
Globally Optimal Training of Spiking Neural Networks via Parameter Reconstruction
Source: arXiv:2605.08022 · Published 2026-05-08 · By Himanshu Udupi, Xiaocong Yang, ChengXiang Zhai
TL;DR
This paper tackles the core training bottleneck of Spiking Neural Networks (SNNs): the non-differentiability of the spike (Heaviside) function forces practitioners to use surrogate gradients, which introduce forward-backward mismatch errors that accumulate layer-by-layer and get worse with depth. The authors' response is not to improve the surrogate but to bypass it entirely via convex reformulation. They extend an existing theoretical framework for parallel feedforward threshold networks (Ergen et al., 2023, ref [11]) to the recurrent case — parallel recurrent threshold networks — and then prove that Leaky-Integrate-and-Fire (LIF) SNNs are a structured special case of this recurrent family. The key theoretical result is a zero-duality-gap (strong duality) theorem showing that the globally optimal solution to the non-convex path-regularized SNN training problem can be recovered by solving a strictly convex bi-dual problem over a finite 'spike dictionary' of all realizable binary activation patterns.
The practical algorithm, called parameter reconstruction, works in two stages. First, 'witnesses' (hidden-layer weight configurations) are generated either by random Gaussian sampling (CVX variant) or by transferring weights from a surrogate-gradient-pretrained SNN (SG-CVX variant). These witnesses define a finite spike dictionary — the set of distinct binary activation patterns the final hidden layer can produce at the last timestep. Second, a convex LASSO-type program is solved over this dictionary to find globally optimal output-layer coefficients. The primal-dual gap is verified empirically to be below 1e-6, confirming that the convex solve is indeed globally optimal with respect to the sampled dictionary.
Experiments across arithmetic addition (bases 2, 3, 5), FIRST-LAST-XOR, and sequential MNIST (MNIST-SEQ) consistently show CVX-variant methods outperforming surrogate-gradient baselines, with the gap widening dramatically at greater depth (L=10) and larger training sets. The SG-CVX hybrid, which uses surrogate-gradient pretraining only to generate better witnesses before the convex solve, achieves the strongest out-of-distribution (OOD) generalization, maintaining accuracy even at sequence lengths 10x beyond training. Ablations reveal a performance ceiling in pure surrogate-gradient training that persists regardless of data volume, whereas CVX accuracy improves monotonically with more training samples.
Key findings
- Convex solve achieves primal-dual gap < 1e-6 across all tested K values (K=2,16,32,64) on FIRST-LAST-XOR (Table 1), empirically verifying global optimality of the parameter reconstruction over the sampled spike dictionary.
- At depth L=10 and timestep T=6 on FIRST-LAST-XOR, CVX reaches 0.973 test accuracy while SG collapses to near-chance at 0.501 (Table 2), a 47.2 percentage-point gap.
- On MNIST-SEQ at L=10, CVX achieves 0.271 accuracy vs. SG at 0.099 — SG collapses to chance while CVX retains nontrivial signal (Table 2).
- For OOD generalization on base-3 arithmetic addition at 10x training sequence length, SG-CVX achieves 0.310 token-wise accuracy vs. SG's 0.177 and CVX's 0.234 (Table 3), with SG-CVX being the only method that does not degrade monotonically with OOD length.
- CVX displays positive data scaling: on base-2 addition (L=3, T=6), sequential accuracy improves from 0.571 at 512 training samples to 0.730 at 4096 samples; SG shows no such trend, hovering between 0.152–0.184 across all dataset sizes (Table 6).
- Depth degradation is substantially milder for CVX: on FIRST-LAST-XOR (T=6), CVX drops from 1.000 at L=3 to 0.841 at L=15, while SG drops from 0.746 at L=3 to 0.504 at L=15 (Table 4a).
- Timestep robustness: CVX maintains consistent advantage over SG at all tested T values on FIRST-LAST-XOR (T=6,8,11,14), and on MNIST-SEQ (T=14,28,56), with the CVX-SG gap widening to 0.134 at T=56 (Tables 4b, 5b).
- SG-CVX outperforms CVX on OOD tasks (Table 3), suggesting surrogate-gradient pretraining produces qualitatively better witnesses (likely via more stable, low-frequency boolean features) even when its direct training result is suboptimal.
Methodology — deep read
THREAT MODEL AND ASSUMPTIONS: This is not a security paper; the 'adversary' here is the optimization landscape itself. The core assumption is that LIF-SNN training can be cast as a path-regularized empirical risk minimization problem where the loss is convex in the output layer. The theoretical machinery requires the network to be a K-parallel architecture (K independent subnetworks sharing input but with disjoint hidden parameters), uses a threshold (Heaviside) activation, and fixes a finite timestep T. The LIF recurrence must follow the specific leak-reset block form U_t = S_{t-1} P_in + (U_{t-1}; S_{t-1}) * (beta; -U_thr), which excludes gated variants. The reset threshold U_thr is assumed trainable. The path regularizer is an L2 norm over scale-bearing edges only (inputs and reset weights), not leak coefficients, since leak coefficients are invariant under the scaling operation (Lemma 3.5).
THEORETICAL PIPELINE — FROM NON-CONVEX TO CONVEX: The authors build on the convexification line of work (Ergen & Pilanci 2021–2025). Step 1: They show a K-parallel recurrent threshold network with fixed timestep T can be unrolled into a DAG with tied weights, then apply joint normalization of feedforward and recurrent incoming weight blocks per hidden neuron (sum of p-norms = 1). This preserves network outputs by positive scaling invariance of threshold activations. Step 2: Under this normalization, the path regularizer reduces to just the L_p norm of output weights (Theorem 3.1 applied to the unrolled DAG). Step 3: They construct the Lagrangian dual of the resulting primal problem and prove zero-duality gap (strong duality) using Slater's condition at lambda=0, giving Theorem 3.3. Step 4: For LIF-SNNs specifically, they define an LIF-specific path regularizer that excludes leak edges (since beta_l < 1 causes path product decay that would harm regularization), restricted to scale-bearing edges (P_in and U_thr). Lemma 3.5 shows diagonal A_l scaling leaves beta unchanged, so the normalization condition becomes ||P_l,in[:,i]||p^p + ||U_thr,i||p = 1, and the path regularizer again reduces to the output norm. Step 5: Theorem 3.6 gives the finite convex program: a LASSO over the spike dictionary D^{L-1,T} in {0,1}^{n x P}, minimizing L(D*w_tilde, Y) + (beta/sqrt(m)) * ||w_tilde||_1. By Caratheodory's theorem, the optimal w_tilde* has at most n+1 nonzero entries for scalar output (ndout+1 for vector output).
SPIKE DICTIONARY CONSTRUCTION (WITNESS GENERATION): The spike dictionary enumerates all distinct binary activation patterns at the final hidden layer at the final timestep across all n training samples. Exhaustive enumeration is combinatorially intractable (complexity derived in Appendix D.6, not reproduced in the main text). The practical solution is to use a finite sampled dictionary: (a) CVX: sample all non-output-layer parameters from a Gaussian distribution, run forward passes on training data to collect the resulting binary activation patterns — this defines the dictionary. (b) SG-CVX: take a converged surrogate-gradient-trained SNN, use its learned weights as the witnesses. In both cases, the convex LASSO program is then solved over this finite dictionary. The paper notes this is globally optimal over the sampled dictionary, not over the complete intractable dictionary. The number of subnetworks K determines the capacity, and the Caratheodory argument guarantees K* <= n+1 subnetworks suffice for scalar output.
DATA: Three task families. (1) Arithmetic addition: two n-digit base-b operands (b=2,3,5), input space grows as b^{2n}. Training uses n=5 digits; OOD evaluation uses 2x, 5x, 10x longer sequences. Token-wise accuracy and sequential (fully correct sequence) accuracy are both reported. Training set size varies from 512 to 7680 in the data-scaling ablation (Table 6). (2) FIRST-LAST-XOR: a synthetic binary classification task with fixed binary input distribution, used as a controlled ablation benchmark because its input statistics don't change with L or T. (3) MNIST-SEQ: standard MNIST digits streamed as sequential pixel patches (T controls how many patches per image). Dataset sizes and exact train/val/test splits are not explicitly stated in the provided text. Labels are integer classes / digit tokens. No explicit mention of data augmentation or special preprocessing beyond the sequential streaming for MNIST-SEQ.
TRAINING REGIME AND EVALUATION: For surrogate-gradient baselines (SG), standard backprop with sigmoid surrogate for the Heaviside is used. SG-SG continues surrogate-gradient training from an SG checkpoint. CVX and SG-CVX solve the LASSO convex program after witness generation. Specific hyperparameters (learning rate, batch size, epochs, optimizer for SG, regularization beta, LASSO solver) are deferred to Appendix E which is not included in the provided text. Hardware: NCSA Delta GPU cluster (NSF ACCESS allocation CIS251094). No mention of random seeds or seed averaging strategy in the provided text — it is unclear whether results are averaged over multiple runs or single runs. Metrics: test accuracy (token-wise for addition, standard for classification tasks). The primal-dual gap is used as a proxy to verify optimality (Table 1). No statistical significance tests (e.g., t-tests, confidence intervals) are reported. Ablations cover: number of subnetworks K (Table 1), depth L (Tables 4a, 5a), timestep T (Tables 4b, 5b), training set size (Table 6), and task type.
CONCRETE END-TO-END EXAMPLE (CVX on FIRST-LAST-XOR, L=3, T=6, K=64): Training samples X_{1:6} are fed through randomly initialized LIF-SNN hidden layers (L=2 hidden layers, weights sampled from Gaussian). At each timestep t=1..6, the membrane potentials U^t_l are computed via the LIF recurrence and thresholded to produce binary spike patterns S^t_l. The final hidden layer's spike pattern at t=6, S^6_{L-1} in {0,1}^{n x m_{L-1}}, is collected for all n training points. Distinct columns form the dictionary D. The convex LASSO min_{w} L(Dw, Y) + lambda||w||_1 is solved (solver not named in provided text). The resulting w* has at most n+1 nonzero entries; each nonzero entry corresponds to a dictionary atom (spike pattern) and is assigned to one subnetwork as its effective output weight. Test accuracy 86.43% is reported at K=64 (Table 1), with primal-dual gap 2.65e-7.
REPRODUCIBILITY: Code is not mentioned as released. Weights are not mentioned as publicly available. The MNIST dataset is public; the arithmetic and XOR datasets appear to be synthetically generated but no generation script release is mentioned. Appendix E contains algorithmic details not available in the provided truncated text.
Technical innovations
- Extension of the zero-duality-gap (strong duality) result from parallel feedforward threshold networks (Ergen et al. [11]) to parallel recurrent threshold networks via joint normalization of feedforward and recurrent incoming weight blocks on the unrolled DAG, yielding Theorem 3.3.
- Proof that LIF-SNNs are a structured special case of parallel recurrent threshold networks, requiring a novel LIF-specific path regularizer that excludes leak-coefficient edges (which are invariant under positive scaling and cause product decay), enabling Theorem 3.6.
- A practical two-stage parameter reconstruction algorithm that (a) generates a finite spike dictionary via Gaussian-sampled or surrogate-gradient-pretrained witnesses, then (b) solves a finite convex LASSO over this dictionary for globally optimal output coefficients, bypassing surrogate gradient approximation entirely.
- Empirical demonstration that surrogate-gradient pretraining serves as a high-quality witness generator for the convex stage (SG-CVX), combining the representation-learning strength of gradient training with the global optimality guarantee of convex reconstruction — a complementary rather than competing relationship.
Datasets
- ADDITION (Base-2, Base-3, Base-5) — synthetically generated arithmetic sequences, n=5 digits, training sizes 512–7680 in ablations — generated by authors
- FIRST-LAST-XOR — synthetic binary classification with fixed binary input distribution — generated by authors
- MNIST-SEQ — 70,000 images streamed as sequential pixel patches — derived from standard MNIST (LeCun et al., public)
Baselines vs proposed
- SG (surrogate gradient): FIRST-LAST-XOR L=3 T=6 test accuracy = 0.746 vs CVX: 1.000
- SG (surrogate gradient): FIRST-LAST-XOR L=10 T=6 test accuracy = 0.501 vs CVX: 0.973
- SG (surrogate gradient): MNIST-SEQ L=10 T=2 test accuracy = 0.099 vs CVX: 0.271
- SG (surrogate gradient): ADDITIONBase-2 L=3 T=6 token-wise accuracy = 0.738 vs CVX: 0.954
- SG (surrogate gradient): ADDITIONBase-3 L=3 T=6 token-wise accuracy = 0.212 vs CVX (best variant): 0.363
- SG-SG (continued SG training): base-3 OOD-10x token-wise accuracy = 0.202 vs SG-CVX: 0.310
- SG (surrogate gradient): base-2 addition sequential accuracy at 4096 training samples = 0.163 vs CVX: 0.730
- SG (surrogate gradient): MNIST-SEQ L=3 T=56 accuracy = 0.687 vs CVX: 0.821
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.08022.
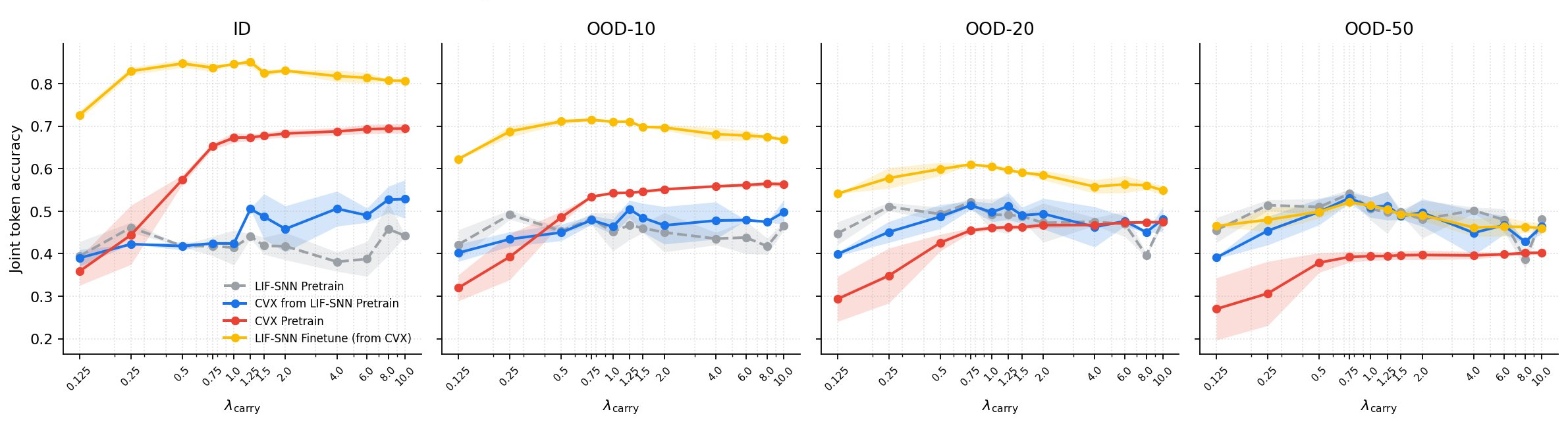
Fig 1: Base-2 addition: effect of λcarry on autoregressive joint-token accuracy for ID and OOD
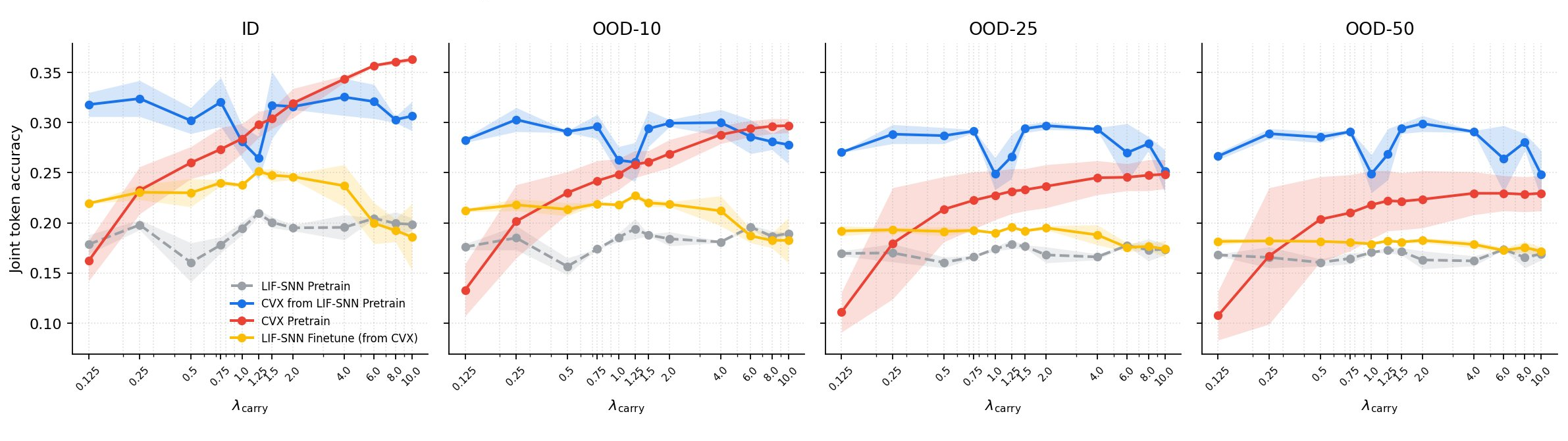
Fig 2: Base-3 addition: effect of λcarry on autoregressive joint-token accuracy for ID and OOD
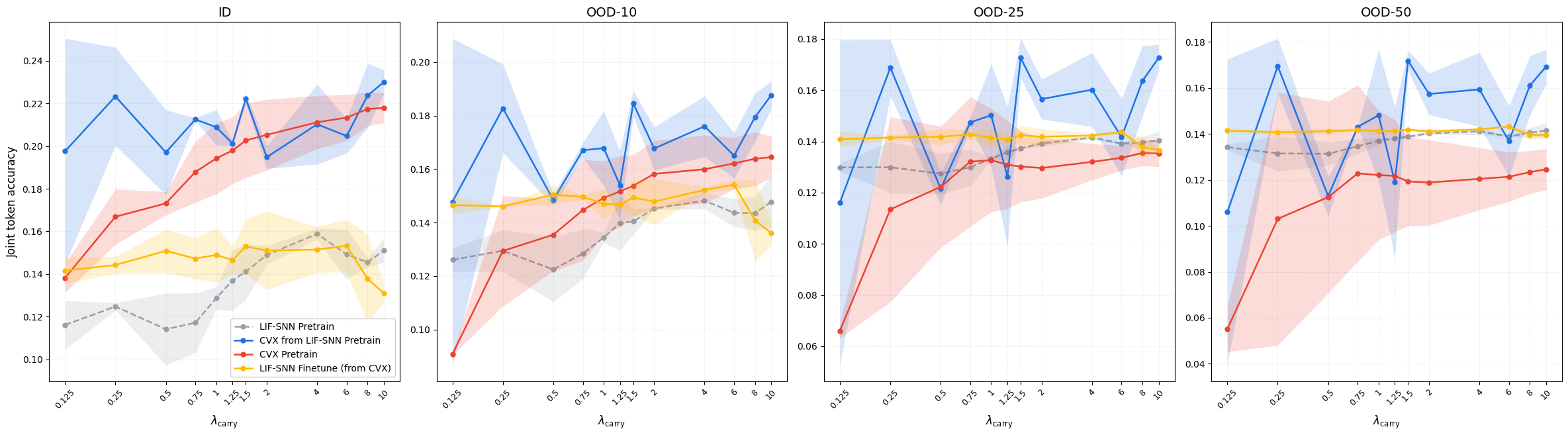
Fig 3: Base-5 addition: effect of λcarry on autoregressive joint-token accuracy for ID and OOD
Limitations
- Benchmark scope is narrow: only arithmetic addition, FIRST-LAST-XOR, and sequential MNIST are tested; no evaluation on speech processing (e.g., SHD, SSC), event-based vision (N-MNIST, DVS-CIFAR10), or neuromorphic benchmarks where SNNs are most practically relevant.
- Architectural scope is restricted to LIF-SNNs with the specific block recurrent structure P_rec = [betaI; -U_thrI]; gated SNNs (LSTM-style spiking variants), attention-augmented SNNs, and convolutional SNN variants are explicitly excluded.
- The global optimality guarantee applies only to the sampled spike dictionary (fixed witnesses), not to the complete exponentially large dictionary; the quality of the solution is therefore bounded by witness quality, and the gap between sampled-dictionary optimum and true global optimum is not quantified.
- No statistical rigor: results appear to be single-run point estimates with no confidence intervals, standard deviations, or significance tests across multiple random seeds, making it difficult to assess whether observed gaps are reliable or due to random variation in witness sampling.
- Computational scalability is not demonstrated: the spike dictionary size grows combinatorially with hidden width and timesteps, and the paper acknowledges exhaustive enumeration is intractable but does not report wall-clock times, memory costs, or scaling curves comparing CVX to SG training cost.
- The mechanism behind SG-CVX's OOD superiority (hypothesized as spectral simplicity of pretrained witnesses inducing low-frequency Fourier-Walsh structure) is stated speculatively with no supporting evidence or ablation; it is explicitly left as future work.
- No evaluation of energy efficiency, which is a primary motivation for SNNs; the paper does not report inference spike rates, synaptic operations, or hardware energy estimates that would validate the energy-efficiency claim in practical settings.
Open questions / follow-ons
- Can the approach scale to larger SNN architectures (deeper, wider, convolutional) and more complex benchmarks like SHD speech or event-based vision, where the spike dictionary would be vastly larger and witness quality more critical?
- Can a spectral generalization bound be proved that formally connects the low-frequency Fourier-Walsh structure of surrogate-gradient-pretrained witnesses to the OOD generalization advantage observed in SG-CVX, as the authors suggest?
- Is there an adaptive or iterative witness refinement strategy (analogous to column generation in linear programming) that could approach the true global optimum of the complete spike dictionary without exhaustive enumeration?
- Does the zero-duality-gap result extend to gated or attention-augmented SNN architectures, or to SNNs with non-diagonal recurrent structure, and if not, what is the tightest achievable duality gap in those settings?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper is relevant primarily as a signal about the maturity trajectory of SNN-based behavioral models rather than as a direct deployable technique. SNNs have been proposed as temporal behavioral feature extractors (e.g., modeling mouse movement or keystroke dynamics as spike trains) due to their native handling of asynchronous event streams. The persistent failure of surrogate-gradient training to scale with depth and data has been a practical barrier to deploying SNNs in production behavioral analysis pipelines. This paper's demonstration that CVX training shows positive data scaling (unlike SG, which plateaus) and more graceful depth degradation is a meaningful signal that SNN training may become viable at scales relevant to production bot detection, where behavioral feature extractors must handle long interaction sequences and benefit from large labeled datasets.
More immediately actionable is the SG-CVX paradigm as a post-training optimization step: if a team already has a surrogate-gradient-trained SNN behavioral model, replacing or augmenting the final readout layer via the convex reconstruction step could improve in-distribution accuracy and OOD robustness at low additional cost (only a convex solve over the existing model's spike dictionary is required). The OOD length generalization results are particularly relevant to bot defense, where bot behavior often manifests at interaction lengths outside the training distribution (very short sessions from simple bots, very long sessions from sophisticated crawlers). The caveat is that all results are on clean synthetic and semi-synthetic tasks; there is no evaluation on noisy real-world behavioral data, adversarial inputs, or distribution shift scenarios that are endemic to bot detection, so significant empirical validation would be needed before adoption.
Cite
@article{arxiv2605_08022,
title={ Globally Optimal Training of Spiking Neural Networks via Parameter Reconstruction },
author={ Himanshu Udupi and Xiaocong Yang and ChengXiang Zhai },
journal={arXiv preprint arXiv:2605.08022},
year={ 2026 },
url={https://arxiv.org/abs/2605.08022}
}