
LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues
Source: arXiv:2605.12493 · Published 2026-05-12 · By Di Wu, Zixiang Ji, Asmi Kawatkar, Bryan Kwan, Jia-Chen Gu, Nanyun Peng et al.
TL;DR
LongMemEval-V2 (LME-V2) is a benchmark for a specific kind of memory problem that prior agent-memory evaluations mostly did not isolate: can a memory system turn long, noisy web-agent experience into reusable environment knowledge? Instead of asking whether an agent remembers a user’s personal facts or whether it can solve a downstream task after seeing long history, the paper asks whether it can act like an experienced colleague inside a customized web environment, retaining interface details, state transitions, workflows, recurring failure modes, and invalid assumptions.
The benchmark contains 451 manually curated questions drawn from WebArena, WorkArena, and WorkArena++ trajectories, with up to 500 trajectories and 115M tokens in the larger setting. The authors define five memory abilities, use a context-gathering formulation (Insert + Query + fixed reader), and compare simple RAG-style memory to a coding-agent-based memory controller. The main empirical result is that the coding-agent approach, AgentRunbook-C, is best overall, reaching 72.5% average accuracy in the authors’ headline summary and 74.9% on LME-V2-Small / 70.1% on LME-V2-Medium in Table 2, while substantially outperforming the strongest RAG baseline but at much higher latency than lightweight retrieval.
Key findings
- LME-V2 contains 451 manually curated questions spanning five memory abilities: static state recall, dynamic state tracking, workflow knowledge, environment gotchas, and premise awareness.
- The benchmark uses large trajectory haystacks: LME-V2-Small has 100 trajectories and about 25.6M tokens; LME-V2-Medium has 498 trajectories and about 114.8M tokens (Figure 3 / Table 1 text).
- Frontier LLMs without trajectory history perform very poorly on non-abstention questions; the best no-context pilot result is 14.1% overall accuracy.
- A simple RAG baseline (query → slice) reaches 42.8% on LME-V2-Small and 38.1% on LME-V2-Medium; adding notes improves to 51.0% and 45.9% respectively (Table 2).
- AgentRunbook-R improves over the strongest RAG baseline to 58.6% on Small and 57.0% on Medium, with about 26.9s and 25.8s query latency respectively (Table 2).
- The off-the-shelf Codex baseline is strong but slow: 69.9% / 68.7% accuracy on Small / Medium with 177.2s / 185.8s latency (Table 2).
- AgentRunbook-C achieves the best reported Table 2 accuracy: 74.9% on Small and 70.1% on Medium, while reducing latency versus Codex to 108.3s and 139.9s.
- The paper reports paired bootstrap significance tests (p < 0.05) for several AgentRunbook results against non-ablation baselines, marked with ✣ in Table 2.
Threat model
The implicit adversary is a long, noisy stream of environment interaction that obscures the few trajectories containing the relevant evidence. The memory system is assumed to receive only the provided history haystack and must answer questions by extracting and compressing evidence from it; it is not allowed to rely on hidden labels or external knowledge. The paper also assumes a fixed downstream reader that only sees truncated memory output, so the memory module itself must decide what to preserve. The benchmark does not model an active hostile attacker who injects deceptive trajectories, tampers with memory, or adapts to the system.
Methodology — deep read
Threat model / task framing: the authors are not modeling an external security adversary in the usual sense; the core “adversary” is informational scarcity and trajectory noise. The memory system is given long histories of past web-agent trajectories and must answer questions about environment-specific experience. The system may only use the provided history; the point of the benchmark is that many questions cannot be answered from parametric knowledge alone. In the pilot study, the best frontier model without context only reaches 14.1% on non-abstention questions, supporting the claim that the benchmark is not solvable by generic world knowledge.
Data provenance and construction: questions are manually curated from multimodal web-agent trajectories collected from three benchmark families: WebArena, WorkArena, and WorkArena++. The paper names the environments as OneStopShop, CMS, Reddit, and ServiceNow. Trajectories were collected using AgentLab2 with a ReAct-style base agent plus Codex, then rejection-sampled with GPT-5.2 and GPT-5-mini as LLMs. The final trajectory pool contains 599 trajectories from WebArena and 941 from WorkArena/WorkArena++, with an overall success rate of 52.0% and an average of 28.1 states per trajectory. The authors say each question is manually annotated by experts, and they filter questions so that strong proprietary LLMs cannot answer from parametric memory alone. Questions come in multiple formats: text-only true/false, multiple choice, short answer, and some gotcha questions framed as a worker message with a screenshot. They also create abstention questions with wrong premises that the model must detect. On average, a question needs evidence from 1.4 trajectories, with a range of 1 to 5.
Benchmark design and labels: LME-V2 has two haystack tiers. LME-V2-Small uses a shared 100-trajectory haystack per environment grouping, and LME-V2-Medium uses roughly 500 trajectories per question. The authors explicitly label answer-bearing trajectories for each question, then assemble haystacks so that the true evidence is sparse. They report that the average oracle answer-bearing set is small relative to the haystack, and Figure 3 shows that the number of answer-bearing trajectories per question is typically low even when the full haystack is large. They also ensure balanced successful and failed trajectories, because many questions are only answerable from failed trajectories (for example, identifying why something went wrong or what assumption was invalid).
Evaluation formulation: the benchmark is cast as a context-gathering problem, not direct QA. A memory system exposes Insert(h) and Query(q). For each question, the system sequentially ingests all trajectories in the question’s haystack, then Query returns compact evidence; this returned context is truncated to 200k tokens and passed to a fixed reader model, Qwen3.5-9B, to produce the final answer. Accuracy is computed with normalized string matching for structured answers and an LLM judge for free-form answers. They also measure query latency, because the paper’s thesis is that memory must be not only accurate but usable in long-running agent loops.
Architecture / algorithm: AgentRunbook-R is a structured RAG memory. At insertion time it creates three knowledge pools: raw state slices centered on trajectory states (to preserve fine-grained UI observations), state-transition events extracted from consecutive states (to model environment dynamics), and procedure/hint notes capturing workflows, navigation patterns, and gotchas. At query time, an LLM controller inspects the question and memory snapshot, then emits multiple retrieval queries: several raw-state queries for exact UI evidence, one event query for key transitions, and one note query for reusable procedural knowledge. Retrieved items are rendered as a multimodal memory context. AgentRunbook-C is a file-based memory/controller hybrid: trajectories are stored as files, and at query time an off-the-shelf coding agent is placed in a sandbox with a workflow document, rendered manifests summarizing memory layout, and helper scripts for operations like viewing a state span or searching within a trajectory. The agent then outputs a structured retrieval package consisting of a short note plus selected trajectory spans. The paper’s novelty here is not a new neural architecture but a controller/interface design: it treats coding agents as file-system memory managers.
Training / implementation / reproducibility: the paper does not describe training a new end-to-end neural model for memory; instead it evaluates prompting, retrieval, and tool-use scaffolding around existing models. The memory controller for RAG is Qwen3.5-9B with Qwen3-Embedding-8B; coding-agent methods use Codex and GPT-5.4-mini at different reasoning settings. The reader is always Qwen3.5-9B. The paper reports latency values and ablations, but the excerpt does not specify optimizer settings, epochs, batch size, or random seed strategy, because there is no conventional model training loop for the main methods. For reproducibility, the paper provides a project website and appendix details, but the excerpt does not confirm whether code, data, or frozen artifacts are fully released.
Concrete example end-to-end: consider the example in Figure 1 from WorkArena/ServiceNow, where one question asks what field appears directly below State after a problem is marked Duplicate and progress changes from Assess to Closed, and another asks for the field that disappears below State. In the benchmark protocol, the memory system first consumes all trajectories in the haystack, including trajectories that may have encountered this exact workflow. For AgentRunbook-R, the controller would likely query the event pool for state transitions around the Duplicate/Assess→Closed sequence, and the raw-state pool for state screenshots or UI labels near the relevant forms. For AgentRunbook-C, the coding agent would inspect the stored trajectory files, possibly search for strings like “Duplicate,” “Assess,” or “Closed,” open the relevant state spans, and produce a compact evidence note. The fixed reader then answers from that compact evidence. This illustrates why the benchmark is harder than standard retrieval: the answer is not a single fact in one document, but a reusable environment-specific observation synthesized across states or trajectories.
Evaluation protocol / baselines / statistical testing: the paper compares no-retrieval, simple query-to-slice RAG, query-to-slice plus notes, AgentRunbook-R, Codex, and AgentRunbook-C, along with ablations removing the raw slice pool, event pool, note pool, workflow instructions, manifest artifacts, or helper functions. Table 2 reports category-wise accuracy on static, dynamic, workflow, and gotcha questions for both Small and Medium tiers, plus latency. The main reported statistical test is a paired bootstrap test with p < 0.05, indicated by ✣. Figure 6 plots the accuracy-latency frontier and shows that AgentRunbook-C shifts the frontier upward relative to plain Codex and RAG baselines. The pilot studies also test whether oracle answer-bearing trajectories or oracle evidence slices improve direct QA, showing that detailed evidence selection matters and that even oracle trajectories are not always enough without better evidence isolation.
Technical innovations
- A new benchmark framing for agent memory: evaluate whether memory systems can convert web-agent trajectories into reusable environment experience, rather than only recalling user history or solving downstream tasks.
- A five-part memory ability taxonomy tailored to web agents: static state recall, dynamic state tracking, workflow knowledge, environment gotchas, and premise awareness.
- A context-gathering evaluation protocol with Insert and Query APIs plus a fixed downstream reader, which measures memory quality directly while keeping the interface practical for agents.
- AgentRunbook-R, a three-pool RAG memory that separates raw state slices, state-transition events, and procedure/hint notes to cover different granularities of evidence.
- AgentRunbook-C, a file-based memory controller that uses a coding agent plus workflow docs, manifests, and helper scripts to inspect trajectories more effectively than vanilla coding-agent prompting.
Datasets
- LME-V2-Small — 100 trajectories shared across questions; 25.6M tokens; built from WebArena / WorkArena / WorkArena++ trajectories
- LME-V2-Medium — roughly 498 trajectories per question; 114.8M tokens; built from WebArena / WorkArena / WorkArena++ trajectories
- Trajectory pool — 599 WebArena trajectories + 941 WorkArena/WorkArena++ trajectories; 52.0% success rate; 28.1 states average
Baselines vs proposed
- No retrieval: overall accuracy = 0.013 on Small vs proposed AgentRunbook-C = 0.749; overall accuracy = 0.013 on Medium vs proposed AgentRunbook-C = 0.701
- RAG: query → slice: overall accuracy = 0.428 on Small vs proposed AgentRunbook-R = 0.586; overall accuracy = 0.381 on Medium vs proposed AgentRunbook-R = 0.570
- RAG: query → slice + notes: overall accuracy = 0.510 on Small vs proposed AgentRunbook-R = 0.586; overall accuracy = 0.459 on Medium vs proposed AgentRunbook-R = 0.570
- Codex: overall accuracy = 0.699 on Small vs proposed AgentRunbook-C = 0.749; overall accuracy = 0.687 on Medium vs proposed AgentRunbook-C = 0.701
- Codex latency: 177.2s on Small vs proposed AgentRunbook-C = 108.3s; 185.8s on Medium vs proposed AgentRunbook-C = 139.9s
- AgentRunbook-R latency: 26.9s on Small and 25.8s on Medium
- AgentRunbook-C ablation – workflow: overall accuracy = 0.701 on Small and 0.641 on Medium vs full AgentRunbook-C = 0.749 / 0.701
- AgentRunbook-C ablation – manifest artifacts: overall accuracy = 0.747 on Small and 0.681 on Medium vs full AgentRunbook-C = 0.749 / 0.701
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12493.
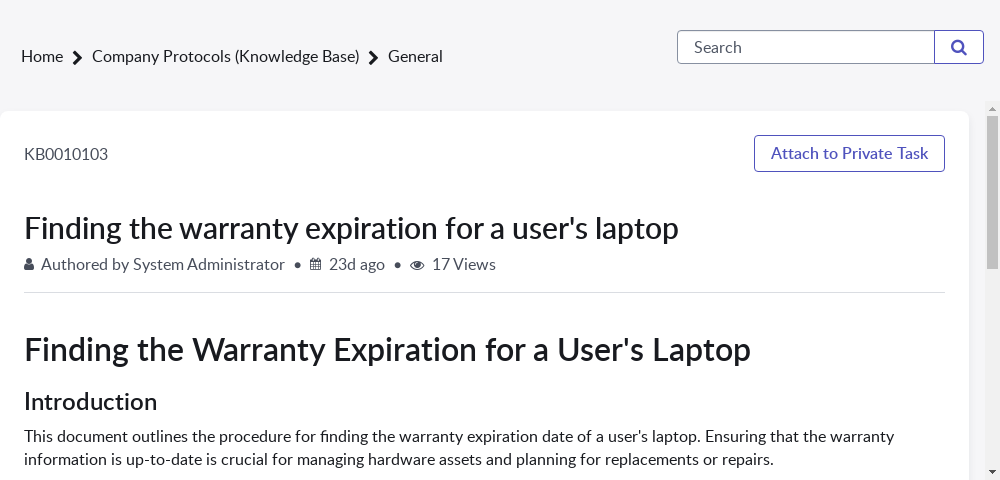
Fig 1: Examples of LongMemEval-V2 questions. We display examples from the WorkArena
Fig 2 (page 2).

Fig 3 (page 2).

Fig 4 (page 2).
Fig 5 (page 2).
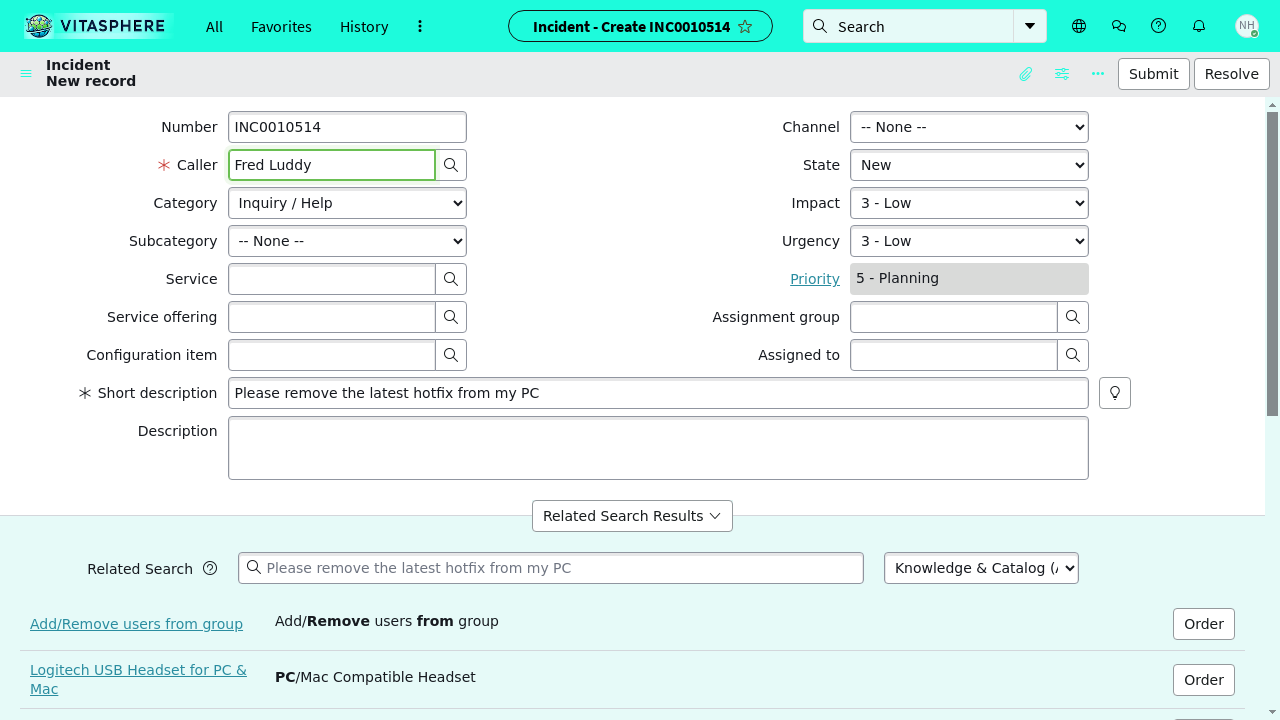
Fig 6 (page 2).
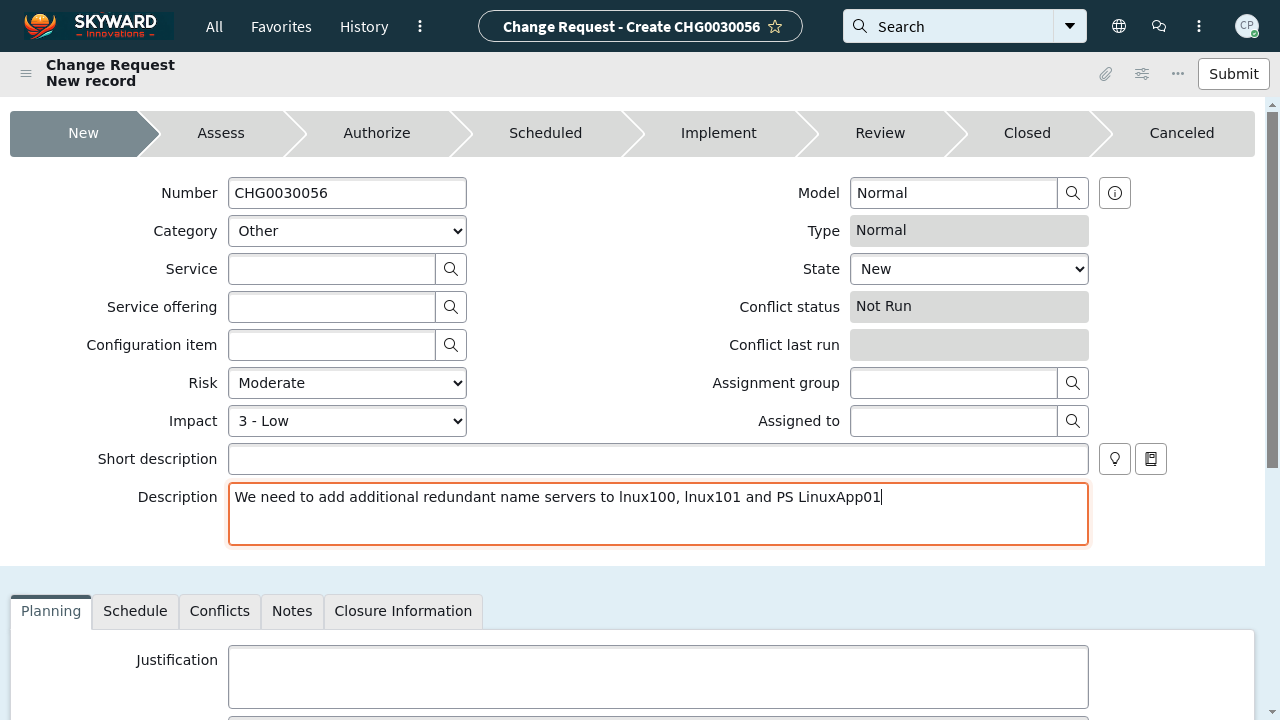
Fig 7 (page 2).
Fig 8 (page 2).
Limitations
- The benchmark is built from a relatively small number of curated questions (451), so coverage is broad by taxonomy but still finite and manually assembled.
- The paper’s main evaluation uses a fixed reader model (Qwen3.5-9B), so results may not transfer to other readers or to end-to-end agent systems without re-tuning.
- The larger haystacks are huge, but they are still benchmark-constructed histories from a bounded set of web environments; generalization to other sites, internal enterprise tools, or adversarially shifting interfaces is untested.
- AgentRunbook-C has very high latency in absolute terms (e.g., 108.3s and 139.9s per query), which may be unacceptable for many interactive deployments.
- The excerpt does not provide full details on seed variance, confidence intervals, or robustness under different trajectory ordering / corruption settings.
- Because questions were manually filtered to be outside strong LLM parametric knowledge, the benchmark may underrepresent cases where memory and prior knowledge interact rather than cleanly separate.
Open questions / follow-ons
- Can the same memory-controller ideas scale to interactive, online agent operation where insert/query decisions happen continuously rather than on a fixed offline haystack?
- How robust are the memory methods to adversarial or corrupted trajectories, especially when failed trajectories contain misleading but plausible patterns?
- Can a learned memory policy outperform the hand-scaffolded coding-agent controller while preserving the ability to inspect fine-grained UI evidence?
- What is the best way to combine parametric priors with trajectory memory for questions that are partly environment-specific and partly general?
Why it matters for bot defense
For bot-defense engineers, the useful takeaway is less about the specific benchmark and more about the evaluation philosophy: long-horizon systems should be tested on whether they retain operational experience, not just whether they can answer isolated facts. In CAPTCHA or bot-detection settings, a comparable memory benchmark would need to ask whether an agent can remember environment-specific signals such as challenge templates, failure modes, rate-limit patterns, and interface changes across many sessions.
The paper also suggests a practical design pattern: split memory into low-level evidence, event transitions, and higher-level procedural notes. For bot defense, that kind of partitioning could support auditing and policy enforcement, because an investigator can ask whether the system retained a raw interaction, a state transition, or a learned workflow rule. The main caution is latency: the best-performing scaffold here is much slower than simple retrieval, so any production deployment would need a much tighter accuracy-latency budget.
Cite
@article{arxiv2605_12493,
title={ LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues },
author={ Di Wu and Zixiang Ji and Asmi Kawatkar and Bryan Kwan and Jia-Chen Gu and Nanyun Peng and Kai-Wei Chang },
journal={arXiv preprint arXiv:2605.12493},
year={ 2026 },
url={https://arxiv.org/abs/2605.12493}
}