
Revisiting Photometric Ambiguity for Accurate Gaussian-Splatting Surface Reconstruction
Source: arXiv:2605.12494 · Published 2026-05-12 · By Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xiaohan Yu, Lin Gu et al.
TL;DR
AmbiSuR addresses a specific failure mode in Gaussian-splatting surface reconstruction: when photometric supervision is ambiguous or incomplete, optimization can converge to overblown primitives, redundant geometry, or incorrect surface explanations that still satisfy pixel-level color loss. The paper’s core claim is that this is not just a problem of weak regularization; there are two built-in representation-level ambiguities in 3D Gaussian Splatting itself, and the authors try to remove them directly instead of only adding external priors.
The proposed solution has two pieces. First, a photometric disambiguation stage truncates Gaussian tails and adds a ray-color consistency term so that primitives along a ray are encouraged to share similar appearance rather than colluding to match the same pixel color with different colors. Second, a spherical-harmonics-based ambiguity indicator uses the magnitude of higher-order SH coefficients to identify likely ambiguous primitives, then selectively applies local normal regularization only where the reconstruction is underconstrained. On DTU, Tanks and Temples, and Mip-NeRF 360, the method reports consistent gains over prior 3DGS-based surface methods, especially in ambiguous or reflective regions, while remaining compatible with both monocular and metric depth priors.
Key findings
- On DTU, AmbiSuR and AmbiSuR-MONO both report the best mean Chamfer distance of 0.46, improving over GeoSVR’s 0.47 and PGSR’s 0.52 in Table 1.
- On Tanks and Temples, AmbiSuR reports the best mean F1-score of 0.59, compared with PGSR at 0.58 and GeoSVR at 0.49 in Table 2.
- The Gaussian Primitive Truncation ablation improves TnT precision/recall/F1 from 0.506/0.551/0.522 (baseline A) to 0.530/0.575/0.547 (item B), before adding the full disambiguation stack.
- Adding Ray-Color Consistency further raises TnT F1 from 0.558 (item C) to 0.566 (item D) and to 0.576/0.589 in later combined settings (items G/H), showing it is not redundant with truncation.
- The SH ambiguity indicator ablation on DTU reduces the reported d-to-s / s-to-d / Cf-Dist from 0.436 / 0.519 / 0.477 (Naive) to 0.419 / 0.504 / 0.461 with the full model in Table 5.
- On Mip-NeRF 360 outdoor scenes, AmbiSuR matches the best reported SSIM in the surface-reconstruction group at 0.752 and reports LPIPS 0.202, tied with or comparable to strong baselines like PGSR (0.752 / 0.203).
- The paper reports training all models for 30,000 iterations on RTX 3090 Ti GPUs, with AmbiSuR’s stated runtime around 0.6h on DTU in Table 1, similar to PGSR (0.5h) and faster than many implicit baselines.
Threat model
The adversary is the scene’s photometric ambiguity: imperfect multi-view consistency caused by textureless, reflective, dark, occluded, or sparsely observed regions that make the inverse problem ill-posed. The method assumes calibrated multi-view images and access to depth/normal priors from external estimators or foundation models; it does not attempt to handle unknown camera poses, maliciously corrupted labels, or adversarially manipulated images. It also assumes that only a small fraction of primitives are ambiguous at each step so that selective regularization remains effective.
Methodology — deep read
The paper assumes the standard surface-reconstruction threat model used in optimization-based multi-view methods: the algorithm is given calibrated multi-view images and must recover geometry even when photometric constraints are imperfect, locally ambiguous, or view-dependent. The adversary here is not a malicious attacker but the data itself: textureless regions, reflections, dark areas, occlusions, and incomplete coverage create underdetermined photometric supervision. The authors explicitly position their work against the failure case where pixel-wise photometric losses can be satisfied by wrong geometry, and they assume access to geometry priors derived from foundation models or depth estimation. They also state that their ambiguity-indication strategy should work with different prior sources, but the strongest configuration uses metric depth from multi-view estimates, while a more broadly compatible variant uses monocular depth.
For data, they evaluate on three standard benchmarks: DTU, Tanks and Temples, and Mip-NeRF 360. The paper follows standard scene splits from prior work, but the excerpt does not enumerate exact train/test counts per split. DTU and TnT images are preprocessed following prior pipelines (they cite 2DGS and Neuralangelo for preprocessing), and they apply 2× image downsampling on DTU and TnT; for Mip-NeRF 360 they use 2× or 4× downsampling depending on whether the scenes are indoor or outdoor. Depth priors are taken from Depth Anything 3 for metric/multi-view depth and Depth Anything V2 for the monocular variant. The paper does not describe a custom labeled dataset; instead, it inherits standard benchmark geometry and evaluation protocols. Mesh extraction is done with TSDF. A concrete example: on a DTU scene, the model starts from a point-cloud/3DGS initialization, trains for 30k iterations, uses depth prior loss plus the proposed ambiguity terms, and finally extracts a mesh via TSDF for Chamfer evaluation against the DTU ground truth mesh.
Architecturally, AmbiSuR builds on a 3D Gaussian Splatting representation where each primitive has center, scale, rotation, opacity, and SH coefficients for color. The first contribution is Gaussian Primitive Truncation: instead of letting each Gaussian’s low-opacity tail participate in rendering, they keep only a core region defined by a distance threshold of γσ with γ = 2. In practice, the rendered opacity uses only this truncated core. Their argument is that the edge of a Gaussian can cover a large spatial area with very low opacity, producing weak gradients and ambiguous overlap; truncation removes this “overblown edge” behavior in a representation-agnostic way. The second part of disambiguation is Ray-Color Consistency. For a ray intersecting N Gaussians, they reinterpret the blended pixel color as an expectation over per-primitive colors and penalize the weighted variance along the ray: if several primitives contribute to one pixel, they should have similar colors rather than using blending to hide geometry mistakes. This term detaches all variables except the primitive colors during its computation, making it a direct regularizer on appearance consistency rather than a second rendering loss.
The second main module, Spherical Harmonics Ambiguity Indication, uses the SH color representation itself as an ambiguity signal. The authors decompose each primitive’s color into an isotropic component and higher-order residual components, then define ambiguity score ISH as the squared L2 norm of the higher-order SH coefficients. Their rationale is that large high-degree coefficients indicate strong view dependence, which may correspond either to genuine view-dependent appearance or to an ambiguous / underconstrained primitive. They therefore use a dual-end selection rule: primitives with the largest ISH values are flagged as high-risk, and primitives with extremely small ISH values are also flagged because they can correspond to poor optimization or incorrectly baked appearances. This is not a global regularizer; only a small selected set of primitives is regularized at each iteration. The regularizer itself is built around a depth-derived normal loss using a geometry prior normal map. The paper also separates parameters carefully: the ambiguous primitives are targeted while the rest are frozen, and opacity and scaling are excluded from the regularized parameters to avoid destabilizing the surface. The regularization mask is amorphous, meaning it can cover fragmented, discrete regions after projection rather than assuming contiguous planar patches.
Training and optimization are comparatively simple. All models are trained for 30,000 iterations, aligned with 3DGS defaults, on RTX 3090 Ti GPUs. The total loss is L = Lphoto + 0.1 Lgeo + 0.1 N + 1e-5 R, where Lphoto is the backbone photometric loss, Lgeo is a prior-based geometric loss, N is the amorphous local regularizer, and R is the ray-color consistency term. For the full AmbiSuR model, the geometric prior is an L1 loss between rendered depth and prior depth, normalized by scene range; for AmbiSuR-MONO, they use a patch-depth loss with monocular depth under standard SfM initialization. The paper states that ηU is 5% for the upper SH indicator, and ηL is 10% on DTU and 5% on the other datasets. The excerpt does not provide learning rates, optimizer choice, batch size, or random seed strategy, so those details remain unclear from the supplied text.
Evaluation is by standard geometry and rendering metrics. For surface reconstruction on DTU and TnT, they report Chamfer distance and F1-score, and for appearance reconstruction on Mip-NeRF 360 they report PSNR, SSIM, and LPIPS. Baselines include implicit methods such as NeuS, Neuralangelo, Geo-NeuS, MonoSDF; explicit/3DGS-derived methods such as 2DGS, GOF, GS2Mesh, VCR-GauS, PGSR, GeoSVR, MILo; and on TnT also SVRaster and NeuRodin. The ablation protocol is fairly detailed: they isolate truncation, ray-color consistency, and SH ambiguity indication, and within the SH module they test dual-end selection, upper-only, lower-only, removing the amorphous mask, and removing parameter separation. The reported results suggest that each component contributes, with the full model best or near-best in each table. Reproducibility is partial: the paper provides a project page and compares against standard benchmarks, but the excerpt does not include code release details, frozen checkpoints, or whether all evaluation assets are public beyond the benchmarks themselves.
Technical innovations
- Gaussian Primitive Truncation removes low-opacity Gaussian tails by retaining only a core region defined by ∥x−µi∥ ≤ 2σi, aiming to suppress edge-induced over-reconstruction.
- Ray-Color Consistency regularizes the weighted variance of per-primitive colors along a ray, turning blended photometric supervision into a primitive-wise appearance constraint.
- The SH Ambiguity Indicator uses the L2 norm of higher-order spherical-harmonics coefficients as a proxy for photometric ambiguity, instead of treating SH only as a view-dependent color basis.
- Dual-end primitive selection flags both very high and very low SH-ambiguity scores, reflecting the authors’ claim that both strongly view-dependent and underfit primitives can be problematic.
- The amorphous local regularizer applies prior-based normal supervision only to ambiguous primitives, with explicit parameter separation to avoid destabilizing opacity and scale.
Datasets
- DTU — standard DTU benchmark split — public benchmark
- Tanks and Temples — standard Tanks and Temples split — public benchmark
- Mip-NeRF 360 — standard Mip-NeRF 360 split — public benchmark
Baselines vs proposed
- NeuS: DTU mean Chamfer = 0.84 vs proposed AmbiSuR = 0.46
- Neuralangelo: DTU mean Chamfer = 0.61 vs proposed AmbiSuR = 0.46
- Geo-NeuS: DTU mean Chamfer = 0.51 vs proposed AmbiSuR = 0.46
- PGSR: DTU mean Chamfer = 0.52 vs proposed AmbiSuR = 0.46
- GeoSVR: DTU mean Chamfer = 0.47 vs proposed AmbiSuR = 0.46
- PGSR: Tanks and Temples mean F1 = 0.58 vs proposed AmbiSuR = 0.59
- GeoSVR: Tanks and Temples mean F1 = 0.49 vs proposed AmbiSuR = 0.59
- GeoSVR: Mip-NeRF 360 outdoor PSNR = 24.83 vs proposed AmbiSuR = 24.79
- PGSR: Mip-NeRF 360 outdoor SSIM = 0.752 vs proposed AmbiSuR = 0.752
- PGSR: Mip-NeRF 360 indoor LPIPS = 0.147 vs proposed AmbiSuR = 0.159
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12494.

Fig 1: In challenging scenarios with ambiguous photometric
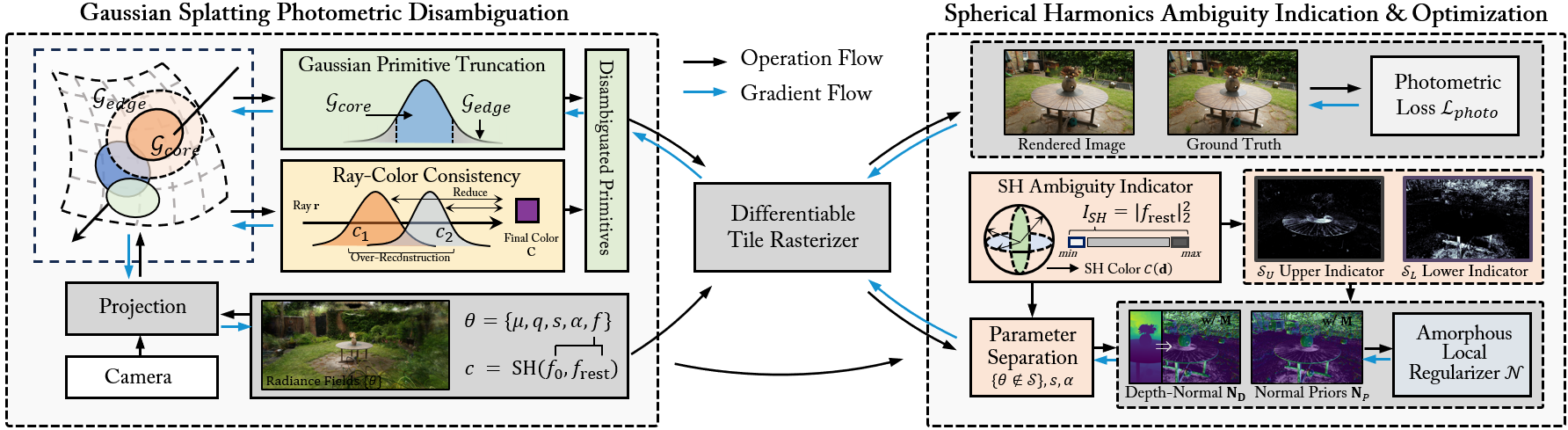
Fig 2: Overview of AmbiSuR. Our approach stems and operates from two perspectives: (a) Representationally, two disambiguation

Fig 3: Illustration of Dual-End Indication. On the free-lunch
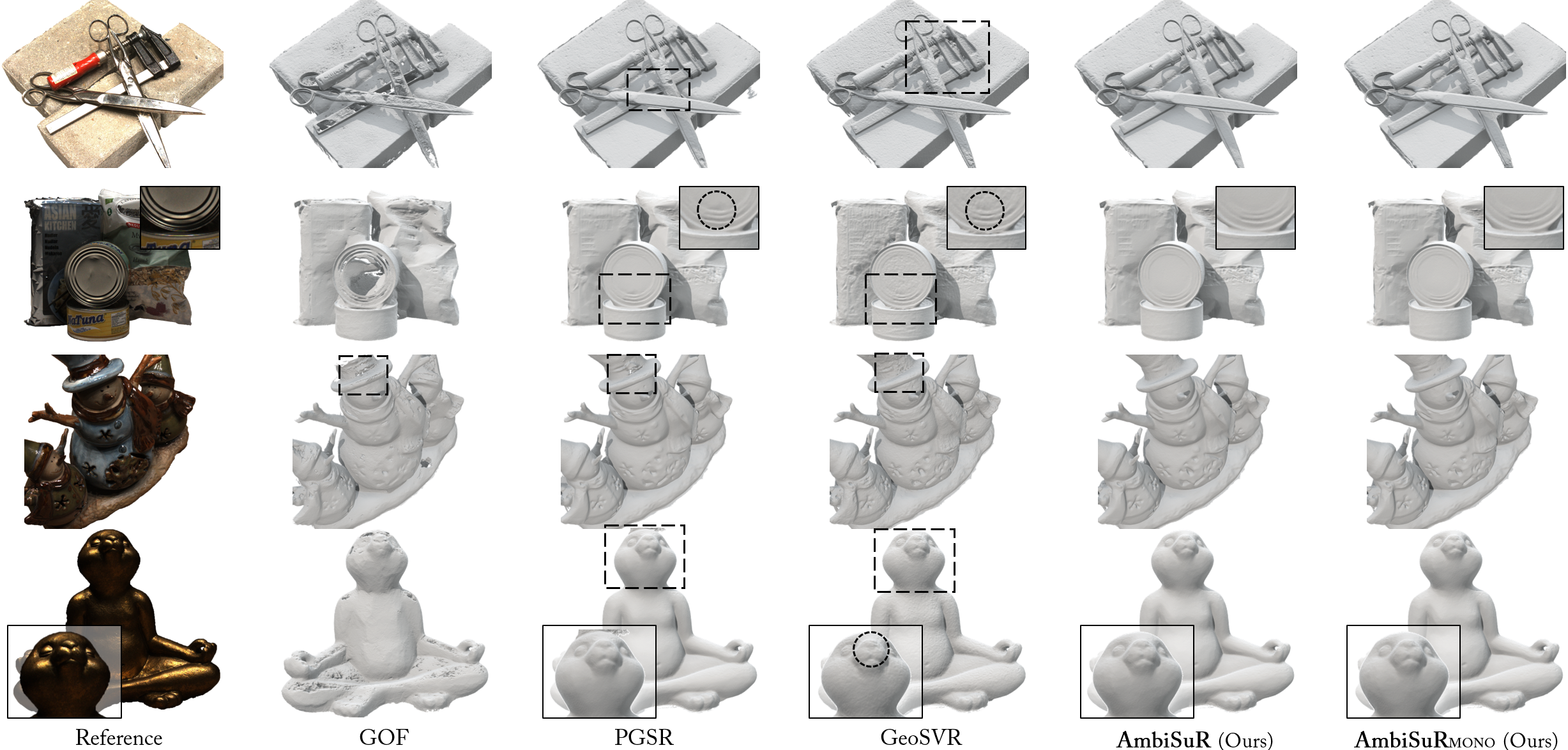
Fig 4: Reconstructed Mesh Comparison on the DTU (Jensen et al., 2014) Dataset. AmbiSuRs consistently reconstruct high-quality

Fig 5: Reconstructed Mesh Comparison on the Tanks and Temples (Knapitsch et al., 2017) Dataset with high-performing baselines.

Fig 6: Mesh Comparison on the Mip-NeRF 360 Dataset.

Fig 7: Visualized Effect of Gaussian Primitive Truncation.

Fig 8: Visualized Effect of Ray-Color Consistency. Solely
Limitations
- The excerpt does not specify optimizer, learning-rate schedule, batch size, or seed strategy, so exact training reproducibility is incomplete from the provided text.
- The method depends on geometry priors from depth/normal estimation; if those priors are poor or biased, the selective regularization may reinforce errors rather than correct them.
- The SH ambiguity score is heuristic: high higher-order SH energy can indicate true view-dependent appearance as well as ambiguity, so the dual-end selection may misclassify some primitives.
- The paper evaluates on standard benchmarks, but the excerpt does not show a dedicated cross-dataset or severe distribution-shift study beyond DTU/TnT/Mip-NeRF 360.
- There is no adversarial or robustness evaluation against intentional perturbations, corrupted calibration, or extreme sparse-view conditions in the supplied text.
- The reported gains are strongest in ambiguous regions, but appearance reconstruction on Mip-NeRF 360 is not uniformly better than all baselines, indicating a trade-off between surface quality and view synthesis quality.
Open questions / follow-ons
- Can the SH-based ambiguity score be calibrated to distinguish true view-dependent appearance from genuinely ambiguous geometry without relying on heuristics like top/bottom percentiles?
- How well do the truncation and ray-color consistency terms transfer to other explicit radiance-field or mesh-optimization frameworks beyond PGSR?
- What happens when the geometry prior is systematically biased, for example on reflective indoor scenes where monocular depth fails or on very sparse-view captures?
- Can the ambiguity indication mechanism be made more principled by learning uncertainty directly instead of using SH coefficient magnitude as a proxy?
Why it matters for bot defense
For bot defense and CAPTCHA systems, the main takeaway is methodological rather than domain-specific: the paper is about identifying where an optimization objective is underconstrained and then using an internal representation signal to localize the ambiguous cases. In CAPTCHA/anti-bot work, analogous failures happen when a classifier or policy can satisfy surface-level losses while relying on shortcuts, spurious correlations, or unstable features. The SH-indicator idea is a reminder that sometimes the model already contains a useful uncertainty signal, and that signal can be used to apply stronger supervision only where needed instead of globally tightening everything.
A bot-defense engineer could translate this into selective hardening: detect uncertain or highly view-dependent examples, isolate them, and apply more expensive verification, higher-fidelity features, or stronger priors only on that subset. The truncation idea is also relevant as a reminder to remove low-signal, high-variance feature tails that contribute little predictive power but increase false matches. The key reaction is not to copy the method, but to think in terms of representation-level ambiguity, selective regularization, and local rather than global enforcement.
Cite
@article{arxiv2605_12494,
title={ Revisiting Photometric Ambiguity for Accurate Gaussian-Splatting Surface Reconstruction },
author={ Jiahe Li and Jiawei Zhang and Xiao Bai and Jin Zheng and Xiaohan Yu and Lin Gu and Gim Hee Lee },
journal={arXiv preprint arXiv:2605.12494},
year={ 2026 },
url={https://arxiv.org/abs/2605.12494}
}