
Which Are the Low-Resource Languages of the Semantic Web?
Source: arXiv:2605.05929 · Published 2026-05-07 · By Ndeye-Emilie Mbengue, Pierre Monnin, Miguel Couceiro, Fabien Gandon
TL;DR
This poster paper tackles the absence of a principled, quantitative definition of 'low-resource language' within the Linked Open Data (LOD) / Semantic Web ecosystem. Whereas the NLP community has prior categorization schemes (notably Joshi et al. 2020, using LDC/ELRA corpus counts vs. Wikipedia edition sizes), no equivalent framework existed for LOD Knowledge Graphs. The authors argue that this gap blocks systematic cross-lingual transfer efforts aimed at enriching KGs for underrepresented languages, since you cannot select transfer candidates without knowing who is resource-poor in the KG sense.
The authors first replicate Joshi et al.'s k-means-based 6-category scheme (Winners → Left-Behinds) on three structurally distinct multilingual KGs — DBpedia, Wikidata, BabelNet — using two dimensions per language: entity count in the KG and Wikipedia edition article count. They find partial but imperfect alignment with NLP categories (NMI scores: 0.63 for DBpedia, 0.60 for BabelNet, 0.56 for Wikidata), and observe that the dominant shared signal is simply the massive prevalence of Left-Behinds, masking structural divergences. Importantly, DBpedia shows a near-linear (Wikipedia-coupled) distribution, Wikidata shows left-divergence (more entities than articles), and BabelNet also leans left-divergent but more compactly — meaning a single NLP-derived scheme cannot uniformly describe all three.
Their main contribution is a formal, quartile-based 4-category definition (Missing, Low-Resource, Medium-Resource, High-Resource) grounded in the empirical distributions of entity counts and article counts within whatever LOD sources are selected. Applied to the aggregate of DBpedia + Wikidata + BabelNet (without entity deduplication, so results are optimistic), results show most covered languages land in Medium-Resource, while a substantial number remain unclassified or Missing. The framework is positioned as a first step toward building targeted cross-lingual transfer pipelines for KG completion.
Key findings
- NMI scores between Joshi et al.'s NLP language categories and KG-derived categories are 0.63 (DBpedia), 0.60 (BabelNet), and 0.56 (Wikidata), indicating only partial alignment — predominantly driven by shared Left-Behinds prevalence.
- DBpedia exhibits a near-linear log-log distribution of entity count vs. Wikipedia article count, reflecting its direct dependency on Wikipedia infobox extraction, making it the KG most suited to cross-lingual transfer strategies.
- Wikidata shows strong left-divergence (entities >> Wikipedia articles for many languages), suggesting KG verbalization rather than text-extraction approaches are more appropriate for improving its low-resource coverage.
- BabelNet presents a compact distribution also leaning left-divergent, indicating its synset-based multilingual coverage partially decouples from Wikipedia text availability.
- The 'Left-Behinds' category — languages with negligible representation in both KG entities and Wikipedia — is the consistently dominant category across all three LOD KGs and the original NLP categorization, underscoring systemic exclusion of the majority of WALS-documented written languages.
- The proposed formal definition uses Q1 and Q3 quartile thresholds on both the entity-count distribution (DE) and Wikipedia-article-count distribution (DW) to delineate Low-Resource (below Q1 on both axes), Medium-Resource (between Q1 and Q3 on both axes), and High-Resource (above Q3 on both axes) languages, with Missing covering languages absent from either dimension.
- When the quartile-based categorization is applied to the aggregated three KGs (no entity deduplication), most languages with any coverage fall into Medium-Resource, indicating that true high-resource status in LOD is rare and low-resource boundaries are meaningful separators.
Methodology — deep read
The threat model here is not a security adversary but a knowledge gap: the study assumes that existing NLP-community definitions of low-resource languages (which use annotated corpus size as a proxy for resource availability) do not transfer cleanly to the LOD context because KG entity coverage and textual corpus coverage are structurally decoupled in ways that vary by KG construction paradigm.
Data and scope: Languages are drawn from the World Atlas of Language Structures (WALS) written-language set, bounding the universe of languages under consideration. This matches the scope used by Joshi et al. [2] for comparability. The three KGs chosen — DBpedia, Wikidata, BabelNet — were selected to represent structural diversity: DBpedia is Wikipedia-extraction-based, Wikidata is community-edited with a broader entity graph, BabelNet is lexical-resource-fusion-based using synsets. For each language l, two counts are extracted: (i) |E(l)| = number of entities (or synsets, for BabelNet) tagged with language l in the KG, and (ii) |W(l)| = number of articles in l's Wikipedia language edition. No details on snapshot dates or exact extraction procedures are given in the poster text — this is a notable underspecification.
Phase 1 — Replication of Joshi et al.: k-means clustering (k=6) is applied in the 2D space of (log|W(l)|, log|E(l)|) for each KG independently. The resulting six clusters are then manually annotated by mapping them to Joshi et al.'s qualitative category labels (Winners, Underdogs, Rising Stars, Hopefuls, Scrapping-Bys, Left-Behinds) based on the description of each category. Normalized Mutual Information (NMI) is computed between each KG-derived clustering and the original NLP categorization from Joshi et al. to quantify overlap. The log-log scatter plots (Figure 1) visualize each KG's distribution alongside Joshi et al.'s NLP scatter for qualitative comparison.
Phase 2 — Formal quartile-based framework: The authors define four categories grounded in empirical quartiles of the distributions DE = {|E(li)|} and DW = {|W(li)|} across L* = LLOD ∩ LTXT (languages present in both a KG and a text corpus). Low-Resource = below Q1 on both dimensions; Medium-Resource = within [Q1, Q3] on both; High-Resource = above Q3 on both; Missing = absent from L*. Languages that fall in off-diagonal quadrants (e.g., high entity count but low Wikipedia count, or vice versa) are not explicitly categorized in the current definition — this is a deliberate simplification flagged for future work.
Aggregated application: The quartile framework is then applied to the union of DBpedia, Wikidata, and BabelNet entity counts (summed per language, without deduplication) paired with Wikipedia article counts, producing Figure 2. The authors explicitly flag that this produces an optimistic upper bound on coverage because cross-KG entity overlap is not resolved.
Evaluation protocol: The primary evaluation tool is NMI between clusterings, plus qualitative interpretation of log-log scatter plots. There is no held-out test set, no statistical significance testing beyond NMI, and no downstream task evaluation (e.g., actual cross-lingual transfer performance). This is a poster-length work, so the evaluation is necessarily preliminary.
Reproducibility: An online companion site (https://nembengue.github.io/language_digital_coverage_lod/) hosts detailed figures. Code or data snapshots are not explicitly described as released. Experiments were run on the Grid'5000 testbed, but no hardware-specific parameters are relevant given the computational simplicity of k-means on a small language set.
Technical innovations
- First formal, quartile-anchored definition of Low-/Medium-/High-Resource and Missing language categories specifically for the LOD/KG context, as opposed to borrowing NLP corpus-count definitions (Joshi et al. 2020).
- Extension of Joshi et al.'s 2D language-coverage analysis (annotated corpora vs. Wikipedia editions) to KG entity counts, enabling cross-modal (KG ↔ text) divergence analysis that reveals structurally distinct completion opportunities per KG.
- Identification and formalization of three divergence regimes in LOD KGs — near-linear (DBpedia, favoring cross-lingual transfer), left-divergent (Wikidata/BabelNet, favoring KG verbalization), and right-divergent (Wikipedia-rich but KG-poor, favoring automatic extraction) — as a guide to selecting enrichment strategies.
Datasets
- DBpedia — language-tagged entity counts per WALS written language — publicly accessible LOD KG
- Wikidata — language-tagged entity counts per WALS written language — publicly accessible LOD KG
- BabelNet — synset counts per WALS written language — partially open/licensed LOD lexical KG
- Wikipedia language editions — article counts per language edition — public (Wikimedia)
Baselines vs proposed
- Joshi et al. [2] NLP 6-category k-means clustering vs. DBpedia-derived 6-category k-means: NMI = 0.63
- Joshi et al. [2] NLP 6-category k-means clustering vs. BabelNet-derived 6-category k-means: NMI = 0.60
- Joshi et al. [2] NLP 6-category k-means clustering vs. Wikidata-derived 6-category k-means: NMI = 0.56
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.05929.
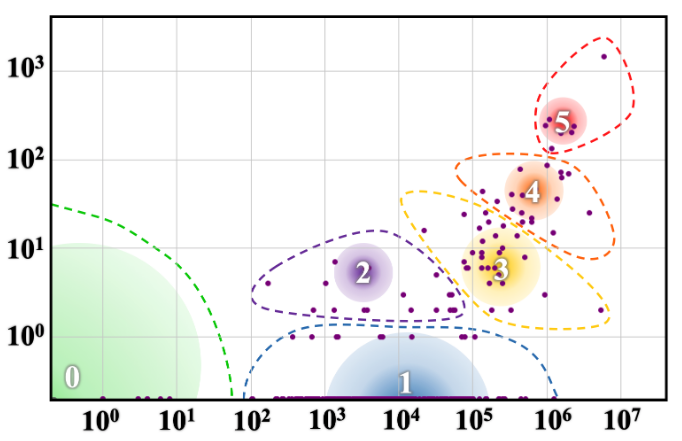
Fig 1: Language coverage (log-log) in BabelNet, Wikidata, DBpedia, and in
Limitations
- No entity deduplication across DBpedia, Wikidata, and BabelNet in the aggregated analysis (Figure 2), meaning entity counts are optimistically inflated and category boundaries in the combined view may be overly favorable.
- KG snapshot dates and exact extraction procedures are not specified, making the results non-reproducible without access to identical KG versions.
- The quartile-based definition does not handle off-diagonal languages (e.g., high KG coverage but low Wikipedia coverage, or vice versa), leaving a potentially large number of languages unclassified — acknowledged as future work but unresolved here.
- The framework is evaluated only on three KGs selected for structural diversity but not for comprehensiveness; other major multilingual LOD sources (e.g., Wikidata's full multilingual graph via SPARQL, ConceptNet, DBnary) are excluded.
- No downstream validation that the proposed categorization actually predicts cross-lingual transfer success — the categories are defined analytically but their utility for transfer candidate selection remains unproven.
- Scope is restricted to WALS written languages, excluding sign languages and unwritten/oral languages, which may themselves be among the most digitally excluded communities.
Open questions / follow-ons
- How do category assignments change after entity deduplication across KGs, and do the quartile thresholds shift enough to reclassify substantial numbers of languages?
- Do the proposed Low/Medium/High-Resource categories actually predict the success of cross-lingual transfer for KG completion tasks (e.g., entity alignment, relation prediction), and which transfer direction (high→low, medium→low) yields the best downstream gains?
- How should off-diagonal languages — those with high entity coverage but low Wikipedia coverage (or vice versa) — be formally categorized, and do they require distinct enrichment strategies beyond the three identified (cross-lingual transfer, verbalization, extraction)?
- Can the quartile-based framework be extended to dynamic settings where KG coverage evolves over time, and how often should category reassignment occur to reflect community editing activity (especially in Wikidata)?
Why it matters for bot defense
For bot-defense and CAPTCHA systems, this paper is tangentially relevant but carries real implications for internationalization of challenge pipelines. Many CAPTCHA systems implicitly assume high-resource language infrastructure — text-based challenges, semantic image labeling tasks, or knowledge-based questions drawn from KGs like Wikidata — and simply do not function equitably for users in low-resource language communities. If a bot-defense system uses a knowledge graph to generate or validate challenge content (e.g., entity-recognition tasks, semantic consistency checks, or GraphRAG-powered behavioral reasoning), the coverage gaps quantified here directly map to blind spots: languages in the 'Left-Behinds' or 'Missing' categories would receive no meaningful KG-grounded challenge content, potentially forcing fallback to language-agnostic modalities or, worse, to challenges calibrated for English/high-resource contexts that disadvantage legitimate users.
More concretely, if a bot-defense team is evaluating whether to enrich their challenge generation pipeline with multilingual KG data to cover a new market (e.g., deploying in a region where a 'Left-Behind' language dominates), this paper provides a diagnostic tool: query the target language's entity count in DBpedia/Wikidata/BabelNet and Wikipedia article count, locate it in the quartile framework, and determine whether cross-lingual transfer from a nearby high-resource language is viable, or whether the KG is so sparse that challenge content would be unreliable. The paper does not solve the enrichment problem, but it provides the first formal vocabulary and measurement methodology for scoping it.
Cite
@article{arxiv2605_05929,
title={ Which Are the Low-Resource Languages of the Semantic Web? },
author={ Ndeye-Emilie Mbengue and Pierre Monnin and Miguel Couceiro and Fabien Gandon },
journal={arXiv preprint arXiv:2605.05929},
year={ 2026 },
url={https://arxiv.org/abs/2605.05929}
}