
BAMIFun: Bayesian Multiple Imputation for Functional Data
Source: arXiv:2605.08018 · Published 2026-05-08 · By Ziren Jiang, Lei Xuan, Eric F. Lock, Erjia Cui
TL;DR
BAMIFun addresses a well-known but under-solved problem in functional data analysis: when trajectories are sparsely or irregularly observed (common in wearable device, microbiome, and neuroimaging studies), standard FPCA-based imputation (the PACE approach) produces single-point estimates with no propagation of imputation uncertainty, leading to overconfident downstream inferences such as systematically under-covered confidence intervals in scalar-on-function regression. The paper introduces a fully Bayesian multiple imputation framework that embeds penalized B-spline representations inside a low-rank matrix factorization (FPCA model), derives a closed-form Gibbs sampler over the spline coefficient matrix B, the PC score matrix V, and the noise variances, and generates a posterior ensemble of plausible complete datasets whose variability is then pooled via Rubin's rules for any downstream analysis.
Beyond single-level functional data, the paper extends the framework to multiway functional data (N × J × K tensors where the K-mode is a continuum) by coupling the Bayesian Gibbs sampler to the Functional Tensor Singular Value Decomposition (FTSVD) model of Han et al. (2024), which is a CP-type factorization with a smoothness constraint on the functional factor. This is claimed to be the first multiple imputation procedure for such data structures. The critical distinction from BAMITA (a prior Bayesian tensor imputation method by Jiang, Li and Lock, 2025) is that BAMIFun enforces functional smoothness via a penalty matrix P derived from integrated squared second derivatives of the spline basis, whereas BAMITA treats the tensor entries as discrete with no such constraint.
Simulation results across missingness levels of 80%, 90%, and 95% and sample sizes of 100, 300, and 500 show that BAMIFun maintains credible interval coverage near the nominal 95% level for imputed entries and for downstream scalar-on-function regression (SoFR) coefficients, whereas PACE systematically under-covers and BAMITA under-covers at small sample sizes. In terms of raw imputation MSE, BAMIFun is competitive with or slightly worse than PACE in some settings but substantially better than BAMITA throughout. Real-data case studies on NHANES physical activity trajectories and a longitudinally collected infant gut microbiome dataset corroborate these patterns under severe practical missingness.
Key findings
- BAMIFun maintains empirical coverage of imputed entries near the nominal 95% level across all simulation scenarios (coverage ranges 91.7–96.6% in Table 1), whereas PACE provides no credible intervals and BAMITA exhibits under-coverage, especially at n=100.
- For single-level functional data at 95% missingness and n=100, BAMIFun relative imputation MSE is slightly worse than PACE (exact values visible in Fig 1 but not fully extracted from truncated text), yet BAMIFun's coverage is near 95% vs. PACE's systematic undercoverage; the MSE gap narrows as n increases to 300 and 500.
- For multiway low-rank functional data (Table 1), BAMIFun outperforms PACE in relative MSE at 90% and 95% missingness (e.g., n=100, 90% missing: BAMIFun 0.272 vs. PACE 0.430; n=100, 95% missing: BAMIFun 0.397 vs. PACE 0.614), while PACE has lower MSE only in the non-low-rank setting at high n.
- For downstream scalar-on-function regression (SoFR, Fig 2), BAMIFun achieves substantially higher coverage of the 95% CI for the functional coefficient β(t) than PACE across all missingness and sample size combinations, addressing the core undercoverage problem that motivated the paper.
- PACE's relative integrated squared error for the SoFR coefficient does not consistently decrease—and in some scenarios increases—with sample size, a counterintuitive failure attributed to single imputation ignoring imputation uncertainty propagation; BAMIFun's ISE does decrease with n.
- Incorporating smoothness (penalized splines) within the Bayesian sampler consistently produces lower imputation MSE than BAMITA (a non-smooth Bayesian tensor imputation baseline) across all functional data settings, demonstrating that the smoothness constraint is not cosmetic but substantially improves reconstruction.
- Cross-validation selection of the smoothing parameter σ²_B yields slightly better MSE than treating σ²_B as a Bayesian unknown but at the cost of mildly reduced coverage; the authors recommend the fully Bayesian approach given its much lower computational cost.
- Both real-data applications (NHANES physical activity, n subjects on 100-point grid; infant gut microbiome, N×152 genera×K time points) produce substantially wider but better-calibrated uncertainty intervals under BAMIFun relative to PACE, consistent with simulation findings under severe sparsity.
Methodology — deep read
Threat model and assumptions (missing data mechanism): The paper assumes data are Missing Completely At Random (MCAR) — the observation indicator O is independent of unobserved values. The adversary here is not a security agent but a statistical one: the concern is that treating single-imputed values as observed truth propagates no uncertainty into downstream inference, producing anti-conservative standard errors and coverage below nominal. The paper does not explicitly address Missing At Random (MAR) or MNAR settings, which is a significant scope limitation acknowledged implicitly.
Data provenance and preprocessing: Simulated data for single-level experiments use K=100 time points and eigenfunctions extracted from a real NHANES physical activity dataset (12 eigenfunctions, eigenvalues [2,2,2,1,1,1,0.5,0.5,0.5,0.1,0.1,0.1]). Noise variance σ²=1. Missing proportions s∈{0.8,0.9,0.95} with the constraint that each subject retains at least 2 observed time points; sample sizes N∈{100,300,500}; 500 simulation replications per scenario. For multiway data, K=100, J=4 visits; two sub-scenarios (low-rank CP structure and non-low-rank MFPCA structure) are tested. Real datasets: (1) NHANES physical activity (accelerometry), publicly available; (2) infant gut microbiome data with J=152 genera as the feature mode, longitudinally collected (source is non-public but referenced). No explicit train/test split for the real data — the entire observed dataset is used for imputation and inference.
Model architecture — single-level: The generative model is Xi(t) = Σ_r ξ_ir u_r(t) + ε_i(t), truncated at R principal components. In matrix form: X = VU^T + E. Eigenfunctions U are parameterized via B-spline basis expansion U^T = BΘ where Θ is L×K (L=15 B-spline basis functions evaluated at K grid points) and B is R×L. The smoothness penalty ∫(u''_r(t))² dt translates into a Gaussian prior on rows of B with precision proportional to the integrated squared second-derivative penalty matrix P. The noise E_ik ~ N(0,σ²). Jeffreys (improper flat) priors are placed on V and σ²; Jeffreys prior on σ²_B (the smoothing variance). This results in a proper posterior because the likelihood is Gaussian and the spline coefficients have a well-defined conditional distribution.
Gibbs sampler derivation (single-level): Four full conditional updates per sweep: (1) V — each row ξ_i· is drawn from N((U^T U)^{-1} U^T X_i·, σ²(U^T U)^{-1}), i.e., standard Bayesian linear regression with no prior on V; (2) Vec(B) — multivariate Gaussian with precision matrix (1/σ²)(Θ^T⊗V)^T(Θ^T⊗V) + (1/σ²_B)(I_R⊗P) and corresponding mean, exploiting Kronecker structure; (3) σ² — inverse-Gamma with shape NK/2 and scale ||X - VU^T||²_F / 2; (4) σ²_B — inverse-Gamma with shape (R×L)/2 and scale Vec(B)^T (I_R⊗P) Vec(B) / 2. After each sweep, missing entries of X are imputed by sampling from N(Ṽ_s Ũ_s^T, σ²_s) at the observed-missing indicator locations, and the imputed values are treated as data in the next sweep (data augmentation). Eigenfunctions are rescaled to unit norm after each iteration. Initialization uses the frequentist face.sparse() FPCA (Xiao et al., 2018) to provide starting values for U and V.
Multiway extension: The FTSVD model X = Σ_r λ_r v_r ∘ w_r ∘ u_r + E is adopted (Han et al., 2024), where v_r (length N), w_r (length J) are discrete factors and u_r (length K) is the smooth functional factor. Matricizing along mode 3 gives X_(3) = U(W⊙V)^T + E_(3). The same penalized spline representation U^T = BΘ and the same prior structure apply. The Gibbs sampler extends to additionally sample W (analogous update to V), and the Khatri-Rao product (W⊙V) plays the role of the design matrix. The full Gibbs sampler for the multiway case is deferred to Supplementary Material Section 3, making independent reproduction non-trivial.
Evaluation protocol: For imputation quality: relative MSE = Σ_{O=0}(X - X̂)² / Σ_{O=0} X² over held-out (artificially missing) entries. For coverage: empirical proportion of true values falling inside the 95% posterior credible interval (BAMIFun) or 95% CI from face.sparse() standard errors (PACE). For downstream SoFR: relative integrated squared error ∫(β̂(t)-β(t))²dt / ∫β(t)²dt, and empirical coverage of 95% CI for β(t) constructed via Rubin's rules (BAMIFun/BAMITA) or nonparametric bootstrap (PACE). Baselines: PACE (Xiao et al., 2018 fast FPCA), BAMITA (Jiang, Li and Lock, 2025); for multiway, PACE via multilevel FPCA (Di et al., 2009). No formal statistical significance tests (e.g., no paired t-tests over replications) are reported — comparisons are purely descriptive across 500 replications. Number of MCMC iterations S and burn-in are not explicitly stated in the truncated main text (likely in supplement).
Reproducibility: Code is publicly released at https://github.com/ZirenJiang/BAMIFun. The NHANES dataset is public. The infant gut microbiome dataset's public availability is unclear from the truncated text. The number of MCMC iterations, burn-in, and convergence diagnostics are not detailed in the main text excerpt, representing a reproducibility concern.
Technical innovations
- First Bayesian multiple imputation framework for sparse functional data that requires no auxiliary scalar outcomes, scalar covariates, or supplementary functional variables — unlike Petrovich et al. (2022), Rao and Reimherr (2021), He et al. (2011), and Jang et al. (2021) which all require side information.
- Integration of penalized spline smoothness constraints (via the integrated squared second-derivative penalty matrix P) directly into the Bayesian prior on spline coefficients B, enabling closed-form Gibbs updates that jointly infer eigenfunctions and propagate smoothing uncertainty — extending Jiang, Crainiceanu and Cui (2025)'s equivalence result into a full posterior sampler.
- Extension of Bayesian multiple imputation to multiway (tensor) functional data via a Bayesian sampler for the FTSVD model (Han et al., 2024 proposed only a frequentist estimator), claimed to be the first multiple imputation method for this data structure.
- Principled combination of functional multiple imputation with Rubin's rules for downstream scalar-on-function regression, demonstrating empirically that between-imputation variance is essential for calibrated inference and that bootstrap on single-imputed data (PACE's approach) systematically under-covers.
- Cross-validation procedure (Algorithm 2) for selecting the number of principal components R within the Bayesian functional imputation pipeline, using 40% of observed data as a validation set and minimizing imputation MSE, trading marginal coverage reduction for improved MSE.
Datasets
- NHANES Physical Activity — ~K=100 time-point accelerometry trajectories, N not specified in excerpt — publicly available (National Health and Nutrition Examination Survey, CDC)
- Infant Gut Microbiome — N subjects × J=152 genera × K time points, longitudinally collected — non-public, source reference not fully extracted from truncated text
- Simulated single-level functional data — N∈{100,300,500} × K=100 × 500 replications — generated from NHANES-derived eigenfunctions
- Simulated multiway functional data — N∈{100,300,500} × J=4 × K=100 × 500 replications — two sub-scenarios (low-rank and non-low-rank)
Baselines vs proposed
- PACE (fast FPCA, Xiao et al. 2018): imputation relative MSE at 90% missing, n=100, low-rank multiway = 0.430 vs BAMIFun: 0.272 (Table 1)
- PACE: imputation relative MSE at 95% missing, n=100, low-rank multiway = 0.614 vs BAMIFun: 0.397 (Table 1)
- PACE: imputation relative MSE at 80% missing, n=100, low-rank multiway = 0.237 vs BAMIFun: 0.215 (Table 1)
- PACE: imputation relative MSE at 95% missing, n=100, non-low-rank multiway = 0.437 vs BAMIFun: 0.541 (Table 1) — PACE wins in non-low-rank setting
- BAMITA: imputation relative MSE consistently higher than BAMIFun across all single-level functional data scenarios due to absence of smoothness constraint (Fig 1, exact values in figure not extractable from text)
- PACE SoFR coverage: systematic undercoverage below 95% nominal level across all n and missing proportion settings vs BAMIFun: near 95% (Fig 2)
- BAMIFun multiway coverage: 91.7–96.6% across all Table 1 scenarios vs PACE: not available (MFPCA software provides no CI for fitted curves)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.08018.
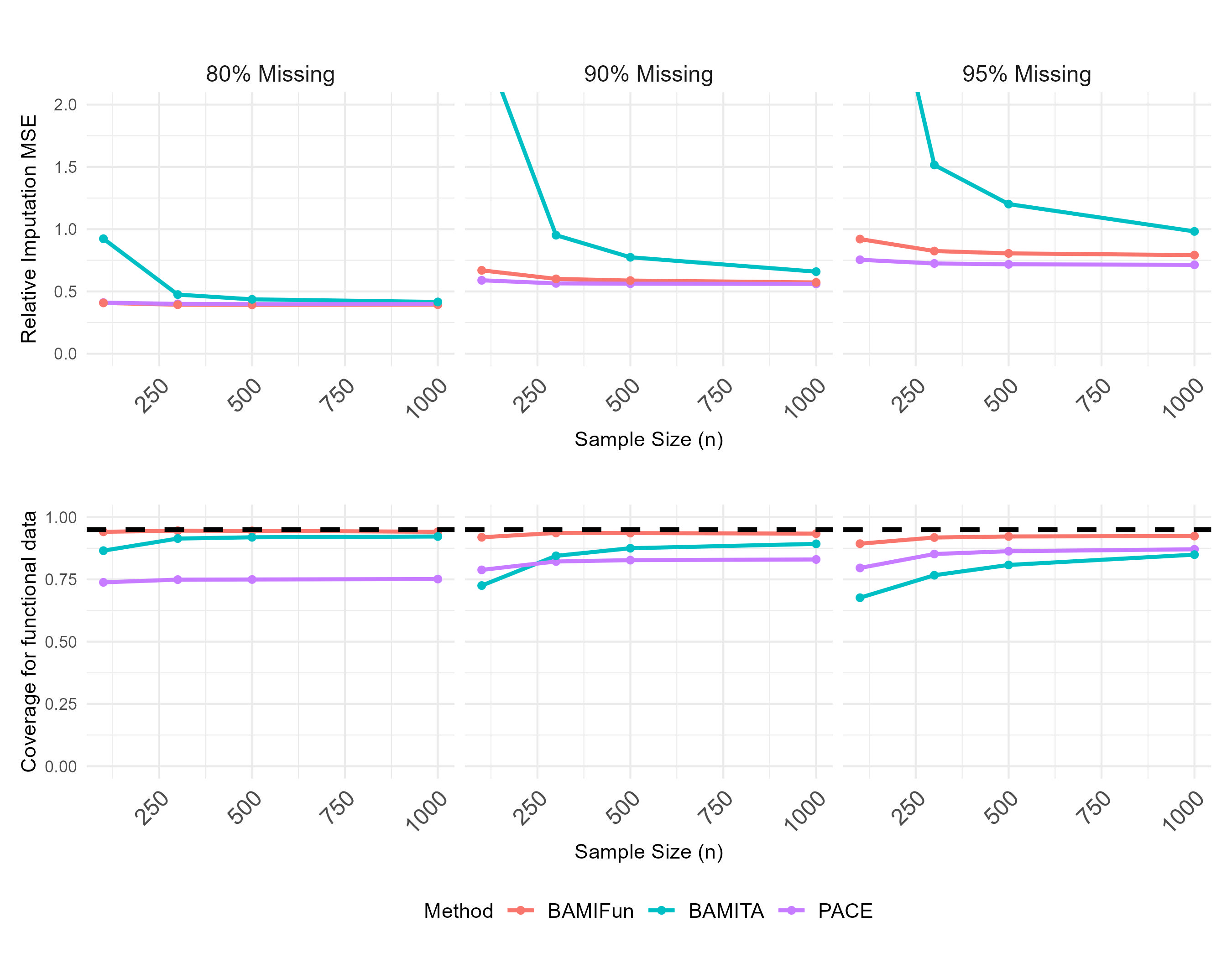
Fig 1: Simulation results for the imputation performance of single-level functional data. The
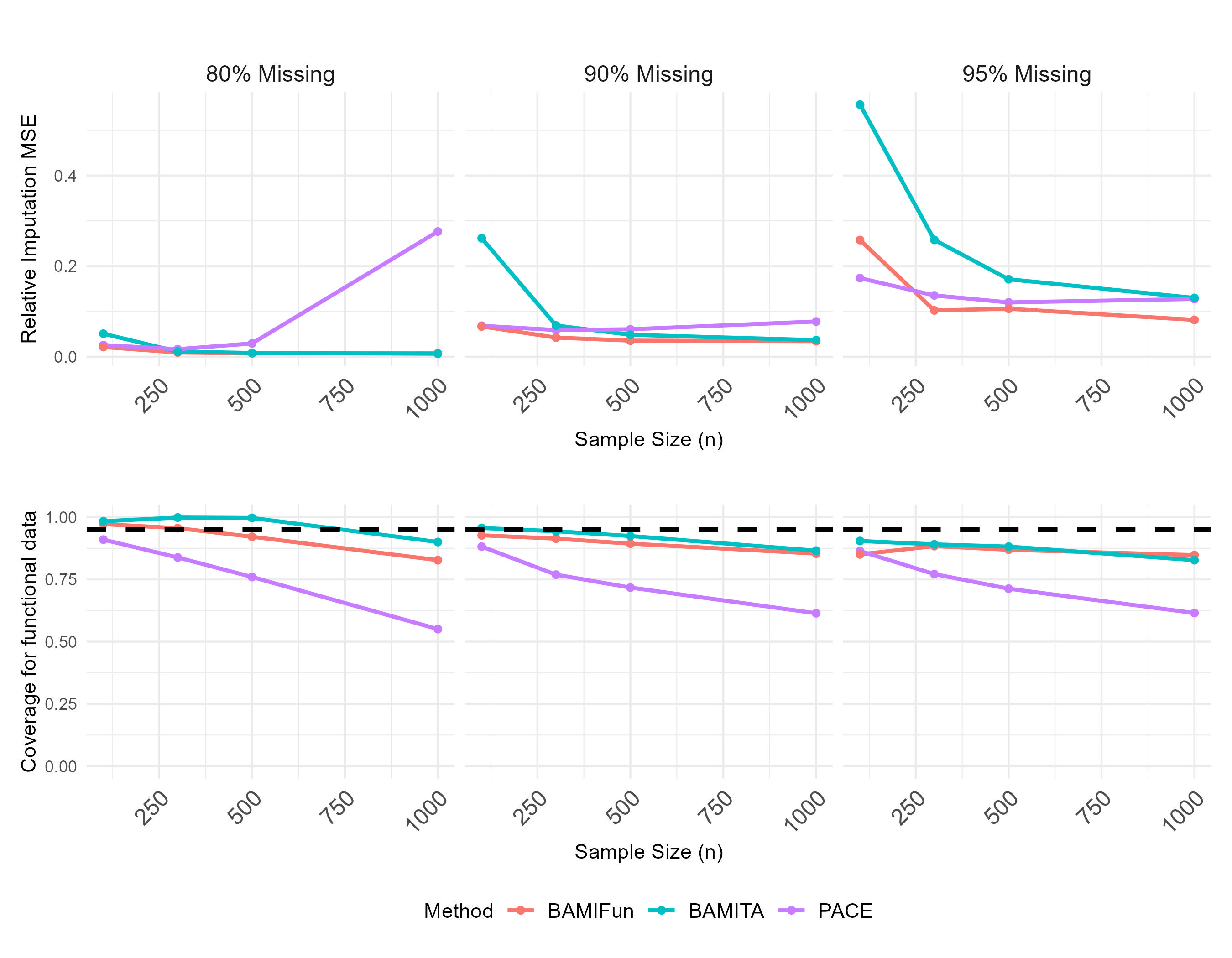
Fig 2: Simulation results for the performance of downstream Scalar-on-Function Regression
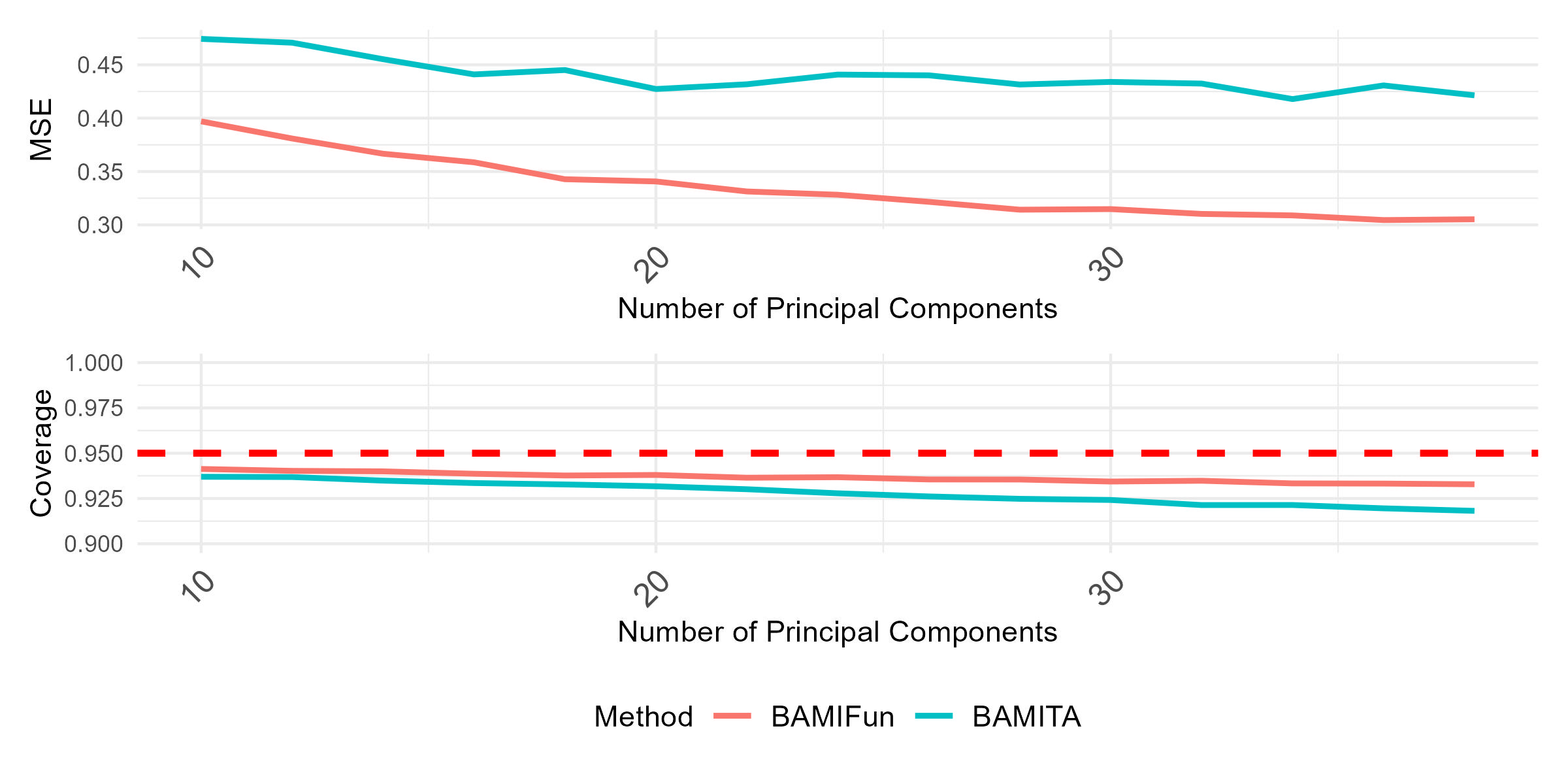
Fig 3: Multiple imputation results using the infant gut microbiome dataset. The top panel
Limitations
- MCAR assumption is never relaxed: the observation model O is treated as independent of unobserved values; MAR and MNAR mechanisms — common in real biomedical data where missingness correlates with subject health state — are not evaluated and could invalidate the imputation.
- The number of MCMC iterations, burn-in length, and convergence diagnostics (e.g., R-hat, effective sample size) are not reported in the main text, making it difficult to assess whether posteriors are well-mixed, especially in high-dimensional multiway settings.
- In the non-low-rank multiway scenario, PACE outperforms BAMIFun in relative MSE (e.g., 0.437 vs 0.541 at 95% missing, n=100), indicating BAMIFun's FTSVD model is misspecified when the true structure is MFPCA-type additive; the paper acknowledges this but does not propose a model selection procedure between FTSVD and MFPCA.
- The Gibbs sampler for multiway functional data (Algorithm and full conditionals for the FTSVD case) is entirely deferred to Supplementary Material Section 3, limiting peer review of the core multiway contribution from the main text alone.
- Downstream analysis is demonstrated only for scalar-on-function regression; it is unclear how Rubin's rules extend to nonlinear functional analyses (e.g., functional clustering, function-on-function regression, classification) where combining rules are less standard.
- Computational cost is not systematically benchmarked: runtime comparisons between BAMIFun, BAMITA, and PACE are absent, which matters practically since Gibbs sampling over large Kronecker-structured systems (e.g., (Θ^T⊗V) for large N, K, L) can be expensive.
- The cross-validation grid for R is anchored to the frequentist FPCA estimate (R_freq - 3 to R_freq - 1), meaning if the frequentist method severely misestimates R (likely under extreme sparsity), the search grid may exclude the true optimum.
Open questions / follow-ons
- How does BAMIFun behave under MAR or MNAR missingness mechanisms, where the probability of observation depends on unobserved functional values (e.g., subjects with extreme activity drop out of NHANES monitoring)? The current framework provides no theoretical guarantees outside MCAR.
- Can the FTSVD Bayesian sampler scale to realistic neuroimaging tensors where N, J, and K are all in the hundreds or thousands, and what approximations (e.g., variational inference, sparse GP priors, stochastic gradient MCMC) would be necessary?
- Is there a principled Bayesian model selection criterion (e.g., LOO-CV, WAIC) to choose between the FTSVD model and MFPCA-type models for multiway functional data when the true generative structure is unknown?
- How does propagating functional imputation uncertainty through nonlinear downstream tasks (e.g., functional clustering via k-means on PC scores, or deep learning on imputed trajectories) differ from Rubin's rules, and can the BAMIFun posterior samples support such extensions directly?
Why it matters for bot defense
At first glance, Bayesian functional data imputation appears orthogonal to bot defense and CAPTCHA. However, behavioral biometrics pipelines — which model continuous mouse trajectory, keystroke timing, scroll velocity, or touch pressure curves — face exactly the structural problem BAMIFun targets: sparse, irregularly sampled behavioral signals that must be reconstructed before being fed to a classifier or anomaly detector. Current pipelines typically interpolate or zero-pad missing signal segments (analogous to PACE's single imputation), treating the reconstructed trajectory as ground truth and discarding uncertainty. This leads to overconfident downstream bot-score distributions, potentially inflating true positive rates in evaluation while degrading calibration in production. BAMIFun's framework offers a principled alternative: generate multiple plausible completions of a partially observed behavioral trajectory, propagate uncertainty through the scoring model, and produce a calibrated confidence interval on the bot probability rather than a point estimate.
A more immediate practical concern is adversarial signal manipulation: a sophisticated bot might deliberately introduce gaps or irregular sampling in its behavioral trace (e.g., by throttling JavaScript event listeners) to exploit the assumptions of single-imputation reconstructors. A Bayesian multiple imputation backend would produce wider, higher-uncertainty imputations in such adversarially sparse regimes, which could itself be a signal — unusually high between-imputation variance on a session's trajectory is an anomaly flag. The multiway extension (handling N users × J behavioral channels × K time points) maps directly onto multi-modal behavioral telemetry. That said, the MCAR assumption is a serious limitation in this context: bot behavioral gaps are almost certainly not random, making the theoretical coverage guarantees suspect without extensions to MAR/MNAR settings. Engineers should treat BAMIFun as a useful research prototype for uncertainty-aware behavioral reconstruction rather than a production-ready system.
Cite
@article{arxiv2605_08018,
title={ BAMIFun: Bayesian Multiple Imputation for Functional Data },
author={ Ziren Jiang and Lei Xuan and Eric F. Lock and Erjia Cui },
journal={arXiv preprint arXiv:2605.08018},
year={ 2026 },
url={https://arxiv.org/abs/2605.08018}
}