
VecCISC: Improving Confidence-Informed Self-Consistency with Reasoning Trace Clustering and Candidate Answer Selection
Source: arXiv:2605.08070 · Published 2026-05-08 · By James Petullo, Sonny George, Dylan Cashman, Nianwen Xue
TL;DR
This paper addresses a real cost problem with 'think twice' inference-time scaling: methods like Confidence-Informed Self-Consistency (CISC) improve accuracy over vanilla Self-Consistency by having a critic LLM score each candidate reasoning trace, but this doubles or more the LLM call count and token budget. The authors observe that many of the n=20 sampled traces per question are semantically redundant or degenerate, so calling the critic on all of them wastes money without adding signal. VecCISC inserts a lightweight clustering step between generation and critic scoring: it embeds each reasoning trace using OpenAI's text-embedding-3-small, groups traces by their final answer, clusters within each answer group using either KMeans or Hierarchical Agglomerative Clustering (HAC), and forwards only the centroid-nearest representative from each cluster to the critic — drastically shrinking the critic call count.
The core insight is that semantic deduplication of reasoning traces, rather than random subsampling, acts as an implicit quality filter. Traces that are hallucinated or degenerate tend to form small, isolated clusters far from any centroid and are therefore dropped; the centroid-nearest representative in each surviving cluster is the least anomalous trace for that answer. This preserves the information CISC needs while discarding noise. The addition of an embedding model is intentionally cheap: text-embedding-3-small is low-latency and low-cost relative to a full LLM call, so the net overhead of the clustering step is small compared to the critic calls it eliminates.
Across five benchmarks (AQuA-RAT, CommonsenseQA, ARC-Challenging, MMLU-Pro, GPQA), five models (GPT-4o mini, Llama 3.1 8B, Llama 3.3 70B, Qwen 2.5 7B, Mistral 7B v0.1), and 10 runs per combination, VecCISC+HAC achieves the best or second-best average accuracy in 23 of 25 model-dataset pairs versus CISC, while the VecCISC+KMeans and HAC variants together reduce total pipeline token usage by 47% on average. Critically, an ablation that randomly subsamples K traces instead of clustering (VecCISC random) consistently falls below both CISC and vanilla Self-Consistency, confirming that the quality filtering effect of clustering — not merely the call reduction — drives the accuracy maintenance.
Key findings
- VecCISC+KMeans reduces LLMcritic call count by 34.68% on average across all 25 (dataset, model) combinations; VecCISC+HAC reduces it by 30.2% (Tables 1 and 2).
- Averaging token consumption across the entire pipeline (sampling + critic), both VecCISC variants achieve a 47% total token reduction relative to CISC, despite LLMcritic calls accounting for 77% of total token usage.
- VecCISC+KMeans reduces critic-only token usage by 36.2%; VecCISC+HAC reduces critic-only token usage by 31.69% (Tables 3 and 4).
- The random-subsampling ablation (VecCISC random) significantly underperforms CISC and Self-Consistency, e.g., dropping Llama 3.1 8B accuracy on CommonsenseQA from 77.3% (CISC) to 54.7% average, confirming that clustering quality filtering — not just call reduction — is responsible for maintained accuracy.
- Min-centroid representative selection outperforms random-within-cluster trace selection (rand-trace) on 15/25 model-dataset pairs for KMeans (60%) and 17/25 for HAC (68%), though the absolute token differences between the two selection strategies are very small in most cells (Tables 3 and 4).
- VecCISC+HAC records the best average accuracy on 23 of 25 (dataset, model) combinations relative to all baselines, including on GPQA with Llama 3.3 70B: 61.7% vs 61.7% CISC and 60.6% SC (matching CISC without accuracy loss).
- The largest single-combination call budget reductions are extreme outliers: VecCISC+KMeans reduces GPT-4o mini critic calls on AQuA-RAT by 71.72% (to 5.66 calls from a budget of 20) and Llama 3.3 70B on AQuA-RAT by 86.99% (Table 1), suggesting high trace redundancy for algebraic word problems with capable models.
- Hyperparameters K (cluster count) and temperature T (softmax smoothing) are dataset- and model-specific and were found via grid search on a holdout set; the paper provides heatmaps for selected values (Figs 3, 4, 5), but no single universal K or T was found to dominate.
Threat model
n/a — this is an LLM inference efficiency paper, not a security or adversarial robustness paper. The paper does not define a malicious adversary. The implicit 'adversary' is economic cost: the LLMcritic call overhead in weighted majority voting inference pipelines. The framework assumes black-box API access to both generator and critic LLMs, and treats hallucinated or degenerate traces as naturally occurring noise rather than adversarially injected content.
Methodology — deep read
Threat model and assumptions: This paper is not a security paper in the adversarial-attack sense. The implicit assumption is that the adversary is cost, not a malicious actor. The threat is economic: CISC's critic LLM calls scale linearly with the number of sampled traces, making it expensive at production inference budgets. The paper assumes the generator LLM (LLMgen) and critic LLM (LLMcritic) are black-box APIs (supporting both open- and closed-source models), and that reasoning trace embeddings via a general-purpose embedding model are sufficient to capture semantic equivalence across diverse domains. No white-box access (logits, hidden states) is assumed.
Data provenance, size, labels, splits, preprocessing: Five public multiple-choice QA datasets were used. AQuA-RAT (algebraic word problems): 1,000 questions sampled from the training split. CommonsenseQA (commonsense reasoning): 1,000 questions from the validation split. ARC-Challenging (grade-school science): 1,000 questions from the test split. MMLU-Pro (multi-domain reasoning): 1,000 questions from the test split. GPQA (expert-level biology, physics, chemistry): all 546 questions used. Splits were used as-is from their public releases; no additional preprocessing beyond formatting for prompts is described. All prompts were zero-shot. The paper uses a holdout set from each (dataset, model) combination for hyperparameter grid search (K and T), though the exact holdout size is not specified in the truncated text.
Architecture and algorithm — the VecCISC pipeline step by step: (1) Sampling: given question q and sampling budget n=20, LLMgen is called n times with a structured JSON prompt instructing chain-of-thought reasoning plus a final answer ID. This yields n (reasoning trace, answer) pairs. (2) Embedding: each reasoning trace ri is encoded via OpenAI text-embedding-3-small, producing a vector in R^d. The choice of this model is explicitly motivated by cost-generality tradeoff. (3) Grouping by answer: traces are partitioned into groups Ga, one per unique final answer a, so that clustering respects answer identity and does not conflate traces leading to different conclusions. (4) Clustering: within each group Ga, either KMeans or HAC is applied with a target of K clusters (or |Ga| clusters if |Ga| < K). K is a grid-searched hyperparameter per (dataset, model) combination. DBSCAN was explicitly rejected because its distance threshold D is unstable in high-dimensional embedding spaces. (5) Centroid-nearest representative selection: for each cluster Ci, the centroid ui is computed as the mean of member embeddings, and the trace with highest cosine similarity to ui is selected as the cluster's representative. The rationale is that the centroid-nearest trace is semantically least deviant, hence least likely to contain hallucinated or anomalous reasoning. (6) Confidence scoring: for each unique answer a, each of its representative traces is concatenated with the original question and answer into a prompt for LLMcritic, which returns a scalar confidence in [0,1]. Scores are softmax-normalized with a temperature T (also grid-searched). (7) Weighted majority vote: the final answer is the argmax of accumulated softmax-normalized confidence scores across all representatives for each answer (Equation 12).
Training regime: There is no training in the conventional sense — no gradient updates, no fine-tuning. The 'training'-equivalent step is a per-(dataset, model) grid search over K and T on a holdout subset. The paper provides heatmaps (Figs 3, 4, 5) showing selected K and T values but does not specify holdout size or the grid search ranges in the truncated text. All LLM calls use unspecified temperature settings for generation (referred to as 'model hyperparameters in Appendix A', which is not fully available in the truncated text). Embeddings are deterministic given the trace; clustering (KMeans) and the final answer sampling (non-deterministic models) introduce stochasticity.
Evaluation protocol: Each (dataset, model, method) combination was run 10 times independently to account for non-determinism in KMeans initialization and LLM sampling. Both best and average accuracy across 10 runs are reported (Table 5). Baselines are vanilla Self-Consistency (SC, majority vote), CISC (reimplemented by the authors on the same sampled question sets to ensure apples-to-apples comparison), VecCISC+KMeans, VecCISC+HAC, and VecCISC(random) as the key ablation. The random variant samples K traces per answer group uniformly at random instead of clustering, isolating the contribution of clustering quality filtering from the call-reduction effect alone. Metrics reported are: accuracy (Table 5), critic call budget reduction percentage (Tables 1, 2), and per-critic token count (Tables 3, 4). Token counting uses the approximation length(prompt)/4 tokens, acknowledged as an approximation for cross-model fairness. No statistical significance tests (t-tests, bootstrap CIs) are reported; the 10-run best/average reporting is the primary variance control. No held-out adversarial test set or distribution-shift evaluation is included.
Concrete end-to-end example: For a single GPQA question with GPT-4o mini and n=20: LLMgen produces 20 (trace, answer) pairs. Suppose 4 unique answers appear. Each trace is embedded. Within each answer group, KMeans with grid-searched K clusters the embeddings; assume K=2 for a group of 8 traces → 2 representatives forwarded to LLMcritic. Across 4 answer groups with varying sizes, perhaps 7 total critic calls are made instead of 20, yielding a 47.19% critic call reduction (Table 1, GPT-4o mini, GPQA). LLMcritic scores each representative in [0,1]; softmax with grid-searched T normalizes them; weighted majority vote selects the final answer.
Reproducibility: The authors state code will be released publicly. Embeddings use a commercially available API (text-embedding-3-small), which is versioned but not frozen against future API changes. LLM outputs are non-deterministic and API-dependent. The holdout split details and exact hyperparameter grid search ranges are deferred to Appendix A, which is not fully available in the truncated text. No frozen weights or dataset snapshots are described.
Technical innovations
- Answer-grouped embedding clustering for critic call reduction: unlike prior work (Knappe et al., 2024) that embeds traces for direct score computation without a critic, VecCISC uses clustering specifically to select a small set of high-quality representative traces per answer to forward to an existing 'think twice' critic, preserving the critic's scoring signal while reducing its call count.
- Centroid-nearest representative selection as an implicit quality filter: selecting the trace closest to a cluster's embedding centroid (by cosine similarity) acts as an anomaly-rejection heuristic, isolating hallucinated or degenerate traces that form peripheral or singleton clusters — a distinct mechanism from random subsampling within clusters.
- Answer-identity-preserving grouping before clustering (Equation 4): by clustering only within traces that share the same final answer, the method ensures that cluster reduction never collapses semantically distinct answers, a failure mode that would occur if all traces were clustered globally.
- Adaptive K selection per (dataset, model) via holdout grid search: rather than a fixed compression ratio, K adapts to the redundancy structure of each model-dataset combination, allowing the framework to be lightweight on high-redundancy settings (e.g., 86.99% reduction on AQuA-RAT with Llama 3.3 70B) without over-compressing low-redundancy ones.
- Explicit rejection of DBSCAN for high-dimensional LLM embedding spaces: the paper provides a principled argument (distance threshold instability in high-dimensional spaces) for preferring KMeans and HAC, which accept a target cluster count, over density-based methods — a practical design choice not previously articulated in this context.
Datasets
- AQuA-RAT — 1,000 questions sampled from training split — public (Ling et al., 2017)
- CommonsenseQA — 1,000 questions sampled from validation split — public (Talmor et al., 2019)
- ARC-Challenging — 1,000 questions sampled from test split — public (Clark et al., 2018)
- MMLU-Pro — 1,000 questions sampled from test split — public (Wang et al., 2024)
- GPQA — 546 questions (full dataset) — public (Rein et al., 2023)
Baselines vs proposed
- Self-Consistency (SC): AQuA-RAT/GPT-4o mini accuracy = 83.5% vs VecCISC+KMeans: 84.3% avg / 84.6% best (Table 5)
- CISC: AQuA-RAT/GPT-4o mini accuracy = 84.0% vs VecCISC+HAC: 84.3% avg (Table 5)
- CISC: MMLU-Pro/Llama 3.3 70B accuracy = 71.3% vs VecCISC+KMeans: 71.3% avg / 71.4% best (Table 5)
- CISC: GPQA/GPT-4o mini accuracy = 40.5% vs VecCISC+KMeans: 39.9% avg / 41.4% best (Table 5)
- CISC: ARC-Challenging/GPT-4o mini critic tokens = 12,245.4 vs VecCISC+KMeans min-centroid: 6,365.6 (Table 3)
- CISC: GPQA/Llama 3.3 70B critic tokens = 25,235.3 vs VecCISC+KMeans min-centroid: 22,389.4 (Table 3, smallest relative reduction observed)
- VecCISC (random) ablation: CommonsenseQA/Llama 3.1 8B accuracy = 54.7% avg vs CISC: 77.3% — random subsampling severely degrades accuracy (Table 5)
- CISC: total pipeline token reduction vs VecCISC+KMeans: 0% vs -47% (averaged across all 25 model-dataset combinations)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.08070.
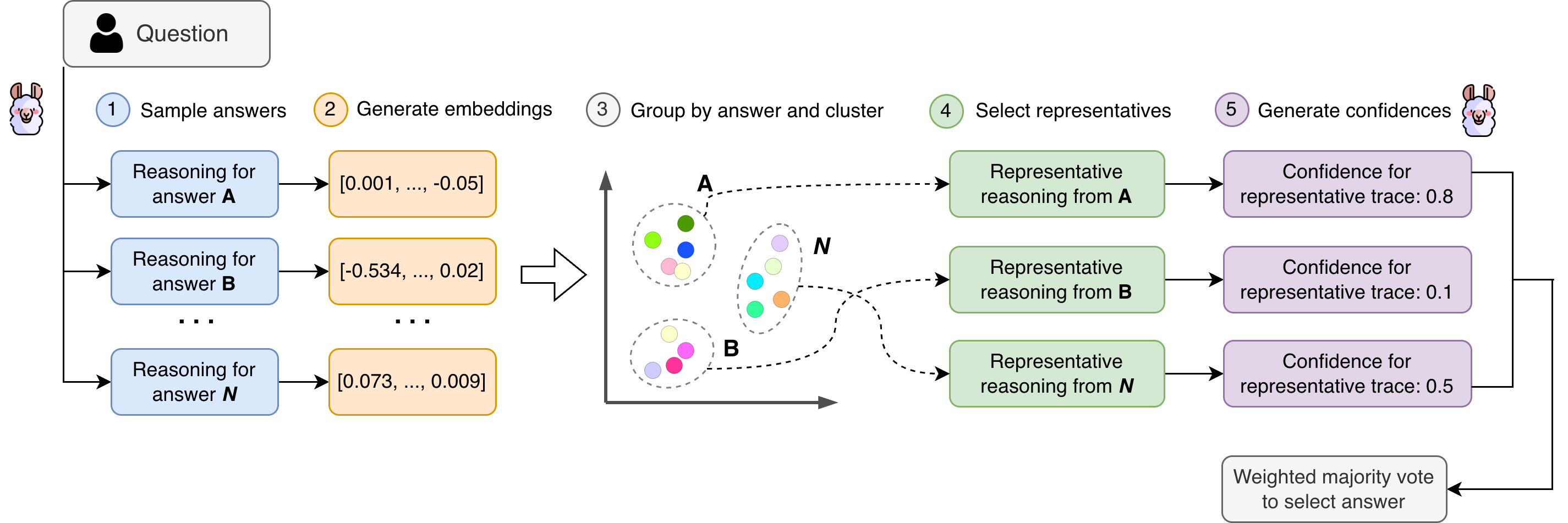
Fig 1: Overview of the VecCISC pipeline. Embeddings of the sampled reasoning traces are clustered within each
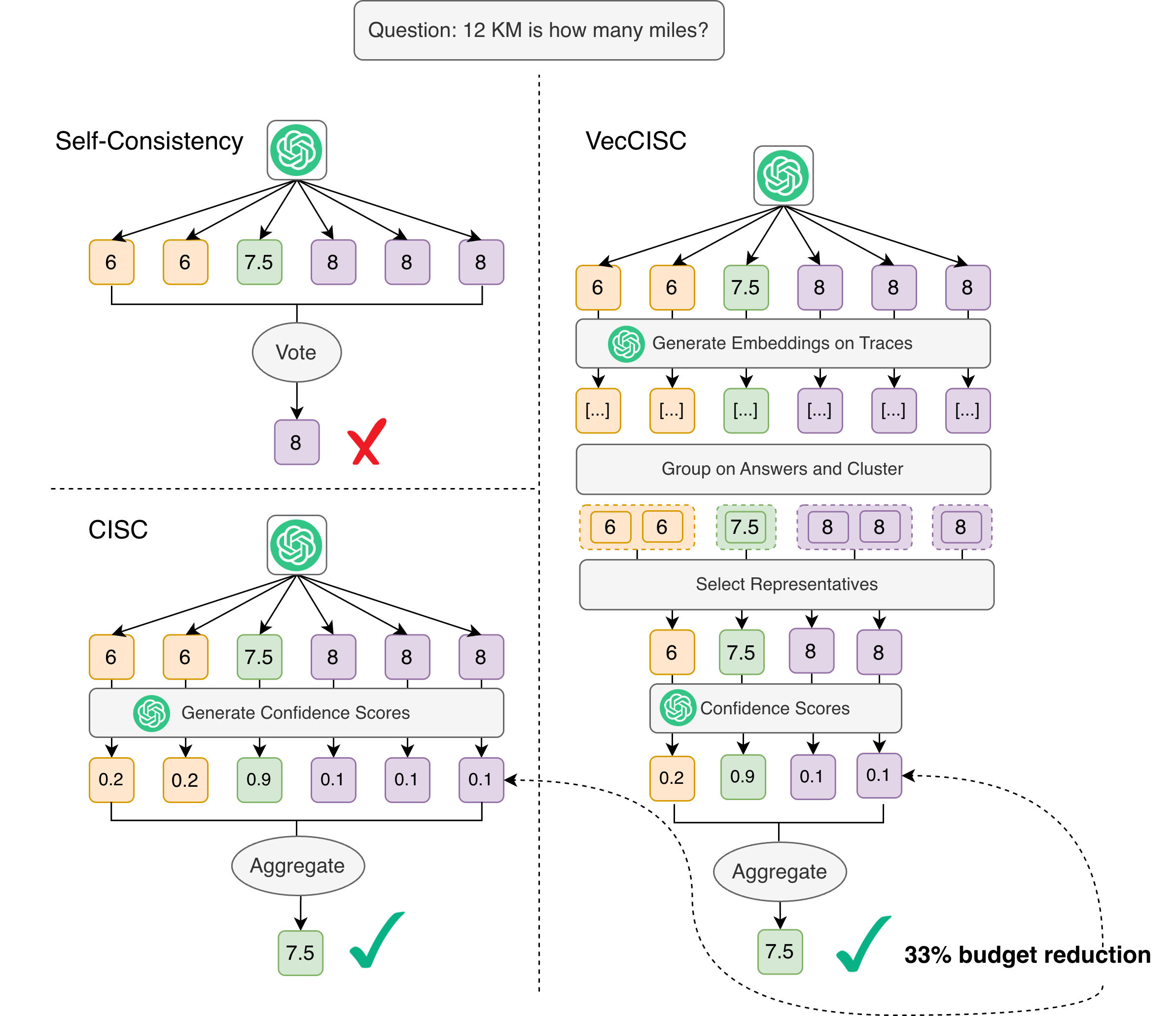
Fig 2: Comparison of VecCISC to Self-Consistency (SC) and CISC. While CISC represents an improvement
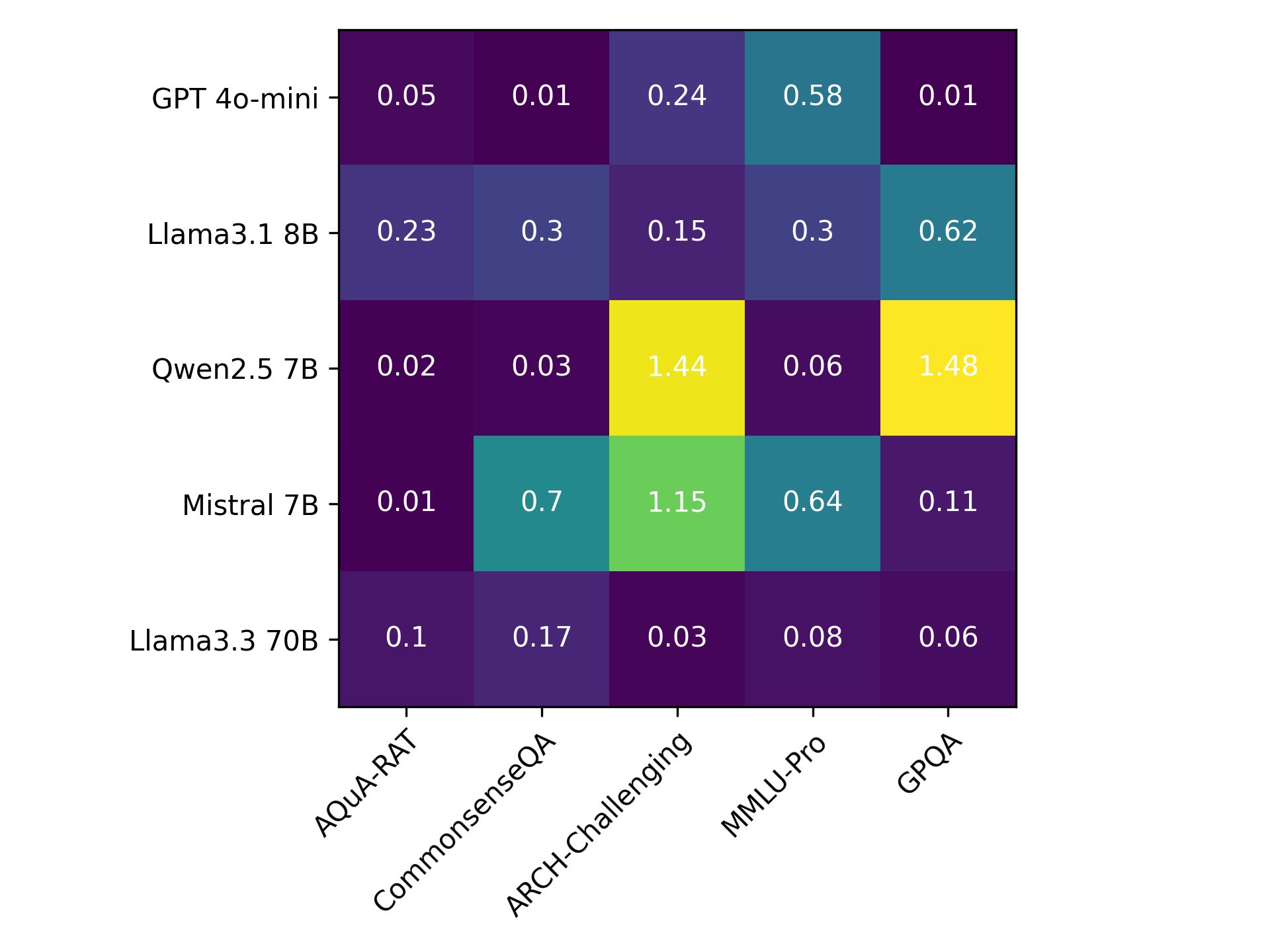
Fig 3: Heatmap of T temperature values. To find T,
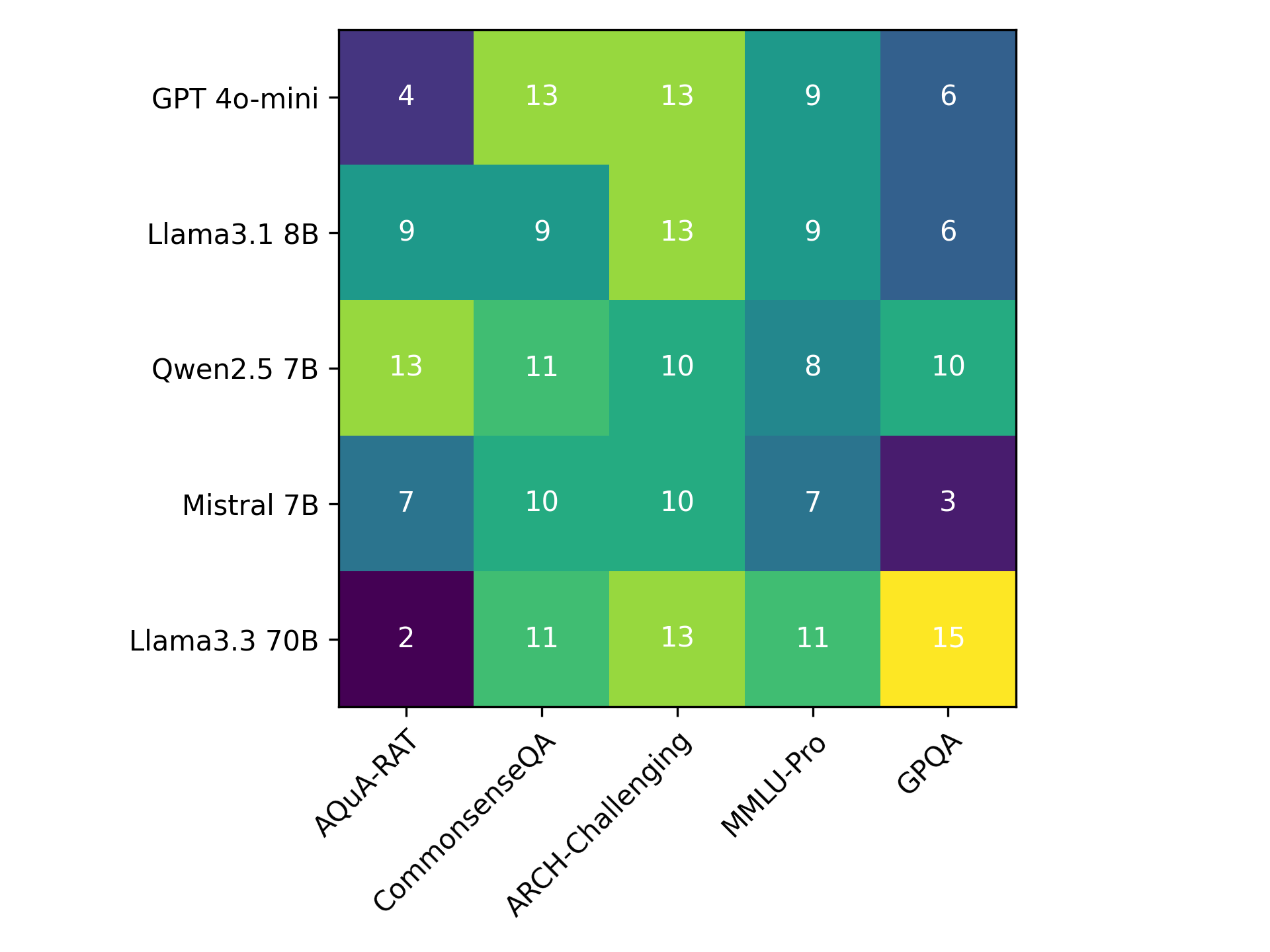
Fig 4: Heatmap of values for K used in VecCISC
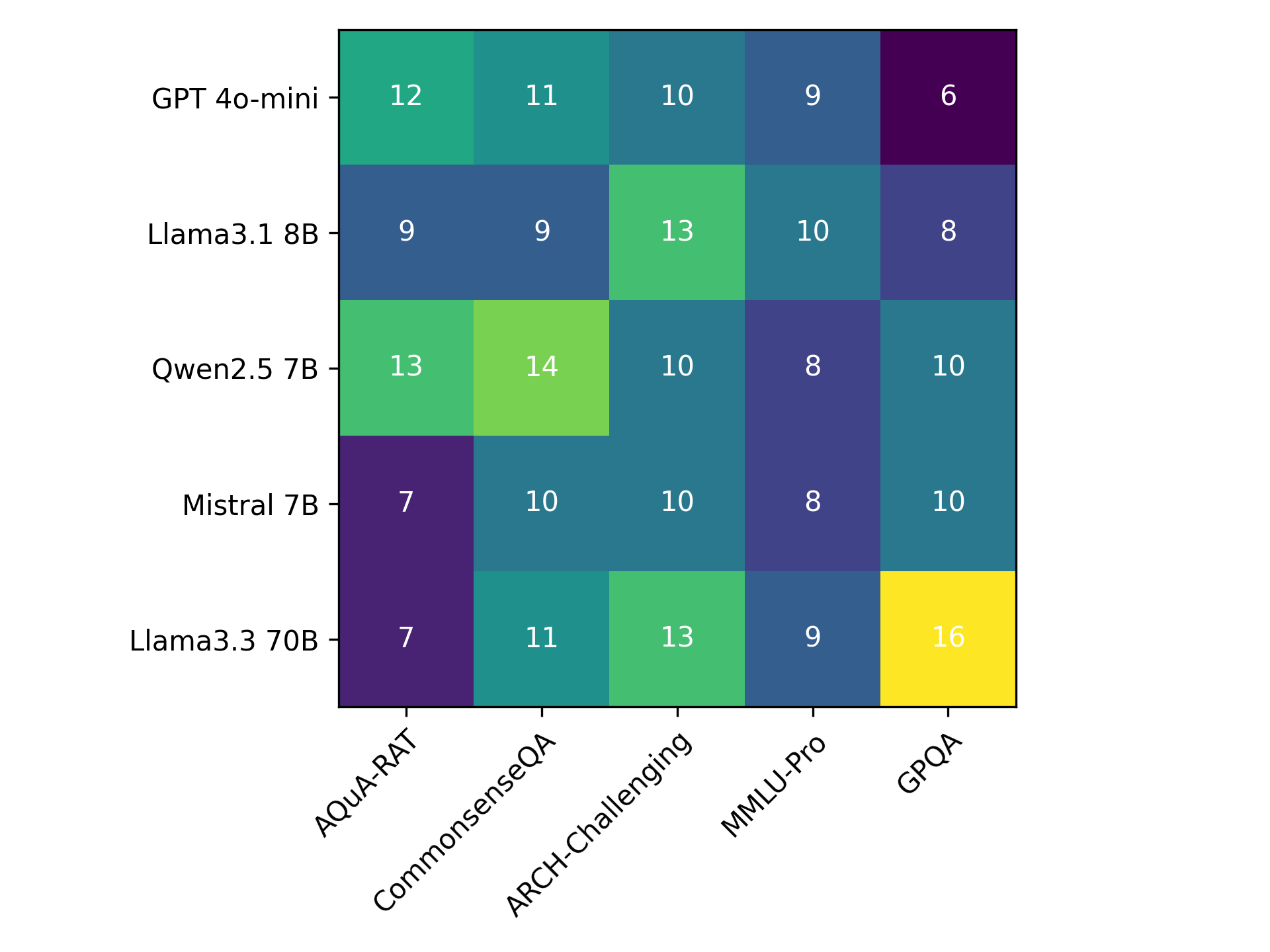
Fig 5: Heatmap of values for K used in VecCISC +
Limitations
- Holdout-dependent hyperparameters: K and T are selected via grid search on a per-(dataset, model) holdout set, meaning VecCISC requires labeled reference data to configure — a non-trivial requirement in production settings where no analogous in-domain holdout exists, as the authors themselves acknowledge.
- General-purpose embedding model only: all experiments use OpenAI text-embedding-3-small; the paper defers domain-specific fine-tuned embedding models to future work, leaving open the question of whether the quality-filtering effect holds for highly specialized domains (e.g., code, formal mathematics, legal text) where a general embedding may not capture semantic equivalence well.
- Token counting approximation: tokens are estimated as length(prompt)/4 for cross-model comparability, which is an approximation that may systematically over- or under-count for non-English or code-heavy reasoning traces, and does not reflect actual API billing precisely.
- No statistical significance testing: accuracy comparisons rely on best/average over 10 runs with no confidence intervals, p-values, or bootstrap tests, making it difficult to assess whether small accuracy gains (e.g., 84.0% CISC vs 84.3% VecCISC+HAC on AQuA-RAT/GPT-4o mini) are meaningfully significant or within noise.
- No evaluation on open-ended or free-form generation tasks: all five benchmarks are multiple-choice, which constrains answer grouping to a small discrete set (typically 4-5 options). The method's applicability to free-form QA, where answer deduplication requires fuzzy matching, is unaddressed.
- Sampling budget n=20 fixed across all experiments: the paper does not explore how VecCISC's reduction rates and accuracy tradeoffs change with different n values (e.g., n=5 or n=50), leaving the method's behavior at other compute budgets unknown.
- No ablation on embedding model choice: the entire pipeline's quality-filtering effect depends on the embedding model's ability to distinguish semantically equivalent from semantically distinct traces; no sensitivity analysis across embedding models is performed.
Open questions / follow-ons
- Adaptive K without holdout data: the current K selection requires per-(dataset, model) grid search on labeled reference data; can an unsupervised criterion (e.g., silhouette score, elbow method, or a learned predictor of answer redundancy) select K adaptively at inference time without any labeled holdout?
- Extension to free-form and chain-of-thought generation: all benchmarks are multiple-choice, enabling clean grouping by answer ID; for open-ended tasks where answers are strings, how should answer identity be determined (exact match, fuzzy match, embedding similarity threshold), and does cluster-based representative selection still yield quality filtering benefits?
- Interaction with reasoning model architectures: VecCISC was tested on instruction-tuned models without explicit reasoning tokens (e.g., not o1-style step-token models); for models that produce structured, step-tagged reasoning traces, do embedding-based clusters capture step-level errors or only trace-level semantic divergence?
- Domain-specific embedding models: the paper defers fine-tuned embeddings to future work; would a domain-fine-tuned embedding (e.g., on chemistry or biology text for GPQA) yield tighter, more meaningful clusters and further improve the quality filtering effect, and would the efficiency gains be preserved or amplified?
Why it matters for bot defense
VecCISC is not directly a bot-defense or CAPTCHA paper, but its core technique — semantic deduplication of LLM outputs via embedding clustering before expensive downstream evaluation — is relevant to practitioners building LLM-based bot-behavior analysis pipelines. Bot detection increasingly involves LLM critics or classifiers scoring candidate behavioral traces, session summaries, or reasoning about whether a sequence of actions is human-like. If such a pipeline samples multiple model outputs (e.g., for ensemble scoring or self-consistency over ambiguous bot signals), VecCISC's clustering approach could reduce the number of expensive critic calls while maintaining or improving classification accuracy — directly reducing cost at scale. The finding that random subsampling of traces catastrophically degrades accuracy (CommonsenseQA/Llama 3.1 8B drops from 77.3% to 54.7%) is a strong warning against naive cost-cutting through random pruning in any such pipeline.
More broadly, the paper's demonstration that semantically near-duplicate reasoning traces can be reliably identified and collapsed via a cheap embedding model, and that centroid-nearest traces are higher quality than random draws, has implications for any bot-defense system that uses LLM ensembles or repeated inference to make risk decisions. The 47% total token reduction with no accuracy loss is a practically significant result — at the call volumes of a production CAPTCHA or fraud-detection system, this represents substantial cost savings. A bot-defense engineer should note the limitation around holdout-dependent hyperparameters (K, T), which could require online adaptation mechanisms in a production setting where traffic distribution shifts, and should verify that text-embedding-3-small captures the semantic structure of behavioral or session-level text rather than assuming the benchmark results transfer directly.
Cite
@article{arxiv2605_08070,
title={ VecCISC: Improving Confidence-Informed Self-Consistency with Reasoning Trace Clustering and Candidate Answer Selection },
author={ James Petullo and Sonny George and Dylan Cashman and Nianwen Xue },
journal={arXiv preprint arXiv:2605.08070},
year={ 2026 },
url={https://arxiv.org/abs/2605.08070}
}