
FuTCR: Future-Targeted Contrast and Repulsion for Continual Panoptic Segmentation
Source: arXiv:2605.12451 · Published 2026-05-12 · By Nicholas Ikechukwu, Keanu Nichols, Deepti Ghadiyaram, Bryan A. Plummer
TL;DR
FuTCR tackles a specific failure mode in continual panoptic segmentation: during the base step, unlabeled objects from future classes are typically collapsed into a single background category, which teaches the model to ignore distinctions that will matter later. The paper’s central claim is that this is not just wasted supervision, but actively harmful representation shaping: future-class evidence gets pulled into old-class/background regions, making later class introduction harder. FuTCR tries to fix this before new labels arrive by converting certain background-like predictions into structured “future-like” regions and then shaping those regions in feature space.
The method is built on two ideas: region-level contrast to make each discovered unlabeled region internally coherent, and known-class repulsion to push those unlabeled features away from current class prototypes. Evaluated on six ADE20K continual panoptic settings spanning overlap vs. disjoint-image streams and 100-5 / 100-10 / 100-50 step schedules, FuTCR improves new-class PQ by up to 28% relative over the strongest comparable baseline (SimCIS), while keeping base-class PQ competitive or slightly better. The strongest story in the paper is not just final PQ, but the analysis: FuTCR reduces future-to-old confusion over time and allows modest prototype drift instead of rigid centroid preservation, which the authors argue is better for reserving capacity for future classes.
Key findings
- On ADE20K 100-5 overlap, new-class PQ rises from 17.3 (SimCIS) to 22.3 with FuTCR, a +28% relative gain; overall PQ goes from 30.6 to 33.3 and mIoU from 43.7 to 46.8.
- On ADE20K 100-5 disjoint-image, FuTCR improves new-class PQ from 22.8 to 23.0 and boosts PQall from 30.6 to 31.3 and mIoU from 43.6 to 46.1.
- On ADE20K 100-10 overlap, FuTCR increases PQnew from 20.1 to 21.0 and PQall from 33.3 to 33.7, while mIoU rises from 46.5 to 47.0.
- On ADE20K 100-50 disjoint-image, FuTCR lifts PQnew from 27.1 to 29.4 and PQall from 37.2 to 37.9; mIoU increases from 49.4 to 51.7.
- Ablation on ADE20K 100-5 validation shows known-future repulsion (KFR) is the stronger standalone component: PQall improves from 31.2 (SimCIS) to 32.2 with KFR alone, while region contrast alone drops PQall to 30.5.
- The full FuTCR model outperforms either component alone on the same validation ablation: PQall reaches 32.8 vs. 32.2 with KFR only and 31.2 for SimCIS.
- Future-class pixels misclassified as old classes are reported to be about 12–16% for strong baselines early in training; FuTCR reduces this fraction across all steps (Fig. 5).
- Cross-step prototype similarity for old classes stays above 0.97 in the baseline, whereas FuTCR allows it to fall to about 0.89 by step 11, and this is associated with higher PQ and lower future-old confusion (Fig. 6).
Threat model
The adversary is the continual learning protocol itself: future-class objects appear in training images before they are labeled, and the learner is forced to treat them as background under a class-incremental schedule. The model knows the current class set Ct and has access only to the current step’s annotations Dt, while future-class pixels remain unlabeled/ignored. It cannot assume access to future labels or earlier training data beyond what the chosen stream provides. The goal is not to defend against malicious input manipulation, but to prevent representational collapse caused by systematic label incompleteness and class overlap across time.
Methodology — deep read
Threat model and learning setting: FuTCR is not a security/attack-defense paper in the usual sense, but it does define an implicit “future-class adversary” problem for the learner: at step t, the model sees images that may contain objects from classes not yet introduced, and standard CPS protocols force those pixels into background. The adversary here is simply the continual learning setup itself—missing labels, class-collapsed background supervision, and the constraint that at step t the model cannot revisit earlier data except under the chosen stream protocol. The model is a query-based panoptic segmentation system; it must segment both thing instances and stuff regions over time, while only being directly supervised on the current class subset Ct. The key assumption is that unlabeled pixels from future classes are present in base-step images (especially in the overlap stream) and that these pixels contain recoverable structure the model can exploit before the classes are formally introduced.
Data and splits: All experiments are on ADE20K [58], partitioned into a base set C1 of 100 classes and 50 remaining classes introduced over multiple incremental steps. The paper evaluates three step schedules: 100-5 (11 total steps; 10 incremental steps of 5 classes each), 100-10 (6 total steps), and 100-50 (2 total steps). The base step uses roughly 10K images; incremental steps average about 700 images each, with a robustness experiment reducing that to roughly 400 and 100 images per step (Fig. 4). Validation and test sets each contain 1K held-out images. The paper reports two streams: an overlap stream where later steps reuse base images so future-class pixels appear in training but are unlabeled, and a disjoint-image stream with no image overlap between base and incremental steps. Metrics are PQ, split into PQbase, PQnew, and PQall, plus mIoU; Eclipse does not report mIoU in their released code, so only PQ is shown for that baseline.
Architecture and algorithm: FuTCR is attached to a query-based panoptic backbone, implemented on top of Mask2Former with a pretrained ResNet-50 backbone in Detectron2. The decoder produces query features h_t(x) in R^{Q×d} and mask logits/predictions for each query. FuTCR adds a “future-aware” module with two losses. First, unlabeled region discovery: it examines per-query masks and selects future-like regions whose mask is confident, sufficiently large, and whose support lies mostly on pixels outside the current class set C≤t. This is model-driven, not externally proposed. For each selected region r=(b,q), it pools mask features F_b over the region support Ω_r to create a prototype p_r via simple averaging (Eq. 1). Second, pixel-to-region contrast (Eq. 2): sampled pixel features from the same region are pulled toward p_r with an InfoNCE-style loss and pushed away from prototypes of other future-like regions, so unlabeled content forms object-centric clusters rather than diffuse background. Third, known-class repulsion (Eq. 3): sampled unlabeled pixels are compared against normalized known-class prototypes/class vectors w_c, and a hinge margin penalizes high similarity to the most similar known class, creating representational space for future categories. The total loss is L_total = L_pan + λ_reg L_reg + λ_rep L_rep, with λ_rep set to 0.5; the text does not state the λ_reg value in the excerpt provided.
Training regime and one concrete example: The model is trained sequentially across incremental steps, initializing each step from the previous checkpoint. The authors say they follow prior work’s training setup and hyperparameters as closely as possible; beyond λ_rep=0.5, the excerpt does not specify all optimizer settings, epochs, or batch sizes, so those details remain in the supplement. All experiments ran on 4 NVIDIA RTX A6000 GPUs, and each incremental step took about 2 hours on average for the 100-5 setting. A concrete end-to-end example at the base step: the model processes an ADE20K image, the panoptic head generates query masks, FuTCR identifies a mask region that is mostly on pixels currently labeled as background but whose logits indicate objectness, averages the region’s mask features into a prototype, pulls pixels in that region toward the prototype via contrastive learning, and simultaneously repels those same pixels away from the nearest known-class prototype if they are too similar. The result is a base-step feature space that already reserves a margin for future classes before they are explicitly labeled in later steps.
Evaluation protocol and reproducibility: The paper evaluates final-step performance after all incremental classes are incorporated, reporting PQbase, PQnew, PQall, and mIoU across the overlap and disjoint-image streams. Baselines include Eclipse [28], Balconpas [30], Combo [21], and SimCIS [23], with SimCIS serving as the closest baseline to the proposed query-based approach. Table 4 ablates region contrast (RC) and known-future repulsion (KFR) on the ADE20K 100-5 validation set; KFR alone improves PQall from 31.2 to 32.2, RC alone hurts PQall to 30.5, and the full method reaches 32.8. The analysis section also includes future-confusion profiling (Fig. 5) and prototype congruence tracking (Fig. 6), showing that FuTCR reduces the share of future pixels predicted as old classes and that moderate prototype drift correlates with better new-class behavior. The authors say code and models will be made publicly available on GitHub, but the excerpt does not confirm a release at the time of writing, and the paper is a preprint.
Technical innovations
- Future-like region discovery directly from the model’s own query masks, instead of using external proposals or collapsing unlabeled pixels into a single unknown/background class.
- Pixel-to-region contrastive learning that turns unlabeled foreground-like pixels into coherent region prototypes aligned with the panoptic query structure.
- Known-class repulsion that explicitly pushes unlabeled features away from current class prototypes in feature space to reserve headroom for future categories.
- A coupled objective that combines standard panoptic losses with future-targeted contrast and repulsion, aimed at reducing future-old class confusion before new labels arrive.
Datasets
- ADE20K — 100-class base + 50 incremental classes; ~10K base images, ~700 images/step on average, 1K val and 1K test — public dataset
Baselines vs proposed
- SimCIS [23] vs FuTCR on ADE20K 100-5 overlap: PQnew = 17.3 vs 22.3; PQall = 30.6 vs 33.3; mIoU = 43.7 vs 46.8
- SimCIS [23] vs FuTCR on ADE20K 100-5 disjoint: PQnew = 22.8 vs 23.0; PQall = 30.6 vs 31.3; mIoU = 43.6 vs 46.1
- SimCIS [23] vs FuTCR on ADE20K 100-10 overlap: PQnew = 20.1 vs 21.0; PQall = 33.3 vs 33.7; mIoU = 46.5 vs 47.0
- SimCIS [23] vs FuTCR on ADE20K 100-10 disjoint: PQnew = 19.1 vs 20.3; PQall = 31.6 vs 32.8; mIoU = 47.4 vs 47.5
- SimCIS [23] vs FuTCR on ADE20K 100-50 overlap: PQnew = 24.9 vs 28.0; PQall = 36.5 vs 37.3; mIoU = 51.1 vs 50.3
- SimCIS [23] vs FuTCR on ADE20K 100-50 disjoint: PQnew = 27.1 vs 29.4; PQall = 37.2 vs 37.9; mIoU = 49.4 vs 51.7
- SimCIS [23] vs FuTCR on ADE20K 100-5 validation ablation: PQall = 31.2 vs 32.8; KFR-only = 32.2; RC-only = 30.5
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12451.

Fig 1: From background noise to structured supervision. (a) Prior continual panoptic methods

Fig 2: Overview of FuTCR, a query-based continual panoptic model produces dense region

Fig 3: provides qualitative comparisons between SimCIS and FuTCR on the ADE20K 100 - 50 setting.
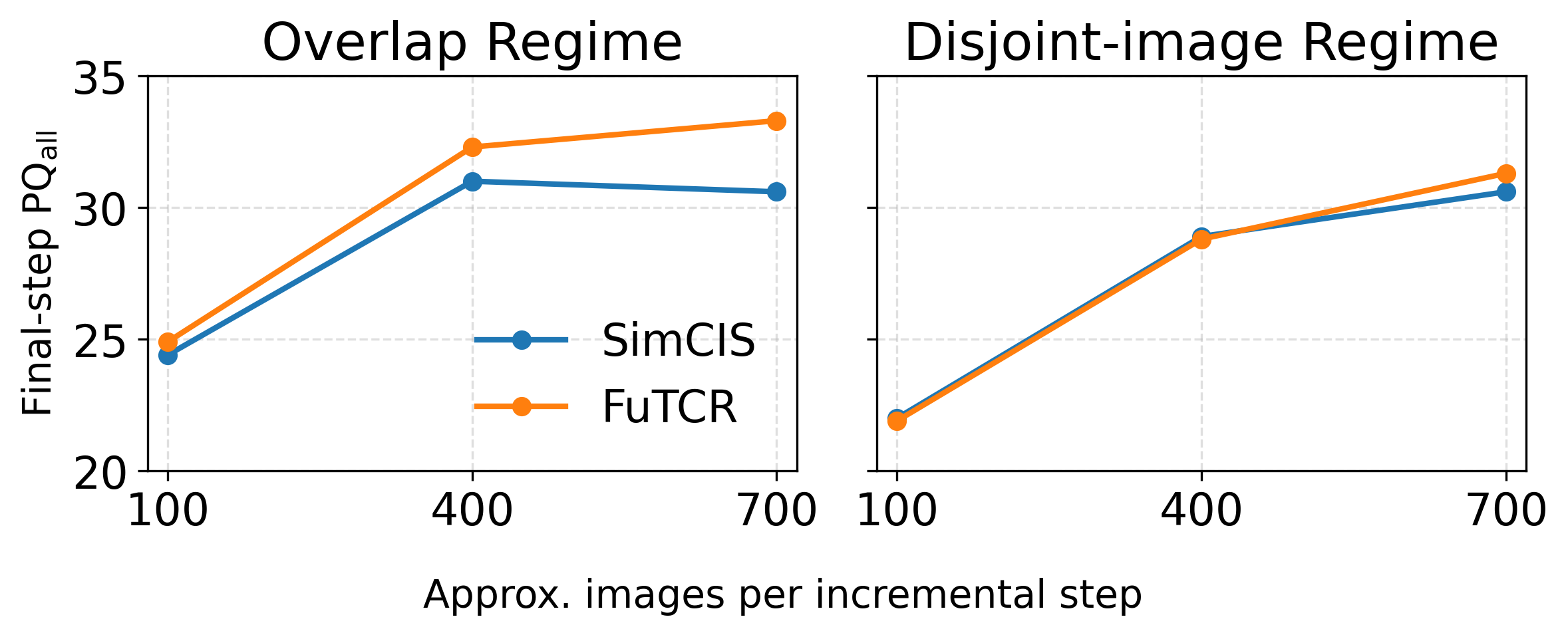
Fig 4: Robustness to reduced incre-
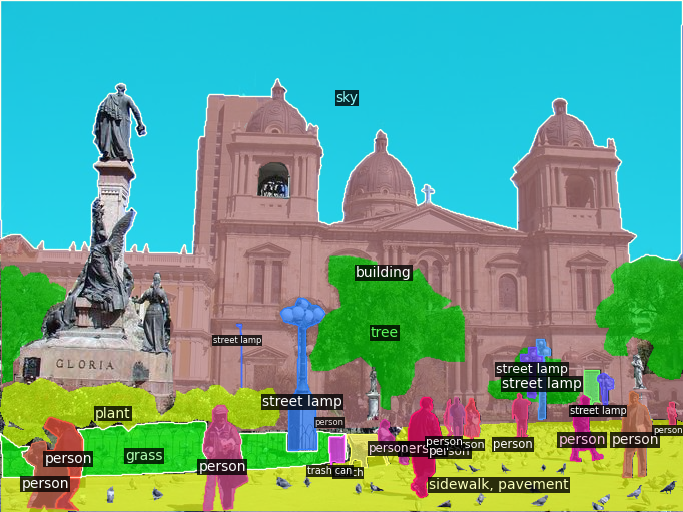
Fig 5: Future-aware error dynamics.

Fig 6: Left/middle: FuTCR consistently outperforms SimCIS [23] in mIoU and PQ on ADE20K

Fig 7 (page 8).

Fig 8 (page 8).
Limitations
- The paper is restricted to ADE20K; there is no evidence in the excerpt for transfer to other continual segmentation benchmarks or domains.
- The authors note a small number of random seeds and architectures, so robustness across backbones and initialization variance is not well characterized.
- The excerpt does not specify all optimization details for reproducibility, such as batch size, epochs, learning rates, or the exact λ_reg value.
- Region selection depends on heuristics like confidence, size, and majority-of-support thresholds; the paper does not show a systematic sensitivity study for these choices in the excerpt.
- The method appears most beneficial when future-class evidence is present in the training images; gains are smaller in the disjoint stream and under very sparse supervision.
- The analysis suggests prototype drift helps, but the method still relies on a specific query-based panoptic architecture, so it is unclear how directly it transfers to non-query segmentation models.
Open questions / follow-ons
- How sensitive is future-like region discovery to the confidence, size, and support-majority thresholds, and can those be learned instead of hand-set?
- Does the same contrast-plus-repulsion idea transfer to other dense prediction architectures beyond query-based Mask2Former-style models?
- Can FuTCR be extended to other continual segmentation regimes with stronger distribution shift, different class orders, or non-ADE20K datasets?
- Would a more principled prototype evolution scheme outperform the observed moderate drift, especially if combined with replay or distillation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main takeaway is architectural rather than directly deployable: the paper shows that ignoring ambiguous or unlabeled regions can poison future class separability, and that explicitly structuring those regions before later supervision arrives can improve long-horizon adaptation. In a CAPTCHA or abuse-detection pipeline, the analogous problem is often “unknown but recurring” traffic patterns being flattened into generic background/other labels, which can make later policy updates brittle. FuTCR suggests a design pattern: discover stable latent clusters from weakly labeled evidence, keep them separated from known benign/abuse prototypes, and avoid over-committing all uncertainty to a single catch-all class. That said, this is a segmentation-specific method on ADE20K, so an engineer would adapt the idea at the representation/objective level rather than reuse the algorithm directly.
Cite
@article{arxiv2605_12451,
title={ FuTCR: Future-Targeted Contrast and Repulsion for Continual Panoptic Segmentation },
author={ Nicholas Ikechukwu and Keanu Nichols and Deepti Ghadiyaram and Bryan A. Plummer },
journal={arXiv preprint arXiv:2605.12451},
year={ 2026 },
url={https://arxiv.org/abs/2605.12451}
}