
QUANTAS 2 An Abstract, Concrete and Byzantine Simulator
Source: arXiv:2605.08547 · Published 2026-05-08 · By Mikhail Nesterenko, Joseph Oglio
TL;DR
QUANTAS 2 is a distributed-algorithm simulator aimed at closing a practical gap in the original QUANTAS: it keeps the fast, round-based abstract model but adds a concrete socket-execution mode and a reusable Byzantine fault layer. The paper’s core claim is not that simulation itself is new, but that a single implementation and one JSON experiment description can now be run in both abstract and concrete settings, while adversarial behaviors are injected through composable hooks rather than by rewriting the algorithm under test.
The results are primarily a capabilities demonstration across four domains: proof-of-work blockchains, PBFT/Raft consensus, reliable data links, and DHTs. In the blockchain case, the authors use parasite-chain attacks to show how attack success changes with coalition strength and release thresholds; in consensus, they show PBFT throughput degrading under equivocation and Raft throughput degrading under crashes; in data links, they compare alternating-bit and stabilizing data-link utility under delay/drop/reorder/duplicate faults; and in DHTs they compare abstract vs concrete runtime at scale on Chord and Kademlia. The paper’s main result is that QUANTAS 2 can run the same algorithm/specification across these modes and produce structured, reproducible outputs, with concrete mode enabling distributed execution across machines.
Key findings
- Parasite-chain attacks on the 12-peer blockchain testbed yield only ~5%–6% parasite share at low coalition strength, but exceed 58% at high coalition strength in both Bitcoin and Ethereum variants.
- At medium coalition strength, the Bitcoin variant stays near ~8%–13% parasite share, while the Ethereum/GHOST-style variant rises to roughly ~29%–31% (Figure 3).
- In the PBFT experiment with 19 nodes over 500 rounds and 10 tests per point, throughput drops from 166 committed values at 0 Byzantine replicas to 134 at 6 Byzantine replicas, then rises sharply once the Byzantine count exceeds 7 and PBFT’s fault threshold is broken (Figure 4).
- In the Raft crash experiment with 21 replicas over 800 rounds and 10 tests per point, throughput declines smoothly as crashed replicas increase from 0 to 8, then falls to complete loss of progress at 10 crashed replicas (Figure 5).
- For alternating-bit protocol (2 nodes, 200 rounds, 10 tests per point, timeout fixed at 3 rounds), utility degrades similarly under delay and drop; the authors compress these into six adversity levels L1–L6 (Figure 6, Table 1).
- For stabilizing data link (SDL), message reordering has no observable effect in the single-message-at-a-time setup, duplicate faults reduce utility moderately, and mixed faults are worst overall because they combine loss, duplication, and potential reordering (Figure 7).
- In the DHT benchmark, abstract runtime grows from roughly 4–5 seconds at 128 peers to about 347 seconds for Chord and 362 seconds for Kademlia at 16,384 peers, while concrete mode is reported as significantly faster under the same implementation and workload (Figure 8).
- The paper states that the same peer code and experiment configuration can be used for abstract rounds or concrete socket communication, reducing the need for separate implementations when comparing algorithms or validating deployments.
Threat model
The adversary is a distributed process or coalition of processes that may behave arbitrarily at the node boundary: crash, equivocate, withhold or rewrite messages, ignore receives, or replace local computation. The simulator assumes the attacker cannot break the simulator’s encapsulation except through the provided fault hooks; in other words, faults are injected by the experimenter rather than emerging from an uncontrolled runtime. In the blockchain setting the adversary is a selfish-mining coalition with less than or more than half mining power depending on the sweep; in consensus it is a bounded number of Byzantine or crashed replicas; and in data-link experiments faults are channel perturbations rather than adaptive external attackers.
Methodology — deep read
Threat model and assumptions: the simulator is built for distributed-algorithm researchers, not end-users. The adversary model is intentionally broad at the node boundary: a Byzantine process can crash, equivocate, withhold messages, rewrite messages, ignore receives, or replace local computation entirely. The simulator assumes the algorithm is written in the QUANTAS 2 node interface, and the fault object can intercept unicast, multicast/broadcast send, receive, and local-computation hooks. In the blockchain case, the adversary is a colluding mining coalition; in PBFT it is a set of faulty replicas that equivocate; in Raft it is crash-only; and in data-link tests the “faults” are channel-level loss/reorder/duplicate behaviors rather than malicious nodes. The paper does not define a formal security proof model; it is a systems/simulation paper focused on experimental exploration.
Data and experiment inputs: the paper does not describe a public training set because this is not a learned model. Instead, the “data” are parameterized simulation configurations. Inputs include network topology, node count, message delay discipline (deterministic, uniform random, or Poisson), message-loss probability, computation length, seeds, and algorithm-specific parameters such as PBFT timeouts, blockchain mining rates, parasite release thresholds, and DHT query counts. For the blockchain experiments, the authors simulate simplified Bitcoin and Ethereum on a 12-peer complete graph, with two colluding miners versus ten honest peers. The parasite attack uses publicBlockThreshold = 2 and leadThreshold in {1, 3}, while attacker mining rates are varied across low/medium/high coalition strength settings (2, 4, 6 vs honest rate 1). For PBFT, they use 19 nodes, 500 rounds, and 10 tests per data point; for Raft, 21 replicas, 800 rounds, and 10 tests per point; for ABP/SDL, 2 nodes, 200 rounds, 10 tests per point; for Chord/Kademlia, peer counts from 2^7 to 2^14 and 100 queries per test, with 10 tests per point. The paper mentions structured JSON logs including seeds, host metadata, round-level metrics, and algorithm-specific values, but it does not provide a formal schema in the excerpt.
Architecture and algorithm: QUANTAS 2 retains QUANTAS’s round-based abstraction. Each simulation run consists of repeated receive-compute-send rounds over a network of nodes with unicast channels, and each message is wrapped in a packet that stores source, destination, and delay. The simulator proper has a Simulation Component, Configuration Component, Network Component, Node Network Interface Component, Packet Component, and an abstract user-implemented Node class. Abstract mode simulates channels directly; concrete mode swaps in socket-based interfaces and a process coordinator so the same peer code can run locally or on multiple machines. A thread pool is used so peers’ round computations can execute concurrently. The novelty in Byzantine support is the fault object: rather than contaminating algorithm code, a fault can override send/receive/computation behavior at the peer boundary. The paper gives an explicit equivocation example (Figure 2): the fault partitions multicast targets into two sets, sends the intended message to one half, and a modified message (bit-flipped var) to the other half. The parasite fault similarly models selfish mining by withholding blocks, privately sharing with collaborators, extending the hidden branch, and releasing only when the branch is both sufficiently ahead and the public chain has progressed enough.
Training regime / implementation regime: there is no model training. The implementation is in C++ templates/classes, with JSON experiment descriptions and build/run-time selection of abstract vs concrete mode. The paper does not report compiler flags, optimization settings, random seed counts beyond logging seeds, or runtime thread-affinity settings. It does report hardware for the concrete DHT experiments: 10 VMs, each with 10 CPU cores, Intel Xeon Gold 6340/6240/6242 CPUs, 64 GB RAM, connected by an Aruba 8325 20 Gb Ethernet switch. Experiments generally run multiple tests per data point (10 in most cases), but the paper does not state whether seeds are fixed across abstract/concrete comparisons or whether confidence intervals/statistical tests are used.
Evaluation protocol: the paper evaluates by domain-specific metrics rather than a single universal score. For blockchain, it measures the fraction of parasite blocks in adopted ledgers (Figure 3). For PBFT and Raft, it records final throughput and latency or throughput under varying numbers of faulty/crashed replicas (Figures 4 and 5). For ABP and SDL, it uses message utility defined as successfully delivered messages divided by transmitted messages, expressed as a percentage (Figures 6 and 7), with ABP also summarized into six adversity levels (Table 1). For Chord/Kademlia, it measures physical runtime over abstract and concrete modes (Figure 8). Baselines are not presented as a separate algorithmic benchmark suite; rather, the paper compares variants of the same algorithms under different fault settings and, in DHTs, compares execution modes. A concrete end-to-end example is the PBFT equivocation test: on a 19-node network for 500 rounds, the simulator attaches equivocation faults to a chosen number of replicas. Each faulty replica sends one value to one quorum and a conflicting value to another quorum. The system then measures committed throughput. The reported trend is that throughput degrades modestly up to 6 Byzantine replicas (166 down to 134 committed values), but once the Byzantine count exceeds 7 the fault threshold is exceeded and the protocol is effectively broken, which is reflected in the sharp throughput change and corresponding latency behavior in Figure 4.
Reproducibility and limitations in the source: the paper emphasizes structured JSON output and shared experiment setup between abstract and concrete modes, which helps reproducibility. It also states that experimental data is available to download, but the excerpt does not include a code repository link, frozen commit, or a public artifact description. Reproducibility is therefore partial from the excerpt alone: the design is described clearly, but exact parameter files, datasets, and full source availability are not fully specified here.
Technical innovations
- A dual-mode execution model that runs the same algorithm implementation either as abstract round-based simulation or as concrete socket-based distributed execution.
- A reusable Byzantine-fault interface that intercepts send, receive, and local-computation hooks so adversarial behavior can be composed without modifying the target algorithm.
- A structured experiment/logging pipeline with shared JSON configuration across abstract and concrete runs, designed for parameter sweeps and post-processing.
- Two concrete reusable Byzantine behaviors are implemented out of the box: equivocation for quorum-splitting attacks and parasite mining for selfish proof-of-work behavior.
Baselines vs proposed
- Bitcoin vs Ethereum under low coalition strength: parasite share ≈ 5%–6% for both; under medium coalition strength: Bitcoin ≈ 8%–13% vs Ethereum ≈ 29%–31% (Figure 3).
- PBFT with 0 Byzantine replicas vs 6 Byzantine replicas: committed throughput = 166 vs 134 (Figure 4).
- Raft with 0 crashed replicas vs 8 crashed replicas: throughput declines smoothly; at 10 crashed replicas the system reaches complete loss of progress (Figure 5).
- ABP under increasing adversity levels L1–L6: utility bends sharply downward at L3 after being similar for L1 and L2 (Figure 6).
- SDL under mixed channel faults vs individual non-FIFO faults: mixed faults yield the worst utility; reordering alone has no observable effect (Figure 7).
- Chord abstract vs concrete at 16,384 peers: abstract runtime ≈ 347 s vs concrete mode reported as significantly faster; Kademlia abstract ≈ 362 s vs concrete mode significantly faster (Figure 8).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.08547.
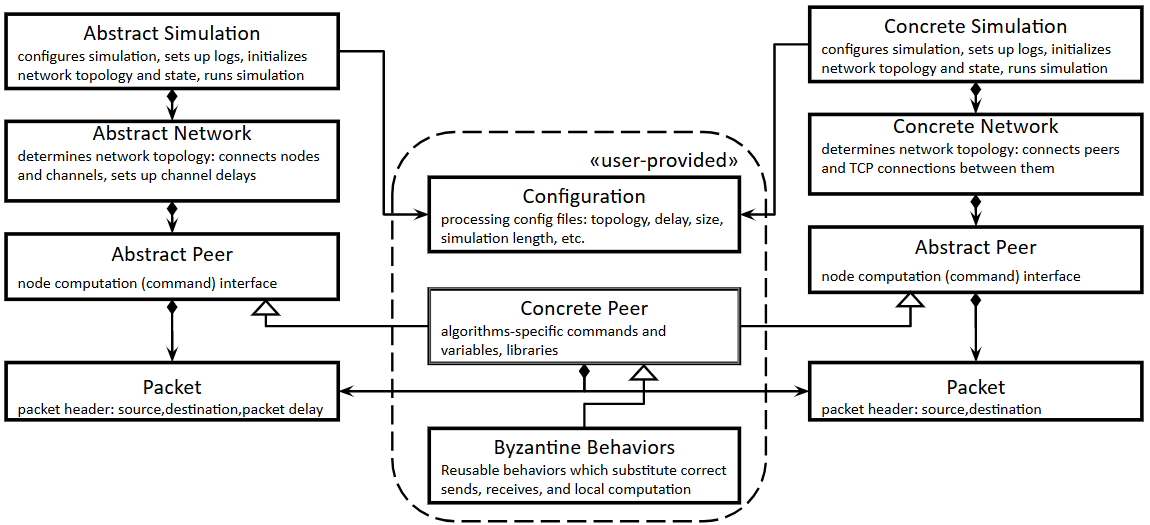
Fig 1: QUANTAS 2 architecture.
Limitations
- No formal security proof or correctness proof is provided for the new Byzantine interface; evaluation is empirical and illustrative.
- The paper does not report confidence intervals, statistical significance tests, or variance bars for the plotted results in the excerpt.
- The benchmark suite is small and domain-specific: one simplified blockchain pair, one consensus pair, one DHT pair, and one data-link pair.
- The blockchain experiments use simplified Bitcoin/Ethereum models on a 12-peer complete graph, so the results may not transfer directly to realistic public-network topologies.
- The excerpt does not fully specify public code availability, exact experiment files, or a frozen artifact, even though it mentions downloadable experimental data.
- Concrete-mode speedups are asserted qualitatively in the excerpt, but the underlying cause of the speedup and the exact abstract-vs-concrete runtime numbers for each point are not fully enumerated in text.
Open questions / follow-ons
- How expressive is the fault-hook interface for adaptive, stateful adversaries that react to observations over many rounds, beyond the two reusable faults shown here?
- Can QUANTAS 2 be coupled with automated adversary search methods to find worst-case schedules that maximize latency or safety violations, as the authors suggest?
- How faithfully do abstract and concrete modes preserve behavior under timing-sensitive algorithms when network delay, OS scheduling, and multi-host deployment interact?
- Can the simulator support dynamic topology changes, mobility, or mid-run reconfiguration without breaking the shared-configuration model?
Why it matters for bot defense
For a bot-defense engineer, the main takeaway is methodological: QUANTAS 2 shows how to separate algorithm logic from execution environment while still testing adversarial behavior under controlled perturbations. That maps well to CAPTCHA and bot-defense systems where you often want to compare an abstract policy, a concrete deployment, and a set of attacker behaviors without rewriting the core evaluator each time.
More concretely, the reusable fault-hook idea is relevant to simulating coordinated bots, partial message manipulation, and selective withholding/release patterns. Even though the paper is not about CAPTCHA, the evaluation style is useful: keep the policy fixed, vary attacker strength, delay, dropout, and topology, and measure outcome metrics under identical experiment descriptions. The main caveat is that the paper does not provide an adversarial learning loop or a realistic human/bot interaction model, so it is more useful as a simulation harness pattern than as a direct CAPTCHA attack model.
Cite
@article{arxiv2605_08547,
title={ QUANTAS 2 An Abstract, Concrete and Byzantine Simulator },
author={ Mikhail Nesterenko and Joseph Oglio },
journal={arXiv preprint arXiv:2605.08547},
year={ 2026 },
url={https://arxiv.org/abs/2605.08547}
}