
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
Source: arXiv:2605.07110 · Published 2026-05-08 · By Zejian Chen, Zhanyuan Liu, Chaozhuo Li, Mengxiang Han, Songyang Liu, Litian Zhang et al.
TL;DR
This paper addresses a structural gap in the computer-use agent (CUA) literature: existing surveys organize the field by methods, platforms, benchmarks, or threat categories, but none provide a unified account of how capability formation, authority exposure, failure origin, and control placement interact across both system architecture and deployment lifecycle. The authors respond by proposing an architecture–lifecycle framework that cross-cuts a tri-layer architectural view (Perception, Decision, Execution) with a four-stage lifecycle view (Creation, Deployment, Operation, Maintenance). The result is a diagnostic coordinate system intended to help practitioners distinguish where a failure becomes visible from where its enabling condition was actually introduced — a distinction the authors treat as the central analytical commitment of the work.
The paper is a synthesis and organizational contribution rather than an empirical one. It does not introduce a new benchmark, new model, or new dataset. Instead, it surveys representative CUA systems (CogAgent, OpenCUA, Mobile-Agent-v3.5, OmniParser, SeeClick, etc.), benchmarks (Mind2Web, OSWorld, WebArena, ScreenSpot-Pro), and security/privacy evaluation frameworks (OS-Harm, WAInjectBench, WebPII, Risky-Bench) and interprets them through the proposed framework. Table I situates the framework against prior survey families; Table II provides the full 4×3 coordinate system; Table III catalogs architectural archetypes with their reliability pressures.
The main result is a structured map of intervention surfaces: data and reward design at Creation, permission scoping and provenance-aware tool mediation at Deployment, runtime verification and human escalation at Operation, and continual assurance under drift at Maintenance. OpenClaw is used only as a motivating public example of an open-deployment pattern and is explicitly not treated as a verified case study. The paper concludes by identifying six open challenges: controllable grounding, long-horizon constraint preservation, safe authority binding, mixed-trust runtime defense, privacy-preserving memory, and continual assurance.
Key findings
- The same model policy acquires a materially different risk profile once it is bound to live tools, sessions, and permissions at Deployment — capability is lifecycle-dependent, not purely model-dependent.
- Many runtime failures (e.g., brittle recovery paths visible during Operation) have enabling conditions introduced earlier: weak grounding supervision at Creation or over-broad permission scope at Deployment — treating every high-risk action as a runtime reasoning defect hides the real control surface.
- ScreenSpot-Pro is cited as evidence that high-resolution professional interfaces still punish small-target grounding even when broader GUI benchmark scores look competitive, indicating that recognition accuracy is an insufficient proxy for execution safety.
- No current perception family simultaneously maximizes element-grounding precision, small-target robustness, scale/theme/localization robustness, and downstream executability — every architectural bet trades one axis against others.
- Low-level mouse/keyboard actions and high-level shell/API actions differ not just in granularity but in blast radius, auditability, and rollback properties; modern CUAs increasingly combine both, making execution design inseparable from permission scope.
- Mixed-trust observability is treated as a default rather than an edge case: the same observation stream can contain user intent, benign interface content, deceptive prompts, retrieved text, and attacker-controlled tool output simultaneously (citing WAInjectBench, WebPII, Risky-Bench, OS-Harm).
- Post-release drift (UI changes, localization shifts, tool/extension updates) is identified as a distinct fourth stage that can reopen failure modes closed at earlier stages, requiring continual rather than one-time assurance.
- Three deployment archetypes are distinguished — benchmark-centered research agents, consumer/assistant-style deployed agents, and self-hosted gateway/tool-binding agents — each with structurally different risk profiles even at equivalent capability levels.
Threat model
The paper does not specify a single unified threat model but synthesizes several from the cited security/privacy literature. The implicit adversary class spans passive and active threats across lifecycle stages. At Creation, the adversary may influence training data or reward signals to embed unsafe grounding habits or action-vocabulary biases. At Deployment, adversaries can exploit over-broad permission bindings, compromised or malicious tool backends, and weakly mediated observation channels. At Operation, the primary adversary is a mixed-trust input injector: an attacker who can place deceptive prompts, adversarial interface content, or malicious tool responses into the agent's observation stream (modeled concretely via WAInjectBench and WebPII). The adversary is assumed to have access to the agent's visible observation surface but not necessarily to model weights or deployment configuration internals. The paper explicitly does not assume a single adversary capability level; instead, it maps threats by lifecycle stage and architectural layer. What adversaries cannot do is left underspecified — a limitation the authors do not fully acknowledge.
Methodology — deep read
This is a survey and framework paper; there is no experimental methodology in the empirical sense. The authors instead employ an organizational and diagnostic methodology whose steps can be reconstructed as follows.
Step 1 — Problem formalization. The authors define a CUA as a policy π(at | ht, ot, g, c) operating over a partially observable software environment E, emitting authority-bearing actions rather than text alone. This formalization is used to motivate why task-success metrics are insufficient: the policy must respect user-specified constraints c, authority boundaries, and recoverability under uncertainty. Three properties of software environments are identified as load-bearing: semantic density (small UI elements carry disproportionate consequences), mixed-trust by default (the observation stream is heterogeneous in trustworthiness), and layered authority (model selection and system permission exercise are distinct).
Step 2 — Framework construction. Two orthogonal views are introduced and cross-tabulated. The architectural view decomposes a CUA into three coupled layers: Perception (raw software observations → actionable state), Decision (actionable state + goal/constraints → trajectory), and Execution (trajectory → authority-bearing operations). The lifecycle view decomposes deployment into four stages: Creation (priors, grounding habits, action vocabulary formed pre-release), Deployment (tools, sessions, permissions, observation channels bound to live surfaces), Operation (trajectories stressed by partial observability, long horizons, mixed-trust inputs), and Maintenance (model–environment–ecosystem stack validity preserved under drift). The 4×3 cross-product yields a working coordinate system (Table II) whose cell entries describe what object is being shaped, which layer is under pressure, and why that stage is analytically distinct.
Step 3 — Assignment rule. An issue is assigned to the earliest stage at which it was materially introduced or could still have been constrained. This rule operationalizes the key distinction between failure origin and failure manifestation and is applied consistently throughout Sections IV–VI to avoid the analytical error of treating all visible runtime failures as runtime causes.
Step 4 — Literature synthesis. The authors survey systems, benchmarks, and security/privacy evaluation studies and map each to cells of the framework. Representative systems include structured-state agents (Mind2Web, WebArena), parser-augmented visual agents (OmniParser, ScreenAI, SeeClick, Ferret-UI, TRISHUL), native end-to-end visual agents (CogAgent, Qwen-VL style, WinClick, MAI-UI, Step-GUI, Mobile-Agent-v3.5, AFRAgent), and hybrid compositional agents. Security/privacy studies referenced include OS-Harm, WAInjectBench, Risky-Bench, and WebPII. The selection criterion is stated explicitly: coverage is weighted toward studies that 'materially inform how CUAs behave once they interact with real software surfaces and operational authority.' Table I formalizes the positioning of six prior literature families against the proposed framework, identifying what each family clarifies and what it leaves less explicit in live deployment.
Step 5 — Threat and control mapping. Section VI maps threats back onto both dimensions of the framework (Figure 3 in the paper serves as an 'intervention map': for each lifecycle stage, salient threat surfaces, system components under pressure, and candidate controls are identified). Controls are categorized by stage: data/reward design and action vocabulary scoping at Creation; permission minimization, provenance-aware tool mediation, and sandboxed execution at Deployment; runtime verification, anomaly detection, human escalation, and rollback at Operation; regression testing, interface monitoring, and threat model refresh at Maintenance.
Step 6 — Open-deployment illustration. OpenClaw is used as a publicly described motivating example of a self-hosted gateway archetype — persistent ingress, tool connectivity, longer-lived context, participation in a broader agent community. The authors explicitly disclaim it as a verified internal case study; it is used only to illustrate how deployment choices (channels, tools, sessions, persistent context) can account for a large share of the resulting risk profile independent of model capability.
Reproducibility note: The paper is entirely organizational. There are no models to release, no datasets to freeze, and no weights to publish. The framework itself is fully described in Tables I–III and Figures 1–3. Whether the framework is useful depends on reader judgment rather than replication.
Technical innovations
- The architecture–lifecycle cross-product framework (3 layers × 4 stages) provides a diagnostic coordinate system that, unlike prior CUA surveys organized by method, platform, or threat family, explicitly separates failure origin from failure manifestation — a distinction prior surveys left implicit.
- The 'assignment rule' (assign an issue to the earliest stage at which it was materially introduced or could still have been constrained) operationalizes failure-origin analysis and prevents the common analytical error of attributing all visible runtime failures to runtime reasoning defects.
- Three structurally distinct deployment archetypes (benchmark-centered research agents, consumer/assistant-style deployed agents, self-hosted gateway/tool-binding agents) are defined with explicit risk-profile differences, in contrast to prior work that treats deployment as a binary benchmark-vs-real-world distinction.
- Execution design is reframed not merely as action granularity but as a joint function of blast radius, auditability, and rollback properties, distinguishing the authority-exposure consequences of low-level GUI actions from high-level API/shell invocations even when both appear in the same task.
Datasets
- Mind2Web — web task benchmark, size not specified in truncated text — public
- WebArena — web task benchmark, size not specified — public
- OSWorld — OS-level task benchmark, size not specified — public
- ScreenSpot-Pro — high-resolution professional GUI grounding benchmark, size not specified — public
- OS-Harm — action-level harm evaluation, size not specified — public
- WAInjectBench — web agent injection benchmark, size not specified — public
- Risky-Bench — deployment-grounded risk evaluation, size not specified — public
- WebPII — privacy/PII exposure evaluation, size not specified — public
- WebForge — synthetic environment builder, size not specified — public
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.07110.
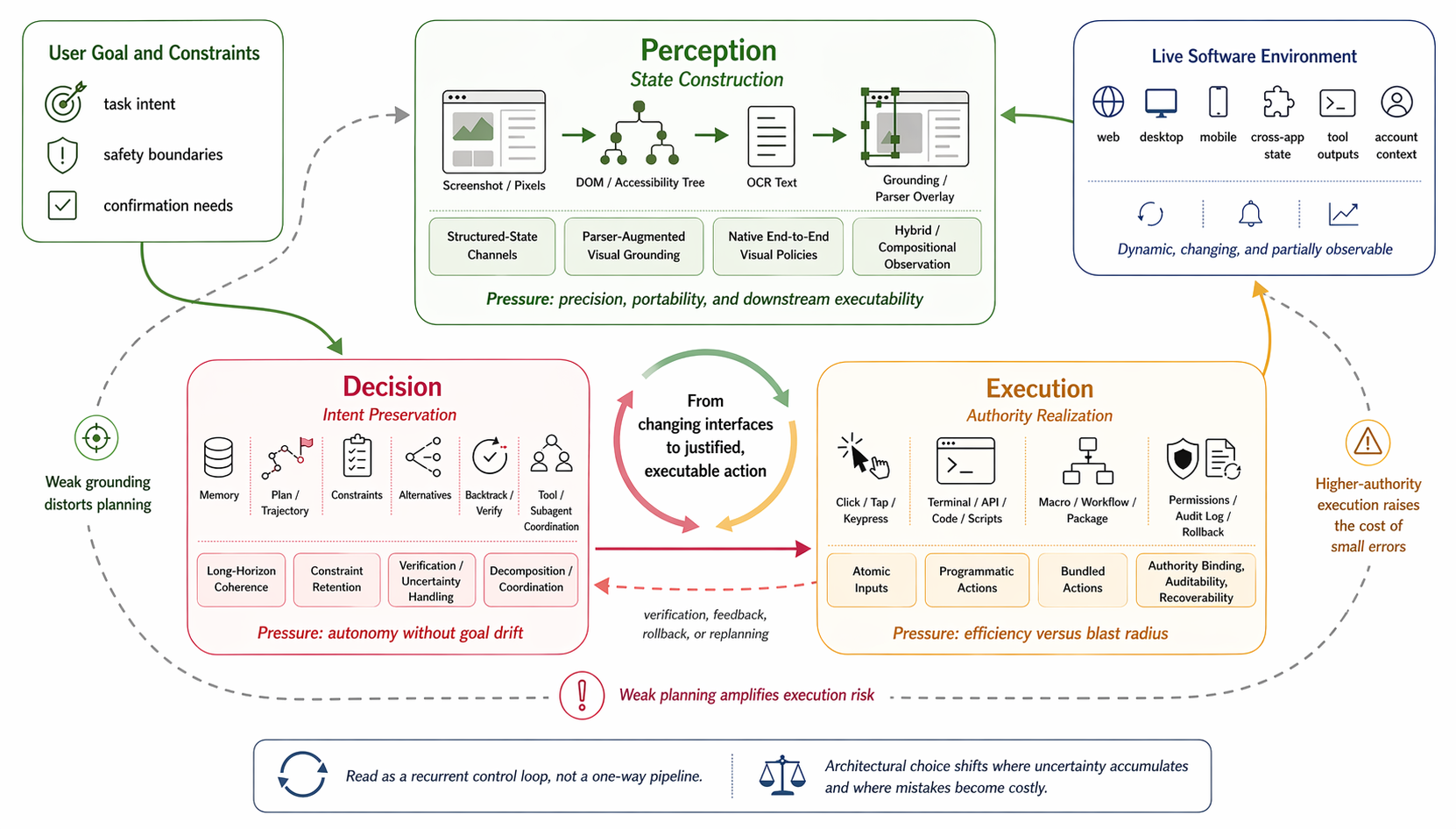
Fig 1: Tri-layer pressure map for deployed CUAs. The figure frames deployed CUA behavior as a recurrent control loop between user goals and constraints
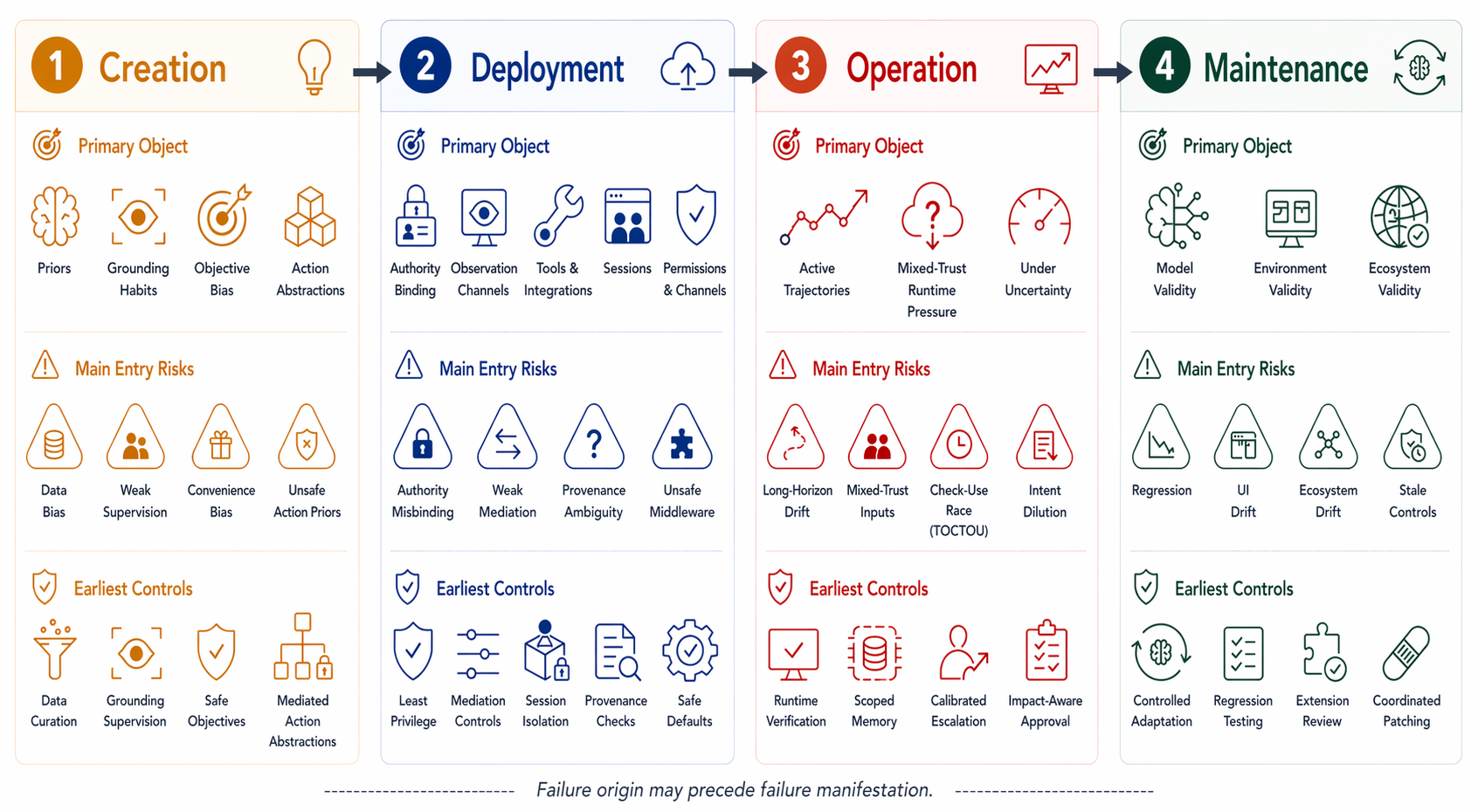
Fig 2: Revised four-stage lifecycle framework for deployed CUAs. Each stage is organized into three aligned bands: the primary object shaped at that stage,
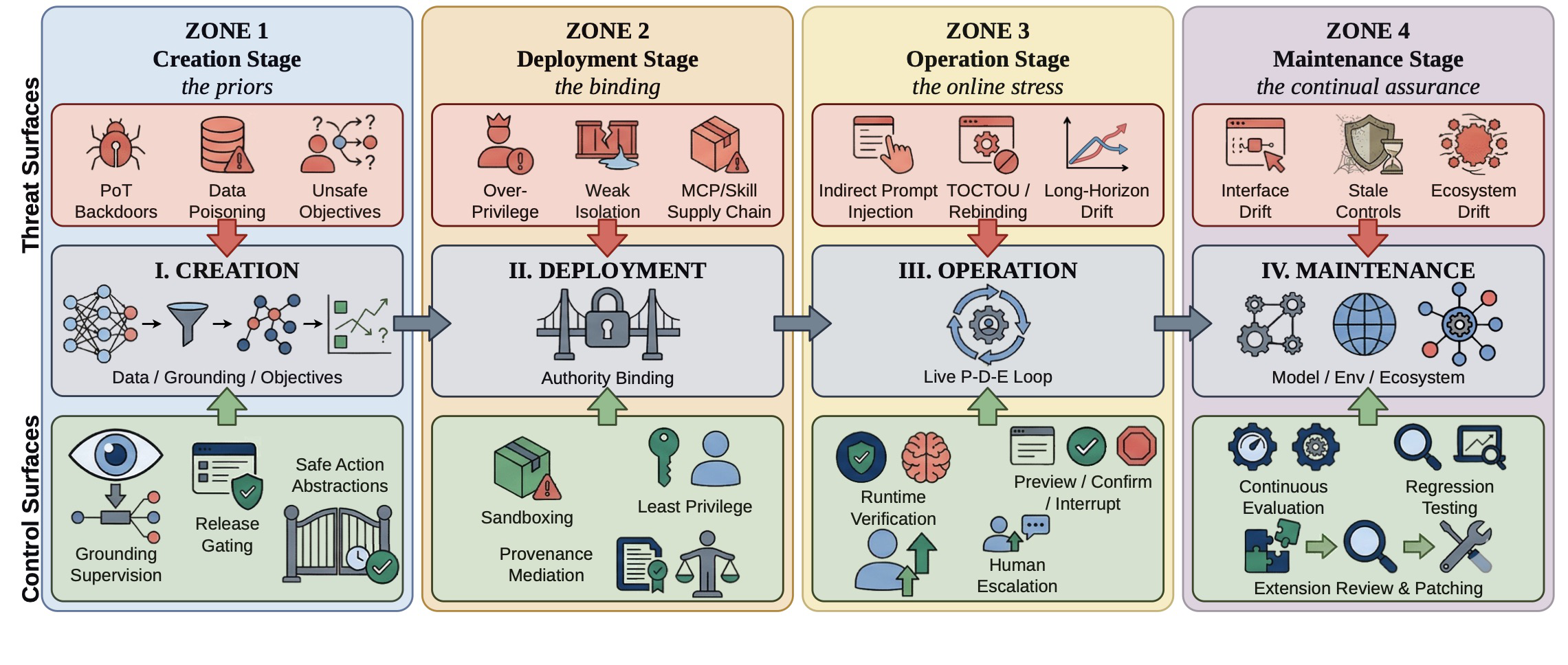
Fig 3: Lifecycle-aligned CUA threats and controls. The figure serves as an intervention map: for each stage, it identifies the salient threat surfaces, the system
Limitations
- No empirical validation: the framework is entirely organizational and diagnostic; no experiments test whether applying it actually reduces failure rates, improves security posture, or helps practitioners identify failure origins more accurately than alternative approaches.
- The assignment rule (assign to the earliest stage of introduction) requires access to system internals, training data provenance, and deployment configuration that practitioners often cannot observe — making the framework descriptively appealing but operationally difficult to apply to black-box deployed CUAs.
- OpenClaw is used as a motivating example but the authors explicitly disclaim verified internal knowledge of it; the 'open deployment pattern' illustration therefore rests on public framing rather than ground truth, limiting its value as a concrete case study.
- Coverage is weighted toward recent CUA work and may underrepresent older agent-security literature, formal verification approaches, and non-English-language interface environments that are increasingly relevant for global deployments.
- The tri-layer decomposition (Perception, Decision, Execution) is acknowledged as heuristic — many deployed systems mix all three simultaneously within a single module (e.g., end-to-end VLM policies), and the layer boundaries become analytically fuzzy precisely in the systems of greatest current interest.
- No statistical or adversarial evaluation of the framework itself: there is no held-out set of real CUA incidents tested against the coordinate system to validate that it correctly identifies enabling conditions, and no adversarial stress test of whether the framework's control recommendations are sufficient against adaptive attackers.
Open questions / follow-ons
- How can controllable grounding be achieved such that a CUA's state representation remains verifiably trustworthy for downstream execution, not just accurate on benchmark recognition metrics — especially under observation-channel mismatch between training and deployment?
- What mechanisms can preserve long-horizon constraints across multi-step, multi-surface tasks without requiring exhaustive runtime verification of every intermediate action, particularly under asynchronous and partially observable software environments?
- How should authority binding be designed so that permission scope is dynamically minimized relative to the current task subtask rather than statically set at deployment — and how can that dynamic scoping remain auditable and reversible?
- What continual assurance protocols are sufficient to detect and respond to post-release drift (UI changes, tool updates, ecosystem evolution) without requiring full retraining, and how should regression testing be structured when the threat model itself may have changed?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper's most directly applicable contribution is the mixed-trust observation framing and the lifecycle origin-vs-manifestation distinction. Modern automated agents that attempt to solve CAPTCHAs or evade bot detection are precisely the class of systems this paper analyzes: they combine visual grounding (perception), multi-step planning (decision), and GUI/API execution with varying authority. The framework's insight that the same model can present very different risk profiles depending on how it is deployed — what tools it has access to, what permissions are bound, what memory it retains — is immediately relevant to bot-defense teams trying to characterize the capability of adversarial agents rather than just detect their current behavior. The distinction between low-level mouse/keyboard automation (detectable via behavioral biometrics) and high-level API/browser-automation invocations (harder to fingerprint) maps directly to existing detection surface taxonomy.
The security threat analysis sections (OS-Harm, WAInjectBench, Risky-Bench, WebPII as reference points) signal that the academic CUA community is now producing structured evaluation frameworks for exactly the capabilities that bot-defense teams face as attack vectors. A bot-defense engineer reading this paper should note two things: first, that grounding robustness benchmarks like ScreenSpot-Pro indicate that professional-grade interfaces still impose meaningful friction on automated agents, which has implications for CAPTCHA design complexity; second, that the paper's open challenges — particularly long-horizon constraint preservation and mixed-trust runtime defense — are effectively the inverse of the bot-defense problem, meaning defenses that force agents into long-horizon, mixed-trust conditions (e.g., multi-page flows with dynamic content) are theoretically well-motivated by the framework's own analysis of where CUA failures cluster.
Cite
@article{arxiv2605_07110,
title={ Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability },
author={ Zejian Chen and Zhanyuan Liu and Chaozhuo Li and Mengxiang Han and Songyang Liu and Litian Zhang and Feng Gao and Yiming Hei and Xi Zhang },
journal={arXiv preprint arXiv:2605.07110},
year={ 2026 },
url={https://arxiv.org/abs/2605.07110}
}