
CA-SQL: Complexity-Aware Inference Time Reasoning for Text-to-SQL via Exploration and Compute Budget Allocation
Source: arXiv:2605.08057 · Published 2026-05-08 · By James Petullo, Nianwen Xue
TL;DR
CA-SQL addresses a specific and well-characterized failure mode in LLM-based Text-to-SQL pipelines: on the hardest queries in the BIRD benchmark, existing inference-time methods fail not because their refinement steps are poor, but because their initial candidate pools lack diversity. When every candidate is generated from the same schema subset seed, increasing sampling count yields diminishing returns on unique queries, so the correct SQL formulation may never appear in the pool at all. The authors argue this is a breadth-of-exploration problem, not a depth-of-refinement problem, and that prior work (including MCTS-based approaches) conflates the two.
CA-SQL introduces three interlocking mechanisms to fix this: (1) a difficulty scorer that maps each incoming NL question to a 1–5 integer complexity score, which then controls how many parallel exploration rounds and refinement steps are allocated; (2) a schema subset seeding strategy that generates multiple distinct table-column subsets per question and expands them via evolutionary crossover and mutation operators rather than repeated LLM sampling; and (3) a sum-of-rewards voting mechanism that aggregates critic scores, confidence weights, and mutation temperatures across all candidate queries to select the final output, rather than using majority voting or LLM-as-a-judge.
The system achieves 51.72% execution accuracy on the 'challenging' tier of BIRD's development set using only GPT-4o-mini, outperforming all reported in-context learning baselines on that tier including those using GPT-4o and GPT-4 (the next best ICL result on challenging with GPT-4o was 51.48% via MCTS). Overall BIRD dev set EX is 61.06% and Soft F1 is 68.77%, which is competitive but not SOTA across all tiers — the method trades some simple/moderate accuracy for substantially better challenging-tier coverage.
Key findings
- CA-SQL achieves 51.72% execution accuracy on the BIRD development set 'challenging' tier using GPT-4o-mini, a 0.24% improvement over the best GPT-4o-based ICL method (MCTS + GPT-4o at 51.48%) and a 5.89% improvement over the best prior GPT-4o-mini ICL method (MCTS + GPT-4o-mini at 45.83%).
- Overall BIRD development set scores are 61.06% EX and 68.77% Soft F1 for CA-SQL + GPT-4o-mini, compared to MCTS + GPT-4o at 69.4% EX and E-SQL + GPT-4o at 67.93% Soft F1 — the method is competitive but not overall SOTA.
- CA-SQL underperforms on simple tasks relative to SOTA: 66.93% EX vs. MCTS + GPT-4o at 74.32% and E-SQL + GPT-4o at 73.02%, suggesting the breadth-focused approach introduces noise or over-exploration penalty on trivially solvable queries.
- Query pools generated from multiple distinct schema subset seeds yield measurably greater candidate uniqueness than pools generated from a single schema subset at equivalent sample counts (Section 4.6 experiment on random BIRD samples; specific uniqueness delta not reported numerically in the truncated text).
- Sum-of-rewards voting (R = s * (1 - t) * k) outperforms majority voting and other self-consistency methods tested in ablation (Section A.1); specific delta over majority voting not quoted in the main text but referenced as ablation result.
- The difficulty scorer uses a single LLM sample to assign complexity 1–5; the authors themselves flag that score variance across repeated samples is uncharacterized and may be high, which is a known limitation they leave for future work.
- All five LLM roles (schema subset generator, query generator, critic, mutator, difficulty scorer) use GPT-4o-mini exclusively; schema subset generator, query generator, mutator, and difficulty scorer run at temperature 1.0 while the critic runs at temperature 0.2.
Threat model
n/a — this is a Text-to-SQL systems paper, not a security paper. The adversarial framing, if any, is the benchmark itself: BIRD's 'challenging' queries are designed to require complex joins, aggregations, and schema reasoning that stress-test SQL generation pipelines. The paper does not model a human adversary attempting to subvert the system.
Methodology — deep read
The threat model here is not adversarial in a security sense — the 'adversary' is the difficulty of SQL query space coverage. The core assumption is that Text-to-SQL failures on hard queries stem from insufficient candidate diversity at generation time, not from inadequate per-candidate refinement depth. The pipeline assumes access to a full database schema, a natural language question, and an evidence/usage hint H, and that the gold query is never revealed to the pipeline during inference.
Data: CA-SQL is evaluated exclusively on the BIRD (BIg Bench for Large-Scale Database Grounded Text-to-SQL) benchmark's development set. BIRD contains 1,534 NL-SQL pairs across 95 databases spanning 37 real-world domains. The databases are described as large, anonymized, and frequently noisy. The benchmark partitions problems into three difficulty tiers: simple, moderate, and challenging. No training or fine-tuning is performed — all learning is in-context. No held-out adversarial split or distribution shift test is reported.
Architecture and algorithm — five components in sequence: (1) Difficulty Scoring: LLMdifficulty(Q, S, H) → integer C ∈ [1, 5]. A single LLM call with a prompt instructing the model to output an integer complexity rating. This score directly gates downstream compute allocation. The number of parallel refinement rounds equals C and the maximum refinement depth per candidate is floor(C/2) + 1. (2) Schema Subset Pool Generation: LLMschema_subset is sampled up to N=20 times to produce distinct subsets S'_i ⊆ S. Each subset contains only tables and columns deemed relevant to Q. All subsets are stored in a pool P, and their union (superset) is also added. This contrasts with prior work (MCS-SQL, E-SQL, CHASE-SQL) that uses a single merged or single-sampled schema subset for all candidates. (3) Evolutionary Subset Expansion: In subsequent exploration rounds (iterations 2 through C), instead of re-sampling from LLMschema_subset, new subsets are generated via crossover (merging two subsets, probability p=0.50) or mutation (randomly dropping table-column pairs from one subset until a novel combination is reached, probability 1-p=0.50). This avoids repeated expensive LLM calls for schema linking while increasing combinatorial coverage. (4) Candidate Query Generation and Critique: For each subset S'_i, LLMgen_query(Q, S'_i) → candidate query QC (temp=1.0). QC is executed against the database; error-raising queries are discarded. Surviving queries are passed to LLMcritic(Q, S'_i, H, QC, O) → (score s, confidence k, mutation temperature t, assessment A). The critic runs at temp=0.2 for stability. The reward is R = s * (1-t) * k. LLMmutate(Q, S'_i, QC, H, A, t) → QC' refines the query. All (QC, R, O) tuples are accumulated in buffer B across all C iteration rounds. (5) Final Answer Selection via Sum-of-Rewards: Outputs O are grouped; the output O* with the highest summed reward across all buffer entries sharing that output is selected, and its associated query is returned. This aggregates evidence across multiple independently-generated candidates that happen to produce the same database output.
Training regime: There is no training. All LLMs are GPT-4o-mini accessed via API. No seeds, epochs, or gradient steps are involved. Hyperparameters are: N_max schema subset samples = 20, crossover probability p = 0.50, LLM temperatures per role as in Table 2.
Evaluation protocol: Two metrics — Execution Accuracy (EX: fraction of queries producing identical output to gold) and Soft F1 (partial credit for minor output discrepancies like column ordering). Results are broken down by BIRD difficulty tier (simple/moderate/challenging) and overall. Baselines include MCS + GPT-4, E-SQL + GPT-4o-mini, E-SQL + GPT-4o, MCTS + GPT-4o-mini, MCTS + GPT-4o — all in-context learning methods. Ablations (Appendix A.1) test voting strategies (majority vs sum-of-rewards vs others). Section 4.6 ablates query uniqueness with single vs multi-seed schema subsets on a random BIRD sample. No statistical significance tests (e.g., bootstrap confidence intervals) are reported. No cross-validation is used — the development set is evaluated as a whole.
Concrete end-to-end example: Given a challenging BIRD question like 'What is the average salary of employees in departments with more than 5 projects in 2022?', LLMdifficulty assigns C=4. LLMschema_subset is called up to 20 times, yielding e.g. 8 distinct subsets varying in which foreign-key columns and junction tables are included. Their union is added as a 9th seed. In round 1 of 4, each of 9 seeds generates a candidate query via LLMgen_query at temp=1.0. Each surviving query is critiqued; suppose QC_3 gets s=0.7, k=0.8, t=0.3, yielding R=0.7*(0.7)*0.8=0.392. LLMmutate rewrites it. Rounds 2–4 use crossover/mutation to generate new schema subsets without re-calling LLMschema_subset. After 4 rounds, buffer B contains ~36 (QC, R, O) tuples. The output O that appears most rewardingly across candidates is selected. Note: exact numerical trace is illustrative based on the paper's formalism; the paper does not provide a worked example.
Technical innovations
- Complexity-gated compute allocation: a single LLM difficulty score C ∈ [1,5] is used to set both the number of exploration rounds and maximum refinement depth (floor(C/2)+1) per candidate, replacing the fixed-budget approach used by all prior BIRD ICL baselines.
- Multi-seed schema subset pool with evolutionary expansion: rather than generating one schema subset per query (as in E-SQL, CHASE-SQL, MCTS approaches), CA-SQL generates up to 20 distinct subsets and then applies crossover and mutation operators to produce additional subsets in subsequent rounds without additional LLM schema-linking calls.
- Sum-of-rewards candidate selection: the final query is chosen by grouping candidates by their database output O and summing R = s*(1-t)*k across all candidates producing each O, providing a richer aggregation signal than majority voting or single-pass LLM-as-a-judge (prior approach in CHASE-SQL and MCS-SQL).
- Critic-derived mutation temperature t as a tiebreaker: the critic explicitly estimates how much a query still needs to change, and this signal penalizes high-reward-but-still-imperfect queries in the reward formula, distinguishing among candidates with identical output scores.
- Empirical characterization of schema-seed diversity: the authors provide an ablation (Section 4.6) directly measuring candidate query uniqueness under single-seed vs multi-seed schema linking, which is a novel empirical contribution clarifying why prior methods plateau on hard queries despite high sample counts.
Datasets
- BIRD (BIg Bench for Large-Scale Database Grounded Text-to-SQL) development set — 1,534 NL-SQL pairs across 95 databases, 37 domains — public benchmark (Li et al., 2023)
Baselines vs proposed
- MCS + GPT-4: Challenging EX = 51.4% vs CA-SQL + GPT-4o-mini: 51.72%
- E-SQL + GPT-4o-mini: Challenging EX = 40.0%, Overall EX = 59.81%, Overall Soft F1 = 61.59% vs CA-SQL + GPT-4o-mini: 51.72%, 61.06%, 68.77%
- E-SQL + GPT-4o: Challenging EX = 48.07%, Overall EX = 66.29%, Overall Soft F1 = 67.93% vs CA-SQL + GPT-4o-mini: 51.72%, 61.06%, 68.77%
- MCTS + GPT-4o-mini: Challenging EX = 45.83%, Overall EX = 63.15% vs CA-SQL + GPT-4o-mini: 51.72%, 61.06%
- MCTS + GPT-4o: Challenging EX = 51.48%, Overall EX = 69.4% vs CA-SQL + GPT-4o-mini: 51.72%, 61.06%
- Simple tier: MCTS + GPT-4o: 74.32% vs CA-SQL + GPT-4o-mini: 66.93% (CA-SQL underperforms on simple tasks)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.08057.
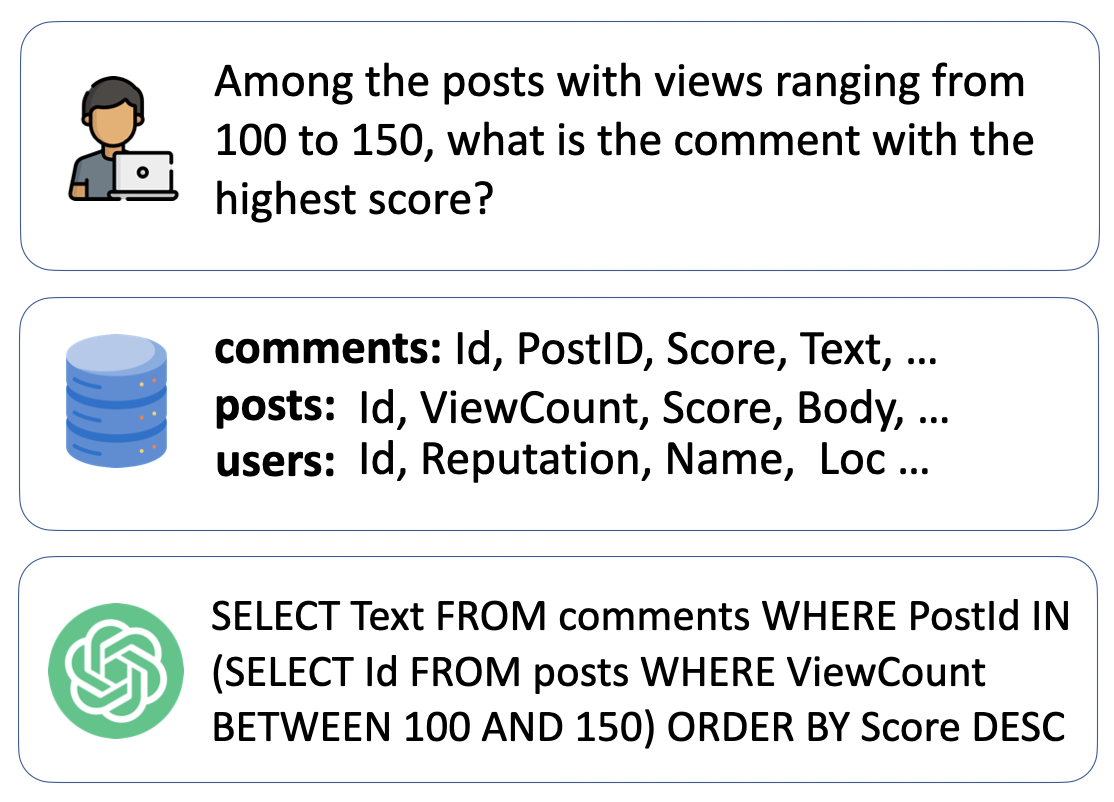
Fig 1: The Text-to-SQL process, whereby a user’s
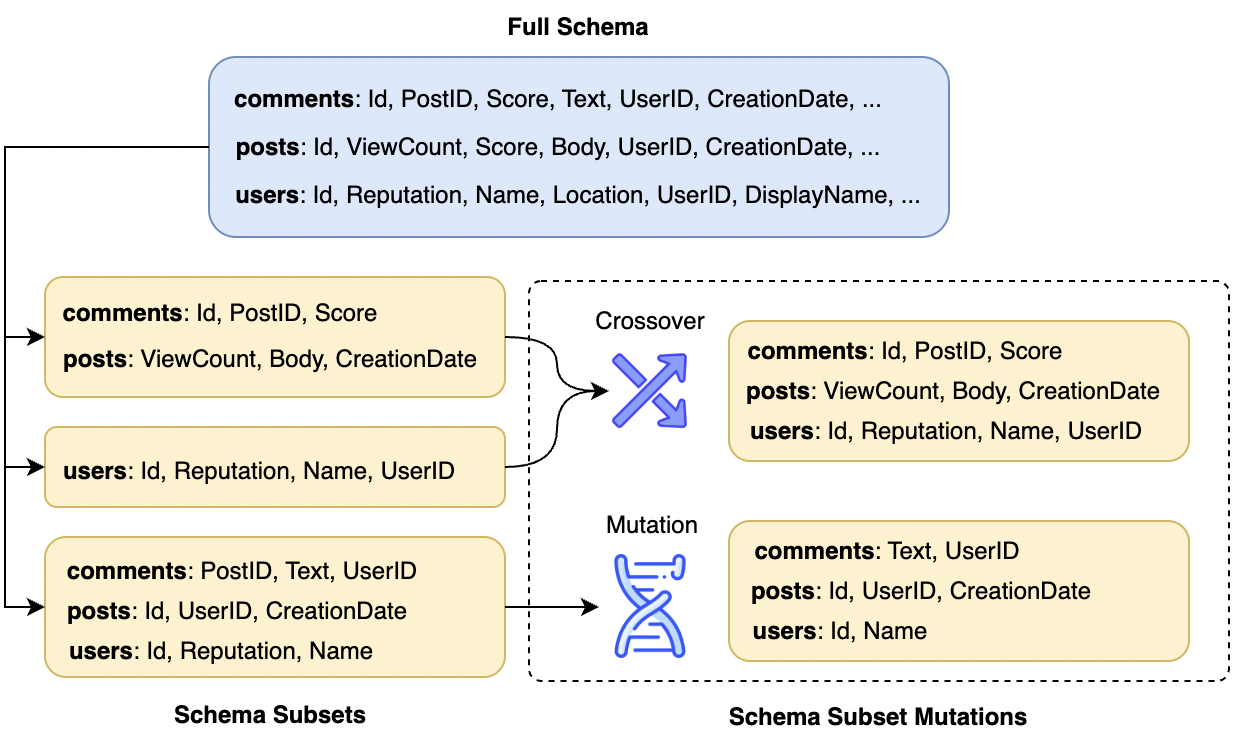
Fig 2: Schema subsets are derived from the full
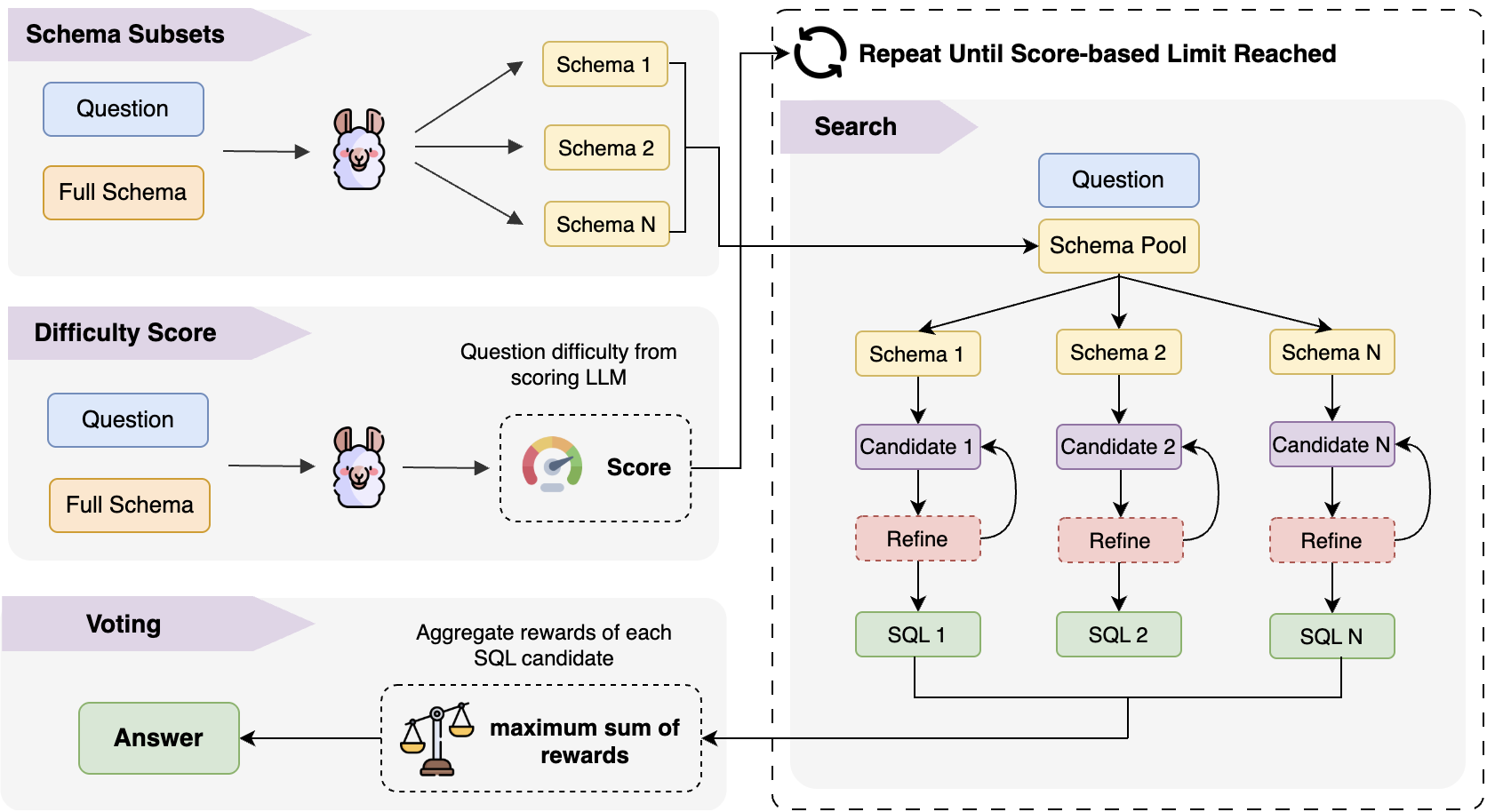
Fig 3: Overview of CA-SQL’s methodology. The core components of our proposed approach include schema
Limitations
- Single-model evaluation: all experiments use GPT-4o-mini exclusively; no results with GPT-4o, GPT-4, open-weight models (Llama, Mistral, etc.), or fine-tuned SQL models, making it impossible to determine whether the gains generalize across model families or are artifacts of GPT-4o-mini's specific behavior.
- Difficulty score variance uncharacterized: C is sampled once from LLMdifficulty; the authors acknowledge this score may fluctuate substantially across samples from the same model for the same question, and no variance measurement or ensemble-voting strategy is implemented — a single noisy score gates all downstream compute.
- Simple-tier performance regression: CA-SQL scores 66.93% EX on simple tasks vs 74.32% for MCTS+GPT-4o and 73.02% for E-SQL+GPT-4o, suggesting the exploration-heavy approach actively hurts on easy queries, possibly through over-refinement or schema-linking noise introducing spurious columns.
- No cost or latency reporting: the paper makes no mention of API call counts, wall-clock time, or dollar cost per query, making it impossible to assess whether the improvement on challenging tasks is economically justified compared to simply using a larger model like GPT-4o directly.
- BIRD dev set only, no test set or external benchmark: all reported results are on BIRD's development set (gold queries available for EX scoring); no BIRD test set submission or Spider/Spider 2.0 evaluation is reported, raising questions about overfitting to BIRD's specific distribution.
- Ablation completeness unclear: Section A.1 is referenced for voting strategy ablations and Section A.2 for exploration analysis, but the full text is truncated — the specific deltas, number of ablation conditions, and whether all components are individually ablated (e.g., removing difficulty scoring while keeping multi-seed) cannot be confirmed from the provided text.
- No statistical significance testing: given that the margin over the nearest baseline on challenging tasks is 0.24% (CA-SQL 51.72% vs MCTS+GPT-4o 51.48%) and 5.89% over the same-model baseline, no bootstrap confidence intervals or significance tests are reported to establish whether the challenging-tier gap is reliable.
Open questions / follow-ons
- Does multi-seed schema subset exploration generalize to other structured prediction tasks beyond SQL (e.g., code generation, knowledge graph querying), or is the benefit specific to the schema-linking bottleneck in Text-to-SQL?
- How sensitive is the pipeline to difficulty score accuracy — if the LLM systematically mis-classifies a challenging query as simple (or vice versa), how much does overall performance degrade, and can ensemble scoring or calibration methods mitigate this?
- Is there an optimal crossover-vs-mutation ratio for schema subset evolution, and does it vary by database size or query type? The paper fixes crossover probability at p=0.50 without ablating this hyperparameter.
- Can the sum-of-rewards voting mechanism be made more robust by incorporating execution result semantics (e.g., output cardinality, value type checks) rather than relying solely on LLM-assigned critic scores, which are themselves noisy signals from the same base model?
Why it matters for bot defense
This paper is not directly relevant to CAPTCHA or bot defense, but it contains methodological ideas that are transferable to any adversarial query-generation or evasion-detection problem where solution space coverage matters. Specifically, the evolutionary schema subset expansion technique is a principled way to generate diverse prompt seeds without proportional LLM call overhead — a practitioner building automated red-teaming tools for CAPTCHA bypass detection or synthetic bot behavior generation could adapt this approach to ensure their attack corpus covers a wider combinatorial space of behavioral patterns rather than clustering around a single high-likelihood mode.
The difficulty-adaptive compute allocation concept is also relevant to bot-defense systems that must triage incoming requests by complexity before deciding how much inference budget to spend on classification. A bot-defense pipeline that applies a cheap complexity pre-filter to route easy cases to a lightweight model and hard cases (e.g., headless browsers mimicking human mouse dynamics with high fidelity) to a more expensive ensemble would mirror CA-SQL's architecture almost directly. The key caution is that CA-SQL's difficulty scorer is itself a single noisy LLM call with uncharacterized variance — any production bot-defense adaptation would need a more calibrated and auditable complexity estimator before relying on it to gate expensive downstream computation.
Cite
@article{arxiv2605_08057,
title={ CA-SQL: Complexity-Aware Inference Time Reasoning for Text-to-SQL via Exploration and Compute Budget Allocation },
author={ James Petullo and Nianwen Xue },
journal={arXiv preprint arXiv:2605.08057},
year={ 2026 },
url={https://arxiv.org/abs/2605.08057}
}