
PianoCoRe: Combined and Refined Piano MIDI Dataset
Source: arXiv:2605.06627 · Published 2026-05-07 · By Ilya Borovik
TL;DR
PianoCoRe addresses a persistent bottleneck in computational piano performance research: the fragmentation of existing symbolic music datasets across incompatible formats, narrow composer coverage, missing score alignments, and inconsistent or legally ambiguous metadata. Rather than collecting new recordings, the paper systematically ingests six major open-source piano MIDI corpora (ASAP/(n)ASAP, ATEPP, GiantMIDI-Piano, PERiScoPe, Aria-MIDI, and PDMX scores), resolves cross-dataset identity collisions at the musical-work level, and outputs a four-tier unified collection totaling 250,046 performances of 5,625 pieces by 483 composers (21,763 hours). The legal grounding is explicit: only EU public-domain works are included, making PianoCoRe more legally stable than predecessors that draw on contemporary competitions or copyrighted editions.
The core technical contributions beyond aggregation are a MIDI quality classifier and a pipeline called RAScoP (Refined Alignment for Scores and Performances). The quality classifier distinguishes four classes — score-like, high-quality, low-quality, and corrupted — trained on heuristically labeled data derived from deduplication signals and alignment ratios, enabling the filtered PianoCoRe-B subset. RAScoP operates on pre-computed note-level alignments from Parangonar's DualDTWNoteMatcher and post-processes them to remove local timing outliers (e.g., crossed-onset errors where adjacent notes swap temporal order) and interpolate missing performed notes from the score, yielding the note-aligned PianoCoRe-A/A* subsets. PianoCoRe-A provides 157,207 score-aligned performances — the largest such open-source collection reported to date.
A downstream evaluation using an expressive performance rendering model trained on PianoCoRe versus smaller or noisier subsets shows improved generalization to unseen pieces, though the evaluation is not a full ablation across all tiers and the rendering model architecture is borrowed rather than novel. The dataset is archived on Zenodo and mirrored on Hugging Face, with MusicXML and MIDI scores, refined MIDI performances, compressed .npz alignment files, and per-file quality label probabilities.
Key findings
- PianoCoRe-A contains 157,207 note-aligned score-performance pairs covering 1,591 unique scores — described as the largest open-source note-aligned piano MIDI collection to date, compared to (n)ASAP's 1,067 performances across 222 scores.
- PianoCoRe-C (complete, unfiltered) contains 250,046 performances of 5,625 pieces by 483 composers totaling 21,763 hours; the deduplicated PianoCoRe-B retains 214,092 performances (18,757 hours) after quality filtering.
- The Numba JIT-optimized DTW alignment runs approximately 12× faster than the unoptimized DualDTWNoteMatcher on the ASAP dataset, making millions of pairwise alignments computationally feasible.
- 5,501 Aria-MIDI files and 92 PERiScoPe files contained 'infinite pitch' transcription artifacts (notes spanning to end-of-file due to unmatched note-on/off events); these were detected and corrected algorithmically.
- The content-based deduplication heuristic uses a 50 ms onset-proximity threshold and 50% note-overlap criterion for clustering; one 'lead' file per cluster is retained, prioritizing recorded over transcribed sources.
- RAScoP's refinement demonstrably reduces temporal noise and eliminates tempo outliers in aligned performances, as shown qualitatively in the paper's figures (Fig. 4 shows before/after alignment crossing errors; Fig. 5 illustrates the pipeline steps).
- The median number of performances per piece in PianoCoRe-C is 8 and the mean is 44; 1,104 pieces have 50 or more performance samples, supporting data-hungry modeling tasks.
- An expressive performance rendering model trained on PianoCoRe shows improved robustness on unseen pieces relative to models trained on raw or smaller individual datasets (exact metric values not specified in the truncated text).
Methodology — deep read
The construction pipeline operates in three conceptually distinct phases: source ingestion and identity resolution, quality filtering and deduplication, and alignment refinement.
Phase 1 — Data Matching and Identity Resolution. The challenge is that six source datasets use incompatible naming conventions, contain overlapping content, and vary in metadata completeness. Rather than relying on title-matching alone (fragile due to mislabeling and transliteration differences), the paper employs MIDI-to-MIDI note alignment as the ground-truth matching signal. MusicXML scores are first converted to MIDI via the partitura library with four non-trivial preprocessing steps: (a) dynamics and tempo markings from <sound> tags are embedded as MIDI velocity and tempo change events; (b) trills and mordents are unrolled using invisible cue notes from MusicXML; (c) grace notes are expanded per acciaccatura/appoggiatura definitions; (d) two repeat-unfolded versions (maximal and minimal) are generated per score. Candidate score-performance pairs are pre-filtered by composer name, note-ratio proximity (0.75 ≤ Rn ≤ 1.33), and catalog/key keyword matching to avoid O(N²) alignment cost. Surviving candidates are aligned with DualDTWNoteMatcher (Parangonar library), JIT-compiled via Numba for a reported 12× speedup. A candidate is confirmed as a match if alignment recall Ra > 0.7. Performances failing against the maximal repeat version are re-tested against the minimal version to recover additional matches. The process is iterative: ASAP and ATEPP are merged first, then public-domain scores (PDMX, KunstderFuge, ClassicalMIDI, and 421 manually sourced MuseScore files) are added, then the three large transcribed collections (GiantMIDI, PERiScoPe, Aria-MIDI) are integrated by matching against existing scores and then against each other for piece-level linkage even when no score is available. Automated matches for new pieces were manually verified against IMSLP.
Phase 2a — Deduplication. For each piece with multiple performances, pairwise similarity is computed: notes are sorted, onset-shifted to zero, and grouped by pitch. For two performances x and z, the fraction of pitch-matched note pairs with |onset_x − onset_z| ≤ 50 ms is computed bidirectionally, taking the maximum direction score. Pairs exceeding 50% similarity are clustered; one 'lead' file per cluster is retained, with a priority ordering favoring recorded (ASAP) over transcribed sources.
Phase 2b — Quality Classification. A MIDI quality classifier assigns one of four labels: 'score' (inexpressive, notated-music-like), 'high quality', 'low quality', or 'corrupted'. Labels for training are derived from a heuristic combining alignment-ratio signals and deduplication evidence (exact feature set and model architecture are described in Section 4 of the paper, which is partially truncated in the provided text — the feature-based validation loss curve is referenced as a figure). The classifier enables creation of PianoCoRe-B by filtering out corrupted and score-like files. The paper notes that ATEPP's existing quality labels miss some corrupted files (validated by re-running the classifier on ATEPP), motivating the new classifier.
Phase 3 — RAScoP Alignment Refinement. Raw Parangonar alignments contain local timing errors — most critically, 'crossed onsets' where two adjacent aligned notes have swapped temporal ordering relative to the score (visible in Fig. 4 top). RAScoP applies two corrections: (H) a heuristic outlier removal step that detects and removes temporally inconsistent note pairs from the alignment, and (O) an interpolation step that inserts missing score notes into the performance MIDI as synthetic note events (annotated via MIDI markers to distinguish real from interpolated notes). The combined H+O pipeline is evaluated against the H-only and O-only variants; Fig. 4 (bottom) shows that applying the full H+O pipeline significantly reduces temporal noise. Refined alignments are stored as _refined_align.npz files, and the cleaned performances as separate MIDI files with marker annotations.
Downstream Evaluation. An expressive performance rendering model (architecture not novel to this paper — borrowed from prior work) is trained on PianoCoRe and compared against models trained on individual source datasets or unrefined data. The evaluation metric appears to be generalization performance on unseen pieces, though the exact metric (e.g., held-out log-likelihood, note-level IOI prediction error) and test set composition are not fully detailed in the truncated text. The paper reports qualitatively improved robustness but does not provide a comprehensive ablation across all four tiers.
Reproducibility. The dataset is released on Zenodo and Hugging Face. Code for the preprocessing pipelines (score conversion, alignment, RAScoP, quality classifier) is implied to be available alongside the dataset, but explicit mention of a frozen code release or versioned model weights for the quality classifier is not confirmed in the available text. The dataset itself is versioned (source datasets cited at specific version numbers, e.g., (n)ASAP v2.1.1, ATEPP v1.2, Aria-MIDI v1).
Technical innovations
- A MIDI quality classifier trained on heuristically labeled data derived from alignment ratios and deduplication signals, capable of distinguishing four classes (score-like, high-quality, low-quality, corrupted) — prior work such as ATEPP's quality labels and GigaMIDI's NOMML heuristic addressed a subset of these classes without a trained classifier.
- RAScoP, a two-stage alignment post-processing pipeline that removes crossed-onset temporal errors from DTW-based note alignments (H step) and interpolates missing score notes into performances as annotated synthetic events (O step), enabling complete note-to-note coverage required for performance rendering models.
- A Numba JIT-compiled wrapper for the DualDTWNoteMatcher that achieves approximately 12× speedup on the ASAP benchmark, making millions of pairwise MIDI-to-MIDI alignment checks computationally tractable at dataset-construction scale.
- A content-based MIDI deduplication heuristic using bidirectional pitch-conditioned onset proximity scoring (50 ms threshold, 50% overlap criterion) that operates directly on note events without requiring audio fingerprinting or metadata matching.
- A unified four-tier dataset architecture (C/B/A/A*) with a standardized IMSLP-aligned directory hierarchy, enabling downstream users to select the appropriate quality-vs-scale tradeoff without reformatting, and covering 483 composers versus the 16–82 covered by predecessors with note-aligned subsets.
Datasets
- PianoCoRe-C — 250,046 performances, 5,625 pieces, 483 composers, 21,763 hours — constructed by authors, archived on Zenodo/Hugging Face
- PianoCoRe-B — 214,092 performances, 5,591 pieces, 478 composers, 18,757 hours — deduplicated/quality-filtered subset of PianoCoRe-C
- PianoCoRe-A — 157,207 performances, 1,591 scores, 151 composers, 12,509 hours — note-aligned subset
- PianoCoRe-A* — 130,275 performances, 1,517 scores, 137 composers, 10,330 hours — high-quality note-aligned subset
- (n)ASAP v2.1.1 — 1,067 performances, 222 scores, 92 hours — https://github.com/CPJKU/asap-dataset
- ATEPP v1.2 — 11,742 performances, 1,596 pieces, 1,009 hours — https://github.com/BetsyTang/ATEPP
- GiantMIDI-Piano (curated subset) — 7,236 files used, 1,237 hours total — https://github.com/bytedance/GiantMIDI-Piano
- PERiScoPe v1.0 — 46,473 performances, 2,738 pieces, 3,784 hours — prior work by same first author
- Aria-MIDI v1 — 1,186,253 total files, 621,132 with composer metadata used — https://github.com/EleutherAI/aria-midi
- PDMX — public domain MusicXML scores sourced from MuseScore — https://github.com/pnlong/PDMX
Baselines vs proposed
- (n)ASAP: note-aligned performances = 1,067 across 222 scores vs PianoCoRe-A: 157,207 performances across 1,591 scores
- PERiScoPe: note-aligned pairs ≈ 35,000+ vs PianoCoRe-A: 157,207
- ATEPP quality labels: misses some corrupted files (confirmed by re-running PianoCoRe classifier on ATEPP) vs PianoCoRe classifier: detects previously unlabeled corrupted transcriptions
- Unoptimized DualDTWNoteMatcher: baseline alignment speed vs Numba JIT version: ~12× faster on ASAP dataset
- Performance rendering model trained on raw/smaller datasets: lower robustness on unseen pieces vs model trained on PianoCoRe: improved generalization (exact metric values not reported in available text)
- RAScoP H-only vs H+O: full pipeline (H+O) significantly reduces temporal noise and eliminates tempo outliers per Fig. 4 analysis (quantitative delta not extracted from truncated text)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06627.

Fig 1: The three-stage data matching and annotation pipeline used to create PianoCoRe dataset.

Fig 5: Real-world alignment challenges motivating the RAScoP pipeline. Top: local timing errors (crossed

Fig 6: Note-level alignment and the RAScoP pipeline for alignment refinement. The processing steps are
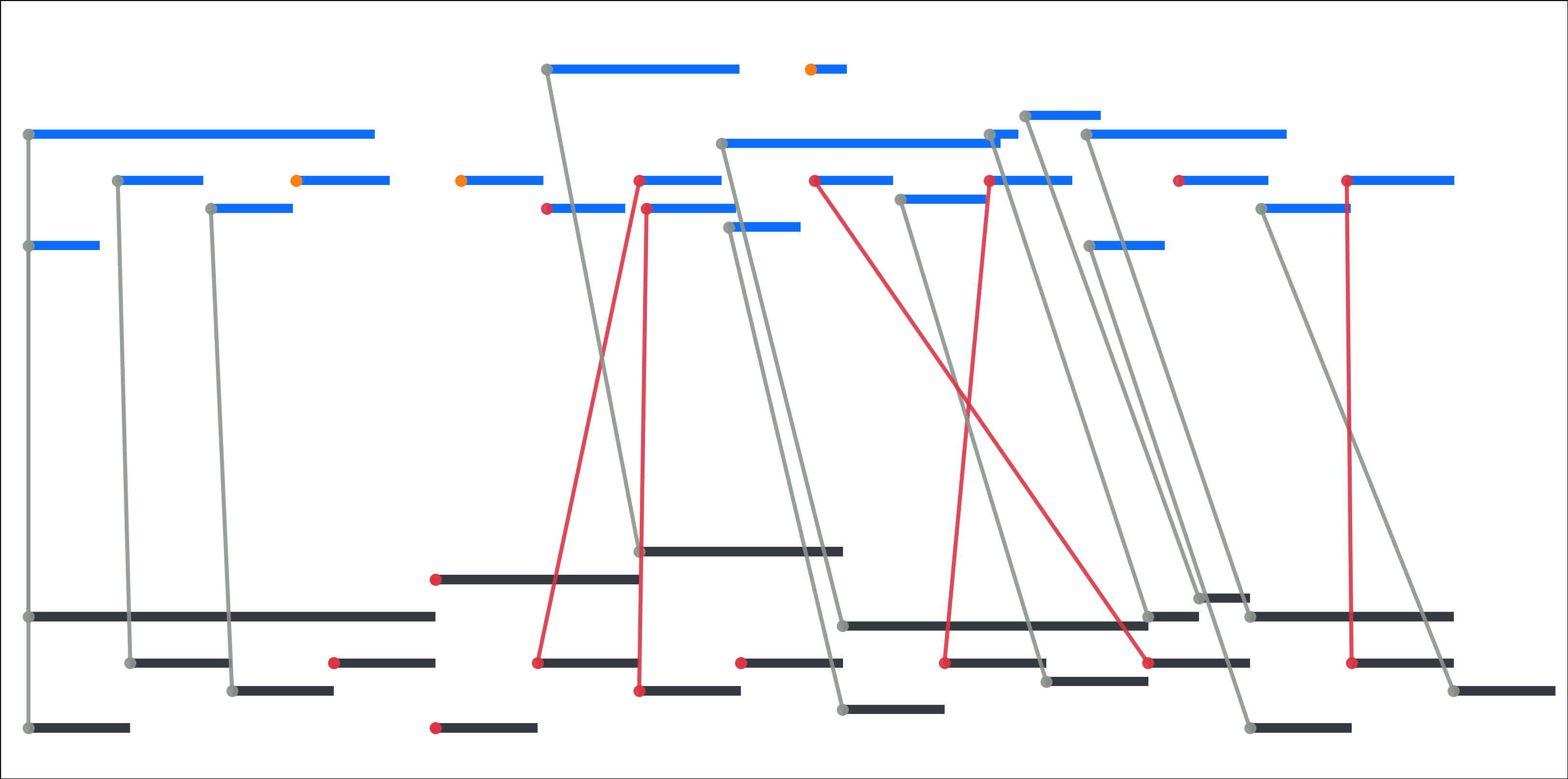
Fig 7: Applying the full pipeline (H+O) signifi-
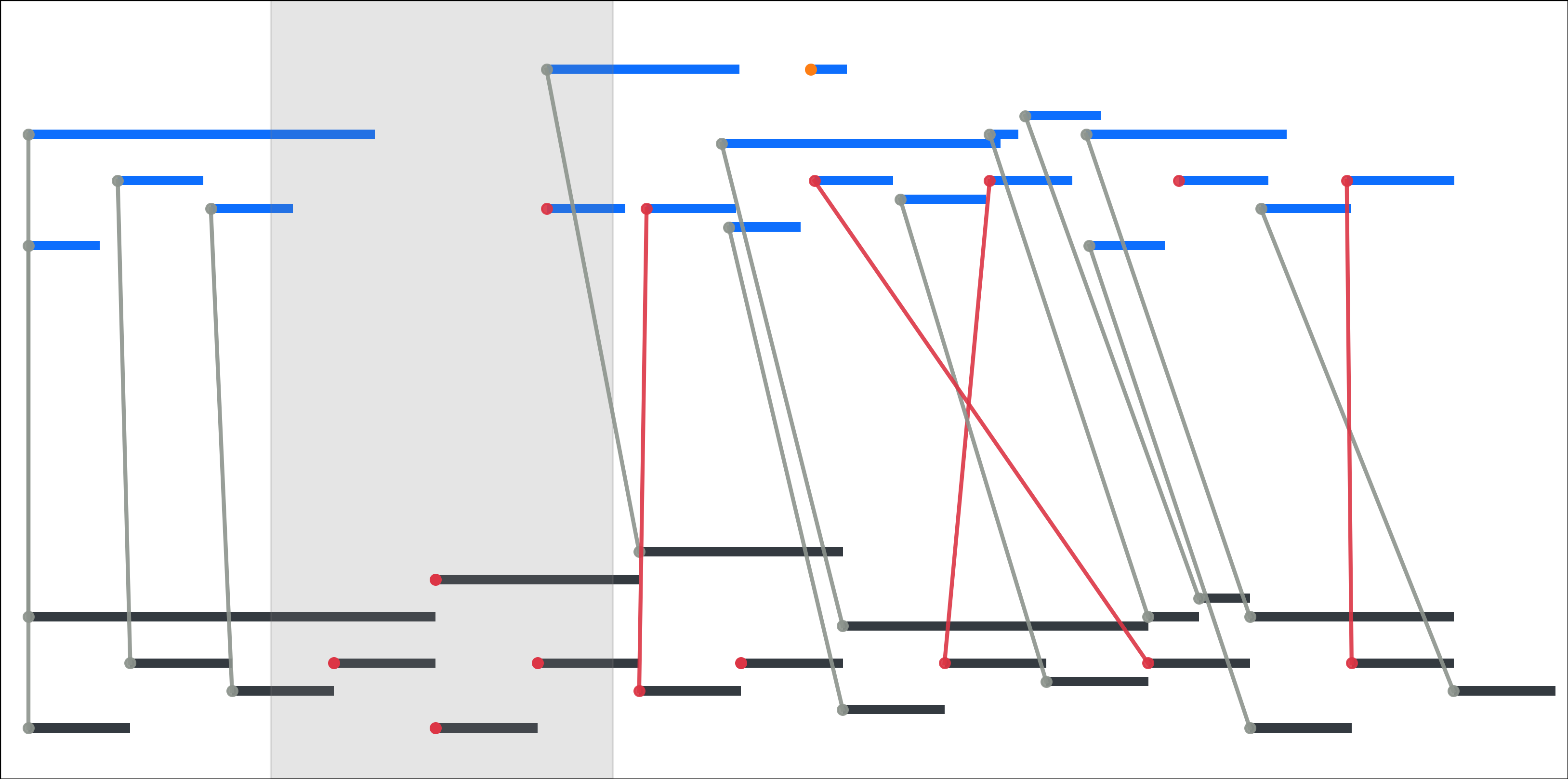
Fig 8: illustrates the feature-based validation losses

Fig 6 (page 12).
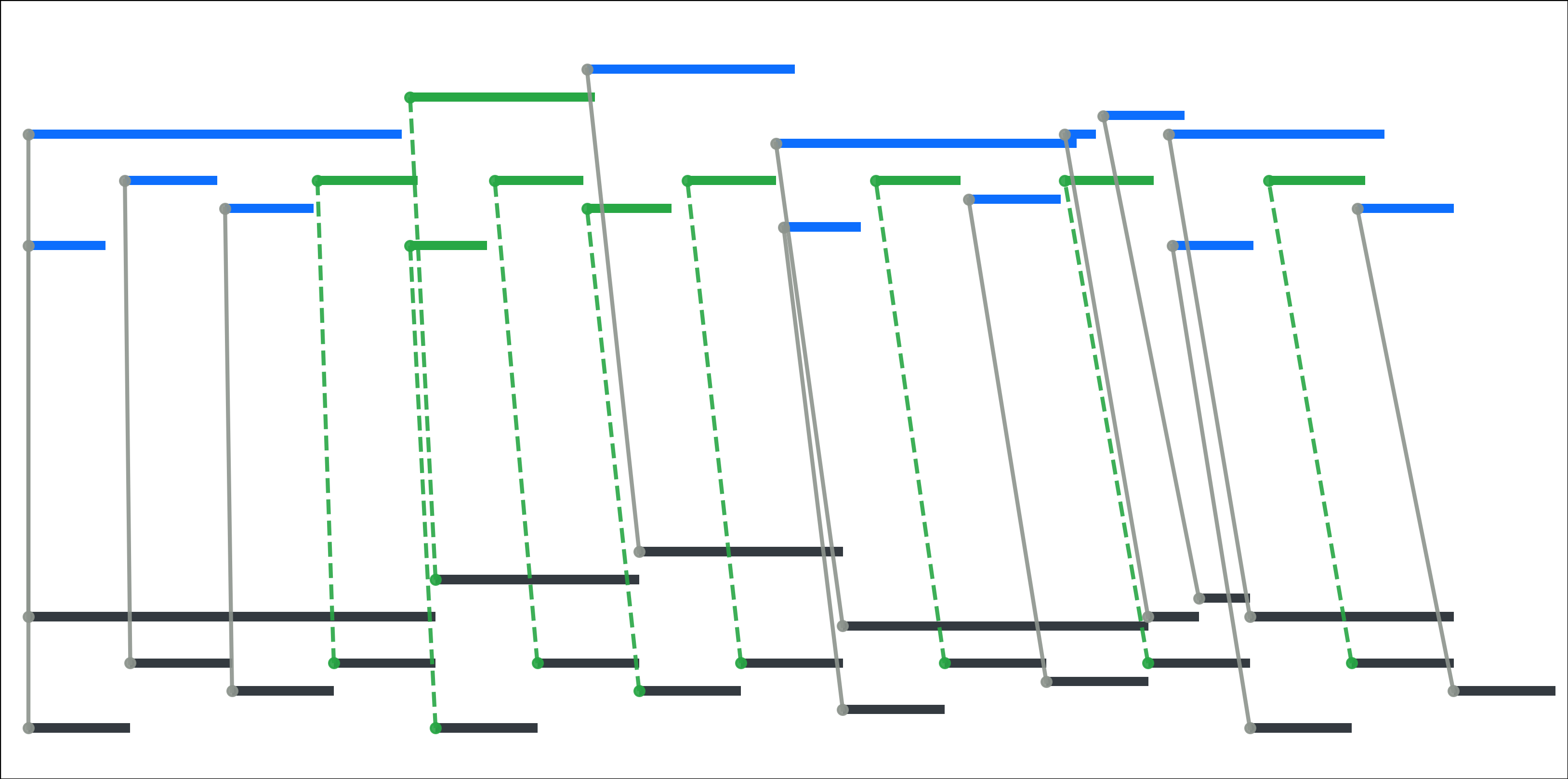
Fig 7 (page 12).
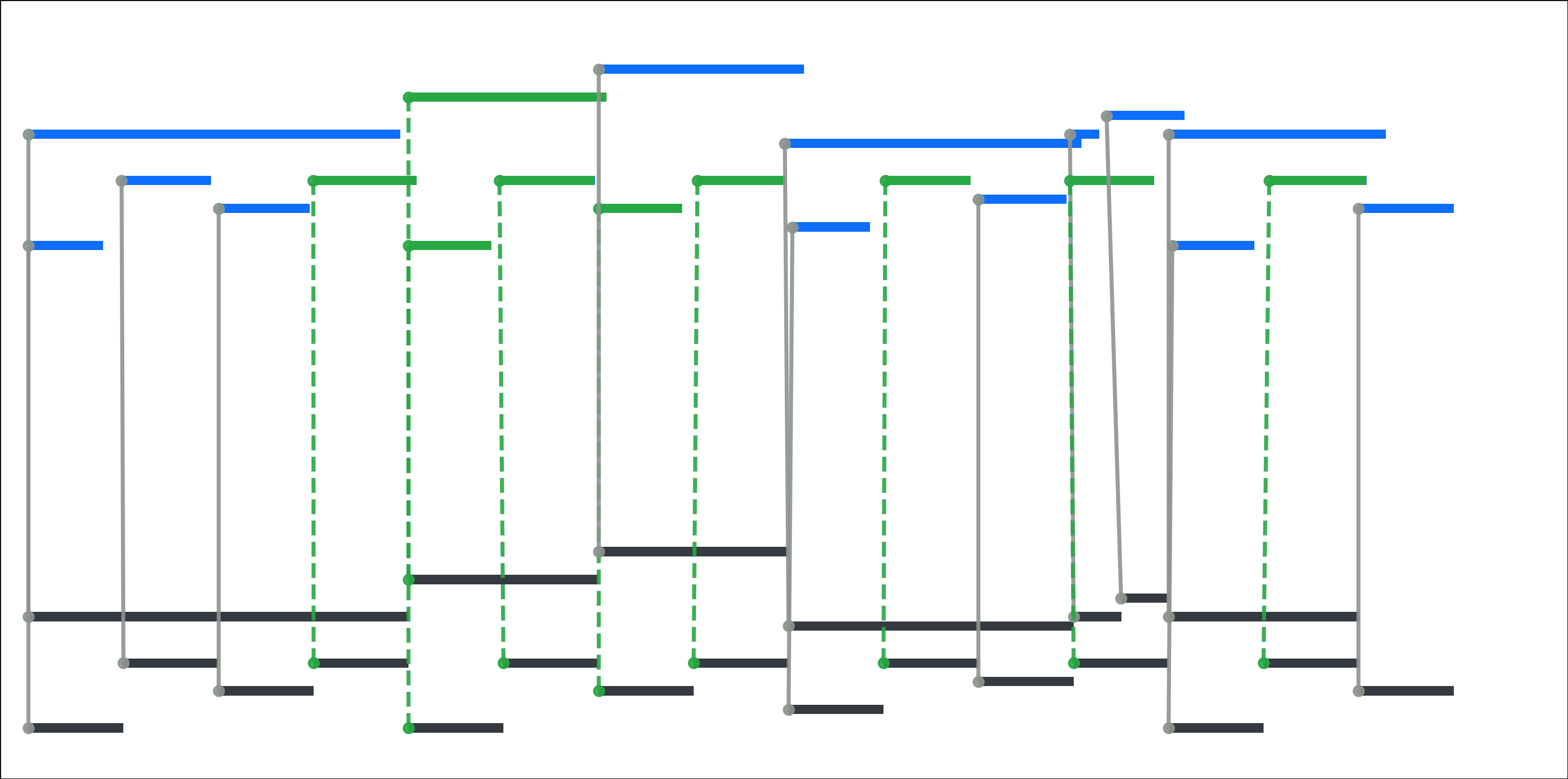
Fig 8 (page 12).
Limitations
- The downstream rendering model evaluation is qualitative or incompletely reported in the available text — no specific metric values (e.g., IOI prediction MSE, velocity correlation) or statistical significance tests are provided, making it difficult to independently verify the claimed generalization improvement.
- The four-tier dataset structure means that the note-aligned PianoCoRe-A covers only 151 composers and 1,591 scores, a small fraction of the full 483-composer, 5,625-piece PianoCoRe-C; the majority of performances in the largest tiers lack alignment and are therefore unsuitable for score-conditioned modeling tasks.
- RAScoP's interpolation of missing notes introduces synthetic note events into performance MIDIs, which could corrupt expressive feature distributions if users do not carefully filter on the MIDI marker annotations distinguishing real from interpolated notes; the paper acknowledges this via the annotation scheme but downstream misuse is a real risk.
- Aria-MIDI contributes the most raw volume but has non-standard sustain pedal encoding (durations predicted as sustained, not distinguishing pressed vs. pedal-sustained duration), which may introduce systematic bias in velocity/duration modeling for that subset.
- GiantMIDI-Piano integration is restricted to 2,139 files that could be matched against other datasets' scores — the majority of GiantMIDI's 10,855 files are excluded due to inability to verify identity, meaning a large potential corpus is unused.
- The MIDI quality classifier's training labels are derived from heuristics rather than human annotation, introducing circular dependency: the classifier learns to reproduce algorithmic signals rather than a true human-perceptual quality standard.
- No adversarial or out-of-distribution evaluation of the quality classifier is reported — it is unclear how the classifier performs on genres or recording conditions not represented in the training heuristics (e.g., jazz transcriptions, contemporary compositions near the public domain cutoff).
Open questions / follow-ons
- RAScoP interpolates missing notes but does not recover the expressive parameters (velocity, timing) of those notes — can a learned model predict plausible expressive values for interpolated notes rather than using score defaults, and how does this affect downstream rendering quality?
- The quality classifier is trained on alignment- and deduplication-derived heuristic labels; would human perceptual annotation of a held-out sample reveal systematic failure modes, and could active learning close that gap efficiently given the dataset scale?
- The dataset is restricted to EU public-domain works (composers deceased 70+ years), which excludes 20th-century modernist repertoire central to contemporary performance research — can a legally compliant extension strategy (e.g., licensed contemporary datasets) be developed that preserves long-term stability?
- PianoCoRe-A provides note-level alignments but the exact repeat structure of performances is not detected — developing a repeat-structure inference module could further improve alignment recall and enable beat-level structural analysis across the full 157K-performance aligned subset.
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, PianoCoRe is not directly applicable as a security dataset. However, it is tangentially relevant in two respects. First, the MIDI quality classifier architecture — a trained model that distinguishes human-expressive performances from mechanical/score-like playback and corrupted transcriptions — is structurally analogous to bot-vs-human behavioral classifiers. The challenge of detecting 'score-like' MIDI (too regular, lacking human timing variance) mirrors the challenge of detecting scripted or automated user interactions that lack natural behavioral noise. The feature engineering approach (alignment ratios, note-level timing statistics) could inform feature design for behavioral biometric systems.
Second, the deduplication heuristic based on onset-proximity clustering bears resemblance to session deduplication problems in web traffic analysis, where near-identical interaction traces from bot farms must be identified across slightly varied timing signatures. The 50 ms threshold and bidirectional similarity scoring are simple but principled choices that a bot-defense engineer might adapt for detecting replayed or slightly perturbed interaction sequences. Neither application is the paper's intent, and practitioners should treat any such transfer with caution — the MIDI domain has significantly different noise characteristics than web interaction logs.
Cite
@article{arxiv2605_06627,
title={ PianoCoRe: Combined and Refined Piano MIDI Dataset },
author={ Ilya Borovik },
journal={arXiv preprint arXiv:2605.06627},
year={ 2026 },
url={https://arxiv.org/abs/2605.06627}
}