
When the Ruler is Broken: Parsing-Induced Suppression in LLM-Based Security Log Evaluation
Source: arXiv:2605.07293 · Published 2026-05-08 · By Chaitanya Vilas Garware, Sharif Noor Zisad
TL;DR
This paper identifies and quantifies a critical evaluation failure mode in large language model (LLM)-based Security Operations Center (SOC) log classification systems, termed parsing-induced suppression. The authors demonstrate that common evaluation methods using brittle, strict regular-expression parsers silently discard valid model outputs simply due to formatting mismatches in field names, causing fully functional models to appear non-functional. They use OpenSOC-AI, a LoRA fine-tuned TinyLlama-1.1B model, as a case study and show a 76 percentage-point threat accuracy gap between a strict regex parser (0% accuracy) and a corrected fuzzy parser (76% accuracy) on the same outputs and evaluation data. Severity accuracy remains stable, isolating the parser as the cause rather than model degradation. The authors also benchmark a large zero-shot baseline Claude Sonnet with 88% threat accuracy for context. Residual errors cluster in behaviorally similar categories indicating class-boundary difficulty rather than general failure. To address this systemic evaluation issue, they propose SOC-Bench v0: a standardized 13-category MITRE-aligned taxonomy, minimum per-class sample size, fuzzy extraction protocols, and public scoring scripts to enable comparable, parser-agnostic evaluation across SOC LLM research. This work highlights how evaluation artifacts can dramatically distort perceived model performance, threatening reproducibility and research progress in SOC automation.
Key findings
- Strict regex parser reports 0% threat accuracy on OpenSOC-AI TinyLlama outputs due to field name format mismatch.
- A fuzzy, format-tolerant parser recovers 76% threat accuracy on the identical model outputs and evaluation set.
- Severity accuracy remains constant at 58% under both strict and fuzzy parsers, serving as an internal control isolating evaluation artifact.
- Claude Sonnet zero-shot evaluated on the same 50-example set achieves 88% threat accuracy and 58% severity accuracy under the same fuzzy evaluation protocol.
- All 12 residual misclassifications under fuzzy evaluation concentrate in three adjacent classes: Reconnaissance, Brute Force, and Credential Stuffing.
- 10 of the 13 threat categories achieve 100% accuracy under fuzzy evaluation, highlighting non-uniform error distribution.
- Evaluation set sample sizes per class are small (1-8 examples), yielding wide confidence intervals especially for failure-concentrated categories.
- SOC-Bench v0 defines a 13-category benchmark taxonomy, requires minimum 20 examples per class, fuzzy parsing, failure inspection, and evaluation metadata documentation to prevent parsing-induced suppression and enable reproducibility.
Threat model
n/a — The paper focuses on evaluation methodology for LLM-based SOC log classifiers rather than adversarial threat modeling against the systems themselves.
Methodology — deep read
The paper’s analysis centers on OpenSOC-AI, an existing LoRA fine-tuned tiny Llama 1.1B model trained on security log classification.
Threat Model & Assumptions: The adversary is not explicitly modeled since the focus is evaluation methodology of SOC LLMs rather than attack resilience. The assumed threat is mischaracterization of model capability due to silent parsing failures.
Data: Training used 450 labeled security log examples across 12 broad threat categories. Evaluation used 50 held-out examples spanning 13 categories aligned to SOC-Bench taxonomy. Dataset label distributions are small per category (~1-8). Preprocessing involved truncation and prompt formatting per original OpenSOC-AI setup.
Architecture/Algorithm: The base model is TinyLlama-1.1B Chat v1.0, fine-tuned via QLoRA (rank 16, scaling α=32, dropout 0.05) targeting attention and MLP layers for 3 epochs on a NVIDIA T4 GPU (training ~4.5 min). Output is free-form text containing fields like Threat Type, Severity, MITRE ID.
Training Regime: Consistent with original OpenSOC-AI — three epochs, minibatches unstated, seed strategy not detailed. Only LoRA adapters trained; base model frozen.
Evaluation Protocol: Three pipelines applied to identical model outputs:
- Strict parser: original OpenSOC-AI regex extractor that exactly matches field names like THREAT_TYPE, case-insensitive but sensitive to underscore vs space differences, silently discards mismatches.
- Fuzzy parser: new tolerant regex extractor accepting variants like Threat Type, Threat_Type, Threat-Type with normalization mapping fine-grained outputs to 13 canonical SOC-Bench categories.
- External baseline: Claude Sonnet (Anthropic large model, zero-shot) evaluated with fuzzy parser on same data. Metrics reported include threat accuracy, severity accuracy. The fuzzy parser is the gold standard for result interpretation.
Residual misclassifications analyzed by category, revealing concentration in behaviorally adjacent classes.
- Reproducibility: SOC-Bench v0 framework, including fuzzy parser, taxonomy, scoring script, and 50-example evaluation set, is publicly released on GitHub for independent validation.
Example: The strict parser applied to the TinyLlama outputs misses all threat type fields due to underscore-vs-space mismatch, scoring threat accuracy 0%. The fuzzy parser accepts the model's natural casing and formatting, normalizes semantic categories, yielding 76% threat accuracy on the same outputs, demonstrating parsing-induced suppression is an artifact of brittle extraction, not model failure.
Technical innovations
- Identification and formalization of parsing-induced suppression: a structural evaluation error from field name formatting mismatches that silently discards valid LLM outputs.
- Design of a fuzzy, format-tolerant parser capable of extracting threat types and other fields robustly from free-form LLM output despite variable field name formats.
- SOC-Bench v0 benchmark framework creating a standardized 13-category MITRE-aligned threat taxonomy with minimum per-class examples and fuzzy extraction requirements to improve reproducibility and comparability.
- Failure concentration analysis isolating residual errors to behaviorally adjacent threat categories, distinguishing class-boundary issues from global model failure.
Datasets
- OpenSOC-AI training set — 450 labeled security log entries — original paper dataset
- OpenSOC-AI evaluation set — 50 held-out labeled security log entries — original paper dataset, publicly provided in SOC-Bench repo
Baselines vs proposed
- TinyLlama-1.1B + LoRA with strict parser: threat accuracy = 0.0%, severity accuracy = 58.0%
- TinyLlama-1.1B + LoRA with fuzzy parser: threat accuracy = 76.0%, severity accuracy = 58.0%
- Claude Sonnet zero-shot with fuzzy parser: threat accuracy = 88.0%, severity accuracy = 58.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.07293.
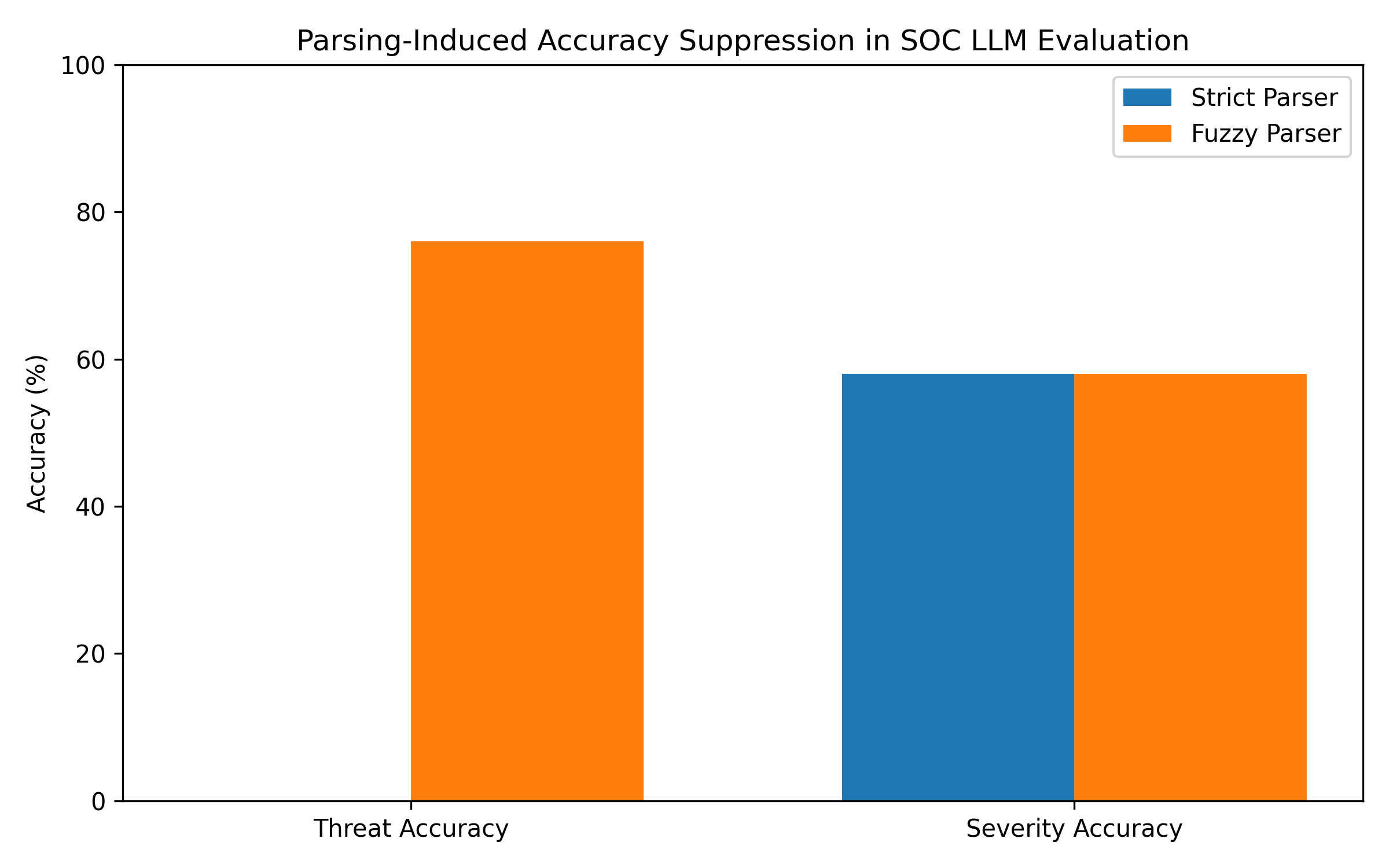
Fig 1: illustrates this result. The visual makes the control
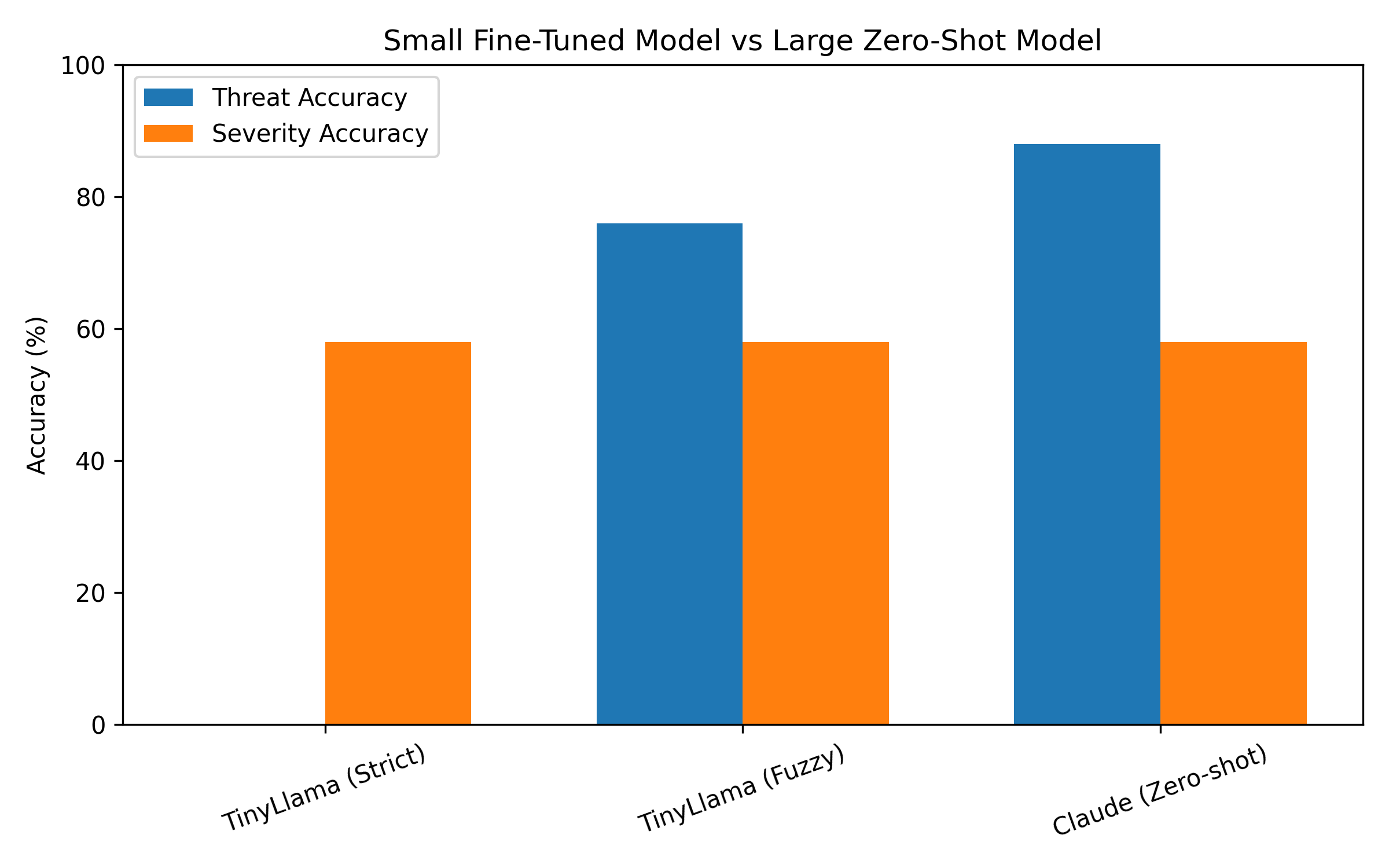
Fig 2: Cross-model comparison under identical fuzzy evaluation protocol
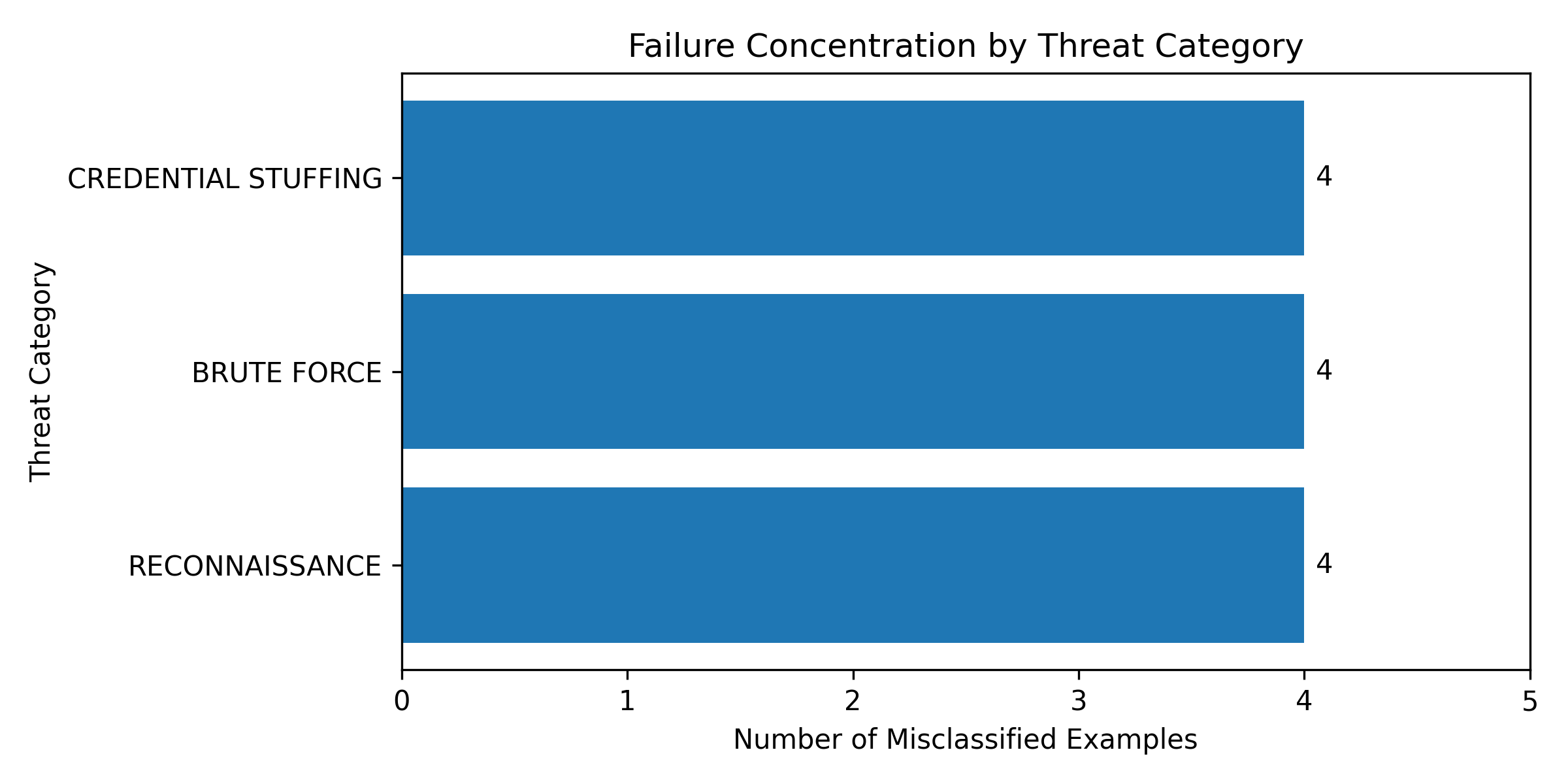
Fig 3: Failure concentration under fuzzy evaluation. All 12 residual errors
Limitations
- Small evaluation set size per category (1-8 examples) yields wide confidence intervals making precise per-class accuracy estimates unreliable.
- Fuzzy parser permissiveness may cause false positives mapping incorrect predictions to correct categories; false-positive rates were not systematically measured.
- Claude Sonnet baseline is proprietary and unreproducible; results may vary over time and cannot be independently verified.
- Observed generation artifacts such as prompt repetition were noted but not causally linked to failures through controlled experiments.
- All controlled fine-tuning experiments use only TinyLlama-1.1B; applicability of parsing-induced suppression magnitude to other model families or scales remains untested.
Open questions / follow-ons
- How does parsing-induced suppression manifest and what is its magnitude with other LLM architectures or scale sizes beyond TinyLlama-1.1B?
- What are the false-positive and false-negative rates of fuzzy extraction parsers, and how can they be optimized to balance extraction tolerance with precision?
- Can augmentation of evaluation datasets reduce class-boundary ambiguities and improve classification of behaviorally adjacent categories like reconnaissance and brute force?
- What controlled inference or fine-tuning interventions could reduce generation artifacts and residual misclassifications observed in certain categories?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners working with security log analysis or threat classification systems based on LLMs will find this work highly relevant. It highlights how brittle evaluation pipelines based on strict regex parsing can completely obscure effective model performance, producing misleading accuracy metrics. The insight that evaluation pipelines must be parser-agnostic, support fuzzy extraction, and include normalization to accommodate natural LLM output variability is critical to ensure reliable benchmarking and deployment decisions.
This research suggests that simply integrating LLM outputs into automated security workflows requires careful attention not only to model architecture or training but also to the downstream parsing and metric extraction logic. The SOC-Bench standard provides a concrete evaluation framework to avoid silent failure modes and facilitate consistent comparisons. For bot-defense systems relying on LLMs, the distinction between parser-induced errors and model errors is crucial to avoid discarding valuable capabilities or misallocating resources based on misleading evaluation artifacts.
Cite
@article{arxiv2605_07293,
title={ When the Ruler is Broken: Parsing-Induced Suppression in LLM-Based Security Log Evaluation },
author={ Chaitanya Vilas Garware and Sharif Noor Zisad },
journal={arXiv preprint arXiv:2605.07293},
year={ 2026 },
url={https://arxiv.org/abs/2605.07293}
}