
Tatarstan Toponyms: A Bilingual Dataset and Hybrid RAG System for Geospatial Question Answering
Source: arXiv:2605.05962 · Published 2026-05-07 · By Mullosharaf K. Arabov
TL;DR
This paper tackles end-to-end geospatial question answering over bilingual (Russian/Tatar) toponymic data for the Republic of Tatarstan — a domain where standard QA benchmarks like SQuAD and SberQuAD have no coverage of structured geographic records with coordinates and etymology. The core contribution is twofold: (1) a hand-curated, academically sourced dataset of 9,688 toponyms with linguistic, etymological, administrative, and coordinate fields, and (2) a hybrid RAG pipeline that combines dense multilingual semantic retrieval (multilingual-e5-large + FAISS) with geospatial KD-tree/haversine filtering, feeding into fine-tuned extractive reader models. The dataset fills a specific gap in low-resource NLP: no prior machine-readable resource for Tatarstan toponyms existed with simultaneous coordinate georeferencing (93.1% of records) and etymological annotation (~63% of records).
The synthetic QA corpus of ~39,000 triples is generated automatically from the structured dataset using Russian-language question templates with guaranteed character-level answer localization in SQuAD format. This sidesteps the expensive human annotation bottleneck common in QA dataset construction, though it introduces limitations around lexical diversity and naturalness of questions. The hybrid retriever achieves near-perfect recall on a 500-query test set (Recall@1=0.988, Recall@5=1.000, MRR=0.994), decisively outperforming BM25 (Recall@1=0.438) and spatial-only (Recall@1=0.536) baselines. On the reader side, XLM-RoBERTa-large achieves EM=0.992 and F1=0.994 post-normalization, while an interesting tokenization-driven failure mode of RuBERT on coordinate questions (F1=0 on raw output) is diagnosed and remedied with simple post-processing that restores RuBERT accuracy to 100% on coordinates.
All artifacts — dataset, QA corpus, trained weights, and a web demo — are published openly on Hugging Face under CC BY-SA 4.0, making this one of the more reproducibility-complete NLP papers for a low-resource regional language setting. The work is primarily of interest to geospatial NLP, multilingual information retrieval, and digital humanities practitioners, though the hybrid retrieval design and the tokenization failure analysis carry broader transferable lessons.
Key findings
- Hybrid retriever (multilingual-e5-large + KD-tree geospatial filter, α=0.1, R=50km) achieves Recall@1=0.988, Recall@3=1.000, Recall@5=1.000, MRR=0.994 on 500 test queries, vs. semantic-only Recall@1=0.774 and BM25 Recall@1=0.438 — a +0.214 absolute gain over the next-best single method.
- Purely spatial search (haversine nearest-neighbor, no text) achieves Recall@1=0.536, outperforming BM25 (Recall@1=0.438), demonstrating that geographic proximity alone is a stronger signal than lexical matching for multilingual toponymic queries.
- XLM-RoBERTa-large (fine-tuned on the generated corpus) achieves EM=0.992 and F1=0.994 after answer normalization, while RuBERT-based models achieve EM≈0.99 and F1≈1.00 post-normalization on non-coordinate questions but F1=0 on coordinate questions before post-processing.
- Simple numerical post-processing (filling tokenization-induced gaps in coordinate strings) restores RuBERT accuracy on coordinate questions from F1=0 to F1=1.00 (100%), isolating the failure to WordPiece tokenization of decimal numbers rather than any semantic deficiency.
- The optimal hybrid weighting found via grid search on 200 validation queries is α=0.1 (90% weight on geospatial score, 10% on semantic score), suggesting that for this highly localized corpus geographic proximity dominates semantic similarity as a ranking signal.
- Microtoponyms (local landscape elements, n=151 test queries) achieve slightly higher Recall@1=0.993 than full toponyms (n=349, Recall@1=0.986), attributed to lower spatial density of candidates within the 50km radius for small local objects.
- The bilingual toponym dataset contains 9,688 records, 93.1% georeferenced (9,023 with lat/lon), with etymological data in ~63% of records and 76 unique geographical object categories, sourced from peer-reviewed academic dictionaries (Garipova, Sattarov, Akhmetyanov) and the toponym.antat.ru portal.
- The synthetic QA corpus of 38,696 pairs is dominated by coordinate questions (31.9%, n=12,344) and object-type questions (20.8%, n=8,032), with physiographic characteristic questions the rarest (1.6%, n=644) due to sparse field population in source records.
Threat model
n/a — This is not a security paper. The adversarial framing is limited to retrieval robustness: the system must correctly distinguish between toponymically similar objects in close geographic proximity (e.g., multiple villages with the same name within 50km). The pipeline assumes a benign user asking natural-language geographic questions in Russian or Tatar; there is no modeling of adversarial query injection, data poisoning, or attempts to retrieve incorrect geographic information intentionally.
Methodology — deep read
The threat/problem model here is not adversarial in the security sense, but the system is designed to handle a challenging retrieval scenario: queries may arrive in either Russian or Tatar, object names have synonymous variants across both languages, and standard lexical indices fail on cross-lingual synonymy (e.g., 'selo' vs. 'derevnya' for village). The adversarial retrieval case — where similar-sounding toponyms in different geographic locations could confuse purely semantic or purely spatial retrievers — is the key engineering challenge the hybrid design addresses.
Data provenance and construction: The base dataset (9,688 records) was manually curated from academic dictionaries (Garipova's hydronym dictionaries, Sattarov's Tatar toponymy studies, Akhmetyanov's etymological dictionaries), the multi-volume Tatar Encyclopedia, dialectological dictionaries, and the toponym.antat.ru digital portal. This is not a scrape of OpenStreetMap or GeoNames — it is academically vetted. Each record contains: unique ID, source URL, toponym type (toponym vs. microtoponym), subtype (oikonym/hydronym/oronym/none), geographical object category (76 types), name in Russian, name in Tatar, federal subject, physiographic details, geographical location description, etymology, bibliographic sources, latitude, longitude, and map availability flag. Records without coordinates (n=665, 6.9%) are excluded from retrieval experiments but included in QA corpus generation for non-spatial question types. No information is given about inter-annotator agreement or quality checks beyond reliance on academic source authority.
QA corpus generation: For each record, a structured context string is assembled by concatenating all fields with Russian-language labeled prefixes (e.g., 'Название (рус):', 'Этимология:', 'Координаты:') joined by ' | ' separators. If the result exceeds 2048 characters, each field is proportionally truncated while preserving its prefix. Seven question categories are covered by Russian-language templates containing a {name} placeholder; for each category, 2-3 template variants exist (e.g., for coordinates: 'Какие координаты у {name}?' and 'Где на карте находится {name}?'). One template per record per category is selected randomly. The answer is the value of the corresponding field, and the answer_start character offset is computed algorithmically as the cumulative length of all preceding field strings plus the target prefix length — guaranteeing exact SQuAD-format localization without human verification of span correctness. The maximum per-record pair count is capped at 10. The resulting 38,696 pairs are split 90/10 (train: 34,826, val: 3,870) stratified by question type. This is entirely synthetic — no human judgment of question naturalness or answer correctness is reported.
Hybrid retriever architecture: Two parallel indices are maintained. (1) Semantic index: each record's context string is encoded with intfloat/multilingual-e5-large (1024-dim, L2-normalized) and stored in a FAISS IndexFlatIP (exact inner product search); GPU-accelerated when available, batch size 32. At query time, the query is encoded and the top-k documents by dot product are retrieved. (2) Geospatial index: a KD-tree is built over all (lat, lon) pairs. At query time, if a geographic center (lat_q, lon_q) and radius R are provided, a bounding box is computed (Δlat = R/111320, Δlon = R/(111320·cos(φ))), candidate records within the box are retrieved from the KD-tree, and exact haversine distances are computed to filter out candidates exceeding R. The spatial score for remaining candidates is geo_score(i) = exp(-d_i/R). Hybrid ranking: semantic scores are min-max normalized among the geo-filtered candidates; spatial scores are normalized by the maximum among candidates. Final score = α·sem_norm + (1-α)·geo_norm. The hyperparameter α is tuned via grid search over {0.1, 0.3, 0.5, 0.7, 0.9} on a 200-query validation set (disjoint from the 500-query test set) maximizing Recall@5; α=0.1 and R=50km were found optimal. The strong tilt toward geo_score (α=0.1 means 90% weight on spatial) is notable and may be dataset-specific.
Reader training and evaluation: Three model families are fine-tuned for 3 epochs on the 34,826-pair training set: (a) RuBERT (base and large, initialized from SberQuAD checkpoints), (b) XLM-RoBERTa-large (initialized from SQuAD 2.0 checkpoint), and (c) T5-RUS (base, used zero-shot/without fine-tuning due to unspecified 'technical reasons', serving as a reference point only). All extractive models use AdamW, lr=3×10⁻⁵, batch size=4, linear warmup over 500 steps, standard span-prediction head (start/end token classification). T5-RUS uses the 'question: ... context: ... → answer' format. A heuristic keyword-matching baseline (looks for answer by matching question keywords to context prefixes) is also included. Evaluation metrics are Exact Match (EM) and F1 computed on the 3,870-pair validation set. A critical post-processing step normalizes predicted answer strings — specifically reconstructing decimal coordinate strings fragmented by WordPiece tokenization — before computing final metrics. Results are reported both before and after normalization. The coordinate failure of RuBERT (F1=0 raw) is traced to WordPiece splitting of decimal numbers (e.g., '55.205' tokenized as fragments that are not reconstructed correctly as a span), whereas XLM-RoBERTa-large uses SentencePiece which handles numeric strings more robustly. A concrete end-to-end example: the query 'Какие координаты у Рантамак?' is processed — the hybrid retriever encodes the query, retrieves geospatially filtered candidates within 50km of a query point, ranks them by combined score, and passes the top-1 context ('Координаты: 55.205461, 52.881862' embedded in the full context string) to XLM-RoBERTa-large, which extracts the span '55.205461, 52.881862' at answer_start=312.
Reproducibility: Dataset, QA corpus, and trained model weights are published on Hugging Face (TatarNLPWorld organization) under CC BY-SA 4.0. A web demo is also provided. No random seed fixation is mentioned for corpus generation or model training. The validation/test split procedure for the retrieval evaluation (500 test + 200 validation queries drawn from 9,688 records) is described at a high level but the exact sampling seed is not reported. The paper does not report retrieval experiments on queries where the geographic center is unknown (text-only queries), which is how the system would typically be invoked in practice.
Technical innovations
- Hybrid retrieval scheme combining FAISS-indexed multilingual-e5-large semantic scores with KD-tree/haversine geospatial scores via a tunable weighted sum, applied specifically to bilingual (Russian/Tatar) toponymic data — prior work (Galimov et al. 2023, Burnashev et al. 2025) used fuzzy logic with spatial data but not dense embeddings.
- Algorithmically guaranteed character-level SQuAD-format answer localization in a synthetically generated QA corpus by computing answer_start as cumulative field-prefix lengths, eliminating the need for human span annotation while ensuring training signal correctness.
- Empirical diagnosis and correction of WordPiece tokenization failure on decimal coordinate strings in RuBERT (F1=0 on raw coordinate predictions → F1=1.00 after post-processing), with SentencePiece (XLM-RoBERTa-large) identified as the robust alternative for numeric span extraction.
- First openly published machine-readable bilingual dataset of Tatarstan toponyms with simultaneous coordinate georeferencing, etymological annotation, and 76-category geographic object taxonomy, sourced from peer-reviewed academic dictionaries rather than crowdsourced gazetteers.
- English-language field prefixes used in the context concatenation for a Russian/Tatar dataset, motivated by the observation that multilingual-e5-large achieves more robust cross-lingual field matching with English-language keys — a pragmatic multilingual embedding alignment trick not previously documented for this model family in low-resource toponymic settings.
Datasets
- Tatarstan Toponyms Dataset — 9,688 records (9,023 georeferenced) — Original, collected from academic dictionaries (Garipova, Sattarov, Akhmetyanov), Tatar Encyclopedia, and toponym.antat.ru; published on Hugging Face (TatarNLPWorld) under CC BY-SA 4.0
- Tatarstan Toponyms QA Corpus — 38,696 question-context-answer triples (34,826 train / 3,870 val) — Synthetically generated from the above dataset; published on Hugging Face (TatarNLPWorld) under CC BY-SA 4.0
- Retrieval test set — 500 queries (+ 200 validation queries) — Derived from the toponym dataset by the authors; not separately published as a standalone artifact per the paper
Baselines vs proposed
- BM25 (retrieval): Recall@1=0.438 [0.394,0.484], Recall@5=0.618 [0.572,0.662], MRR=0.508 [0.469,0.545] vs. Hybrid: Recall@1=0.988, Recall@5=1.000, MRR=0.994
- Spatial-only (haversine nearest-neighbor, retrieval): Recall@1=0.536 [0.492,0.576], Recall@5=0.796 [0.760,0.830], MRR=0.634 [0.598,0.673] vs. Hybrid: Recall@1=0.988, Recall@5=1.000, MRR=0.994
- Semantic-only (multilingual-e5-large + FAISS, retrieval): Recall@1=0.774 [0.736,0.810], Recall@5=0.940 [0.918,0.960], MRR=0.840 [0.813,0.866] vs. Hybrid: Recall@1=0.988, Recall@5=1.000, MRR=0.994
- RuBERT (reader, raw output, coordinate questions): F1=0.000 vs. XLM-RoBERTa-large raw: F1=0.984
- RuBERT (reader, after post-processing, coordinate questions): F1=1.000 (restored from 0) vs. XLM-RoBERTa-large post-processing: F1 not separately re-stated but EM=0.992 and F1=0.994 overall
- T5-RUS base (not fine-tuned, used as reference): exact metrics not numerically specified in available text — paper describes it as an 'additional reference point'; precise EM/F1 values for T5-RUS not extractable from the truncated full text
- Heuristic keyword-matching baseline (reader): described as implemented but specific EM/F1 values not present in the available text excerpt
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.05962.
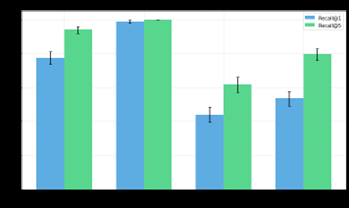
Fig 1: Comparison of Recall@1 and Recall@5 with 95% confidence intervals for BM25, purely spatial, semantic,

Fig 2: Recall@1 of the hybrid method for the “Toponym” and “Microtoponym” categories.
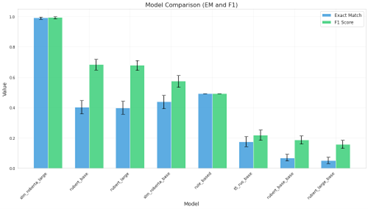
Fig 3: Comparison of models by Exact Match and F1 score after normalization (error bars represent 95% confidence
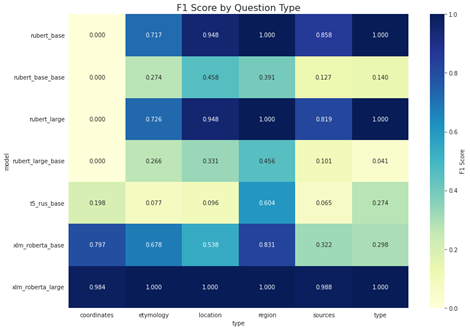
Fig 4: Heatmap of F1 score by question type for fine-tuned models (after normalization). Black cells are absent,
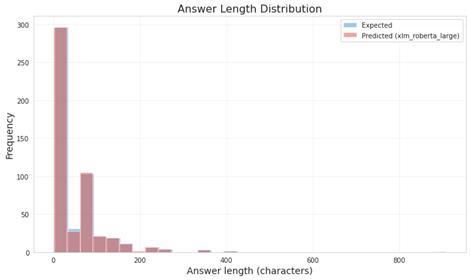
Fig 5: Distribution of answer length (in characters) for reference values and predictions of the xlm_roberta_large
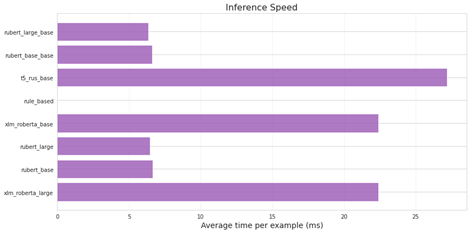
Fig 6: Average processing time per example (ms) for the considered QA models.
Limitations
- Entirely synthetic QA corpus: all 38,696 question-answer pairs are auto-generated from a single template pool per category, producing low lexical diversity and unnatural question phrasing; no human evaluation of question naturalness or answer plausibility is reported.
- The retrieval evaluation assumes the query is accompanied by a known geographic center point (lat_q, lon_q) and radius R; how the system performs on purely text-based queries without geographic coordinates is not evaluated — a significant gap for real-world deployment where users rarely supply explicit coordinates.
- The optimal α=0.1 (90% geospatial weight) is tuned on only 200 validation queries from the same distribution as the test set; generalization to out-of-distribution query types (e.g., etymological queries where spatial proximity is irrelevant) is not tested.
- T5-RUS is not fine-tuned due to unstated 'technical reasons', making the generative baseline comparison incomplete and potentially misleading as a fair architectural comparison.
- Dataset geographic coverage skews heavily toward Tatarstan proper (~93% of records), with only ~4% from Tyumen Oblast and ~3% from adjacent regions; performance on cross-regional queries or Tatar diaspora toponyms outside this footprint is untested.
- No adversarial or out-of-distribution retrieval evaluation: all test queries are generated from the same dataset as the indexed corpus, guaranteeing exactly one relevant document exists. Real users asking about objects not in the dataset, misspelled names, or transliteration variants are not evaluated.
- No inter-annotator agreement, error analysis, or quality audit of the source academic data is reported; the assumption that peer-reviewed dictionary sourcing guarantees data quality is asserted but not validated computationally.
Open questions / follow-ons
- How does the hybrid retriever perform when no geographic center point is available — i.e., purely text-based queries without lat/lon context — and can the geospatial component be replaced with an entity-linking step that infers a candidate region from the query text itself?
- Would the α=0.1 optimal weighting (heavily geospatial) transfer to other multilingual toponymic regions with different spatial density profiles (e.g., dense urban naming in Central Asia vs. sparse rural Siberia), or is this parameter fundamentally corpus-specific?
- Can the RuBERT coordinate tokenization failure mode be addressed at the pre-training level (e.g., by including geospatial corpora with decimal coordinates in continued pre-training) rather than requiring post-hoc string reconstruction heuristics?
- The QA corpus is monolingual Russian in its questions despite the bilingual (Russian/Tatar) dataset — how significantly does adding Tatar-language question templates affect retrieval and reader performance, particularly for cross-lingual queries where the question is in Tatar but the answer context contains Russian field values?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most immediately transferable insight is the tokenization failure analysis: RuBERT's complete inability to extract decimal coordinate strings (F1=0) due to WordPiece fragmentation, correctable with trivial post-processing, is a concrete example of how tokenizer choice creates silent failure modes in span-extraction tasks. Any bot-defense system using extractive QA to parse structured numeric outputs (IP addresses, timestamps, challenge tokens, coordinate-based geofencing) from transformer-based models should audit its tokenizer's behavior on numeric strings before production deployment.
The hybrid retrieval architecture — semantic dense retrieval gated by a hard geospatial filter — is a pattern directly applicable to location-based bot detection: combining behavioral/semantic signals with geographic IP or device location signals in a weighted ranking rather than hard-threshold filtering mirrors this paper's approach. The finding that α=0.1 (geospatial dominates) is optimal for a localized corpus suggests that in a similarly geographically constrained context (e.g., detecting bots targeting region-specific services), a heavily location-weighted hybrid signal may outperform purely behavioral classifiers. However, practitioners should note the paper evaluates only in-distribution queries with guaranteed ground truth; the absence of adversarial evaluation (crafted queries, name spoofing, coordinate manipulation) means the robustness claims do not transfer directly to adversarial bot-defense settings.
Cite
@article{arxiv2605_05962,
title={ Tatarstan Toponyms: A Bilingual Dataset and Hybrid RAG System for Geospatial Question Answering },
author={ Mullosharaf K. Arabov },
journal={arXiv preprint arXiv:2605.05962},
year={ 2026 },
url={https://arxiv.org/abs/2605.05962}
}