
EgoForce: Forearm-Guided Camera-Space 3D Hand Pose from a Monocular Egocentric Camera
Source: arXiv:2605.12498 · Published 2026-05-12 · By Christen Millerdurai, Shaoxiang Wang, Yaxu Xie, Vladislav Golyanik, Didier Stricker, Alain Pagani
TL;DR
EgoForce addresses the challenging problem of accurately reconstructing absolute 3D hand pose and shape from a single egocentric (head-mounted) RGB camera, a critical task for AR/VR, telepresence, and interactive applications requiring compact and unobtrusive sensing. Existing monocular methods typically recover only relative root-based hand joint positions and require costly device-specific training due to depth-scale ambiguity and wide variation in camera optics. EgoForce innovates by jointly modeling the forearm alongside the hand, leveraging the biomechanical coupling and anthropometric priors that forearm shape and pose provide to robustly infer absolute depth and scale. Additionally, it proposes a camera-model-agnostic ray space solver that unifies absolute 3D hand pose recovery across diverse optics including fisheye, perspective, and wide field-of-view cameras.
The framework features a unified transformer architecture (HALO) that separately encodes and then cross-attends hand and forearm image crops enriched with camera intrinsic tokens, enabling consistent reasoning across camera models and occlusion scenarios. The predicted root-relative hand and forearm parameters are lifted to absolute camera-space 3D poses using a closed-form confidence-weighted ray space solver. Experiments on multiple egocentric datasets demonstrate state-of-the-art accuracy, with up to 28% reduction in camera-space mean joint position error (MPJPE) on the HOT3D benchmark compared to prior work. Ablations show that incorporating forearm context and explicit camera geometry modeling substantially improves accuracy and temporal stability, especially under hand occlusion and distortions from fisheye optics.
Key findings
- EgoForce reduces camera-space mean joint position error (CS-MJE) by up to 28% on the HOT3D dataset compared to prior best method HandDGP (43.9mm vs 61.3mm).
- On ARCTIC, EgoForce improves root-relative mean joint error (RS-MJE) by 3% and camera-space MJE by 2.7% with forearm context vs no forearm.
- Camera-space acceleration error (CS-ACC) on H2O dataset is 5.5 m/s² with EgoForce, outperforming HaMeRD (55.9 m/s²), MobRecon (21.7), HandOccNet (11.7), and HandDGP (8.5).
- Explicit undistortion combined with crop intrinsic token conditioning cuts HOT3D CS-MJE from 123.4mm to 45.8mm (62.9% reduction).
- When forearm is out of view, the hand-conditioned VAE prior reduces arm RS-MJE error by 55.4% and CS-ACC by 10.7%, maintaining plausible arm pose.
- EgoForce achieves consistent performance across diverse camera models (perspective, fisheye, wide FOV) via ray space solver, outperforming pinhole-based lifting methods that degrade near image periphery.
- The Ray Space Solver operates on 2D-3D correspondences formulated as rays, enabling closed-form camera-space translation estimation with confidence weighting.
- Temporal stability improves significantly: 22% and 17% reduction in CS-ACC and RS-ACC on ARCTIC by adding forearm context.
Threat model
N/A — the paper focuses on monocular 3D hand pose estimation accuracy and robustness under occlusions and camera distortions rather than explicit security or adversarial threat modeling.
Methodology — deep read
- Threat Model & Assumptions:
- The system assumes a single calibrated monocular head-mounted RGB camera with arbitrary projection optics (perspective, fisheye, wide-FOV).
- The adversary context is not deeply explored; the focus is on accurate 3D pose recovery under occlusion, distortion, and depth-scale ambiguity.
- No assumptions on additional sensors or multi-view data; single-frame inference is targeted.
- Data:
- Training data consists of 3.67 million RGB images annotated with MANO hand parameters and 3D joints, pooled from six datasets: Re:InterHand, HandCO, H2O, ARCTIC, HO3D, HOT3D.
- Among these, only ARCTIC, H2O, and HOT3D contain egocentric views; others contain exocentric.
- Forearm parameters (FARM) were generated per dataset where possible via conversion or multi-view triangulation; not available for some datasets due to occlusions or monocular ambiguity.
- Data preprocessing includes cropping hand (224x224) and forearm (112x112) regions, undistortion of crops, normalization, and augmentation with crop intrinsic tokens encoding crop geometry and camera intrinsics.
- Dataset splits and training/validation partitions are detailed in supplementary materials but follow standard protocol.
- Architecture / Algorithm:
Input: monocular RGB frame; extract hand and forearm crops.
Arm-Hand Crop Encoder: undistorts crops, splits crops into patches, projects to token embeddings augmented with crop intrinsic tokens (CIT) representing crop geometry and camera intrinsics.
A Vision Transformer (ViT) backbone encodes combined hand and arm tokens into features.
Hand-Arm Latent-Shape & Orientation (HALO) Architecture: A transformer decoder with learnable queries for hand and forearm jointly decodes regression parameters.
Predicts 2D keypoints, their confidence weights, MANO hand pose/shape parameters, and FARM forearm pose/shape parameters.
When forearm is not visible, replaces arm tokens with learned missing-arm tokens and uses a conditional variational autoencoder (VAE) prior conditioned on hand features to infer plausible arm features.
The predicted root-relative 3D joints and parameters are passed to the Ray Space Solver.
Ray Space Solver (RSS): For each 2D joint, back-project keypoint into a ray based on calibrated camera intrinsics.
Formulate a confidence-weighted least squares problem minimizing perpendicular distances from predicted joint (translated by camera-space translation t) to corresponding rays.
Closed-form solution recovers absolute camera-space translation t shared by hand and forearm.
Use a Kalman filter to temporally smooth translation estimates.
- Training Regime:
- Losses combine: 2D joint heatmap losses, 3D joint L2 losses (root-relative), MANO and FARM parameter regression losses, relative hand-arm orientation geodesic loss, prior VAE KL divergence loss, and camera-space 3D joint loss.
- Training uses AdamW optimizer with learning rates 1e-5 for transformer, 5e-4 for others.
- Batch size 27, 113 epochs, training on 5 NVIDIA H200 GPUs (~4 days).
- Gradients do not flow through the Ray Space Solver to the earlier stages to prevent unstable gradients.
- Evaluation Protocol:
- Metrics: Camera-space mean joint position error (CS-MJE), root-relative MJE (RS-MJE), Procrustes-aligned MJE (PS-MJE), and acceleration errors (CS-ACC, RS-ACC).
- Baselines: MobRecon, HandOccNet, HandDGP retrained on the same data, and HaMeRD with external depth lifting.
- Evaluation on three main egocentric datasets (ARCTIC, HOT3D, H2O) plus HO3D.
- Ablations investigate effect of camera geometry modeling (undistortion, crop intrinsics token, rectification), forearm inclusion and prior.
- Qualitative assessments include mesh projections, occlusion robustness, and temporal stability.
- Reproducibility:
- Implementation done in PyTorch.
- Official baselines used with original hyperparameters.
- Precise code release not explicitly mentioned; project page provided for further details.
- Some dataset annotations (FARM) generated or converted internally.
Example End-to-End Inference:
- From a monocular egocentric RGB frame (e.g., fisheye camera on Aria glasses), the hand and forearm crops are extracted.
- The crops are undistorted and tokenized with accompanying crop intrinsic tokens.
- The HALO transformer jointly encodes and decodes hand and arm parameters.
- 2D keypoints and confidences are predicted.
- Root-relative MANO and FARM parameters are regressed.
- The Ray Space Solver applies confidence-weighted perpendicular distance minimization of 3D joints to rays to recover the absolute camera-space hand and forearm translation.
- A Kalman filter smooths per-frame translation estimates.
- The absolute 3D mesh and joint poses are output in the camera coordinate system.
- The system runs interactively at ~14 FPS on an RTX 3090 GPU.
Overall, the methodology integrates transformer-based visual encoding with a novel forearm representation and a geometric closed-form absolute lifting solver to robustly recover metric 3D hand pose from difficult egocentric viewpoints with diverse camera optics.
Technical innovations
- Introduction of FARM, a fully differentiable forearm representation that provides metric cues to reduce monocular depth-scale ambiguity in egocentric 3D hand pose estimation.
- HALO: A unified arm-hand transformer architecture that separately encodes hand and forearm crops, augmented with crop intrinsics tokens and cross-attention, enabling robust joint hand-arm pose and shape regression.
- A camera-model-agnostic Ray Space Solver that directly lifts 2D-3D keypoint correspondences formulated as rays (bearing vectors) to recover camera-space absolute 3D poses across perspective, fisheye, and distorted wide-FOV optics in a closed-form confidence-weighted least squares manner.
- A conditional variational arm prior that infers plausible arm poses when the forearm is out of the camera’s field of view, maintaining continuity and realism via hand-conditioned latent sampling.
- Encoding crop intrinsics as tokens to the transformer to achieve consistent geometric reasoning across varying crop sizes, camera intrinsics, and optical distortions.
Datasets
- Re:InterHand — millions of RGB images with MANO annotations — public research dataset
- HandCO — large-scale RGB dataset with MANO 3D annotations — public research dataset
- H2O — egocentric and exocentric RGB dataset — public research dataset
- ARCTIC — egocentric multi-modal RGB dataset — public research dataset
- HO3D — object interaction dataset with 3D hand annotations — public research dataset
- HOT3D — egocentric fisheye RGB dataset with 3D ground truth — public research dataset
Baselines vs proposed
- HaMeRD: ARCTIC CS-MJE = 2067.3 mm vs EgoForce 49.5 mm
- MobRecon: HOT3D CS-MJE = 116.3 mm vs EgoForce 43.9 mm
- HandOccNet: H2O CS-MJE = 62.1 mm vs EgoForce 25.0 mm
- HandDGP: HOT3D CS-MJE = 61.3 mm vs EgoForce 43.9 mm
- HaMeRD: H2O CS-ACC = 55.9 m/s² vs EgoForce 5.5 m/s²
- HandDGP: ARCTIC RS-MJE = 9.9 mm vs EgoForce 8.0 mm
- HaMeRD: HO3D PS-MJE = 7.7 mm vs EgoForce 9.0 mm (slightly worse)
- EgoForce ablation - undistortion + crop intrinsic token reduces HOT3D CS-MJE from 123.4 mm to 45.8 mm
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12498.

Fig 1: EgoForce reconstructs the absolute 3D pose and shape of the hands from the user’s viewpoint using a monocular RGB camera from Aria
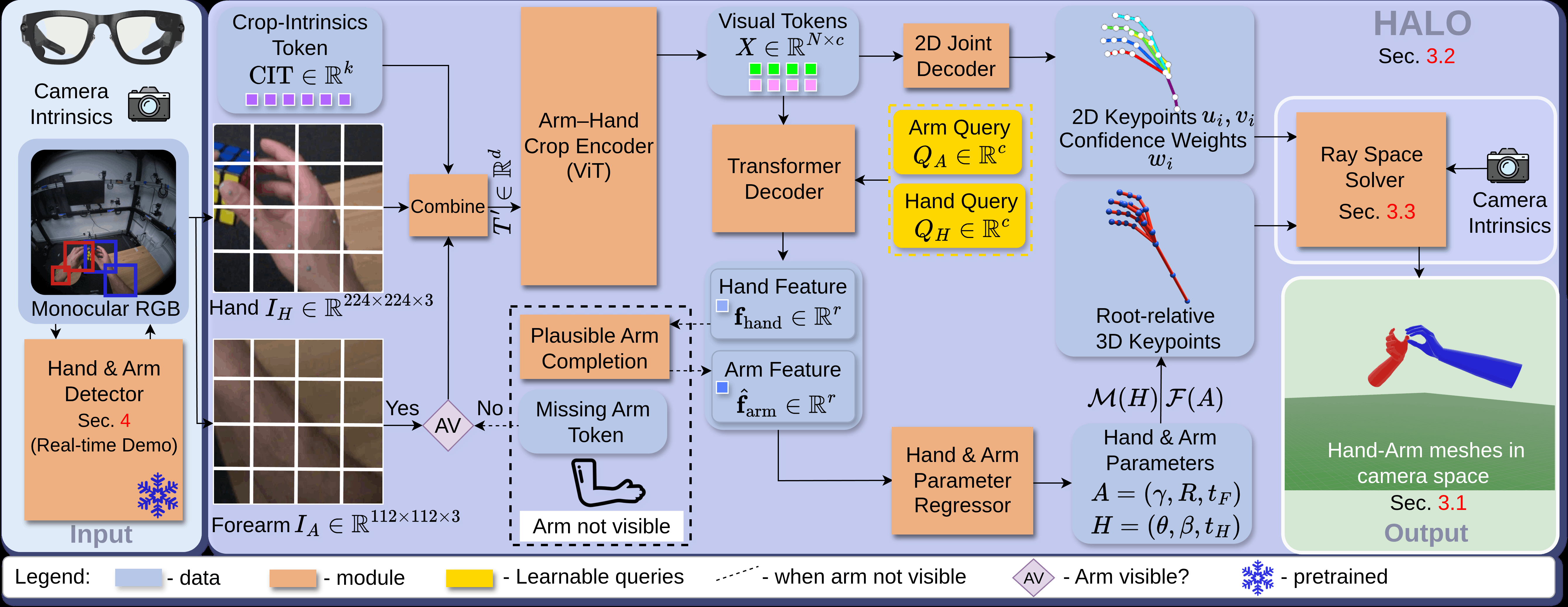
Fig 2: EgoForce processes a monocular egocentric RGB frame by extracting hand and forearm crops, tokenizing them, and conditioning the features on
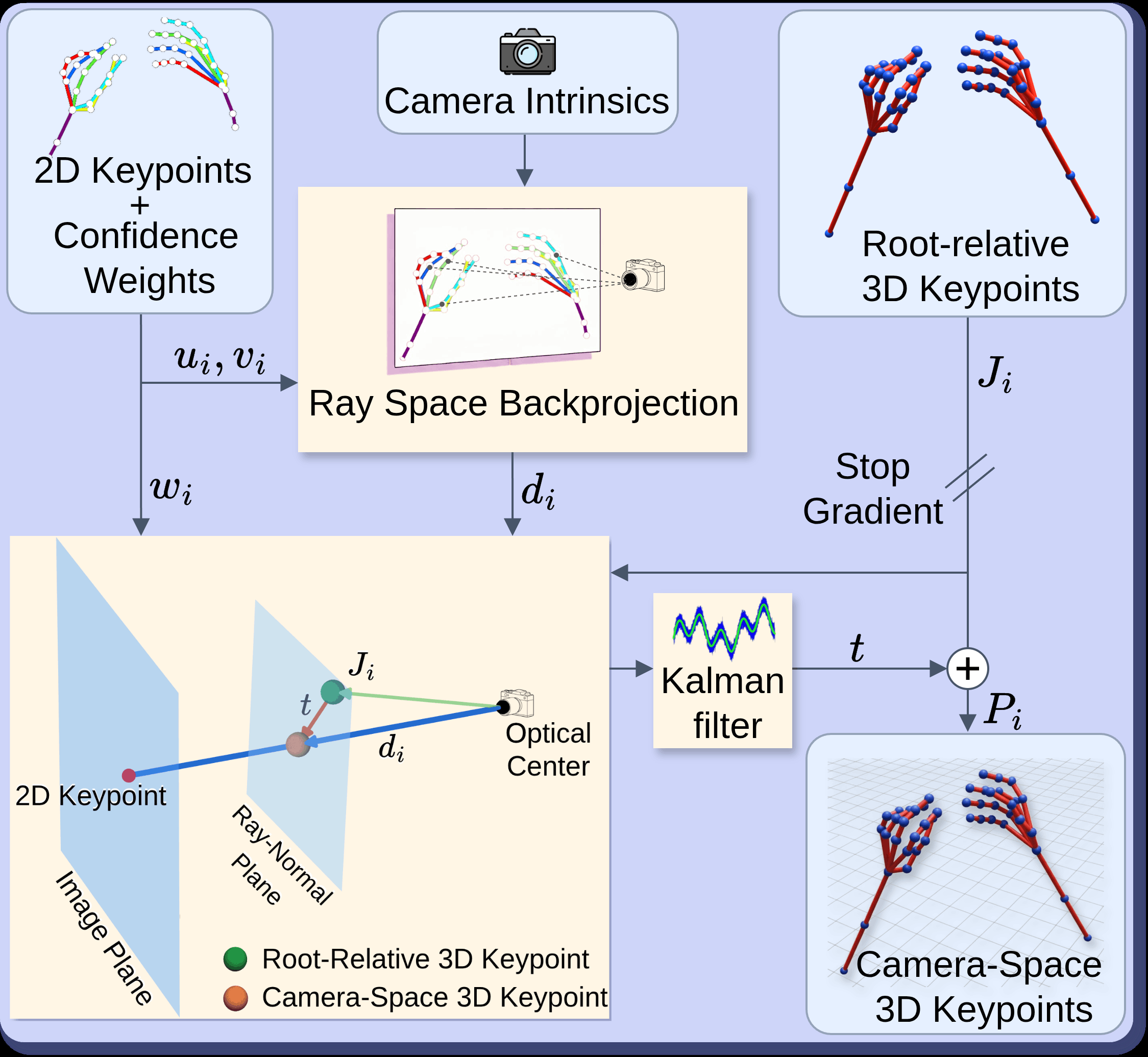
Fig 3: The Ray Space Solver is a cross-camera (calibration-conditioned)
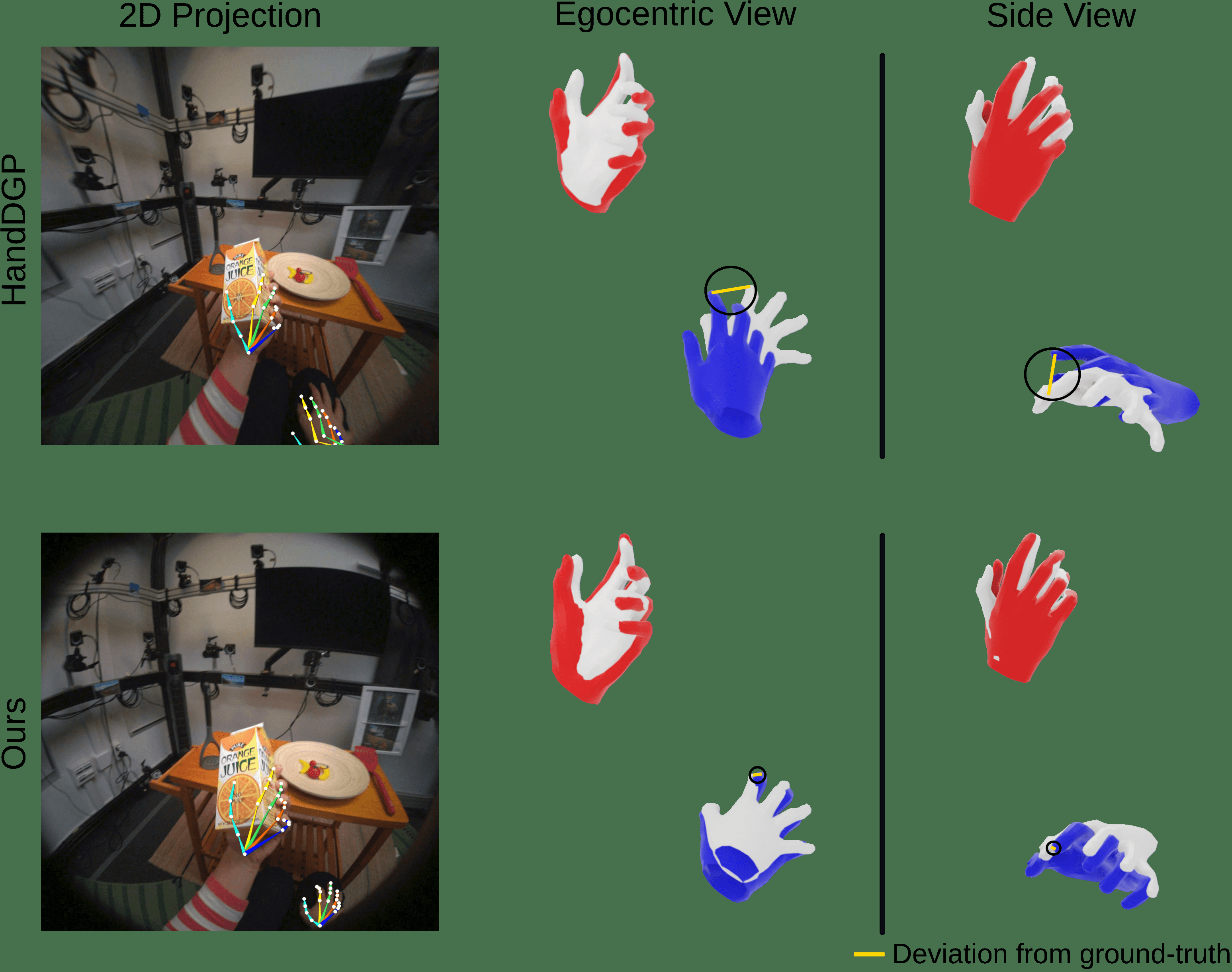
Fig 5: Camera-space results on HOT3D. Left: egocentric input with the
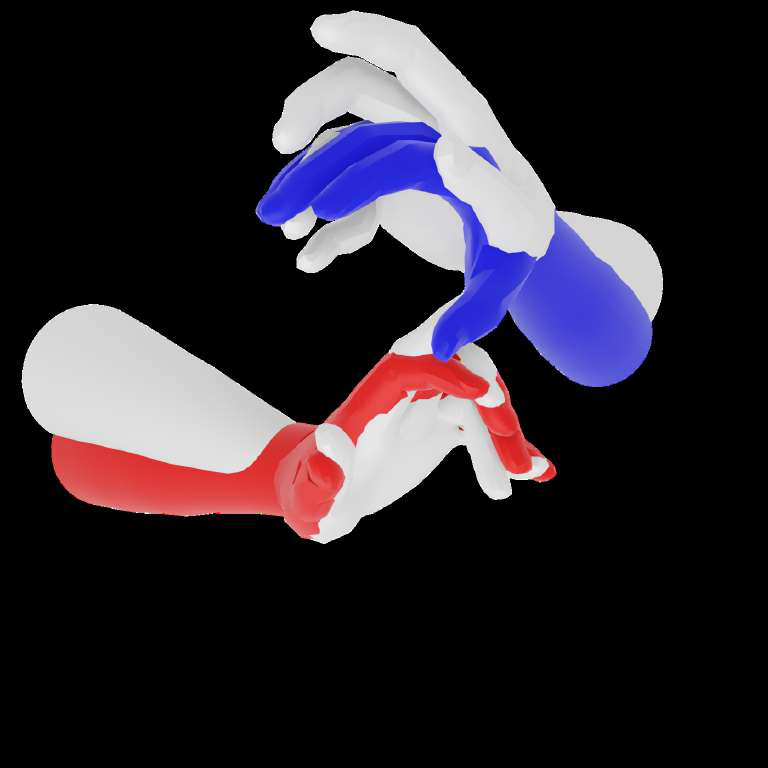
Fig 6: Influence of arm input. Providing the arm crop as an input to the
Fig 7: Influence of the variational arm prior. Without the variational

Fig 8: Qualitative camera-space results on egocentric datasets. We compare our method against three state-of-the-art camera-space 3D hand pose
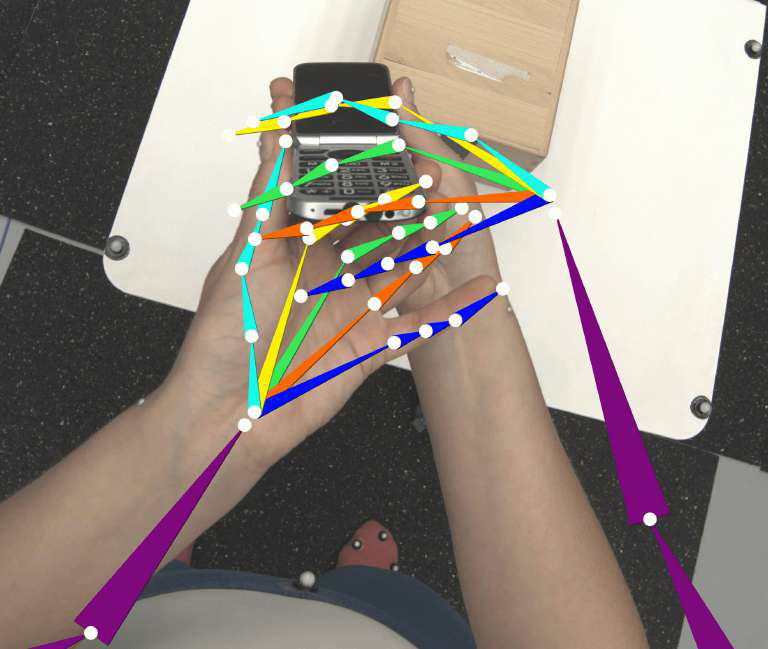
Fig 9: Camera-space hand mesh projections on egocentric datasets. We project predicted hand meshes onto images from three camera types: HOT3D
Limitations
- Forearm parameter (FARM) annotations had to be generated or inferred because most existing datasets only contain MANO hand parameters or lack forearm visibility.
- FARM recovery is infeasible for several datasets (HO3D, HOT3D, Re:InterHand, HandCO) due to monocular depth ambiguity or occlusions — forearm modeling relies on partial or synthetic annotations.
- The model requires camera intrinsics and calibration for proper ray space lifting; uncalibrated cameras cannot be handled directly.
- The approach is trained and validated mostly on datasets with mostly static or scripted hand-object interactions; real-world unconstrained scenarios may degrade performance.
- No explicit adversarial or security evaluation was conducted; robustness against deliberate spoofing or adversarial perturbations is unknown.
- While temporal smoothing (Kalman filter) improves stability, the system is primarily single-frame and does not model temporal dynamics deeply.
- Code and full dataset details for FARM parameter generation are partially closed or deferred to supplementary materials, limiting immediate reproducibility.
Open questions / follow-ons
- Can the method be extended to handle fully uncalibrated monocular cameras or dynamically varying intrinsic parameters?
- How does EgoForce cope with adversarial occlusions or deliberate spoofing attacks in hostile environments?
- Can temporal dynamics be incorporated explicitly for improved tracking consistency beyond Kalman smoothing?
- What is the impact of physically wearable device variations (e.g., different glasses hardware) beyond current datasets, and can domain adaptation improve cross-device generalization?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, EgoForce offers insights into robust monocular 3D hand pose estimation leveraging biomechanical priors and intrinsic camera modeling. Understanding the fusion of forearm-hand coupled representation with a camera-model-agnostic lifting technique may inspire defenses against automated bot interaction attacks involving realistic hand gestures or mimicry detection. The ray space solver concept demonstrates how geometric constraints derived from camera calibration can improve spatial reasoning under distortion, which might translate to more robust user interaction verification in diverse device optics scenarios. Additionally, the use of variational priors to fill missing data elegantly handles partial occlusion, a common challenge in authentication contexts. However, the method's reliance on calibrated cameras and controlled datasets suggests that deploying such 3D pose estimation directly in adversarial or highly variable settings requires further adaptation and validation. Nevertheless, technical ideas on combining transformer-based visual encoders with well-grounded geometric lifting could inform future CAPTCHA or bot-detection systems seeking to verify genuine human hand movements from minimalistic ego-RGB inputs.
Cite
@article{arxiv2605_12498,
title={ EgoForce: Forearm-Guided Camera-Space 3D Hand Pose from a Monocular Egocentric Camera },
author={ Christen Millerdurai and Shaoxiang Wang and Yaxu Xie and Vladislav Golyanik and Didier Stricker and Alain Pagani },
journal={arXiv preprint arXiv:2605.12498},
year={ 2026 },
url={https://arxiv.org/abs/2605.12498}
}