
EDGER: EDge-Guided with HEatmap Refinement for Generalizable Image Forgery Localization
Source: arXiv:2605.12002 · Published 2026-05-12 · By Minh-Khoa Le-Phan, Minh-Hoang Le, Minh-Triet Tran, Trong-Le Do
TL;DR
This paper addresses the challenge of generalizable image forgery localization (IFL) in the face of realistic text-guided inpainting manipulations that blur the boundary between authentic and synthetic content. Existing methods often fail to localize manipulated regions accurately across different domains or image resolutions. The authors propose EDGER, a patch-based dual-branch framework that preserves native resolution and fuses complementary cues to produce reliable manipulation masks. The first branch, Edge-Guided Segmentation (EGS), employs a novel Frequency-based Edge Detector that emphasizes high-frequency inconsistencies at boundaries between real and manipulated regions and feeds these as spatially stacked priors into a SegFormer segmentation backbone. The second branch, Synthetic Heatmapping (SH), is a sliding-window patch classifier fine-tuned with LoRA on a CLIP-ViT model to detect fully synthetic patches, providing coarse region-level priors. Combining fine-grained edge cues and region-level heatmaps via pixel-wise max fusion yields robust and accurate localization across multi-megapixel images.
The approach is extensively evaluated on the MediaEval 2025 SynthIM benchmark, focusing on spliced (partially manipulated) images produced by diverse inpainting models unseen in training. EDGER demonstrates strong cross-domain generalization and outperforms state-of-the-art baselines including IML-ViT, MVSSNet, and CATNet. Ablation studies confirm the effectiveness of patch-based inference, the frequency-based edge detector, and the dual-branch fusion over single branches or simple baselines. Qualitative results highlight that the SH branch captures large synthetic regions but misses fine detail, while the EGS branch preserves boundary sharpness. Fusion delivers the best overall mask quality, particularly at high resolutions where downsampling-based methods suffer detail loss. These results indicate that combining frequency-based boundary detection and CLIP-derived semantic priors can significantly enhance manipulation localization in realistic, high-resolution, and cross-domain scenarios.
Key findings
- EDGER's fused EGS+SH model scores 0.590 mean IoU on the SynthIM 2025 validation set spliced images, outperforming IML-ViT (0.362), MVSSNet (0.355), CATNet (0.351), and SegFormer baseline (0.370) in merged patch mode (Table 1).
- Edge-Guided Segmentation (EGS) alone achieves 0.442 image-level IoU and 0.597 patch-level IoU, improving seam precision over the SegFormer baseline (0.370 image IoU) (Table 2).
- Synthetic Heatmapping (SH) alone achieves 0.384 image IoU, indicating coarse but incomplete localization compared to fusion (0.590) (Table 2).
- Spatial stacking of frequency-based edge priors with RGB inputs yields 0.438 image IoU versus 0.372 image IoU for simple channel concatenation; adding edge augmentations during training further improves to 0.442 image IoU (Table 3).
- Non-overlapping patch inference at native resolution avoids downsampling artifacts that reduce localization accuracy down to 0.305 IoU (resize baseline) (Table 2).
- The frequency-based edge detector fuses high-pass residuals, SRM-like filters, Sobel and Laplacian gradients, processed by dilated residual blocks and global pooling, producing soft multi-scale boundary priors (Section 3.1).
- Sliding-window SH branch applies a LoRA-fine-tuned CLIP-ViT image classifier at 336×336 windows with stride 112 and Hann blending to generate smoothly merged synthetic likelihood heatmaps (Section 3.3).
- Qualitative results show SH branch captures coarse synthetic regions in large images but misses small or thin structures, whereas EGS captures fine boundary details, with fusion combining strengths (Figures 4 and 5).
Threat model
The adversary is assumed to be a forger who manipulates images via text-guided inpainting, producing partially spliced images that blend synthetic content into authentic backgrounds with smooth, realistic boundaries. The adversary has access to generative inpainting models and aims to create undetectable manipulations at arbitrary resolutions. However, the adversary does not have knowledge of the precise detection model internals or defenses — the defender assumes black-box manipulations with no white-box attack capability.
Methodology — deep read
The threat model assumes an adversary who generates partially manipulated images via text-guided inpainting, aiming to create realistic, high-resolution forgeries with seamless blending. The defender must localize these manipulated regions accurately across diverse generative models and image scales, without relying on specific domain or generator assumptions.
The data provenance is the MediaEval 2025 SynthIM benchmark's Manipulated Region Localization task training set (TGIF dataset) containing approximately 75,000 text-guided inpainting samples generated by Stable Diffusion variants (SD2, SDXL) and Adobe Firefly. Each original (OR) image has corresponding spliced (SP) and fully regenerated (FR) versions. Localization training uses OR (with empty mask) and SP (with pixel-level mask) images only. Evaluation is performed on 3,043 SP images from the SynthIM validation split based on SAGI-D, generated by unseen diverse inpainting methods including BrushNet and ControlNet, with images ranging from ~100k to >100 million pixels, emphasizing cross-domain generalization and resolution scaling.
The architecture is a patch-based dual-branch framework: (1) Edge-Guided Segmentation (EGS) branch incorporating a frozen Frequency-based Edge Detector and a SegFormer MiT-B3 decoder; (2) Synthetic Heatmapping (SH) branch using a CLIP-ViT Large (14/336) image encoder fine-tuned by LoRA for FR vs non-FR classification, repurposed as a sliding-window patch-level synthetic region detector. Each input image is tiled into non-overlapping patches (≤1024 pixels per side) processed independently at native resolution by the EGS branch, which predicts fine-grained pixel masks with RGB plus soft edge priors spatially stacked as a tall input tensor. The SH branch slides overlapping 336×336 windows with stride 112 and produces soft heatmaps via weighted Hann blending. Outputs are fused pixel-wise by maximum.
Training details: Edge Detector is trained first with multi-scale soft edge targets derived from morphological gradients on true masks; it extracts high-pass filtered residuals, SRM-like prediction errors, and fixed gradient filters. This detector remains frozen to provide non-learnable low-level boundary cues. The SegFormer is then fine-tuned with Adam optimizer (lr 1e-5, weight decay 1e-4) for 100 epochs on batches of 8 padded patches, integrating the edge prior. For the SH branch, the CLIP-ViT Large is fine-tuned with LoRA adapters (rank 8, alpha 32, dropout 0.05) using AdamW (lr 1e-4) on 336×336 random crops with batch size 32 and horizontal flips.
Evaluation protocol measures mean Intersection over Union (mIoU) on SP images across entire images (stitched patches) at multiple threshold levels. Baselines and ablations include resized full-image SegFormer, patch-based without edge, edge with various fusion schemes, SH-only, and fused EGS+SH. Statistical tests are not reported explicitly. Cross-domain robustness is tested by training only on TGIF (SD2-based) but evaluating on the diverse, higher-resolution SynthIM validation set.
Reproducibility: Code is implemented in PyTorch and models trained on a single NVIDIA A100 GPU. Exact code or weights release is not mentioned. The TGIF and SynthIM datasets are publicly released as part of MediaEval 2025.
Technical innovations
- A Frequency-based Edge Detector combining fixed high-pass residuals, SRM-like filters, and RGB gradient operators fused via multi-branch dilated residual convolutions and global pooling to produce soft multi-scale edge priors.
- Spatial stacking of RGB image and replicated edge probability maps vertically into a tall tensor for injection into a SegFormer decoder without modifying the backbone encoder.
- Dual-branch framework combining pixel-level edge-guided segmentation with region-level synthetic heatmaps from LoRA-adapted CLIP-ViT classifiers applied in a sliding window manner with Hann blending.
- Sliding-window dense synthetic heatmap generation by reusing a fully regenerated classifier, enabling region-level localization without retraining or additional supervision.
Datasets
- TGIF — ~75,000 samples — public synthetic text-guided inpainting dataset used for training
- SynthIM validation split (SAGI-D subset) — 9,439 images total, 3,043 spliced (SP) images evaluated — MediaEval 2025 public challenge dataset
Baselines vs proposed
- IML-ViT: merged IoU = 0.362 vs EDGER (EGS+SH): 0.590 (Table 1)
- MVSSNet: merged IoU = 0.355 vs EDGER (EGS+SH): 0.590 (Table 1)
- CATNet: merged IoU = 0.351 vs EDGER (EGS+SH): 0.590 (Table 1)
- SegFormer-B3 (baseline patch): image IoU = 0.370 vs EDGER EGS: 0.442, EGS+SH: 0.590 (Table 2)
- SH branch alone: image IoU = 0.384 vs EGS+SH: 0.590 (Table 2)
- Edge prior + SegFormer spatial stacking + augmentation: patch IoU = 0.597, image IoU = 0.442 vs channel adapter fusion: 0.372 image IoU (Table 3)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.12002.
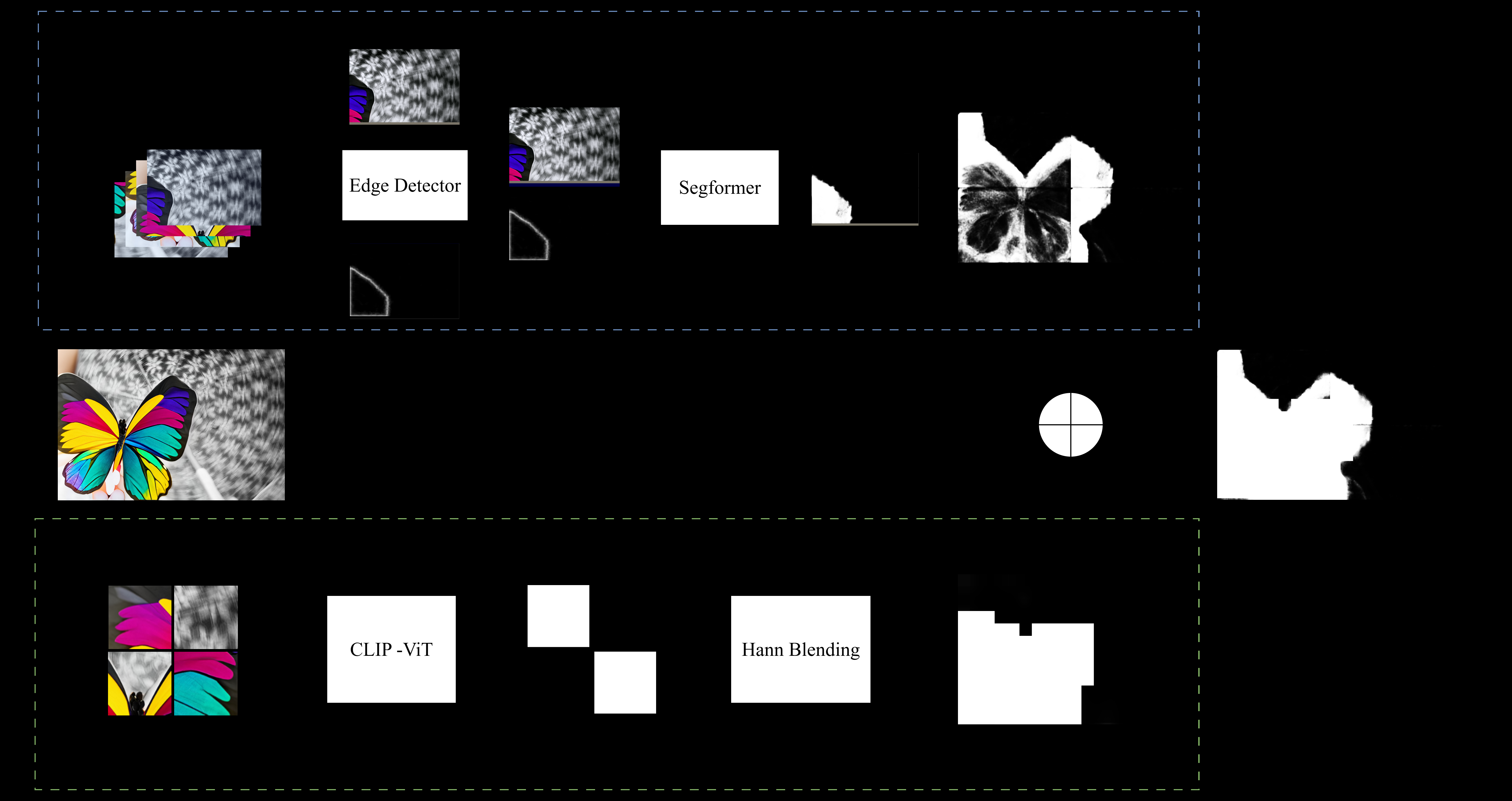
Fig 1: Overall localization pipeline. A patch-based dual-branch design: (i) the EGS
Fig 2: Pipeline of the Frequency-based Edge Detector. The network extracts high-
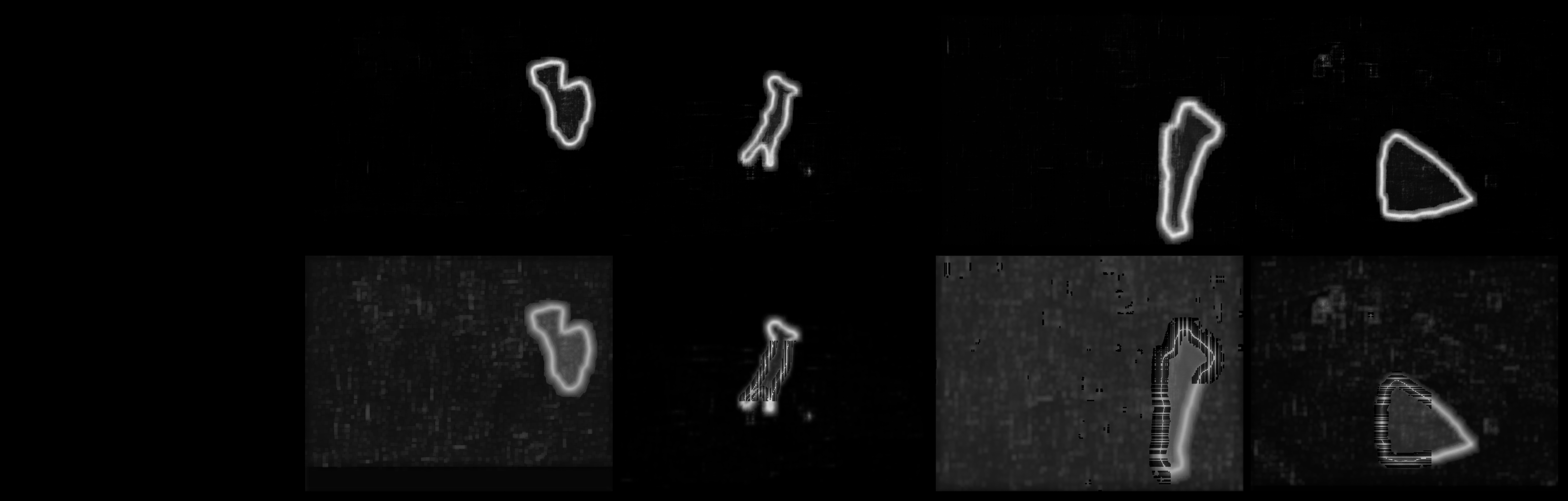
Fig 3: Predicted edge maps and their augmented counterparts used to simulate chal-

Fig 4: Each group of five images shows, from left to right, the EGS mask, the SH mask,

Fig 5: Each triplet shows, from left to right, the SH mask, the ground-truth mask,
Limitations
- The method is evaluated only on synthetic inpainting (spliced) images; fully regenerated images and other manipulation types are outside the main focus.
- Fusion weights the two branches by pixel-wise max, a heuristic without learned adaptive fusion or end-to-end training.
- No explicit adversarial robustness or attack resilience evaluation is provided; robustness is only tested via augmentation of edges and cross-domain evaluations.
- The edge detector is frozen after training on TGIF data, potentially limiting adaptability to new edge artifacts.
- The SH branch relies on FR/non-FR classification labels, which could limit generalizability to novel forgery types lacking such annotations.
- No statistical significance testing or uncertainty quantification for results; single-validation set results only.
Open questions / follow-ons
- Can the dual-branch EDGER framework be extended to fully regenerated and other manipulation types, beyond spliced inpainting?
- Would end-to-end joint training of both branches and learned fusion improve localization accuracy and robustness?
- How does EDGER perform under adversarial perturbations or adaptive attacks against the frequency-based edge detector or SH classifier?
- Can the method be optimized to run efficiently on even larger ultra-high resolution images or video sequences?
Why it matters for bot defense
For bot-defense and CAPTCHA engineering, the EDGER paper provides valuable insights into detecting subtle, realistic image manipulations at scale and across domains—important for verifying image authenticity in web environments where synthetic images may be employed for deception. Its patch-based, resolution-agnostic design demonstrates how to preserve fine manipulation cues without downsampling artifacts, a common challenge in practical deployments dealing with varied input sizes. The dual-branch fusion approach shows the merit of combining low-level boundary anomalies with high-level semantic region reasoning, suggesting that multi-cue fusion is critical for reliable localized forgery detection. However, the reliance on synthetic heatmaps derived from models like CLIP also implies the importance of leveraging strong image-text pretrained representations for improved generalization over fixed forensic features. Overall, the paper underscores that to stay effective against sophisticated generative manipulations, CAPTCHA and bot-detection systems should consider hybrid architectures combining frequency-based edges and learned semantic heatmaps, with evaluation under cross-domain and high-resolution conditions. The approach could inspire future bot-detection pipelines aiming to flag AI-generated or partially forged images used in malicious automation or account hijacking.
Cite
@article{arxiv2605_12002,
title={ EDGER: EDge-Guided with HEatmap Refinement for Generalizable Image Forgery Localization },
author={ Minh-Khoa Le-Phan and Minh-Hoang Le and Minh-Triet Tran and Trong-Le Do },
journal={arXiv preprint arXiv:2605.12002},
year={ 2026 },
url={https://arxiv.org/abs/2605.12002}
}