
Parser agreement and disagreement in L2 Korean UD: Implications for human-in-the-loop annotation
Source: arXiv:2605.06625 · Published 2026-05-07 · By Hakyung Sung, Gyu-Ho Shin
TL;DR
This paper addresses the practical bottleneck of manually annotating L2 (second-language learner) Korean text under the Universal Dependencies (UD) framework. Fully manual annotation is resource-intensive and hard to scale, while fully automatic annotation of learner language is unreliable due to non-canonical forms, case-marker omission, and proficiency-driven syntactic complexity. The authors propose a three-step human-in-the-loop (HITL) workflow: (1) run two independently fine-tuned parsers (Stanza and Trankit) on the same text, (2) auto-accept tokens where both parsers agree, and (3) route disagreement tokens to human annotators, with a third annotator adjudicating unresolved cases. The central empirical question is whether parser agreement is a reliable enough signal to skip human review safely.
The core finding is that when two domain-adapted parsers agree on a token, human annotators also agree on that token 93% of the time across all four annotation layers (LEMMA, XPOS, HEAD, DEPREL), comfortably exceeding the 90% threshold the authors set as their feasibility criterion. This means roughly 69% of tokens can be auto-accepted, concentrating human effort on the 31% of tokens flagged by parser disagreement. A secondary pipeline-validation experiment (5 incremental fine-tuning rounds on 500 new sentences) confirmed that incorporating adjudicated annotations did not degrade model performance on the held-out test set.
The disagreement analysis reveals that parser conflicts are not random noise but cluster into four linguistically coherent categories: grammatical-relation ambiguity (often triggered by case-marker omission), clause-boundary ambiguity (driven partly by the polyfunctional connective -ko and complementizer -ci), discourse-level structural ambiguity (especially topic-marked/dislocated elements), and modifier-attachment ambiguity. Many of these are tractable through targeted retraining, but some reflect genuine representational indeterminacy in the UD scheme when applied to learner language, implying that no amount of model refinement will fully eliminate them.
Key findings
- Across all four annotation layers (LEMMA, XPOS, HEAD, DEPREL), the two parsers agreed on 82.58% of token-level decisions (punctuation excluded) on a 2,208-sentence corpus of 25,814 tokens drawn from the KoLLA argumentative essay corpus.
- Within parser-agreement cases, human inter-annotator agreement reached 92.93% on average and exceeded 90% for every individual feature (LEMMA: 96.97%, XPOS: 91.97%, HEAD: 90.22%, DEPREL: 92.55%), meeting the authors' 90% feasibility threshold.
- 31% of tokens (7,994/25,814) required human correction in at least one feature when human review was restricted to parser-disagreement cases; of these, 8% of all tokens (2,019/25,814) required further third-annotator adjudication after the two reviewers still disagreed.
- In the DEPREL disagreement analysis, grammatical-relation ambiguity (263 cases), discourse/structural ambiguity (235 cases), clause-boundary ambiguity (206 cases), and modifier-attachment ambiguity (152 cases) were the four largest mismatch categories.
- Pipeline-validation experiment over five incremental fine-tuning rounds (100 sentences/round, 500 total from KoLLA, no overlap with training data) showed both Stanza and Trankit maintained test-set accuracy at approximately 85% or higher with no observable degradation (Fig. 1).
- Baseline in-domain performance on the UD-KSL test set before HITL annotation differed substantially between parsers: Stanza LAS 80.36% vs. Trankit LAS 89.13%, and Stanza UAS 85.53% vs. Trankit UAS 92.28%, indicating the two models have meaningfully different error profiles — a prerequisite for disagreement to be informative.
- The top morpheme-level XPOS mismatch (NNG+JKS vs. NNG+JKC, 54 occurrences) reflects systematic case-particle ambiguity, confirming that morphological and syntactic disagreements share a common root cause in L2 case-marker omission or ambiguity.
Methodology — deep read
Threat model and assumptions: This is not a security paper; there is no adversary. The implicit assumption is that two independently fine-tuned parsers will have partially uncorrelated errors, so their agreement is a stronger signal of correctness than either parser alone. The authors further assume that if human annotators converge on a token at >90% rates within the parser-agreement subset, auto-accepting those tokens introduces acceptable annotation noise. Both parsers were fine-tuned on the same training treebank (UD-KSL), which means they share some systematic biases — the authors acknowledge this but do not quantify correlation of errors between models.
Data provenance and composition: The main annotation corpus consists of 2,208 argumentative essays written by adult L2 Korean learners (Japanese and Chinese L1 backgrounds) drawn from the KoLLA corpus (Lee et al., 2009). The total token count after alignment was 25,814 (punctuation excluded for agreement calculations). Annotation followed the morphosyntactic scheme from Sung et al. (2025), covering four layers: LEMMA (dictionary base form), XPOS (language-specific morpheme-level POS tags including segmentation), HEAD (dependency head index), and DEPREL (UD dependency relation label). UPOS was excluded because it is deterministically derived from XPOS in this scheme. For the pipeline-validation experiment, 500 sentences were randomly sampled from KoLLA, confirming none overlapped with the UD-KSL training data used to fine-tune the parsers.
Model architecture and domain adaptation: Stanza (Qi et al., 2020) uses a BiLSTM-based pipeline for joint tokenization, POS tagging, lemmatization, and transition-based dependency parsing. Trankit (Van Nguyen et al., 2021) is a transformer-based pipeline built on XLM-R representations for joint morphosyntactic analysis. Both were fine-tuned on the UD-KSL training treebank (Sung and Shin, 2025a), which is a learner corpus of L2 Korean writing annotated with morpheme-level segmentation, XPOS tags, and dependencies. No further architectural changes were made; the novelty is in the workflow design, not the models themselves. The paper does not report hyperparameters for the initial fine-tuning, only that incremental retraining used 10 epochs per round.
HITL workflow (the proposed contribution): Step 1 runs both parsers on all sentences. Step 2 performs token-level cross-model comparison on all four layers; a token is flagged if any layer disagrees. Step 3 sends flagged tokens to two trained annotators who annotate independently. If both annotators agree, that label is adopted as gold. If they disagree, a third annotator (one of the paper's authors) adjudicates by reviewing all four outputs (two parser predictions plus two human annotations). Tokenization mismatches between the two parsers were resolved prior to comparison to ensure proper alignment; the paper does not detail the resolution procedure, which is a gap.
Evaluation protocol — proxy validity test: Before restricting human review to disagreement cases, the authors first had both annotators label ALL 2,208 sentences fully independently. This baseline full-annotation pass enabled computing two quantities: (a) overall parser agreement rate, and (b) human agreement rate conditioned on parser agreement. The key test is whether human agreement within parser-agreement cases exceeds 90%. The paper reports averages and per-feature breakdowns in Table 3. No formal statistical significance tests (e.g., Cohen's kappa, confidence intervals) are reported — the evaluation is descriptive. There is no held-out test of whether auto-accepted tokens would degrade downstream SLA research tasks.
Pipeline-validation experiment: 500 sentences from KoLLA were annotated in five batches of 100. After each batch, adjudicated annotations were added to the training set and both models were retrained for 10 epochs. Performance was re-evaluated on the fixed UD-KSL test set after each round. Fig. 1 plots accuracy across rounds; results show stability at ~85%+. The paper does not report numeric values for each round explicitly in the text — only the figure — so exact round-by-round deltas are not extractable from the text.
Disagreement analysis: For DEPREL, each disagreement token pair (Stanza label vs. Trankit label) was manually categorized into four types: grammatical-relation identification, clause-boundary/type differentiation, discourse-level structural organization, and modifier attachment. Category counts are in Table 6. For XPOS, the top 20 most frequent mismatch pairs are listed in Table 7 with raw counts. These analyses are qualitative-taxonomic; no inter-rater reliability is reported for the categorization itself. Concrete annotated examples (Figures 2–8) illustrate each category with morpheme-by-morpheme glosses. One concrete end-to-end example: the sentence 밖에서 노는 시간 뺏겨서 ('When time spent playing outside is taken away') has the nominal 시간 ('time') with accusative case marker dropped; Stanza assigned nsubj while Trankit assigned obj. Both annotators reviewed this flagged token; contextual interpretation favored obj, so obj was adopted as gold without third-annotator adjudication.
Reproducibility: No code repository is mentioned. The UD-KSL treebank is referenced as a prior publication (Sung and Shin, 2025a/b) but its public availability is not confirmed in this paper. The KoLLA corpus is a named external resource. Annotator training procedures are not described. The paper is exploratory and explicitly frames itself as a feasibility study rather than a system ready for deployment.
Technical innovations
- Binary parser-agreement triaging as an annotation proxy: using token-level consensus between two independently fine-tuned parsers (Stanza and Trankit on UD-KSL) as a filter that auto-accepts ~69% of tokens, rather than applying uncertainty sampling from a single model or requiring full manual annotation as in all prior L2 Korean UD corpora.
- Incremental pipeline-validation protocol: a five-round iterative retraining loop (100 sentences/round) that tests whether integrating HITL-adjudicated annotations degrades held-out test performance, providing empirical evidence for pipeline stability rather than assuming it.
- Linguistically-grounded taxonomy of L2 Korean parser disagreements: the four-category DEPREL mismatch typology (grammatical-relation identification, clause-boundary, discourse/structure, modifier attachment) goes beyond generic error analysis by linking each category to a specific morphosyntactic feature of Korean learner language (case-marker omission, polyfunctional connectives, topic-prominence), providing actionable targets for retraining data curation — prior work on L2 Korean parsing (Sung and Shin, 2025b) evaluated overall performance without this disaggregation.
Datasets
- UD-KSL (L2 Korean UD treebank) — size not explicitly stated in this paper; used as training/test set for fine-tuning Stanza and Trankit — Sung and Shin (2025a), non-public availability unconfirmed
- KoLLA corpus (Korean Language Learner corpus) — 2,208 argumentative essays / 25,814 tokens used in this study (500 sentences for pipeline validation) — Lee et al. (2009), non-public availability unconfirmed
Baselines vs proposed
- Stanza (fine-tuned on UD-KSL): LEMMA F1 = 95.64, XPOS F1 = 89.72, UAS = 85.53, LAS = 80.36 vs. Trankit (fine-tuned on UD-KSL): LEMMA F1 = 88.84, XPOS F1 = 91.81, UAS = 92.28, LAS = 89.13 (Table 2)
- Full manual annotation (implicit baseline — prior L2 Korean UD corpora per Table 1): requires 100% human review of all tokens vs. proposed HITL workflow: 31% of tokens require human review, 8% require third-annotator adjudication
- Human inter-annotator agreement within parser-agreement cases: average 92.93% across all four features (LEMMA: 96.97%, XPOS: 91.97%, HEAD: 90.22%, DEPREL: 92.55%) vs. authors' feasibility threshold of 90% — threshold met for all features (Table 3)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06625.
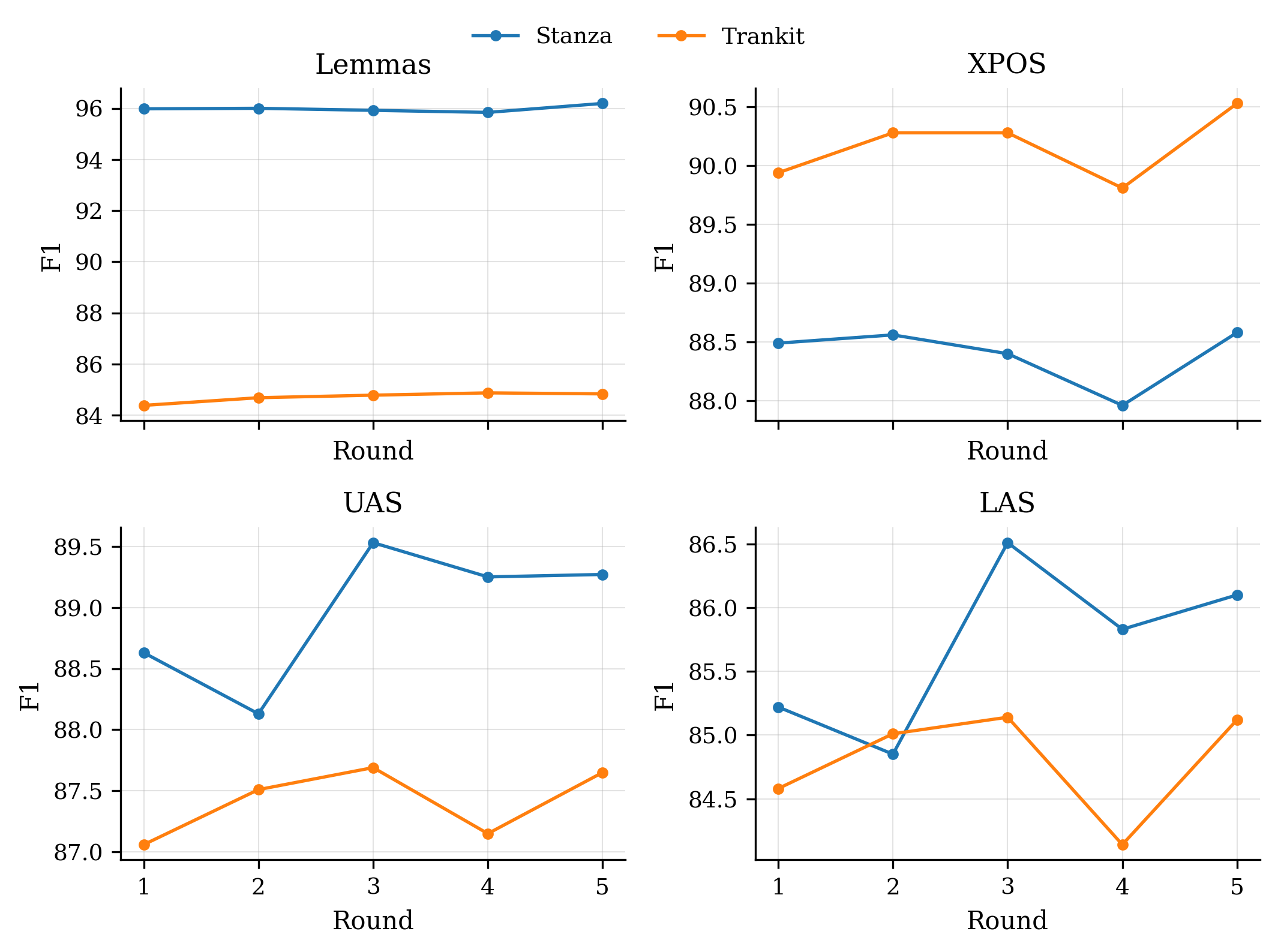
Fig 1: presents model performance on the test
Limitations
- Single genre and learner population: the corpus consists exclusively of argumentative essays by adult Japanese and Chinese L1 learners of Korean; the authors acknowledge this limits generalizability to spoken data, younger learners, other genres, and other L1 backgrounds.
- No inter-rater reliability metric for the disagreement taxonomy: the four-category DEPREL typology in Table 6 was assigned by the researchers, but no kappa or agreement score is reported for the categorization itself, making it unclear how replicable the taxonomy is.
- Correlated model errors not quantified: both parsers were fine-tuned on the same UD-KSL training data, so their agreement does not guarantee correctness — systematic training-data biases shared by both models will be silently auto-accepted. The paper notes this conceptually but provides no estimate of the magnitude.
- No downstream validity test: the study does not assess whether auto-accepted annotations are accurate enough for actual SLA research tasks (e.g., syntactic complexity measurement, dependency-based feature extraction), only that human annotators agree within those cases.
- Pipeline-validation sample is very small (500 sentences, 5 rounds of 100) and the figure (Fig. 1) is described qualitatively; exact per-round numeric results are not reported in the text, making it hard to assess the magnitude of stability.
- No formal statistical tests: agreement rates are reported as raw percentages without confidence intervals, significance tests, or Cohen's kappa, which limits the strength of claims about 'strong correspondence'.
- Tokenization mismatch resolution procedure is undescribed: the paper notes that pre-analysis alignment was performed when the two parsers disagreed on tokenization, but does not specify how conflicts were resolved, which could introduce systematic bias before the disagreement rate is even computed.
Open questions / follow-ons
- How does the proxy validity of parser agreement generalize across proficiency levels and L1 backgrounds? The current dataset pools Japanese and Chinese L1 learners in a single genre; it is unknown whether agreement-as-proxy holds for lower-proficiency learners who produce more non-canonical forms, or for spoken data where prosodic and disfluency phenomena are present.
- Can the four-category disagreement taxonomy be operationalized as a targeted active-learning signal — e.g., oversampling grammatical-relation and complementizer-headed clause disagreements during retraining — and if so, how much model improvement results per annotation hour invested?
- What is the lower bound on model divergence required for the proxy to remain valid? As both models are iteratively retrained on the same growing dataset, their outputs will converge, reducing the disagreement signal. At what agreement ceiling does the HITL filter become uninformative or introduce systematic shared errors?
- How should the UD scheme itself be adapted for inherently ambiguous L2 Korean constructions (e.g., the polyfunctional -ko connective, topic-prominent dislocations) where neither parser nor human annotator can resolve the label without pragmatic context — should these receive underspecified or multi-labeled annotations rather than forcing a single-label decision?
Why it matters for bot defense
This paper is primarily a computational linguistics / NLP methods paper with no direct application to bot defense or CAPTCHA. The core contribution — using two-model agreement to triage which outputs need human review — is a general annotation-efficiency technique, not a behavioral signal relevant to distinguishing humans from bots. A bot-defense engineer would not find actionable takeaways for traffic analysis, bot detection, or challenge design in this work.
There is a loose methodological parallel: the idea of using model disagreement as a confidence signal for routing decisions (auto-accept vs. escalate to human) mirrors some CAPTCHA risk-scoring pipelines that use ensemble disagreement to decide whether to serve a hard challenge. However, the paper does not develop this angle, operates in a completely different domain (offline corpus annotation vs. real-time traffic), and makes no claims about adversarial robustness. A practitioner interested in human-in-the-loop review queues for content moderation or annotation of behavioral telemetry might find the incremental retraining protocol (Section 3.3) worth reading as a methodological reference, but would need to substantially adapt it.
Cite
@article{arxiv2605_06625,
title={ Parser agreement and disagreement in L2 Korean UD: Implications for human-in-the-loop annotation },
author={ Hakyung Sung and Gyu-Ho Shin },
journal={arXiv preprint arXiv:2605.06625},
year={ 2026 },
url={https://arxiv.org/abs/2605.06625}
}