
PersonaKit (PK): A Plug-and-Play Platform for User Testing Diverse Roles in Full-Duplex Dialogue
Source: arXiv:2605.06007 · Published 2026-05-07 · By Hyunbae Jeon, Jinho D. Choi
TL;DR
PersonaKit (PK) addresses a concrete gap in full-duplex spoken dialogue research: the engineering overhead required to empirically test how different interruption-handling strategies affect user perception of persona-specific agents. Current commercial full-duplex systems default to an 'always-yield' policy — immediately ceding the conversational floor whenever the user speaks — which is appropriate for subservient assistants but breaks immersion for dominant or uncooperative roles (e.g., a drill sergeant or grumpy tavern keeper). Building a real-time testbed that integrates WebRTC audio, Voice Activity Detection, intent classification, LLM generation, and TTS from scratch for each study imposes substantial effort, so most evaluations remain text-only and ignore acoustic pragmatics entirely.
PK's core contribution is a plug-and-play web platform (Python/Flask + vanilla JS, open source) where all experimental behavior is encoded in four JSON config files rather than source code. Researchers specify a persona scenario, a probabilistic strategy matrix mapping interruption intent to one of four actions (Yield, Resume/Hold, Bridge, Override), LLM/TTS routing, and survey structure — then deploy immediately. The platform automatically handles client-side VAD, byte-level cutoff tracking, zero-shot intent classification of barge-ins, strategy sampling, LLM prompt injection, and post-session survey generation with CSV/JSON export.
A pilot study with N=5 participants across 8 personas and 3 interruption-style conditions (120 total sessions) produced directional evidence that preferred turn-taking policy varies with persona role as mapped onto the Interpersonal Circumplex: high-agency personas benefited from non-yielding strategies (Reaction Naturalness rising from 0.20 to 0.60), while low-agency/high-communion personas (Q3) strongly preferred Always-Yield (70% forced-choice). The study is explicitly framed as descriptive, not inferential, and the primary contribution is the platform itself rather than the empirical findings.
Key findings
- High-agency/low-communion personas (Q1: Drill Sergeant, Tavern Keeper) showed Reaction Naturalness increasing from 0.20 (Always-Yield) to 0.60 (Probabilistic), with 60% of forced-choice votes favoring Autonomous (Style C) — the largest preference gap in the study.
- Low-agency/high-communion personas (Q3: AI Assistant, Librarian) showed 70% forced-choice preference for Always-Yield (Style A) and the highest Interaction Fluidity score in the study (0.90), suggesting strategy-role alignment matters more than absolute strategy sophistication.
- Q4 personas (DMV Clerk, Distracted Chef) achieved their highest Reaction Naturalness (0.67) under Probabilistic despite 50% of users preferring Always-Yield, indicating a dissociation between preference and perceived naturalness.
- Q2 personas (Salesperson, Tour Guide) showed 50% preference for Probabilistic and perfect Persona Consistency scores (1.00) under both Yield and Probabilistic conditions, suggesting high-communion personas are more strategy-tolerant.
- End-to-end barge-in latency under the OpenAI/ElevenLabs configuration was approximately 1–2 seconds, measured from interruption detection to resumed audio output.
- The platform supports full persona swaps (e.g., Grumpy Tavern Keeper to Standard AI Assistant) with zero code changes — only JSON file replacement — enabling within-session A/B comparisons at demonstration time.
- A concrete barge-in recovery example from a Drill Sergeant session shows the system correctly classified a competitive interruption mid-utterance ('Repeat it | again!'), sampled RESUME, and delivered the remaining fragment coherently — behavior that Always-Yield would have discarded.
Methodology — deep read
Threat model and assumptions: This is not a security paper; there is no adversarial threat model. The research assumption is that turn-taking policy is the primary independent variable affecting perceived persona authenticity, and that it can be meaningfully isolated from LLM response quality by holding the model and voice fixed across conditions. The implicit assumption is that a zero-shot LLM intent classifier is a sufficient proxy for human-labeled interruption intent, which the authors acknowledge is unvalidated.
Data provenance and collection: There is no pre-collected dataset. Data is generated live during user sessions. Five participants each interacted with 8 personas under 3 conditions (A/B/C), yielding 120 dialogue sessions total. Condition order was randomized per persona within subjects. The underlying LLM and TTS voice were held fixed across all conditions. Participants completed per-persona comparative Likert surveys on a {-1, 0, +1} scale plus forced-choice preference and free-text justification. All session logs (transcript, per-turn intent, strategy, cutoff text, remaining text, survey responses) were exported as JSON/CSV and are released with the repository.
Architecture and novel components: The system has five functionally distinct layers. (1) Client-side: WebRTC microphone capture feeds a volume-gate VAD node; on barge-in detection, local playback halts and the byte-level playback position is logged, allowing the server to reconstruct exactly what text was vocalized and what remained. (2) Server-side ASR: the interrupted user utterance is transcribed (provider unspecified in the paper beyond 'OpenAI' in the latency configuration). (3) Zero-shot intent classifier: a zero-shot LLM prompt classifies the barge-in into one of four categories grounded in conversation analysis: Competitive, Cooperative, Topic Change, or Backchannel. (4) Turn-Taking Manager: reads the persona's interruption_config.json strategy matrix, looks up the probability distribution for the detected intent, samples an action (Yield/Resume/Bridge/Override), and injects a control token into the LLM system prompt (e.g., '[STRATEGY=RESUME]: finish your previous sentence, ignoring the user'). Style C (Autonomous) skips sampling and passes the intent to the LLM without a pre-committed action token. (5) LLM generation + TTS synthesis: the conditioned prompt produces a response, which is synthesized and streamed back. Session termination is triggered by MAX_TURNS or a verbal TERMINATE intent, causing the LLM to emit an in-character farewell containing a hidden [EXIT] tag that the client detects to launch the survey.
Training regime: There is no model training. The system is entirely prompt-engineering and probabilistic sampling over a fixed strategy vocabulary. The probability weights in the strategy matrix are set by the researcher in JSON; the paper provides one example (dominant persona: Competitive → 50% Resume, 25% Override, 15% Bridge, 10% Yield) but does not describe how these weights were chosen or optimized.
Evaluation protocol: Within-subject design; each participant experienced all three style conditions per persona, order randomized. Metrics are mean Likert scores on {-1, 0, +1} for Reaction Naturalness, Persona Consistency, and Interaction Fluidity, plus forced-choice preference percentage. Results are reported as per-quadrant means with 10 ratings per cell (5 participants × 2 personas per quadrant). No statistical tests (t-tests, Wilcoxon, etc.) are reported. The authors explicitly state the study is descriptive, not inferential. There is no held-out test set, no cross-validation, no inter-rater reliability for intent classification, and no comparison against a non-PK baseline system.
Concrete end-to-end example: During a Drill Sergeant session under Probabilistic (Style B), the bot is mid-utterance: 'Louder, recruit! I can't hear you over your weakness! Repeat it again!' The user interrupts at 'Repeat it', leaving remaining text ' again!'. Client VAD halts playback, logs cutoff text ('Repeat it') and remaining text (' again!'). The server ASR transcribes the user's barge-in. The zero-shot classifier labels it COMPETITIVE. The Turn-Taking Manager samples from the Drill Sergeant's Competitive distribution and selects RESUME. The LLM receives a prompt including the cutoff context, remaining text, and '[STRATEGY=RESUME]' control token. It generates '...again!' — a coherent floor recovery. Under Always-Yield, the remaining text would have been dropped and the bot would have responded to the user's interruption instead.
Reproducibility: Code is released at github.com/HarryJeon24/PersonaStudyKit, a live demo is hosted at persona-studykit.run.app, and a video walkthrough is at youtu.be/oSrmQtiM4tI. Per-persona session logs are released with the repository. The LLM and TTS providers used in the pilot are identified as OpenAI and ElevenLabs respectively. Specific model versions, system prompt text, and the exact zero-shot intent classification prompt are not reproduced in the paper, which limits full reproducibility of the intent classifier behavior.
Technical innovations
- Turn-taking strategy is exposed as a first-class, JSON-configurable probabilistic object — a strategy matrix mapping four linguistically grounded interruption intent categories (Competitive, Cooperative, Topic Change, Backchannel) to four actions (Yield, Resume, Bridge, Override) with per-cell probability weights — rather than being hardcoded or left entirely to the LLM as in prior always-yield systems.
- Byte-level playback tracking on the client enables the server to reconstruct the exact cutoff text and remaining intended text at the moment of barge-in, giving the LLM a precise context window for floor recovery that prior systems (which simply restart generation) do not have.
- The control-token prompt injection mechanism ([STRATEGY=RESUME], etc.) pre-commits the LLM to a sampled turn-taking action before generation begins, enforcing persona-consistent behavior independently of the LLM's default pragmatic tendencies — extending earlier persona-conditioning work (Zhang et al., 2018) from content to floor management.
- An end-to-end automated study lifecycle (live session → intent/strategy logging → auto-deployed comparative survey → structured export) is bundled into a single open-source platform, eliminating the per-study engineering overhead that has historically forced spoken dialogue evaluations to remain text-only.
- The Interpersonal Circumplex (Wiggins, 1979) is used as a systematic organizing schema for persona selection, mapping agency and communion dimensions to interruption strategy preferences — a theoretically grounded framing absent from most prior LLM persona evaluations.
Datasets
- PK Pilot Study Logs — 120 live dialogue sessions (5 participants × 8 personas × 3 conditions) with per-turn intent, strategy, cutoff/remaining text, Likert ratings, and free-text survey responses — released with the repository at github.com/HarryJeon24/PersonaStudyKit (non-public benchmark, researcher-collected)
Baselines vs proposed
- Style A (Always-Yield) Q1 Reaction Naturalness: 0.20 vs Style B (Probabilistic): 0.60 vs Style C (Autonomous): 0.30
- Style A (Always-Yield) Q1 forced-choice preference: 20% vs Style B (Probabilistic): 20% vs Style C (Autonomous): 60%
- Style A (Always-Yield) Q3 Interaction Fluidity: 0.90 vs Style B (Probabilistic): 0.70 vs Style C (Autonomous): 0.70
- Style A (Always-Yield) Q3 forced-choice preference: 70% vs Style B (Probabilistic): 10% vs Style C (Autonomous): 20%
- Style A (Always-Yield) Q4 Reaction Naturalness: 0.50 vs Style B (Probabilistic): 0.67 vs Style C (Autonomous): 0.30
- Style A (Always-Yield) Q2 Persona Consistency: 1.00 vs Style B (Probabilistic): 1.00 vs Style C (Autonomous): 0.70
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06007.
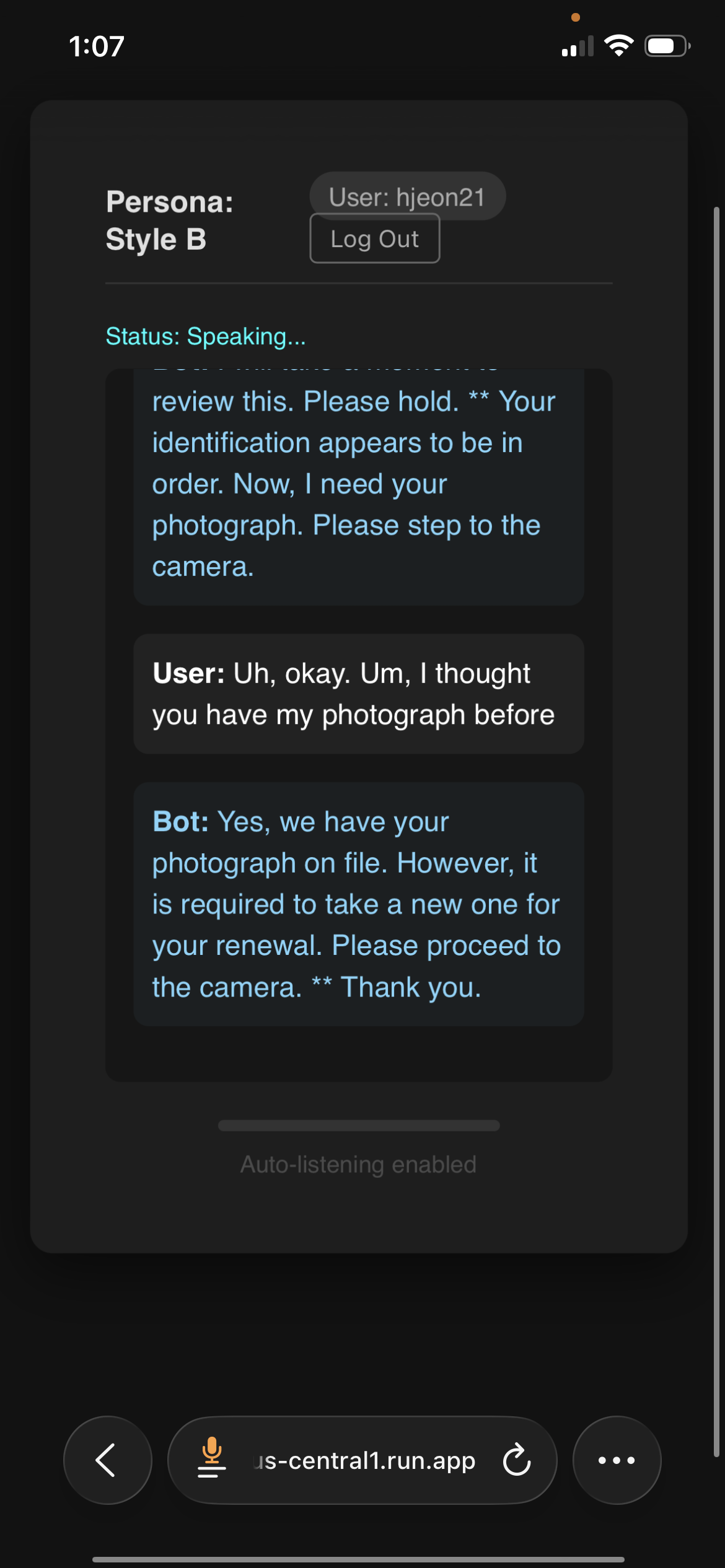
Fig 2: PersonaKit runs on both desktop and mobile.
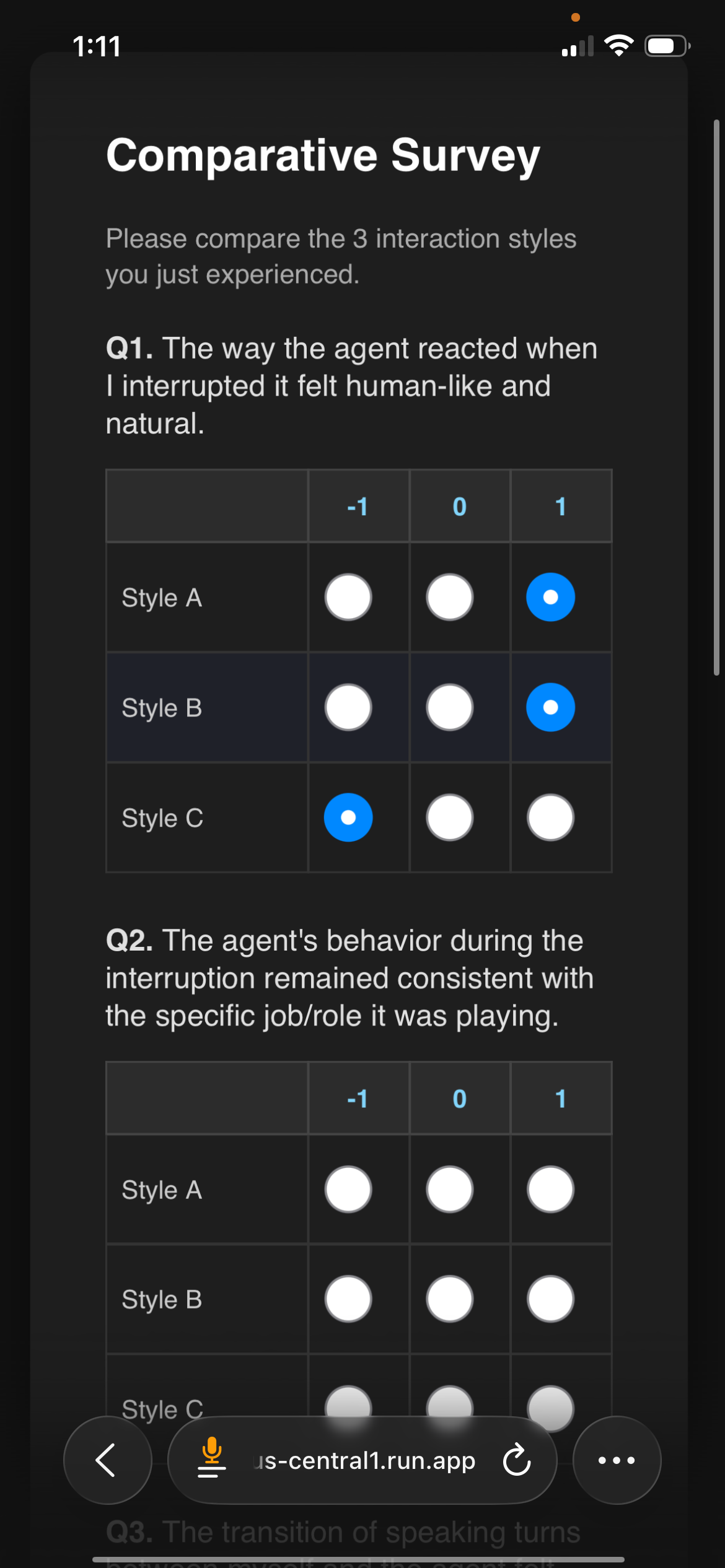
Fig 2 (page 4).
Limitations
- N=5 is far too small for any inferential statistics; with 10 ratings per cell the study cannot detect effects reliably or generalize circumplex-to-strategy mappings beyond this specific sample — the authors acknowledge this explicitly.
- The zero-shot LLM intent classifier (Competitive/Cooperative/Topic Change/Backchannel) was never validated against human annotations; under noisy acoustic conditions or ambiguous utterances, misclassification would silently corrupt the experimental manipulation without the researcher knowing.
- Probability weights in the strategy matrix appear to be researcher-chosen without optimization or theoretical derivation; the paper provides one example but gives no guidance on how to set weights for novel personas, making replication of specific persona configurations non-trivial.
- End-to-end barge-in latency of ~1–2 seconds is likely perceptible to users and may itself influence naturalness ratings independently of the strategy condition — this confound is not controlled or discussed.
- The four-action vocabulary (Yield, Resume, Bridge, Override) deliberately excludes prosodic and paralinguistic cues (pitch reset, latching, gaze, timing microvariation) that are central to human turn-taking, meaning the system can only approximate the sociolinguistic behaviors it aims to study.
- No cross-demographic replication: all 5 participants are uncharacterized in the paper (age, language background, familiarity with voice agents), so cultural or linguistic variation in turn-taking norms is entirely unaddressed.
- The specific LLM model version, system prompt templates, and TTS voice settings are not fully disclosed in the paper, limiting precise reproducibility of the pilot study results even with the released code.
Open questions / follow-ons
- How should probability weights in the strategy matrix be set or learned for novel personas? Bayesian optimization, RLHF from user preference signals, or mapping from established interpersonal circumplex coordinates are all plausible but untested approaches.
- Can the zero-shot intent classifier be replaced with a validated, lightweight acoustic-linguistic model that handles noisy real-world audio more reliably, and what is the downstream effect on persona consistency when intent misclassification rates are known?
- Does the ~1–2 second barge-in latency independently suppress naturalness ratings enough to mask genuine strategy effects, and what latency threshold renders the experimental manipulation ecologically valid for real deployed agents?
- Would the circumplex-to-strategy preference mappings observed here (high-agency → non-yield, low-agency/high-communion → yield) replicate across languages and cultures where turn-taking norms differ substantially from the presumably Western English-speaking pilot sample?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most immediately relevant aspect of PersonaKit is not its persona modeling per se, but the barge-in recovery and intent classification pipeline it demonstrates at low cost. Modern voice-based CAPTCHA or liveness challenges increasingly need to distinguish human conversational dynamics (natural interruptions, backchannels, competitive floor-taking) from bot behaviors (rigid turn-waiting, absence of barge-in, uniform response latency). PK's architecture — client-side VAD with byte-level cutoff tracking, server-side zero-shot intent classification of interruptions, and per-turn strategy/latency logging — provides a ready-made harness for collecting labeled datasets of human barge-in behavior that could seed supervised classifiers for bot detection in voice channels. The four intent categories (Competitive, Cooperative, Topic Change, Backchannel) map naturally onto behavioral signals that bots are unlikely to exhibit authentically under adversarial probing.
More broadly, the platform's A/B infrastructure could be repurposed to empirically test how different challenge designs (e.g., a deliberately uncooperative or dominant agent persona) affect bot pass rates versus human completion rates — a dimension of CAPTCHA design that is almost entirely unstudied. A bot fine-tuned to pass a subservient always-yield voice agent might fail badly when the agent holds the floor aggressively or issues competitive interruptions that require pragmatically coherent recovery. The N=5 pilot is far too small to draw conclusions, and the latency (~1–2 s) would need significant reduction for real-time security applications, but the open-source codebase provides a concrete starting point for building voice-channel behavioral biometric test environments.
Cite
@article{arxiv2605_06007,
title={ PersonaKit (PK): A Plug-and-Play Platform for User Testing Diverse Roles in Full-Duplex Dialogue },
author={ Hyunbae Jeon and Jinho D. Choi },
journal={arXiv preprint arXiv:2605.06007},
year={ 2026 },
url={https://arxiv.org/abs/2605.06007}
}