
GlazyBench: A Benchmark for Ceramic Glaze Property Prediction and Image Generation
Source: arXiv:2605.06641 · Published 2026-05-07 · By Ziyu Zhai, Siyou Li, Juexi Shao, Juntao Yu
TL;DR
GlazyBench addresses the absence of any large-scale, standardized dataset for computational ceramic glaze design. The ceramic glaze development process is notoriously opaque: high-temperature firing triggers complex phase transitions that determine color, transparency, and surface texture, and the field has historically relied on expensive trial-and-error iteration. The authors scrape and rigorously clean data from the Glazy community platform, producing 23,148 real-world glaze recipes with firing parameters, chemical compositions, community-annotated properties, and user-uploaded photographs. They then define a two-step benchmark: (1) predict post-firing surface properties—color (RGB and 9-class family), transparency (4-class), and surface finish (9-class)—from raw material composition and Unity Molecular Formula (UMF) features; and (2) generate 128×128 visual representations of the glaze conditioned on those predicted properties.
The paper's core contribution is not a new model architecture but a curated dataset and evaluation protocol that had not previously existed. The authors invest significant effort in data hygiene: a model-voting scheme selects the true glaze color from noisy community photos (Random Forest + XGBoost ensemble, 95.6% voting accuracy on the manually labeled test set), GrabCut segmentation extracts relevant image regions (90.13% success on training data), and a quality-based patch extraction pipeline using LBP texture analysis and Sobel edge detection further filters images. The result is 12,175 validated training samples for property prediction and 2,323 effective training images for generation.
Baseline experiments with traditional ML models (Random Forest, CatBoost, LightGBM, XGBoost, Logistic Regression), three LLMs (GPT-4o-mini, DeepSeek-V3, Claude Sonnet 4.5) in zero- and five-shot settings, and two generative architectures (conditional VAE and a lightweight WGAN-GP) reveal that all current approaches fall well short of practical utility. The best property predictor (CatBoost) achieves only 52.5% accuracy on 4-class transparency and 42.1% on 9-class surface finish. Image generation quality is visually poor at 128×128, and LMMs conditioned on raw chemistry rather than explicit appearance attributes exhibit severe 'conditional interpretability collapse,' producing schematic outputs that do not faithfully reflect the input formula.
Key findings
- CatBoost achieves the highest transparency classification accuracy at 52.5% (Micro-F1: 0.530) and surface finish accuracy at 42.1% (Micro-F1: 0.444) on the GlazyBench test set; Logistic Regression collapses to 1.6% accuracy on 9-class surface, illustrating a large linear-vs-nonlinear gap.
- Color family classification (9-class) is the hardest property prediction task across all models: best accuracy is 27.0% (Random Forest) and best Micro-F1 is 0.151 (XGBoost), barely above a uniform random baseline of ~11%.
- RGB color regression MAE is 40.14–42.20 across tree ensemble models (LightGBM lowest at 40.14, CatBoost highest at 42.20), on a [0,255] scale per channel, indicating roughly 16% average channel error.
- LLMs in 5-shot setting: Claude Sonnet 4.5 reaches 48.6% accuracy on 9-class surface finish, outperforming GPT-4o-mini (40.2%) and DeepSeek-V3 (40.7%); however all LLMs remain below or near the CatBoost supervised baseline, demonstrating that in-context chemistry reasoning does not substitute for task-specific training.
- Lightweight WGAN-GP outperforms conditional VAE on image color consistency: mean RGB Euclidean distance drops from 134.49 to 72.31, median from 112.89 to 46.54, and 'pass rate' (distance < 100) improves from 46.6% to 75.9%, yet visual quality remains insufficient for production use.
- The Random Forest + XGBoost voting ensemble used for training-set color label selection achieved 95.6% accuracy on the manually annotated test set, enabling automated labeling of 12,175 training samples; 4,438 training samples were removed due to model-voting inconsistency.
- GrabCut segmentation achieved a 90.13% success rate on 4,490 training images and 98.87% on 443 test images; subsequent quality-based patch extraction retained only 51.74% of training images (2,323/4,490) versus 74.04% of test images (328/443), reflecting the superior quality of manually curated test data.
- Train/test label distribution shift is low across all property tasks: KL divergence between training and test set class distributions is below 0.12 for all annotation types, supporting unbiased evaluation.
Methodology — deep read
Threat model and assumptions: This is not a security paper. The relevant 'adversary' is the complexity of ceramic chemistry itself—the assumption is that post-firing glaze properties are a deterministic (though noisy) function of raw material ratios, firing cone, and atmosphere, and that this mapping is learnable from community-sourced data. No adversarial robustness evaluation is performed.
Data provenance, construction, and splits: Raw data originates from the Glazy open-source platform (glazy.org), comprising 23,148 community-contributed glaze recipes. Each recipe contains ingredient names and weight percentages, firing cone range (minimum/maximum), firing atmosphere (oxidation/reduction/neutral), community-annotated transparency and surface labels (enumerated fields), and user-uploaded photographs from which RGB color swatches are automatically extracted by the platform. The dataset is partitioned into 18,245 training and 4,903 test samples with strict disjointness. The test set undergoes manual verification by the authors; the training set relies on automated and model-assisted labeling.
Feature engineering: Raw ingredient lists are converted to Unity Molecular Formula (UMF) representation, which normalizes oxide compositions into flux (RO/R2O), stabilizer (R2O3), and glass-former (RO2) groups—a standard ceramics science normalization. The feature vector includes 47 oxide percentages in UMF form, minimum and maximum cone rating (firing temperature proxy), and atmosphere category. Physically motivated ratio features such as SiO2:Al2O3 are also constructed. This dual representation (raw wt% and UMF) is used selectively: traditional ML baselines use UMF + firing parameters, while LLMs receive chemical composition, UMF ratios, and firing conditions as structured text.
Property prediction—training and evaluation: Five supervised models are trained with default hyperparameters (no tuning): Logistic Regression, Random Forest, XGBoost, LightGBM, and CatBoost. No cross-validation or hyperparameter search is reported; the authors explicitly state default library parameters are used for reproducibility. Evaluation uses the fixed train-test split; metrics are micro F1 and accuracy for the three classification tasks (transparency, surface, color family) and MAE for RGB regression. No statistical significance tests are reported. Three LLMs—GPT-4o-mini, DeepSeek-V3 (described in the paper as 'DeepSeek-v3' and 'DeepSeek-V3.2' interchangeably), and Claude Sonnet 4.5—are evaluated zero-shot and 5-shot on the classification tasks only (not RGB regression). Prompts require direct label output; detailed prompt templates are in Appendix C (not reproduced in the truncated text).
Training-set color label construction (key preprocessing step): The platform auto-extracts two prominent colors per photo (actual glaze color and background color). To identify which is the true glaze color for 12,175 training samples, the authors train Random Forest and XGBoost on the manually labeled 4,903-sample test set, select whichever of the two candidate colors is closer in feature space to the model prediction, and remove borderline cases (339 samples) where both candidates map to different color families. This introduces a potential circularity: the test set is used to train the label-selection models for training data, but since the test set labels are manually verified and the training labels are derived independently, this does not constitute direct leakage.
Image generation—data pipeline and baselines: Starting from 4,490 training and 443 test images, GrabCut (graph-cut-based foreground segmentation) extracts glaze surface regions; failures (443 training, 5 test samples) are discarded. A quality-based patch extraction pipeline using LBP texture analysis, Sobel edge detection, and a fill ratio check further culls low-quality patches, yielding 2,323 training and 328 test images at 128×128 resolution. Two baseline generative architectures are evaluated: a conditional VAE (convolutional encoder-decoder, ELBO objective) and a lightweight WGAN-GP generator (Wasserstein loss with gradient penalty). Both are conditioned on a 25-dimensional vector encoding surface type (9 classes), transparency (4 classes), target RGB (3 continuous values), and firing atmosphere. Architecture details and hyperparameters are in Appendix D (not fully reproduced). Three LMMs are also prompted with three input types (raw wt%, UMF features, and explicit surface attributes) and their outputs are shown qualitatively in Fig. 3. Image generation evaluation uses FID (distribution-level), LPIPS (sample-level perceptual similarity to real images), pairwise LPIPS diversity (anti-mode-collapse), and RGB Euclidean distance to target color (color consistency with a pass threshold of 100). Numeric FID and LPIPS values for the generative baselines are not reported in the truncated paper text—only color distance metrics appear in Table 8; it is unclear whether full FID/LPIPS tables exist in appendices.
Reproducibility: The paper does not explicitly state whether code or model weights are released. The dataset originates from a public platform (Glazy) but the curated benchmark split, annotations, and image preprocessing pipeline are the authors' contribution; release status is not confirmed in the available text. All traditional ML baselines use default hyperparameters, aiding reproducibility. Random seeds are not mentioned.
Technical innovations
- First large-scale standardized benchmark for ceramic glaze property prediction and image generation, sourced from 23,148 real community recipes on the Glazy platform, with a reproducible two-task evaluation protocol—prior work used small single-system datasets of tens to hundreds of samples.
- Model-voting-based training label construction: a Random Forest + XGBoost ensemble trained on the manually verified test set disambiguates true glaze color from background in noisy community photos, achieving 95.6% voting accuracy and enabling automated annotation of 12,175 training samples.
- Two-step decomposition of the recipe-to-image problem into (1) chemistry-to-property prediction and (2) property-conditioned image generation, explicitly encoding firing context (cone range and atmosphere) as features—prior work typically treated firing conditions as constants within single kiln studies.
- Quality-controlled image preprocessing pipeline combining GrabCut segmentation with LBP texture analysis and Sobel edge detection for patch quality scoring, yielding average quality scores of 0.688 (train) and 0.712 (test) on a standardized 128×128 crop.
- UMF-based dual feature representation (raw oxide wt% alongside normalized flux/stabilizer/glass-former groups plus physically motivated ratios like SiO2:Al2O3) as a transferable input across heterogeneous firing contexts, distinguishing the approach from prior fixed-composition studies.
Datasets
- GlazyBench (property prediction) — 23,148 total recipes; 12,175 training samples with verified RGB labels, 4,903 test samples manually annotated — sourced from glazy.org (public community platform), curated split is authors' contribution
- GlazyBench (image generation) — 2,323 effective training images, 328 effective test images at 128×128 RGB — subset of above, filtered via GrabCut + quality patch extraction — sourced from glazy.org user-uploaded photos
Baselines vs proposed
- CatBoost (transparency, 4-class): Accuracy = 0.525, Micro-F1 = 0.530 — best among all traditional ML baselines
- Logistic Regression (surface, 9-class): Accuracy = 0.016, Micro-F1 = 0.008 vs CatBoost: Accuracy = 0.421, Micro-F1 = 0.444
- Random Forest (color family, 9-class): Accuracy = 0.270, Micro-F1 = 0.119 — best accuracy; XGBoost: Micro-F1 = 0.151 — best F1
- LightGBM (RGB regression): MAE = 40.14 — best among traditional ML; CatBoost: MAE = 42.20 — worst
- Claude Sonnet 4.5 zero-shot (transparency): Accuracy = 0.400 vs 5-shot: Accuracy = 0.380 (degraded); DeepSeek-V3 5-shot: Accuracy = 0.413 (best among LLMs on transparency)
- Claude Sonnet 4.5 5-shot (surface, 9-class): Accuracy = 0.486, Micro-F1 = 0.379 — best LLM result on any task; GPT-4o-mini 5-shot: Accuracy = 0.402; DeepSeek-V3 5-shot: Accuracy = 0.407
- All LLMs (color family): best zero-shot accuracy = 0.199 (GPT-4o-mini); few-shot does not improve — GPT-4o-mini 5-shot drops to 0.169
- Conditional VAE (image color distance): Mean = 134.49, Median = 112.89, Pass Rate (< 100) = 46.6% vs Lightweight WGAN-GP: Mean = 72.31, Median = 46.54, Pass Rate = 75.9%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06641.
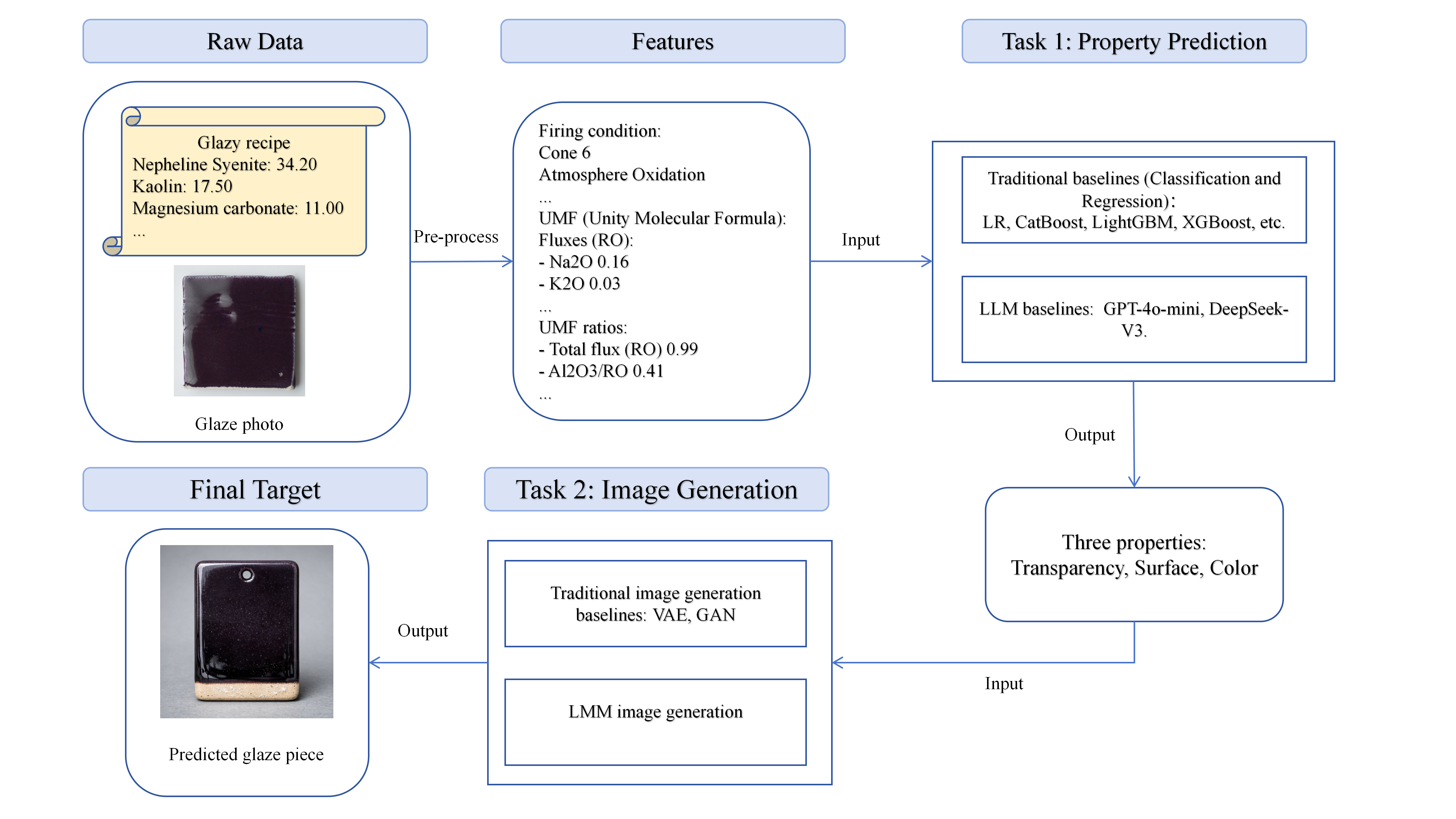
Fig 1: Two-step image generation task

Fig 2: Image region extraction pipeline.
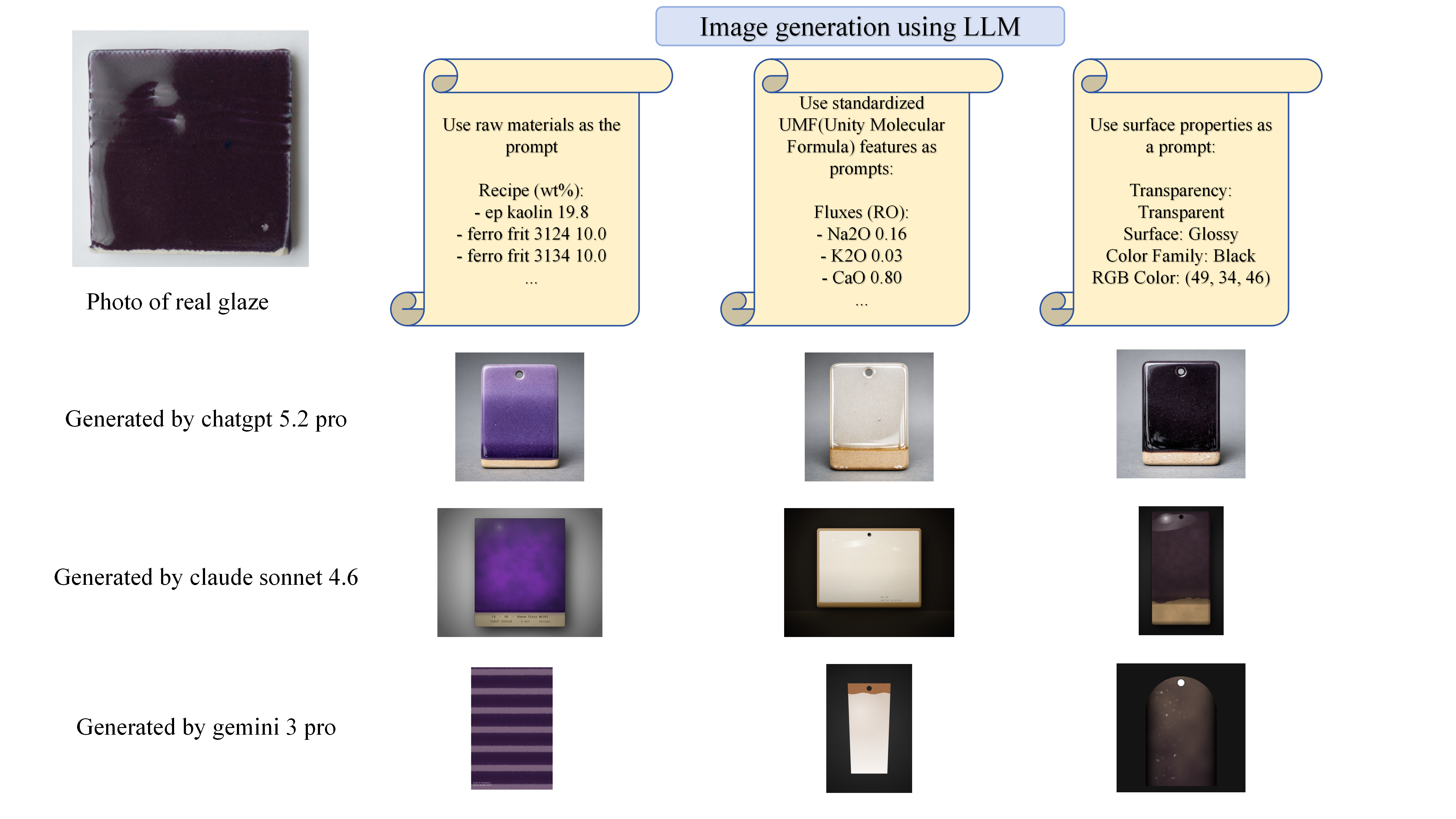
Fig 3: LLM’s image generation results under three different prompt conditions
Limitations
- All property prediction models use default hyperparameters with no tuning or cross-validation; reported numbers represent underoptimized baselines and do not bound what is achievable—this is by design for a benchmark paper but means the results do not indicate true ceiling performance.
- Image generation is capped at 128×128 resolution, which the authors acknowledge is insufficient for production-level glaze preview; no super-resolution or higher-resolution generation baselines are included.
- Community-sourced labels for transparency and surface are self-reported by recipe authors with no inter-annotator agreement statistics, introducing unknown label noise that the authors acknowledge 'inherently caps the upper limit of achievable model performance.'
- Geographic and material system bias is likely: Glazy is an English-language community platform, so recipes likely skew toward Western studio pottery traditions, specific raw material suppliers, and North American/European cone systems; generalization to industrial glazes or non-Western ceramic traditions is unvalidated.
- FID and LPIPS scores for the generative baselines are not reported in the available paper text (only RGB color distance is tabulated in Table 8); it is unclear whether these distribution-level metrics appear in appendices or were simply not computed, leaving the generation evaluation incomplete.
- The color label construction pipeline has a subtle methodological concern: the Random Forest and XGBoost models used to disambiguate training-set colors are trained on the test set, meaning model selection for test-set evaluation and label generation for training are not fully independent processes.
- No adversarial or out-of-distribution evaluation: all models are tested on held-out Glazy data from the same distribution; performance on novel material systems, extreme firing conditions, or industrial glaze chemistries is entirely unknown.
Open questions / follow-ons
- Can physics-informed neural networks or graph neural networks over the oxide reaction graph substantially outperform tree ensembles on property prediction, given the known nonlinear chemistry of silicate systems during firing?
- Would fine-tuning a vision-language model on GlazyBench's paired (recipe, image) data—rather than zero/few-shot prompting general LMMs—close the gap between attribute-conditioned and chemistry-conditioned image generation, and if so, how much paired data is required?
- How do models trained on GlazyBench generalize to industrial glaze databases (e.g., tile manufacturer or sanitaryware datasets) that use different raw materials, tighter process controls, and standardized imaging—can the UMF representation bridge this domain gap?
- The two-step pipeline propagates errors from property prediction into image generation; what is the quantitative degradation in image quality when predicted (rather than ground-truth) properties are used as generation conditions, and can joint end-to-end training mitigate this?
Why it matters for bot defense
At first glance this paper has no direct relevance to bot defense or CAPTCHA systems. However, there are two tangential connections worth noting for practitioners in this space. First, the dataset construction methodology—specifically the use of a model-voting ensemble to clean noisy community-sourced labels, combined with GrabCut-based foreground extraction and quality scoring—mirrors challenges in building training sets for visual CAPTCHA recognition and bot-behavior classifiers, where ground-truth labels are often noisy or ambiguous. The voting-based label arbitration approach (RF + XGBoost at 95.6% agreement) is a practical, reproducible technique applicable to any binary or multi-class label-cleaning problem over web-scraped imagery.
Second, the LMM evaluation finding is noteworthy: large multimodal models conditioned on low-level input features (chemical formula) fail to produce accurate visual outputs, while conditioning on high-level semantic attributes produces far better results. This 'conditional interpretability collapse' phenomenon—where a model cannot reliably translate structural/compositional inputs into perceptual outputs—is relevant to adversarial CAPTCHA research. Specifically, it suggests that CAPTCHAs grounded in domain-specific material or scientific knowledge (rather than generic visual semantics) may remain resistant to LMM-based solvers for longer, since these models lack the causal domain knowledge to bridge low-level input to high-level visual prediction. This is not a strong security claim, but it is an empirical data point on current LMM capability boundaries.
Cite
@article{arxiv2605_06641,
title={ GlazyBench: A Benchmark for Ceramic Glaze Property Prediction and Image Generation },
author={ Ziyu Zhai and Siyou Li and Juexi Shao and Juntao Yu },
journal={arXiv preprint arXiv:2605.06641},
year={ 2026 },
url={https://arxiv.org/abs/2605.06641}
}