
NeuroAgent: LLM Agents for Multimodal Neuroimaging Analysis and Research
Source: arXiv:2605.06584 · Published 2026-05-07 · By Lujia Zhong, Yihao Xia, Jianwei Zhang, Shuo huang, Jiaxin Yue, Mingyang Xia et al.
TL;DR
This paper addresses the substantial manual effort and complexity involved in multimodal neuroimaging preprocessing and downstream analysis, which currently requires extensive expert tuning and coordination of heterogeneous tools. The authors propose NeuroAgent, a hierarchical autonomous agent framework powered by large language models (LLMs) to automate the entire neuroimaging workflow from raw data preprocessing across multiple modalities (sMRI, fMRI, dMRI, PET) through to downstream statistical analysis and disease classification. NeuroAgent uses a multi-agent architecture where a central orchestrator parses natural language goals and delegates tasks to modality-specialized agents, each wrapping domain-specific neuroimaging pipelines. A feedback-driven Generate-Execute-Validate execution engine manages iterative code generation, sandbox execution with automatic error recovery, and output validation to guarantee preprocessing integrity.
The system was extensively evaluated on 1,470 subjects from the ADNI dataset across multiple LLM backends, reaching up to 100% intent parsing accuracy and 84.8% end-to-end preprocessing correctness with the strongest model (Qwen3.5-27B). The agent ensemble also achieved an Alzheimer’s Disease classification AUC of 0.9518 using four modalities, outperforming all single-modality baselines. The human-in-the-loop interface limits manual review to rare edge cases. This work demonstrates that LLM-based autonomous agents can substantially reduce manual neuroimaging pipeline engineering effort, enable reproducible end-to-end analysis, and integrate natural language interaction for interactive research workflows.
Key findings
- NeuroAgent achieves up to 100% intent-parsing accuracy across multiple LLM backends for neuroimaging pipeline commands.
- The strongest LLM backend (Qwen3.5-27B) reaches 84.8% end-to-end preprocessing step correctness on the ADNI dataset.
- Automated error recovery significantly reduces manual intervention, confining human-in-the-loop review to edge cases only.
- The agent ensemble's Alzheimer’s disease classification on multimodal data attains ROC-AUC = 0.9518, exceeding all single-modality baselines.
- Subjects evaluated include 1,470 total with sMRI and tabular data, subsets with Tau-PET (n=469), resting fMRI (n=278), and DTI (n=620).
- Pipeline ablations show measurable improvements from the Generate-Execute-Validate mechanism compared to static script approaches.
- Post-preprocessing analyses reproduce clinically established patterns such as AD-associated cortical thinning and age-related fractional anisotropy decline.
Threat model
n/a — The work is not a security paper but considers operational reliability adversities such as heterogeneous data, runtime errors, and tool failures as the challenges the agent must autonomously detect and recover from, minimizing human intervention.
Methodology — deep read
Threat Model & Assumptions: The adversary model is not explicitly about security but rather addresses reliability and autonomy in executing complex neuroimaging pipelines. The system assumes access only to raw multimodal neuroimaging data and natural language research prompts. The agent must handle heterogeneous datasets and tool failures without external manual intervention, limiting human involvement to oversight via the human-in-the-loop interface.
Data: The evaluation data are pooled from multiple ADNI phases (1,470 subjects total), stratified into cognitively normal (CN=1,000) and Alzheimer's disease (AD=470) groups. Every subject has structural MRI and tabular clinical data; subsets have Tau-PET (n=469), resting-state fMRI (n=278), and diffusion MRI (DTI, n=620). The dataset includes raw DICOM series, converted and standardized to NIfTI/BIDS by NeuroAgent. Label availability supports downstream classification and biomarker correlation.
Architecture / Algorithm: NeuroAgent comprises a hierarchical multi-agent framework:
- Central Orchestrator (Planning Module): An LLM-powered planner that parses high-level natural language goals, extracts required data modalities and target tasks, and constructs a directed acyclic dependency graph to schedule workflows.
- Specialized Modality Agents: Each handles domain-specific pipelines using wrapped neuroimaging tools (FreeSurfer for sMRI, FSL/FreeSurfer integration for fMRI, FSL/DIPY/MRtrix3 for dMRI, Elastix for PET).
- Feedback-Driven Execution Engine: Iteratively Generate (produce Python preprocessing code), Execute (sandbox code execution with error logging), and Validate (enforce output schema compliance and quality checks) with automated self-correction on failures.
The system incorporates Human-in-the-Loop to escalate edge case failures for human review.
Training Regime: Not applicable as the system orchestrates tool execution rather than learning from scratch. Deep learning models for downstream classification (3D CNNs for volumetric data; MLPs/GNNs for connectivity features) are integrated from module Model Zoo. Hyperparameters and training regimes for classification models are not detailed.
Evaluation Protocol: Pipeline components are evaluated across multiple LLM backends (including Qwen3.5-27B) measuring:
- Intent-parsing accuracy: ability to correctly interpret research goals.
- Step correctness: percentage of preprocessing steps executed correctly end-to-end.
- Data integration fidelity: correctness of subject alignment and multimodal feature merging.
Downstream clinical validity was tested by reproducing known biomarker effects and performing AD classification with ROC-AUC metrics, comparing multimodal ensemble performance to single-modality baselines. Manual intervention rates were recorded via the human-in-the-loop interface.
- Reproducibility: Code release status unclear from text; pipeline uses publicly available neuroimaging tools wrapped in Python interfaces. The use of large LLM backends (some possibly proprietary) may impact reproducibility. Evaluation uses the public ADNI dataset.
Concrete Example: For an AD classification task, the Orchestrator parses the prompt, identifies modalities sMRI, fMRI, Tau-PET, and DTI, schedules structural MRI preprocessing first as needed for alignment, dispatches each Specialized Agent to generate and execute modality-specific preprocessing code. The execution engine runs code, detects any runtime errors, triggers parameter adjustments and retries autonomously. Once preprocessing completes and passes validation, data from all modalities are consolidated into a unified dataset. Deep learning classifiers run on these features yielding high AUC. The entire workflow runs with minimal manual oversight due to automated error recovery and HITL escalation only in rare cases.
Technical innovations
- A hierarchical multi-agent architecture combining a central LLM orchestrator with modality-specific specialist agents to decompose and execute complex multimodal neuroimaging pipelines.
- A feedback-driven Generate-Execute-Validate engine enabling iterative code generation, sandbox execution with automated runtime error recovery, and strict output validation to ensure pipeline reliability.
- Automated resolution of cross-modality dependencies through dynamic workflow construction that enforces implicit prerequisites (e.g., structural MRI preprocessing prior to fMRI alignment).
- Integration of a human-in-the-loop monitoring interface to escalate only edge cases for manual review, minimizing expert intervention while preserving safety and quality control.
Datasets
- ADNI dataset — 1,470 subjects total (CN=1,000, AD=470) — public Alzheimer's Disease Neuroimaging Initiative data
- Tau-PET subset — 469 subjects — from ADNI
- Resting-state fMRI subset — 278 subjects — from ADNI
- Diffusion MRI (DTI) subset — 620 subjects — from ADNI
Baselines vs proposed
- Single-modality AD classification baseline (best reported single modality): lower than 0.9518 AUC
- NeuroAgent multimodal ensemble: AD classification ROC-AUC = 0.9518
- Intent parsing accuracy (multiple LLMs): up to 100%, strongest backend Qwen3.5-27B achieves 84.8% end-to-end preprocessing correctness
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06584.
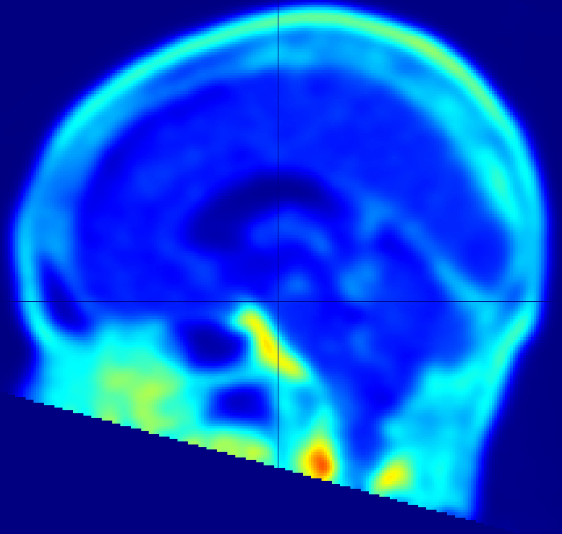
Fig 1: | NeuroAgent Framework Overview. The system comprises a Central Orchestrator (plan-
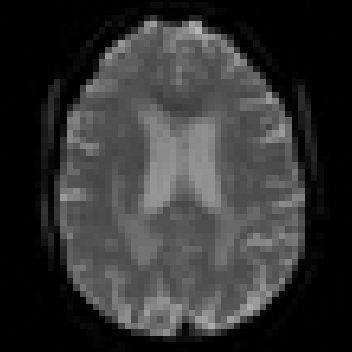
Fig 2 (page 6).
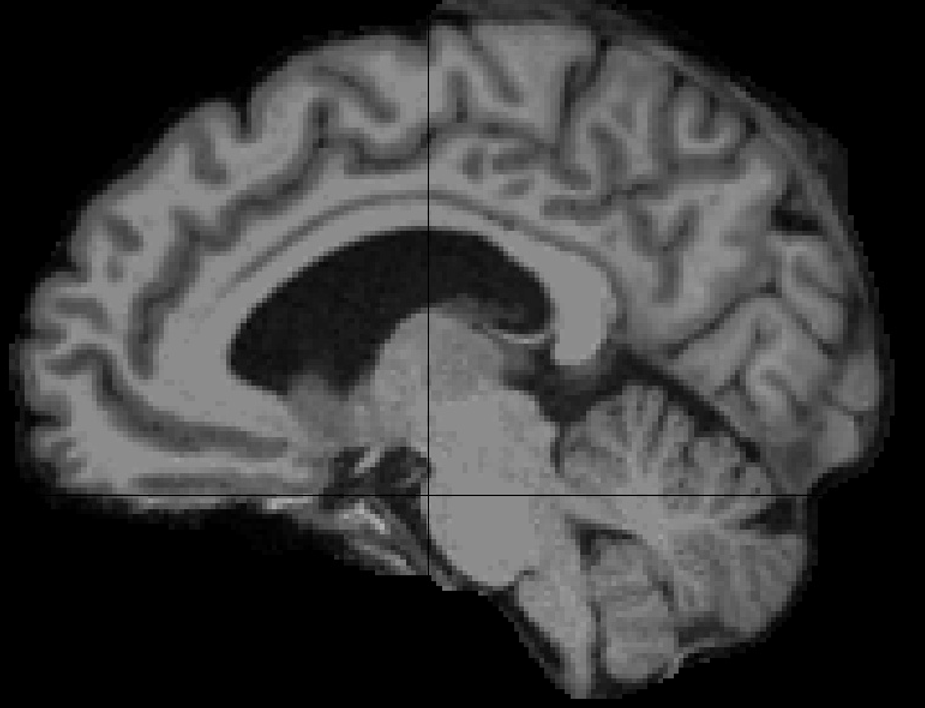
Fig 3 (page 6).
Fig 4 (page 6).
Fig 5 (page 6).
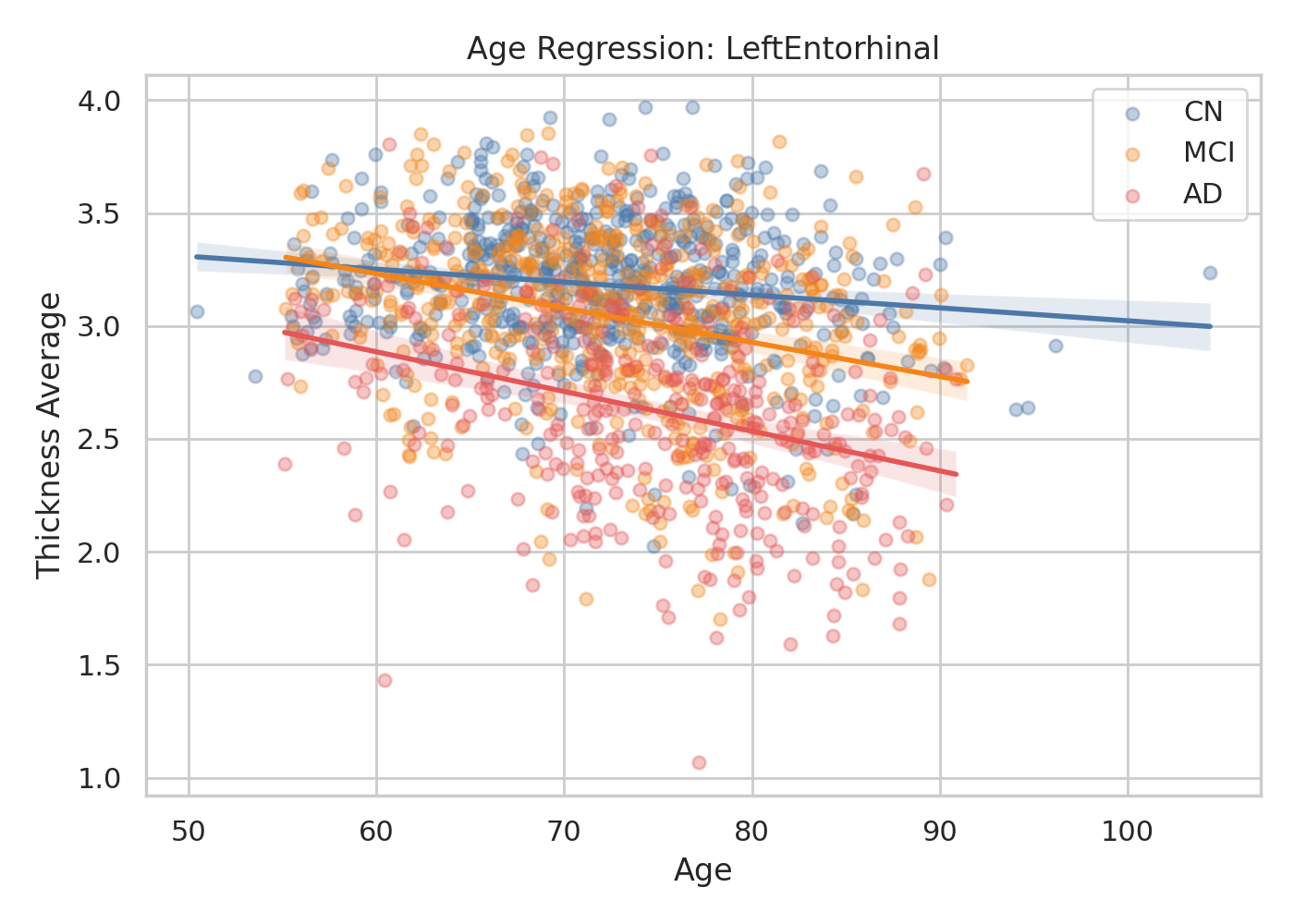
Fig 2: | Age-related Cortical Thinning in the Entorhinal Cortex (Agent-Generated). NeuroAgent
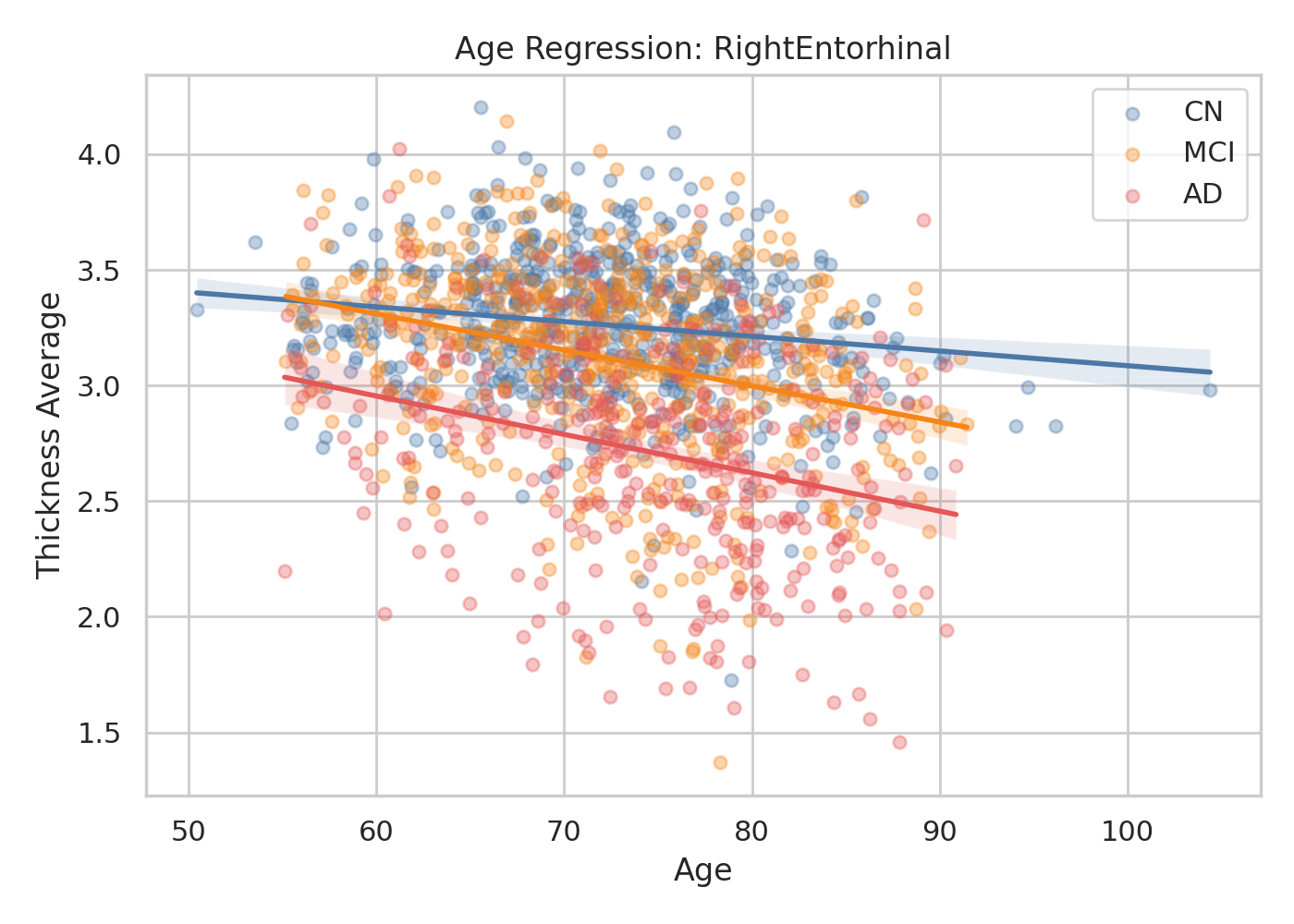
Fig 3: | Diagnosis-wise Cortical Thickness Comparison in the Entorhinal Cortex (Agent-
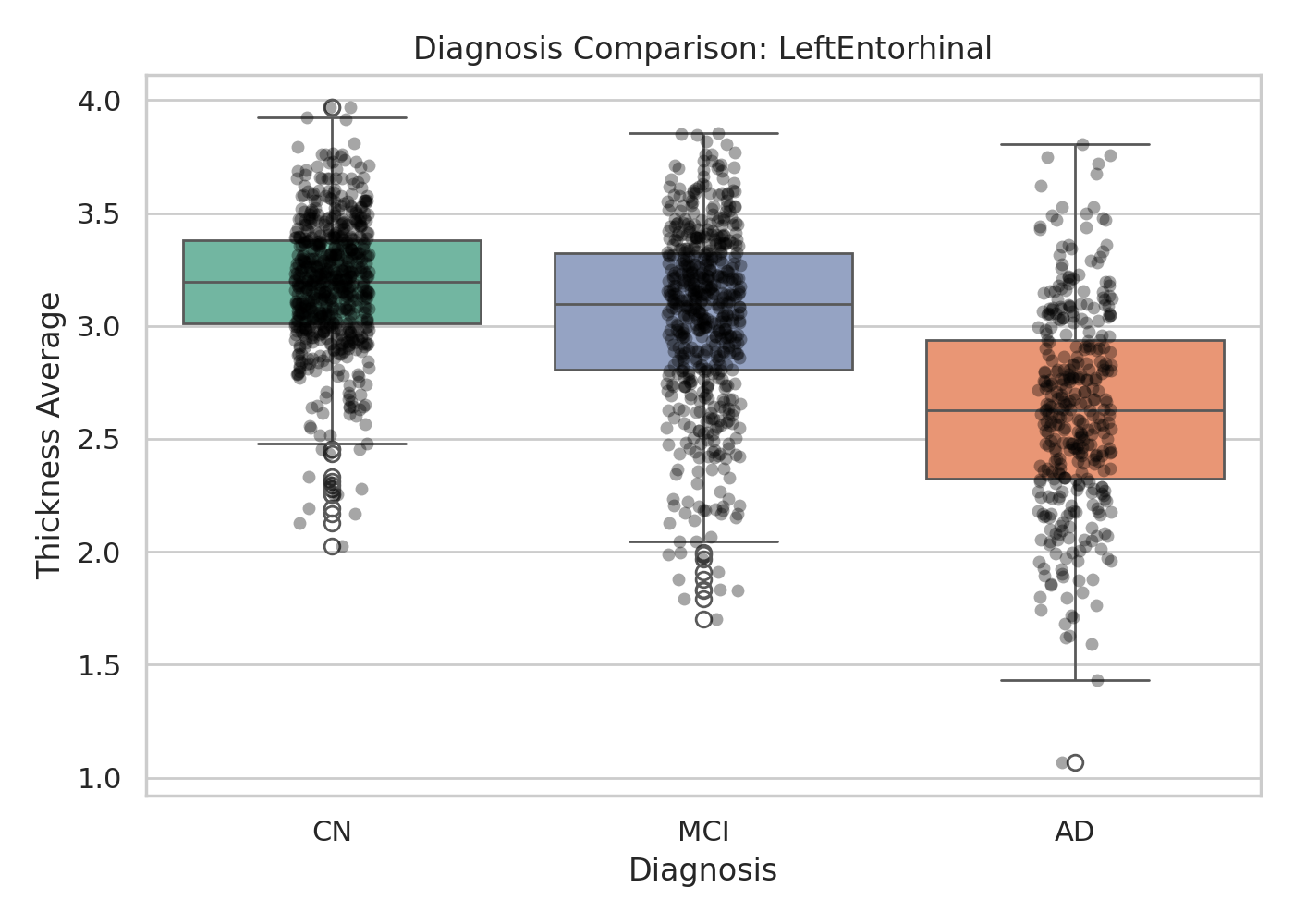
Fig 4: | Age-related Trajectories in the Inferior Parietal Cortex (Agent-Generated). (a) FA
Limitations
- LLM reliability remains tied to specific backends; generalizing performance across all LLMs is uncertain.
- Details on variability induced by dataset heterogeneity, missing modalities, or scanner differences are not extensively studied.
- The human-in-the-loop intervention interface requires expert oversight, meaning fully hands-off operation remains aspirational.
- Downstream deep learning models’ training details (hyperparameters, cross-validation) are underreported, limiting assessment of classification robustness.
- Unclear whether the system has been stress-tested with novel or out-of-distribution neuroimaging protocols.
- Code and model release status is not specified, potentially limiting reproducibility.
Open questions / follow-ons
- How robust is NeuroAgent to out-of-distribution neuroimaging data from scanners or protocols not seen during evaluation?
- Can the agent framework generalize to other neurological diseases or imaging modalities beyond those tested (e.g., PET tracers for other pathologies)?
- What are the tradeoffs in LLM backend selection regarding latency, cost, and preprocessing correctness in clinical deployment?
- How can the system adapt long-term via continual learning or user feedback to improve reliability and extend functionality?
Why it matters for bot defense
This work exemplifies how large language models can be turned into orchestrating autonomous agents that integrate heterogeneous toolchains and handle complex multi-step scientific workflows with interactive natural language interfaces. For bot-defense and CAPTCHA practitioners, NeuroAgent’s architecture underscores the potential of LLM agents not just for text generation but for reliable controlled execution, self-correction, and human-in-the-loop verification in domains requiring high-integrity pipeline processing. Its approach to multimodal data fusion and dynamic dependency resolution can inspire automated pipelines for security data analysis or biometrics verification within CAPTCHA systems. However, care must be taken in extending LLMs to environments demanding strict determinism and error recovery, highlighting the importance of scaffolded fallback mechanisms seen here. The human oversight component also parallels HITL designs in bot detection, emphasizing that fully autonomous systems must still transparently surface uncertainties for review.
Cite
@article{arxiv2605_06584,
title={ NeuroAgent: LLM Agents for Multimodal Neuroimaging Analysis and Research },
author={ Lujia Zhong and Yihao Xia and Jianwei Zhang and Shuo huang and Jiaxin Yue and Mingyang Xia and Yonggang Shi },
journal={arXiv preprint arXiv:2605.06584},
year={ 2026 },
url={https://arxiv.org/abs/2605.06584}
}