
Power, Prescription, and Postpositivism: Considerations for collecting and representing neurodiversity demographic information in physics education research
Source: arXiv:2605.12609 · Published 2026-05-12 · By Mason D. Moenter, George R. Keefe, Liam G. E. McDermott, Erin M. Scanlon
TL;DR
This paper critically examines the current practices around collecting and representing neurodiversity demographic information in physics education research (PER) and broader STEM education research. The authors identify major inconsistencies and methodological issues in how neurodivergent identities are categorized, often relying on prescriptive approaches that require official diagnoses or impose predetermined categories. These practices risk erasing the complexity and authenticity of participants' self-identified neurodivergent experiences and identities, thereby reducing data trustworthiness and interpretive power. The study systematically reviewed 2,469 sources and narrowed them to 47 relevant papers focusing on neurodivergent undergraduate STEM learning, performing a thematic analysis of demographic data collection methods. They find a spectrum of descriptive versus prescriptive and individual versus hyper-aggregate approaches, with nearly two thirds of studies falling into hyper-aggregate or prescriptive categories that oversimplify or misrepresent neurodivergent identities.
The core contribution is a set of guidelines aligned with Disability Critical Race Theory (DisCrit) principles that advocate for a participant-centered, descriptive "bottom-up" approach to demographic data collection. The NEURO-ID framework encourages collecting open-ended self-identifications from participants and then categorizing them reflectively rather than imposing preset labels or overly broad groupings. This framework aims to improve both ethical inclusion and empirical rigor by respecting individual experiences while preserving meaningful analytic use. The authors call on the PER community to adopt this more nuanced, intersectional, and justice-oriented framework for neurodivergent demographic data moving forward.
Key findings
- From 2,469 sources sifted, only 47 focused on neurodivergent undergraduate STEM learning and performance.
- 41.3% (19) of sources used a hyper-aggregate-prescriptive approach to demographic data collection, broadly categorizing neurodivergence with predetermined labels.
- 34.8% (16) of sources employed an individual-descriptive approach collecting participant self-identifications in their own words.
- 23.4% of papers listed 'learning disability' as a broad category, with many failing to disaggregate or define specific learning disabilities.
- Two-thirds (65.2%) of sources either hyper-aggregated data or prescribed participant identity categories, limiting trustworthiness and inclusivity.
- Thematic analysis identifies four demographic data collection categories: descriptive, prescriptive, hyper-aggregate, and individual, which form a spectrum rather than binary groups.
- Authors propose NEURO-ID, a bottom-up, descriptivist demographic data collection framework that builds categories from participant self-descriptions to avoid erasing individual identities.
- The guidelines align with DisCrit theory, emphasizing intersectionality, social constructions of identity, participant autonomy, and rejecting medical-model categorizations.
Methodology — deep read
The study adopts a postpositivist and social constructivist theoretical framework which emphasizes participant autonomy and the sociopolitical contexts of identity. It centers on the assumption that neurodivergent identities are fluid and socially constructed, requiring researchers to act as secondary interpreters of participant self-identifications.
Data were collected through a large-scale systematic literature review starting with 2,469 sources from diverse publication types (peer-reviewed articles, theses, dissertations) related to neurodivergent STEM learning and performance. From this, a corpus of 47 focused studies on undergraduate neurodivergent STEM learners was identified. These 47 sources were annotated, collecting metadata such as sample size and demographic data reporting approaches.
The core analysis was a qualitative thematic analysis performed by two authors who inductively coded how demographic data were collected and represented across the corpus. They categorized studies on a descriptive-to-prescriptive dimension (whether demographic categories were participant-derived or imposed) and an individual-to-hyper-aggregate dimension (granularity of categories).
The resulting four-category schema (descriptive-individual, descriptive-hyper-aggregate, prescriptive-individual, prescriptive-hyper-aggregate) was visualized and quantified (Fig. 2). Examples of studies in each category were referenced to illustrate differing approaches.
Using this empirical foundation, the authors synthesized guidelines (NEURO-ID) for demographic data collection grounded in Disability Critical Race Theory (DisCrit). The recommendations prioritize: open-ended self-identification questions; construction of analytic categories from participant descriptions; attentiveness to intersectionality and social constructions of disability; inclusion of neurodivergent scholars in research design; and ethical considerations to avoid ableist or medical-model framings.
The study is largely qualitative and interpretive. It does not perform new quantitative experiments; rather it investigates research practice across a defined body of literature, highlights methodological gaps, and proposes a conceptual and ethical framework. The authors acknowledge that demographic data collection is inherently complex and messy, advocating for practices that reflect lived experience over imposed categorization.
The research team’s positionality includes neurodivergent and neurotypical members with varied identities, strengthening interpretive depth. The corpus and code details beyond descriptions in the paper are not released publicly. The framework is a call to action for the PER community rather than a tested software or algorithm.
Technical innovations
- Systematic thematic analysis categorizing neurodivergent demographic data collection along descriptive-prescriptive and individual-hyper-aggregate spectra.
- Proposal of NEURO-ID: a bottom-up, descriptivist framework that builds demographic categories from participant self-identifications instead of imposing diagnostic or preset labels.
- Integration of Disability Critical Race Theory (DisCrit) principles into demographic data collection guidelines to address intersectionality and social constructions in PER research.
- Critical distinction and rejection of hyper-aggregated and prescriptive demographic practices common in STEM education research that oversimplify neurodivergent identities.
Datasets
- Systematic literature corpus — 2,469 initial sources sifted, 47 sources used in qualitative thematic analysis — literature from STEM education research on neurodivergent undergraduate learners
Baselines vs proposed
- Hyper-aggregate-prescriptive approach: N=19 papers (41.3%) vs individual-descriptive approach: N=16 papers (34.8%) in demographic data collection
- 23.4% of papers use broad 'learning disability' categories without detailed disaggregation vs more descriptive papers that use participant self-words
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12609.
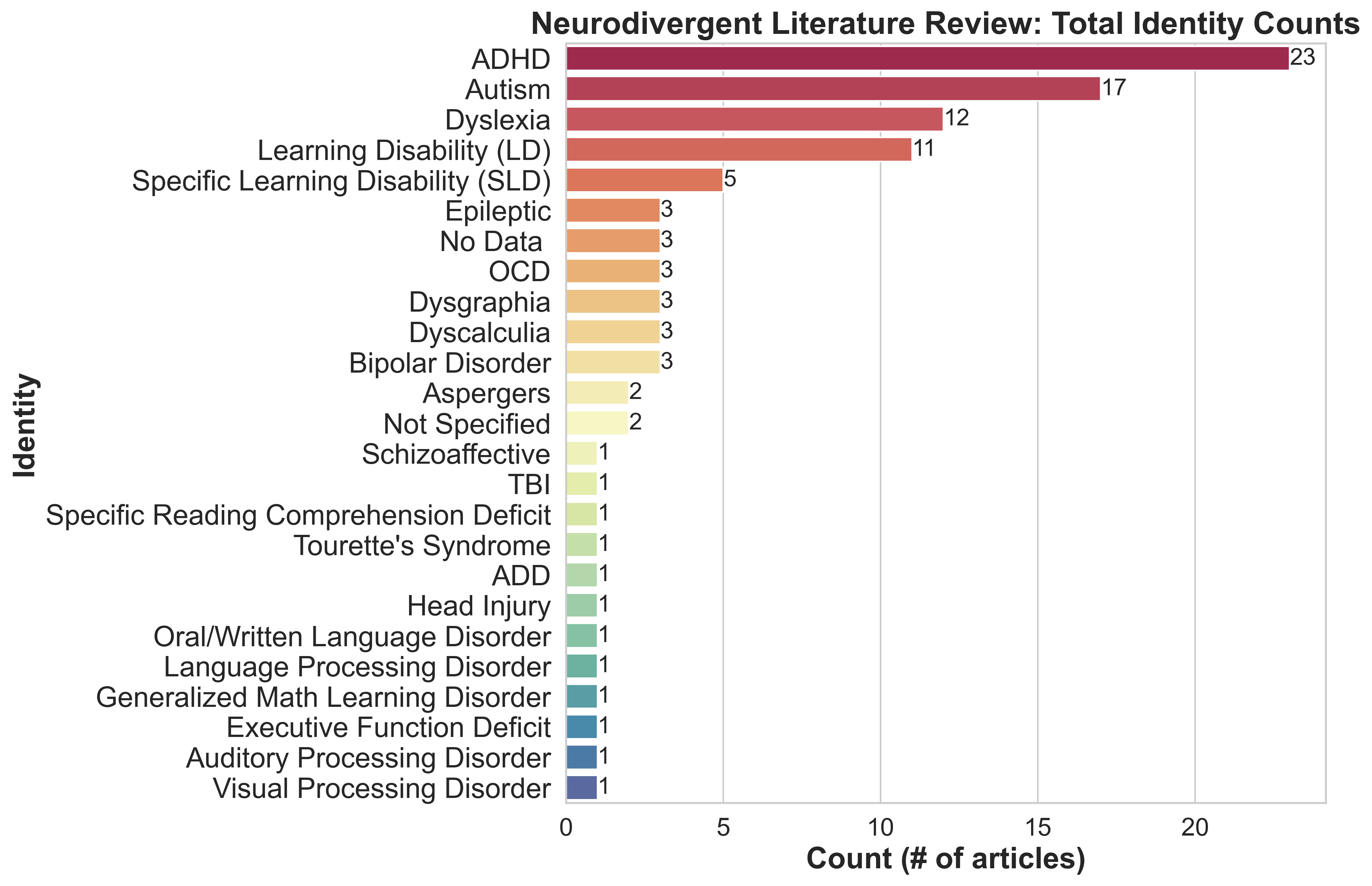
Fig 1: shows a breakdown of demographic representa-
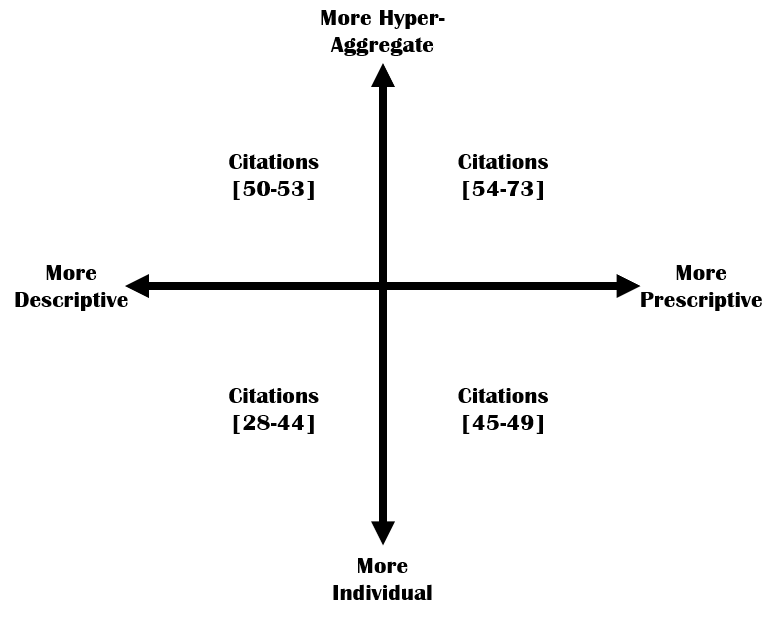
Fig 2: The four demographic data categories visualized

Fig 3: The NEURO-ID approach to demographic data collec-

Fig 4 (page 5).

Fig 5 (page 5).
Limitations
- Study is based on published literature, so conclusions depend on completeness and scope of corpus; potential publication bias.
- No direct new empirical data collection from neurodivergent participants; conclusions rely on secondary interpretation of existing studies.
- Positionality and interpretation inherently subjective; different researchers might categorize some studies differently.
- Recommendations reflect conceptual and ethical frameworks but lack quantitative validation or tested impact on research outcomes.
- The code and dataset (annotated bibliography and inductive codes) are not publicly shared, limiting reproducibility.
- Focused on neurodivergent undergraduate STEM learners; may not generalize to other populations or domains.
Open questions / follow-ons
- How do bottom-up demographic data collection approaches impact empirical findings and statistical conclusions in PER?
- What methods can improve scalability and standardization of descriptive demographic frameworks like NEURO-ID while preserving participant nuance?
- How can intersectional data on neurodivergence, race/ethnicity, gender, and other identities be effectively modeled and analyzed in education research?
- What are best practices for ethical dissemination and reporting of complex, participant-driven demographic data?
Why it matters for bot defense
While this paper does not directly address bot defense or CAPTCHA systems, its core insights about demographic data collection and representation have indirect relevance to user verification and access control research. Key takeaways for bot-defense engineers include the pitfalls of prescriptive, overly rigid categorizations of participant or user attributes that may oversimplify or misrepresent authentic user diversity. The NEURO-ID framework advocates for participant-centered, descriptive data collection that respects individual identity and lived experience—a principle that can inform more inclusive and equitable user profiling in security systems. Furthermore, understanding intersectional identities and avoiding hyper-aggregated, monolithic categories can improve the fairness and accuracy of adaptive bot detection or user-challenge systems by accounting for complex user heterogeneity. Researchers working on CAPTCHAs or behavioral biometrics might consider descriptive, user-driven data collection methodologies to better capture genuine variability and reduce bias. However, concrete application would require further work to translate these qualitative social science insights into mechanistic or algorithmic features for bot defense.
Cite
@article{arxiv2605_12609,
title={ Power, Prescription, and Postpositivism: Considerations for collecting and representing neurodiversity demographic information in physics education research },
author={ Mason D. Moenter and George R. Keefe and Liam G. E. McDermott and Erin M. Scanlon },
journal={arXiv preprint arXiv:2605.12609},
year={ 2026 },
url={https://arxiv.org/abs/2605.12609}
}