offers a deep mechanistic understanding of routing dynamics—a key factor impacting model specialization, efficiency, and stability. It suggests that preserving the natural geometric coupling between routers and experts is critical to maintaining expert specialization and balanced workload, which influence inference latency and model robustness. Intervention strategies like auxiliary load-balancing losses, though improving token distribution, may harm specialization by inducing router vector collapse and eroding assignment geometry, potentially degrading performance under diverse input distributions. The proposed centroid-based K-Means router exemplifies a gradient-free and explicit routing mechanism maintaining expert-specific geometry and avoiding interference gradients, producing highly balanced expert usage with minimal performance loss. This insight motivates future routing designs for SMoE layers in security-critical applications that emphasize stability, balance, and interpretability rather than purely optimizing load metrics. Understanding these dynamics could inform defenses against adversarial input routing or targeted expert misuse, where router–expert coupling must be preserved to reliably differentiate expert responsibilities. Overall, such geometric analyses enrich the toolset for designing scalable, robust routing layers relevant to CAPTCHA generation, bot detection NLP models, or security-focused model partitioning.
Cite
@article{arxiv2605_12476,
title={ Routers Learn the Geometry of Their Experts: Geometric Coupling in Sparse Mixture-of-Experts },
author={ Sagi Ahrac and Noya Hochwald and Mor Geva },
journal={arXiv preprint arXiv:2605.12476},
year={ 2026 },
url={https://arxiv.org/abs/2605.12476}
}