
Verifier-Backed Hard Problem Generation for Mathematical Reasoning
Source: arXiv:2605.06660 · Published 2026-05-07 · By Yuhang Lai, Jiazhan Feng, Yee Whye Teh, Ning Miao
TL;DR
The paper addresses a core bottleneck in LLM self-improvement: the inability to reliably generate novel, valid, and hard mathematical problems without human experts. Prior self-play approaches (notably R-Zero) let a setter LLM earn reward from solver failure, but this invites reward hacking — generating syntactically or semantically broken problems the solver cannot answer trivially, falsely signaling difficulty. VHG (Verifier-backed Hard problem Generation) breaks the two-party setter–solver loop open into a three-party game by inserting an independent verifier that must accept a generated problem-reference pair (x, y*) before any solver-failure signal reaches the setter's reward. The setter's reward is thus the product of a binary validity gate (verifier) and a continuous difficulty signal (1 − solver accuracy), preventing invalid generations from earning credit regardless of how thoroughly they confuse the solver.
The framework is instantiated in two flavors. The Hard verifier uses SymPy to symbolically differentiate a proposed antiderivative F and check whether F' equals the integrand f — a deterministic, nearly error-free check. The Soft verifier uses an LLM-as-a-judge with hard-coded pre-filters (malformed outputs, missing answers, trivial copies) applied before model judgment, suitable for open-ended general math where symbolic oracles are unavailable. Both variants share the same training loop: cold SFT initializes the setter, then RL with verifier-gated reward iterates generation, verification, difficulty scoring, and solver training.
On indefinite integral benchmarks, VHG trained on Qwen3-4B-Base improves Pass@1 by 16.6–21.4 percentage points over the base model and substantially outperforms R-Zero, which actually degrades below vanilla GRPO after three iterations. On general math, VHG raises overall Pass@1 from 56.8% to 69.0% across MATH, AMC, Minerva, Olympiad, and AIME 2024–2026. A key additional finding is that hard problems generated by a 4B setter remain challenging for 8B, 14B, and 32B models (Pass@1 < 50%; Pass@8 still leaves 14–30% unsolved), suggesting a viable weak-to-strong curriculum generation path.
Key findings
- VHG (Hard verifier) raises Pass@1 on AntiderivBench Competition/Qualifier and Integral Stress Test from 28.8%/52.5%/43.3% (Qwen3-4B-Base) to 45.4%/69.4%/64.7% — absolute gains of +16.6, +16.9, and +21.4 pp respectively.
- R-Zero, the consensus-based self-play baseline, does not improve over vanilla GRPO on indefinite integral after three iterations (Competition Pass@1 degrades from 31.9% at iteration 1 to 30.5% at iteration 3), directly attributable to the absence of a hard validity gate.
- VHG (Soft verifier) raises overall general math Pass@1 from 56.8% (best R-Zero iteration) to 69.0% across MATH, AMC, Minerva, Olympiad, and AIME 2024–26, outperforming the best R-Zero iteration on all benchmarks except GSM8K.
- The setter's learning dynamics follow a two-phase pattern: validity improves first (reference-valid rate rises from 30.6% to 65.2% in steps 0–50), then difficulty improves (solver pass rate on valid samples falls from 42.0% to 17.6% in steps 50–200), while valid-and-hard fraction rises from 27.5% to 58.5%.
- Problems generated by the 4B VHG setter and filtered for zero local pass rate remain hard for much larger models: Qwen3-8B/14B/32B Pass@1 stays below 50% on both integral and general math challenge pools; Pass@8 still leaves 14% (integral) and 30% (general math) unsolved.
- R-Zero's consensus construction structurally cannot retain problems below 0.1 local accuracy (requires at least one supporting answer), whereas VHG places 46.0% of its hard-verifier-accepted integral pool in the [0.0, 0.1) accuracy bin (Fig. 5).
- Validity rate in VHG decreases monotonically as problem difficulty increases, but VHG maintains a relatively higher validity rate for the hardest problems compared to R-Zero, resulting in a larger absolute yield of hard-valid pairs in the [0.0, 0.1) bin.
Threat model
The adversary in VHG is the setter LLM itself acting as a reward-maximizing agent within the self-play loop. The setter has full access to its own generation process and observes the difficulty signal (solver accuracy) as reward feedback. Without a validity gate, the setter can exploit the proxy reward by generating syntactically plausible but semantically invalid, underspecified, or trivially broken problems — problems the solver cannot answer not because they are hard but because they are malformed. The setter cannot, by assumption, directly manipulate the verifier in the hard-verifier case (SymPy is a deterministic external oracle). In the soft-verifier case, a sufficiently capable setter could in principle learn to produce outputs that game the LLM judge, a risk the paper acknowledges by citing reward-hacking literature but does not empirically evaluate. The paper does not consider an external adversary (e.g., a user attempting to inject bad problems into the pipeline) — the threat model is entirely internal to the training loop.
Methodology — deep read
Threat model and problem framing. The adversarial dynamic here is not an external attacker but the setter LLM itself gaming its own reward signal. In standard setter–solver self-play, the setter's reward is 1 − AccS(x, y*): lower solver accuracy means higher reward. A setter trained purely on this signal can exploit it by producing malformed, underspecified, or trivially invalid problems — the solver fails, the setter earns high reward, but no useful training data is created. VHG's central design decision is to make validity a hard prerequisite for any difficulty reward, so the setter can only earn reward through genuinely difficult valid problems.
Data provenance and seed sets. For indefinite integral, the authors collected a small set of problems from a college calculus textbook and built a moderate-difficulty seed set. No exact count is provided in the truncated text, but it is described as 'small.' For general math, they sampled from the MATH dataset (Hendrycks et al., NeurIPS 2021 Datasets Track) and filtered to an easy subset where Qwen3-4B-Base achieves Pass@1 ≥ 0.75, ensuring the setter is initialized on problems currently solvable by the backbone. Labels are problem-reference pairs (x, y*); the setter must produce both, not just x. Splits are not formally described — the seed set feeds setter training, and held-out benchmarks (AntiderivBench, Integral Stress Test, MATH, AMC, AIME, etc.) evaluate the trained solver. The paper does not report a fixed random seed strategy or cross-validation.
Architecture and algorithm. All three parties (setter Q, solver S, verifier V) are built on Qwen3-4B-Base. The setter and solver are separate model instances with independent weights; both start from the same pretrained checkpoint. The verifier is either external (SymPy) or a separate LLM judge instance. The setter takes seed problem-reference pairs as context (few-shot conditioning) and generates new (x, y*) pairs. The reward function is formally: R_Q(x, y*) = 1[V(x,y*)=1] · (1 − AccS(x, y*)), where AccS is estimated via repeated sampling (64 samples per integral problem, 16 per general math problem). For solver training, only verifier-accepted pairs enter the RL data pool, with reward R_S(x, y*) = AccS(x, y*) for the solver on verified pairs. The RL algorithm used is GRPO (Group Relative Policy Optimization); the soft verifier combines a hard-coded filter (rejecting missing/multiple final answers, trivial copies, malformed outputs) with an LLM judge checking problem validity, answer validity, and their correspondence. The setter is initialized via cold supervised fine-tuning (SFT) on a small set of demonstrated problem-generation examples before RL begins.
Training regime. The setter RL runs for approximately 200 steps based on Fig. 4 (the trajectory plot shows steps 0–200). A context window of 8192 tokens is used for AMC and AIME benchmarks; 4096 tokens for all others. Backbone is Qwen3-4B-Base throughout. The paper does not report batch size, learning rate, optimizer, or specific hardware in the truncated text. The iterative pipeline is: (1) cold SFT on setter; (2) setter RL with verifier-gated reward; (3) generate a problem pool from the trained setter; (4) apply verifier and data-quality filters; (5) score accepted pairs by solver difficulty; (6) use selected hard pairs for solver RL training or challenge evaluation.
Evaluation protocol. For indefinite integral, evaluation benchmarks are AntiderivBench (Qualifier and Competition splits) and a curated Integral Stress Test. For general math, benchmarks are MATH, GSM8K, AMC, Minerva Math, Olympiad-level problems, AINE 2024, AIME 2025, and AIME 2026. Metrics are Pass@1 and Pass@8 under fixed sampling budgets. Baselines include: Qwen3-4B-Base (no training), Vanilla GRPO (on original seed data), Vanilla GRPO with SFT data, and R-Zero (up to 3 iterations). For the solver evaluation, the same Qwen3-4B-Base backbone is used for all conditions, enabling controlled comparison. The 'stronger solver' experiment (Table 2) evaluates Qwen3-8B, 14B, and 32B on the VHG-generated challenge pool to test transfer of difficulty beyond the training-time model size. No formal statistical significance tests (e.g., bootstrap CIs) are reported. No adversarial attacker evaluation against the verifier is conducted.
Concrete end-to-end example. Starting from seed problem '-1/x' (antiderivative), the setter generates the integral ∫[sin(ln|x|) − cos(ln|x|)] / x² dx with reference antiderivative y*. SymPy differentiates y* symbolically and checks F' = f; if matched and format-valid, V(x, y*) = 1. The solver then attempts this problem 64 times; suppose it succeeds on 5/64 attempts (AccS ≈ 0.078). The setter's reward is 1 · (1 − 0.078) = 0.922. This pair is added to the solver RL training pool. If instead the setter had hallucinated an invalid antiderivative, SymPy would detect F' ≠ f, V = 0, and reward = 0 regardless of solver failure, preventing the bad pair from polluting training.
Reproducibility. The paper does not mention a code release, frozen weights, or public availability of the generated problem pools in the truncated text. The prompts for the soft verifier are included in Appendix E.4 of the paper. The hard verifier (SymPy) is open-source. Whether the curated integral seed set or the filtered MATH easy subset is released is not stated.
Technical innovations
- Three-party self-play with a first-class validity gate: unlike R-Zero's consensus pseudo-labeling (which infers validity indirectly from solver agreement), VHG makes verifier acceptance a hard prerequisite in the reward oracle before any difficulty signal is computed, formally preventing invalid generations from earning setter reward.
- Dual-verifier instantiation: a Hard symbolic verifier (SymPy derivative check, near-100% reliable) and a Soft LLM-as-a-judge verifier (with hard-coded pre-filters) allow the same framework to operate in domains with and without symbolic oracles, extending the validity-gated reward paradigm beyond formally verifiable tasks.
- Setter generates problem-reference pairs jointly (x, y*) rather than problems alone, enabling direct symbolic or judge-based verification of the reference answer as part of the validity check — a departure from prior setters that produce only problem statements.
- Weak-to-strong curriculum generation: the empirical demonstration that a 4B-parameter setter trained with VHG can produce problems that remain unsolved by 8B–32B models (Pass@8 leaves 14–30% unsolved) provides evidence for scalable data generation where smaller models bootstrap harder data for larger models.
Datasets
- AntiderivBench (Qualifier and Competition splits) — size not specified in paper — source not stated (appears to be an existing benchmark for indefinite integral evaluation)
- Integral Stress Test — size not specified — curated by the authors for this paper
- MATH — 12,500 problems — Hendrycks et al., NeurIPS 2021 Datasets Track (public)
- GSM8K — 8,500 problems — Cobbe et al., arXiv 2021 (public)
- AMC — size not specified — competition problems (public)
- Minerva Math — size not specified — Google Research (public)
- Olympiad benchmark — size not specified — source not specified in paper
- AIME 2024, AIME 2025, AIME 2026 — 30 problems each — American Mathematics Competitions (public)
- College calculus textbook integral seed set — size described as 'small' — non-public, collected by authors
Baselines vs proposed
- Qwen3-4B-Base (no training) — Integral Competition Pass@1 = 28.8% vs VHG (Hard): 45.4%
- Qwen3-4B-Base (no training) — Integral Qualifier Pass@1 = 52.5% vs VHG (Hard): 69.4%
- Qwen3-4B-Base (no training) — Integral Stress Test Pass@1 = 43.3% vs VHG (Hard): 64.7%
- Vanilla GRPO — Integral Competition Pass@1 = 38.8% vs VHG (Hard): 45.4%
- Vanilla GRPO — Integral Qualifier Pass@1 = 66.5% vs VHG (Hard): 69.4%
- Vanilla GRPO — Integral Stress Test Pass@1 = 60.3% vs VHG (Hard): 64.7%
- R-Zero Iter. 1 — Integral Competition Pass@1 = 31.9% vs VHG (Hard): 45.4%
- R-Zero Iter. 3 — Integral Competition Pass@1 = 30.5% vs VHG (Hard): 45.4%
- Best R-Zero iteration — General Math overall Pass@1 = 56.8% vs VHG (Soft/Judge-Verified): 69.0%
- Vanilla GRPO w. SFT data — Integral Competition Pass@1 = 43.0% vs VHG (Hard): 45.4%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06660.

Fig 1: VHG framework. The setter proposes problem-

Fig 2 (page 2).

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).
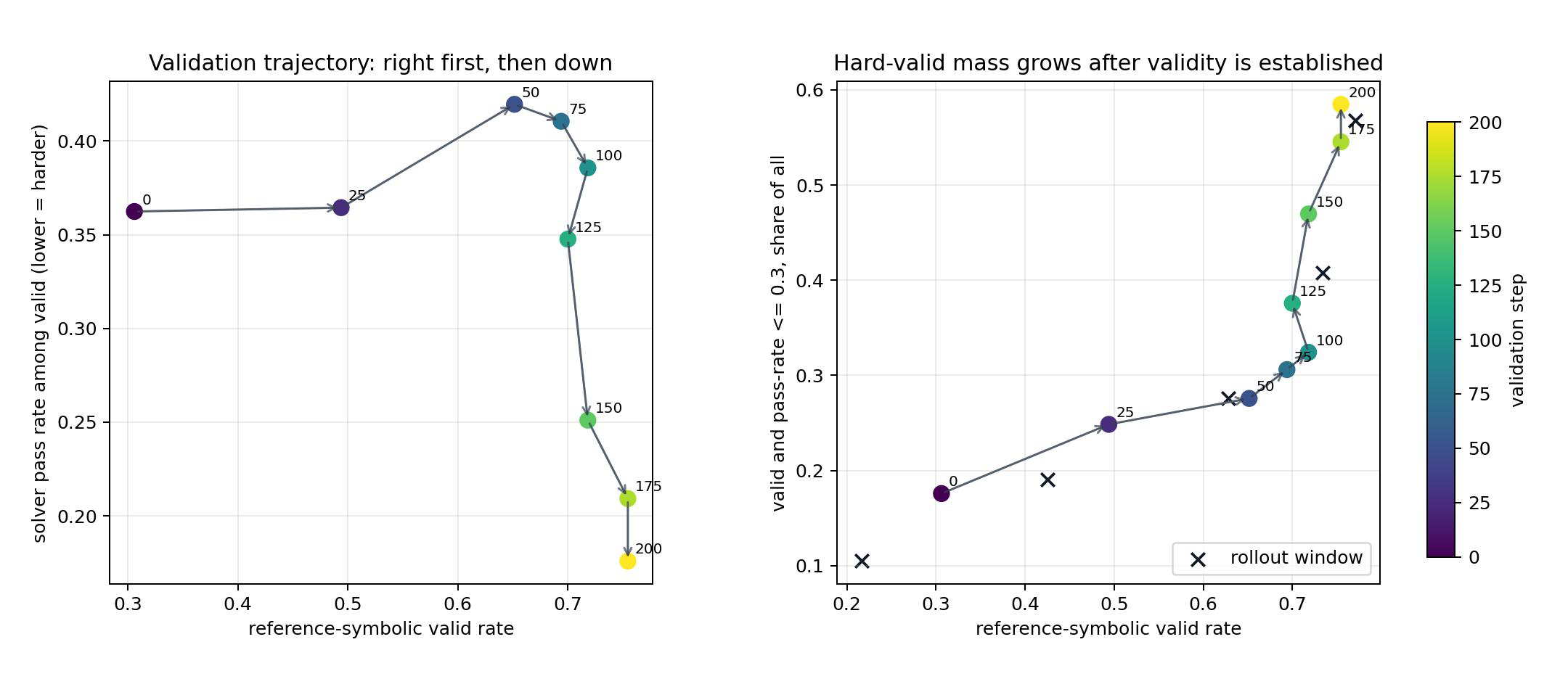
Fig 4: Learning trajectory of the hard-verifier setter on indefinite integral. Validity improves
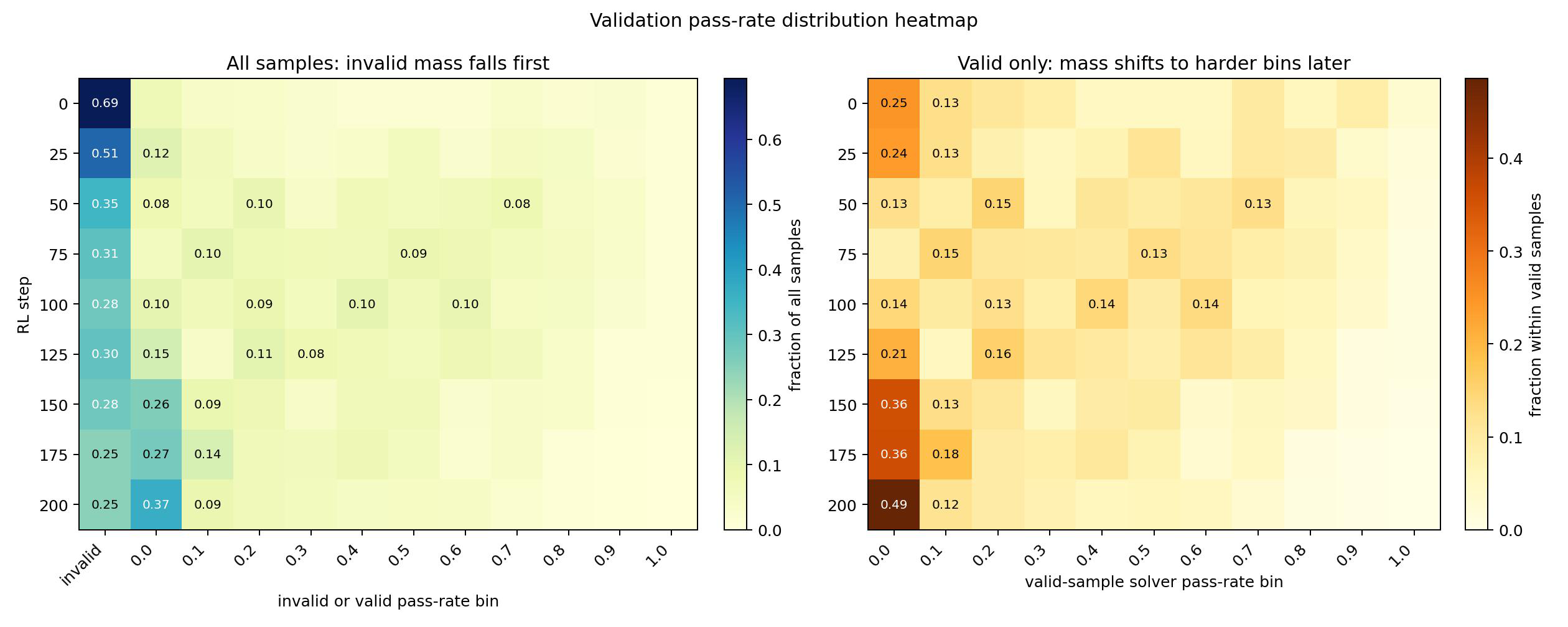
Fig 6: Validation pass-rate heatmap for the hard-verifier setter. Rows correspond to validation
Limitations
- Soft verifier reliability is not quantified: the paper does not report false-positive or false-negative rates for the LLM-as-a-judge on general math, making it unclear how much residual reward hacking persists and how sensitive results are to the choice of judge model.
- Scale is limited to a single 4B backbone for setter and solver; all gains are demonstrated within the Qwen3 family, and it is unknown whether the framework's dynamics (two-phase validity-then-difficulty learning) generalize to other model families or significantly larger setters.
- No adversarial evaluation of the verifier: the paper does not test whether a sufficiently capable setter could learn to produce problems that pass SymPy or the LLM judge while remaining semantically invalid or trivially solvable by other means — a real concern as setter capability scales.
- Distribution shift on GSM8K is acknowledged but not mitigated: training on hard-problem pools explicitly hurts elementary-level performance, raising a question about how VHG-trained solvers would perform in production settings requiring broad coverage across difficulty levels.
- Reproducibility is limited: no code release or model weights are mentioned, the curated integral seed set is not public, and hyperparameters (batch size, learning rate, optimizer) are not reported in the main paper or the truncated appendix sections.
- The 'stronger solver' generalization claim (Table 2) uses only the hardest subset (zero local pass rate) of VHG-generated problems and does not report whether training Qwen3-8B/14B/32B on VHG data actually improves those larger models — only that the problems are hard for them at inference time.
- Evaluation benchmarks for general math include AIME 2024–2026, but AIME 2025–2026 problems may have been partially seen during pretraining of Qwen3 models, and the paper does not discuss or control for this potential contamination.
Open questions / follow-ons
- Verifier robustness at scale: as setter capability increases (larger models, more RL steps), can a fixed SymPy or LLM judge verifier continue to reliably gate validity, or does the setter eventually learn to produce problems that satisfy the verifier's formal criteria while being educationally vacuous or semantically degenerate?
- Weak-to-strong training effectiveness: the paper shows VHG-generated problems are hard for larger models but does not demonstrate that training those larger models on VHG data actually improves their performance — a direct experiment training Qwen3-14B or 32B on 4B-setter-generated data is the natural next step.
- Curriculum scheduling: the two-phase learning dynamic (validity first, then difficulty) suggests that a staged reward schedule or difficulty curriculum might accelerate or stabilize VHG training — the paper does not explore whether explicitly annealing the validity vs. difficulty components of the reward changes outcomes.
- Domain generalization beyond math: the soft verifier mechanism is general in principle, but it is only tested on mathematical reasoning; applying VHG to code generation, formal proofs, or scientific hypothesis generation would test whether the validity-gating principle holds when LLM judges are noisier and domain-specific oracles are less available.
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, VHG is directly relevant as a principled framework for automatically generating challenge questions that are both valid and hard — precisely the dual requirement of a good CAPTCHA or adaptive challenge. The reward-hacking failure mode VHG addresses (a generator earning high reward by producing unsolvable-but-broken challenges rather than genuinely difficult ones) is structurally identical to the failure mode in automated CAPTCHA generation pipelines where difficulty is proxied by bot failure rate without a validity gate. The three-party architecture — setter proposes, verifier gates validity, solver measures difficulty — maps cleanly onto a CAPTCHA generation pipeline where a generator proposes challenges, a ground-truth oracle or rule-checker confirms the challenge is well-formed and has a correct answer, and a bot (or human surrogate model) measures difficulty. The two-phase learning dynamic (validity before difficulty) is also a useful practical signal: any automated challenge generator should be monitored for validity rate before optimizing for difficulty, since the dynamics suggest these objectives are sequentially acquired, not jointly.
The weak-to-strong generalization finding has direct operational implications: a relatively cheap 4B-scale setter can generate problems that remain unsolved by much larger and more capable solver models, suggesting that challenge generation does not need to outpace the attacker at the same capability level. For adaptive CAPTCHA systems that co-evolve with increasingly capable bots, this asymmetry — cheap generator, hard challenge — is economically attractive. The soft verifier design is the relevant branch for most CAPTCHA domains, since symbolic oracles are rarely available for visual or behavioral challenges; the paper's finding that even noisy LLM-judge validation outperforms no validation (R-Zero) is encouraging, though practitioners should independently characterize their judge's false-positive rate before deploying it in a live reward loop.
Cite
@article{arxiv2605_06660,
title={ Verifier-Backed Hard Problem Generation for Mathematical Reasoning },
author={ Yuhang Lai and Jiazhan Feng and Yee Whye Teh and Ning Miao },
journal={arXiv preprint arXiv:2605.06660},
year={ 2026 },
url={https://arxiv.org/abs/2605.06660}
}