
In Data or Invisible: Toward a Better Digital Representation of Low-Resource Languages with Knowledge Graphs
Source: arXiv:2605.05931 · Published 2026-05-07 · By Ndeye-Emilie Mbengue
TL;DR
This PhD proposal addresses the systematic underrepresentation of low-resource languages in Linked Open Data (LOD) Knowledge Graphs (KGs), arguing that the digital language divide is being actively worsened by emerging AI technologies that depend on open access data. The paper's core observation is that no fine-grained, quantitative characterization of language coverage specific to the LOD ecosystem currently exists — prior work (notably Joshi et al. 2020) benchmarked this gap in NLP corpora but not in KGs like DBpedia, BabelNet, or Wikidata. The proposal frames three sub-research questions around: (1) identifying which variables best capture language distribution in LOD, (2) benchmarking candidate transfer-language selection strategies for Multilingual KG Completion (MKGC), and (3) exploring whether analogical reasoning can provide a weakly supervised alignment mechanism when seed data is extremely scarce.
The preliminary results confirm a heavily skewed, heterogeneous language distribution across all three major LOD KGs, with the majority of WALS-documented written languages having zero or near-zero representation. The normalized mutual information (NMI) between LOD-derived language clusters and Joshi et al.'s NLP-derived taxonomy scores only 0.63 (DBpedia), 0.60 (BabelNet), and 0.56 (Wikidata), indicating that LOD and NLP coverage landscapes diverge meaningfully — a finding with direct implications for which languages should be prioritized in cross-lingual transfer experiments. The paper identifies structural differences across KGs: DBpedia's coverage correlates near-linearly with Wikipedia article counts (due to infobox extraction), BabelNet shows less dispersion via its WordNet+Wikipedia integration, while Wikidata is highly heterogeneous and community-driven.
The research is explicitly early-stage: only SRQ1 has preliminary empirical output; SRQ2 and SRQ3 are planned work with methodology sketched but no results yet reported. The planned contributions include new MKGC benchmark datasets for low-resource languages, a formal LOD-specific definition of language resource levels, and a CNN-based analogical classifier (building on Lim et al.) for inferring cross-lingual entity correspondences. The proposal is positioned at the intersection of Semantic Web, multilingual NLP, and formal analogical reasoning.
Key findings
- Language distribution in LOD KGs is heavily skewed: the majority of WALS-documented written languages have minimal or zero representation in DBpedia, BabelNet, and Wikidata (Fig. 1, all three panels show a large 'Missing Written Languages' cluster).
- NMI between LOD-derived K-means clusters (6 categories, using Wikipedia article count + KG entity count) and Joshi et al.'s NLP taxonomy is 0.63 for DBpedia, 0.60 for BabelNet, and 0.56 for Wikidata — indicating the LOD coverage landscape is distinct from the NLP landscape.
- DBpedia exhibits a near-linear relationship between Wikipedia edition size and KG entity coverage (log-log scale), reflecting its dependence on Wikipedia infobox extraction; BabelNet is more homogeneous due to WordNet integration; Wikidata is the most heterogeneous.
- Right-divergent clusters (strong Wikipedia coverage, weak LOD coverage) signal languages amenable to information extraction from text corpora; left-divergent clusters (strong KG coverage, weak Wikipedia) signal candidates for KG verbalization to generate corpora.
- Language families are approximately homogeneously distributed across coverage clusters, supporting the hypothesis that within-family transfer (e.g., from higher-resource to lower-resource Romance languages such as Neapolitan and Ladino) is a viable strategy for MKGC.
- On the DBP-5L benchmark, the best-performing MKGC model reported is DMGNNSI (hybrid GNN+text) with Hits@1 of 63.6 (Greek), 59.7 (Japanese), 38.7 (English), 57.3 (Spanish), 60.2 (French), outperforming all graph-only baselines (KENS: 27.5/32.9/14.4/22.3/25.2) by large margins.
- No prior LOD study has benchmarked the effect of transfer candidate language selection on MKGC performance; existing work relies on fixed DBP-5L and EPKG benchmark sets without ablating candidate choice — identified as a central gap motivating SRQ2.
- Analogical reasoning has not previously been applied to cross-lingual KG alignment despite demonstrated effectiveness in KG bootstrapping (Jarnac et al., CIKM 2023) and morphological NLP tasks (Alsaidi et al., 2021) — identified as the motivation for SRQ3.
Methodology — deep read
The paper is a PhD proposal, so the methodology is a mix of completed preliminary work (SRQ1 descriptive analysis) and planned future work (SRQ2 and SRQ3). The following describes both what has been done and what is intended.
Threat model and assumptions (framing): There is no adversarial threat model in the security sense. The 'adversary' is structural: it is the data imbalance itself — the concentration of LOD resources in a small number of dominant languages leads to systematic exclusion of low-resource language communities from digital applications. The proposal assumes that LOD KGs are the primary substrate worth improving, and that cross-lingual transfer from higher-resource languages is feasible given sufficient linguistic proximity or analogical structure.
Data provenance and preliminary analysis (SRQ1): The study scope is restricted to written languages documented in WALS (World Atlas of Language Structures), providing a well-defined, externally grounded universe of languages. Two variables are measured: (i) the number of articles in each language's Wikipedia edition (a proxy for textual resource availability), and (ii) the number of entities/synsets annotated with the target language tag in each of three LOD KGs — BabelNet, Wikidata, and DBpedia. These are publicly accessible, and a companion website (nembengue.github.io/language_digital_coverage_lod/) provides dynamic visualizations. No explicit dataset size (count of languages processed) is stated in the truncated text. A third variable — number of language-tagged relations — is planned but not yet incorporated. Preprocessing details (e.g., how entity counts were extracted via SPARQL, handling of deprecated entities, date of KG snapshots) are not described in the available text.
Clustering and evaluation for SRQ1: K-means unsupervised clustering is applied to group languages into 6 categories (mirroring Joshi et al.'s 6-class taxonomy: Winners, Underdogs, Rising Stars, Hopefuls, Scrapping-Bys, Left-Behinds) using the log-transformed two-variable space (Wikipedia articles × KG entity count). Cluster quality is evaluated via Average Silhouette Score (ASS) and Variance Ratio Index (VRI). Alignment with Joshi et al.'s categorization is measured with Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI). Category boundaries are defined using a quantile-based approach for reproducibility. The reported NMI values (0.63, 0.60, 0.56 for DBpedia, BabelNet, Wikidata respectively) are preliminary; ARI values are not yet reported in the available text. The choice of K=6 is motivated by comparability with Joshi et al. rather than optimized via elbow or gap-statistic methods — this is a methodological assumption not explicitly justified.
Planned MKGC benchmarking (SRQ2): The proposal plans to evaluate six published MKGC models spanning graph-only (KENS, SS-AGA) and hybrid graph+text families (AlignKGC, JMAC, DMGNNSI, CA-MKGC) under three transfer candidate selection strategies: (i) Digital Resource — selecting transfer candidates with the highest LOD coverage as identified by SRQ1; (ii) Language Proximity — using WALS-derived features (language family, macro-area, genus, shared typological features) rather than just phylogenetic trees as in prior work; (iii) Curated Seed Alignments — filtering noisy seed alignments using a minimum-entropy criterion inspired by Luo et al. The evaluation will first use DBP-5L's five languages as targets, then extend to genuinely low-resource languages identified in SRQ1. Metrics are MRR and Hits@K for link prediction quality, plus training/inference time for computational cost. The entropy-based alignment curation method is described as 'yet to be investigated' in precise formalization.
Planned analogical reasoning framework (SRQ3): The analogy framework models cross-lingual correspondences as proportional analogies of the form 'A:B :: C:D' (e.g., entity in Language 1 is to its Language 2 equivalent as another Language 1 entity is to its Language 2 equivalent). The initial baseline classifier is the two-layer CNN proposed by Lim et al., applied to detect valid analogical quadruples. The goal is a language-agnostic model that can infer new alignments (or approximate correspondences) from sparse seed sets, leveraging alignments across other language pairs. The architecture beyond the Lim et al. baseline, training data construction, and loss function are not yet specified in the available text.
Reproducibility posture: Preliminary cluster visualizations are publicly available via the companion website. The literature review corpus is shared on Zotero. Code for the KG analysis and the MKGC benchmarking experiments has not yet been released (the work is early-stage). The planned MKGC experiments will produce new datasets that are intended for release. Specific random seeds, K-means initialization strategies, and snapshot dates for KG data are not documented in the available text.
Technical innovations
- A LOD-specific quantitative characterization of global language distribution using WALS-scoped languages across three KGs (DBpedia, BabelNet, Wikidata), extending Joshi et al.'s NLP-focused taxonomy to the Linked Open Data ecosystem for the first time.
- A planned benchmarking framework that systematically ablates transfer candidate language selection strategies (resource-coverage-based, linguistic-proximity-based, alignment-quality-based) in MKGC — prior work (DBP-5L, EPKG benchmarks) uses fixed language sets without evaluating this choice.
- A proposed entropy-based seed alignment curation method to filter noisy inter-language entity correspondences before MKGC training, inspired by Luo et al. but not yet formalized in this proposal.
- The first proposed application of analogical reasoning (A:B :: C:D proportional inference) as a weakly supervised framework for cross-lingual KG alignment, extending prior analogical approaches in KG bootstrapping (Jarnac et al., CIKM 2023) to the multilingual alignment setting.
- Use of WALS typological features (macro-area, genus, shared features) rather than phylogenetic trees alone as language proximity signals for transfer candidate selection, generalizing Martinez et al.'s language-family-based approach.
Datasets
- DBpedia — multilingual LOD KG, size not specified in this paper — publicly available (dbpedia.org)
- BabelNet — multilingual LOD KG/lexical resource, size not specified in this paper — publicly available (babelnet.org)
- Wikidata — multilingual LOD KG, size not specified in this paper — publicly available (wikidata.org)
- DBP-5L — 5-language MKGC benchmark (Greek, Japanese, English, Spanish, French) — derived from DBpedia, publicly available
- EPKG — multilingual KG alignment benchmark — publicly available, size not specified in this paper
- WALS (World Atlas of Language Structures) — universe of documented written languages used to scope the study — publicly available (wals.info)
Baselines vs proposed
- KENS (graph-only): Hits@1 = 27.5 (Greek), 32.9 (Japanese), 14.4 (English), 22.3 (Spanish), 25.2 (French) on DBP-5L
- SS-AGA (graph-only): Hits@1 = 30.8 (Greek), 34.6 (Japanese), 16.3 (English), 25.5 (Spanish), 27.1 (French) on DBP-5L
- AlignKGC (hybrid): Hits@1 = 57.6 (Greek), 53.2 (Japanese), 37.2 (English), 53.0 (Spanish), 52.9 (French) on DBP-5L
- JMAC (hybrid): Hits@1 = 55.2 (Greek), 53.3 (Japanese), 29.5 (English), 45.4 (Spanish), 49.3 (French) on DBP-5L
- DMGNNSI (hybrid): Hits@1 = 63.6 (Greek), 59.7 (Japanese), 38.7 (English), 57.3 (Spanish), 60.2 (French) on DBP-5L — highest reported
- CA-MKGC (hybrid): Hits@1 = 59.6 (Greek), 54.6 (Japanese), 34.9 (English), 49.1 (Spanish), 51.3 (French) on DBP-5L
- Joshi et al. NLP taxonomy vs. LOD KG clustering (NMI): DBpedia = 0.63, BabelNet = 0.60, Wikidata = 0.56 — proposed KG-based clustering vs. NLP reference
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.05931.
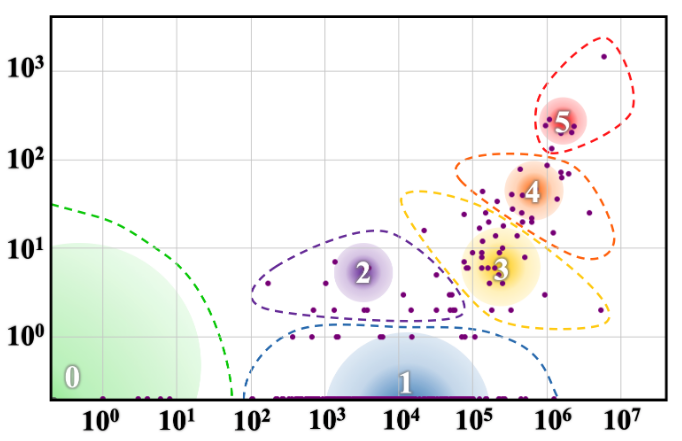
Fig 1: Language coverage (log-log scale) in BabelNet, Wikidata, and DBpe-
Limitations
- This is a PhD proposal, not a completed study: SRQ2 and SRQ3 have no empirical results yet — all claims about transfer selection and analogical reasoning are planned contributions, not demonstrated ones.
- The preliminary clustering analysis uses only two variables (Wikipedia article count and KG entity count); the third planned variable (language-tagged relations) is not yet incorporated, and the justification for K=6 clusters is based on comparability with prior work rather than data-driven optimization.
- KG snapshot dates, SPARQL query methodology, handling of deprecated or merged entities, and exact language tag filtering logic are not documented, making the preliminary results difficult to reproduce precisely.
- The study scope is restricted to written WALS languages, which excludes oral-only and undocumented languages — precisely those most severely underrepresented and most in need of digital inclusion advocacy.
- The entropy-based seed alignment curation method (SRQ2) is explicitly described as 'yet to be investigated,' meaning a core methodological component is unspecified at proposal time.
- All MKGC baseline results reported (Table 1) are from prior publications on the DBP-5L benchmark using its standard fixed transfer configuration — no new experimental results are provided for SRQ2, and no genuinely low-resource language (e.g., Neapolitan, Ladino) has been evaluated under any model yet.
- No adversarial or distribution-shift evaluation is planned for the analogical classifier (SRQ3); it is unclear how the framework would behave when source and target languages share little structural overlap or when seed analogies are noisy.
Open questions / follow-ons
- How robust is within-family cross-lingual transfer when the higher-resource source language has itself only moderate LOD coverage (e.g., transferring from a 'Rising Star' to a 'Left-Behind' within the same genus)? The proposal assumes family proximity implies transfer utility, but this has not been empirically validated in the MKGC setting.
- Can the entropy-based seed alignment curation scale to very large multilingual KGs, and does minimizing alignment noise always improve downstream MKGC performance or can it over-filter semantically valid but structurally unusual alignments?
- The analogical classifier baseline (Lim et al. two-layer CNN) was designed for morphological analogies in NLP — how much architectural adaptation is required for KG entity alignment, where the 'features' are graph embeddings rather than character strings, and what constitutes a valid training set for analogical quadruples in a KG context?
- Given that Wikidata's coverage is editorially driven and DBpedia's is Wikipedia-extraction-driven, will a single unified 'low-resource language in LOD' definition be meaningful across all three KGs, or will separate formalization per KG type be necessary?
Why it matters for bot defense
The direct relevance of this paper to bot-defense and CAPTCHA engineering is low, but there are two indirect connections worth noting for practitioners thinking about multilingual bot traffic and language-aware fraud signals. First, the characterization of language distribution in LOD KGs (SRQ1) has implications for any system that relies on knowledge graph lookups or entity resolution to profile users or detect fake accounts — if a user's declared language or locale corresponds to a severely underrepresented language in the underlying KG, entity-resolution-based signals will be systematically weaker or absent for those users. This can create blind spots in bot scoring models that use KG-derived features. Practitioners should audit which languages their KG-dependent signals cover and consider whether low-resource language users are being systematically misclassified due to missing entity data rather than genuine behavioral anomalies.
Second, for CAPTCHA and challenge design teams deploying multilingual or culturally-adapted challenges (e.g., text-based CAPTCHAs, common-knowledge questions, or image challenges localized to specific regions), the finding that LOD KGs have a highly heterogeneous and often near-zero coverage of low-resource languages means that automated challenge generation pipelines built on top of DBpedia, Wikidata, or BabelNet will produce very sparse or no challenges for communities speaking these languages. This is both an equity issue and a practical coverage gap. The planned MKGC enrichment methodology could, if successful, eventually improve the substrate available for such pipelines, but practitioners should not expect near-term tooling — the work is at proposal stage with no completed SRQ2 or SRQ3 results.
Cite
@article{arxiv2605_05931,
title={ In Data or Invisible: Toward a Better Digital Representation of Low-Resource Languages with Knowledge Graphs },
author={ Ndeye-Emilie Mbengue },
journal={arXiv preprint arXiv:2605.05931},
year={ 2026 },
url={https://arxiv.org/abs/2605.05931}
}