
Directional Consistency as a Complementary Optimization Signal: The GONO Framework
Source: arXiv:2605.06575 · Published 2026-05-07 · By Victor Daniel Gera
TL;DR
This paper identifies and formalizes the direction-loss decoupling phenomenon in deep learning optimization, where directional consistency of consecutive gradients can be near perfect while loss remains high or decreases slowly. Existing optimizers like Adam, SGD, and RMSprop lack an explicit mechanism to leverage temporal consistency in gradient directions, relying mostly on gradient magnitude signals that conflate plateaus, saddle points, and true convergence. To address this, the authors introduce GONO, an Adam variant that adapts the momentum coefficient beta_1 dynamically based on the consecutive gradient cosine similarity (cc_t). By increasing momentum when gradients are directionally consistent and decreasing it during oscillation, GONO provably matches Adam's O(1/sqrt(T)) convergence rate and reduces exactly to Adam when the directional signal is uninformative.
Empirically, the consecutive cosine similarity achieves perfect oscillation detection (F1=1.00) vs 0.45 for gradient norm, validated on synthetic oscillatory functions and the Rosenbrock benchmark. On vision benchmarks like MNIST, CIFAR-10, and ResNet-18, GONO's performance is competitive with Adam and AdamW, establishing direction consistency as a theoretically grounded and practically useful additional optimization signal. The paper provides both rigorous theoretical proofs and comprehensive experiments supporting the adaptive momentum strategy based on directional alignment.
Key findings
- The direction-loss decoupling phenomenon: directional consistency (cc_t → 1) occurs well before loss convergence, demonstrated on multiple datasets (Figure 1).
- Oscillation detection using consecutive cosine similarity achieves F1 = 1.00, outperforming gradient norm detection F1 = 0.45 on a steep quadratic function (Table 1).
- On the Rosenbrock function, GONO outperforms SGD with momentum by converging within 3000 steps, adapting beta_1 during oscillatory narrow valleys.
- GONO matches Adam's theoretical O(1/sqrt(T)) convergence rate under standard assumptions (Theorem 2).
- On MNIST, GONO achieves 98.15% test accuracy vs. Adam's 97.08% and AdamW's 98.22%, with consistent training loss improvements (Table 2).
- On CIFAR-10 10k subset, GONO achieves 43.14% accuracy, comparable to AdamW (43.22%) and Adam (42.75%) (Table 3).
- On ResNet-18 with full CIFAR-10, GONO reaches 75.44% vs AdamW 76.88% and SGD-Momentum 66.22% (Figure 5), showing competitive performance.
- GONO's adaptive momentum beta_1 varies between 0.5 and 0.99, boosting momentum when cc_t near 1 and reducing it during oscillations (Figure 4).
Threat model
N/A. This paper focuses on gradient-based optimization dynamics and algorithmic improvement; no attacker or adversarial threat is modeled.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly the optimization dynamics including oscillation or plateaus encountered during training; no explicit adversarial attacker. The framework assumes standard smoothness and bounded gradient conditions common in non-convex stochastic optimization, with the ability to measure gradients and their temporal cosine similarity at consecutive steps.
Data: Experiments span synthetic functions and standard vision benchmarks. Synthetic data includes a noisy linear regression dataset (200 samples), a steep oscillating quadratic function for oscillation detection (100 steps), and the Rosenbrock function benchmark run for 3000 steps. Vision datasets are MNIST (60k train, 10k test), CIFAR-10 subsets (10k training subset and full 50k training set), and ResNet-18 architecture on CIFAR-10 original splits. Preprocessing and splits follow standard conventions.
Architecture / Algorithm: GONO modifies Adam's momentum coefficient β1 dynamically at each step using the consecutive gradient cosine similarity cct = ⟨∇Lt, ∇Lt-1⟩ / (∥∇Lt∥∥∇Lt-1∥ + ε). The adaptive β1,t is clipped within [β1_min=0.5, β1_max=0.99] and computed as β1 * (1 + λ * cct) with λ=0.4 controlling sensitivity. When consecutive gradients align (cct ≈ 1), β1,t exceeds baseline 0.9, amplifying momentum; when gradients oscillate (cct < 0), it reduces momentum to damp oscillations. All other Adam calculations for vt and parameter updates remain the same.
Training Regime: Synthetic experiments use fixed learning rates and small batch or single-step SGD or Adam to stress test oscillations and plateau detection. Vision tasks are trained with standard hyperparameters: MNIST MLP trained 25 epochs with batch size 128 and learning rate 10^-3; CIFAR-10 MLP trained 20 epochs with batch size 64 and learning rate 10^-3 on 10k subset; ResNet-18 trained on full CIFAR-10 with typical settings. Each experiment is averaged over 3 or 5 seeds to capture variability.
Evaluation Protocol: Metrics include test accuracy for vision benchmarks, training loss, and oscillation detection F1-score on synthetic functions. Baselines compared are SGD-momentum, Adam, and AdamW. Ablations include setting λ=0 (reduces GONO to Adam) and tuning oscillation detection thresholds. Statistical significance or variance is reported using mean ± std over seeds.
Reproducibility: Code is available on GitHub. The datasets used are publicly available standard benchmarks except synthetic and Rosenbrock which are fully described. The adaptive β1 update requires storing one previous gradient vector and computing one dot product per step. Details on hyperparameters, clipping, and sensitivity are clearly documented. No pretrained closed datasets are used.
Technical innovations
- Identification and formalization of the direction-loss decoupling phenomenon: perfect consecutive gradient alignment does not guarantee loss convergence.
- Introduction of consecutive cosine similarity (cct) as a reliable, computationally cheap signal to detect gradient oscillations with perfect detection (F1=1.00), outperforming gradient norm-based detectors.
- Adaptive momentum coefficient β1,t in Adam framework based on cct, amplifying momentum during directional consistency and reducing it to damp oscillations.
- Proof that GONO matches Adam’s theoretical O(1/sqrt(T)) convergence rate under standard smoothness and bounded gradient conditions.
Datasets
- Synthetic linear regression — 200 samples — generated per experiment details
- Steep quadratic function — 100 steps — synthetic benchmark for oscillation detection
- Rosenbrock function — synthetic test function with classical benchmark settings
- MNIST — 60k train, 10k test — public standard vision dataset
- CIFAR-10 subset — 10k train subset, test standard — public dataset
- CIFAR-10 full — 50k train, 10k test — public dataset
Baselines vs proposed
- Gradient norm oscillation detector: F1 = 0.45 vs Consecutive cosine detector: F1 = 1.00 on oscillating quadratic function
- SGD-momentum: failed to converge on Rosenbrock within 3000 steps (final loss 2.05) vs GONO converged
- MNIST test accuracy - SGD-momentum: 97.23% vs Adam: 97.08% vs AdamW: 98.22% vs GONO: 98.15%
- CIFAR-10 (10k subset) test accuracy - SGD-momentum: 43.89% vs Adam: 42.75% vs AdamW: 43.22% vs GONO: 43.14%
- ResNet-18 on CIFAR-10 test accuracy - SGD-momentum: 66.22% vs AdamW: 76.88% vs GONO: 75.44%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06575.
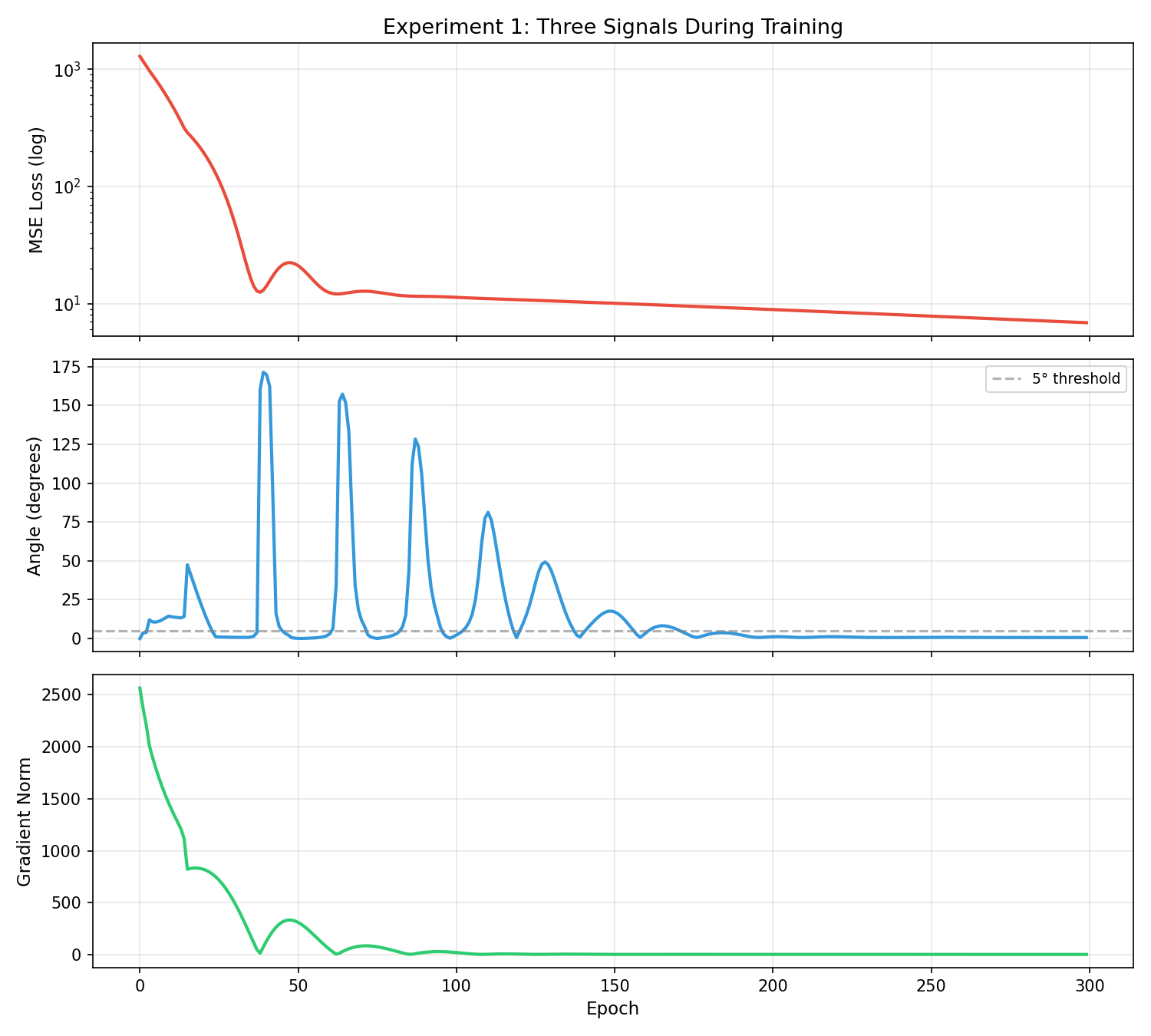
Fig 1: Three signals during a 300-epoch training run (Experiment 1). Top: MSE loss (log scale).
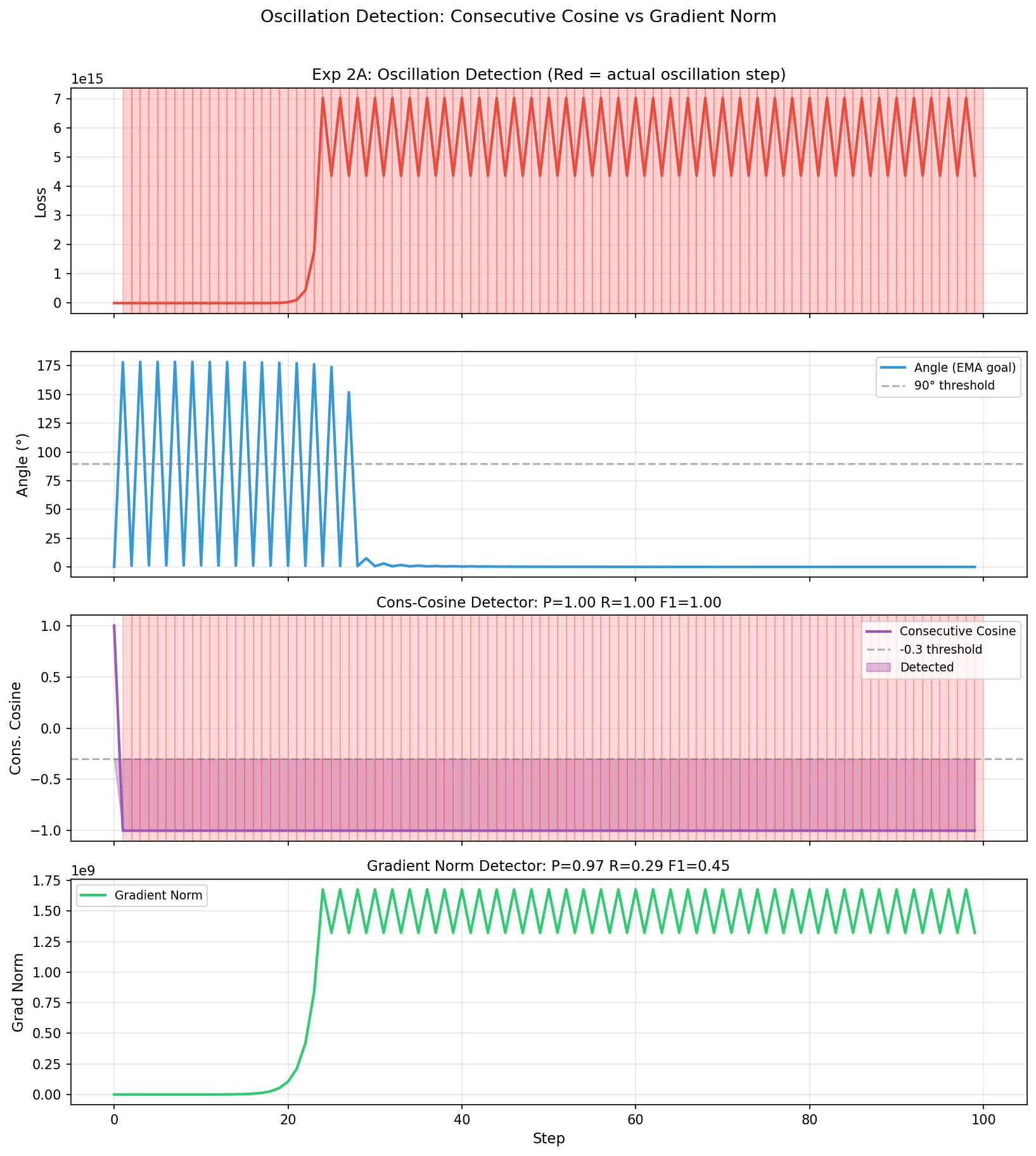
Fig 2: Oscillation detection comparison (Experiment 2A). Red background = actual oscillating
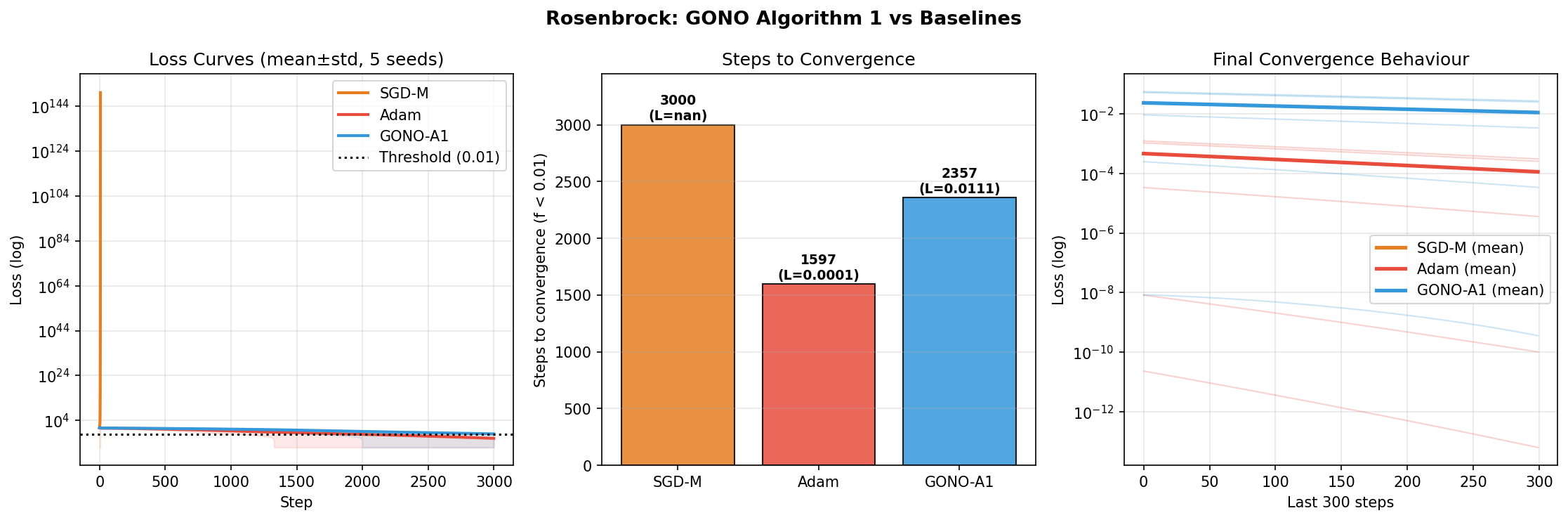
Fig 3: Rosenbrock optimization (Experiment 2B). Left: Loss curves (mean ± std, 5 seeds).
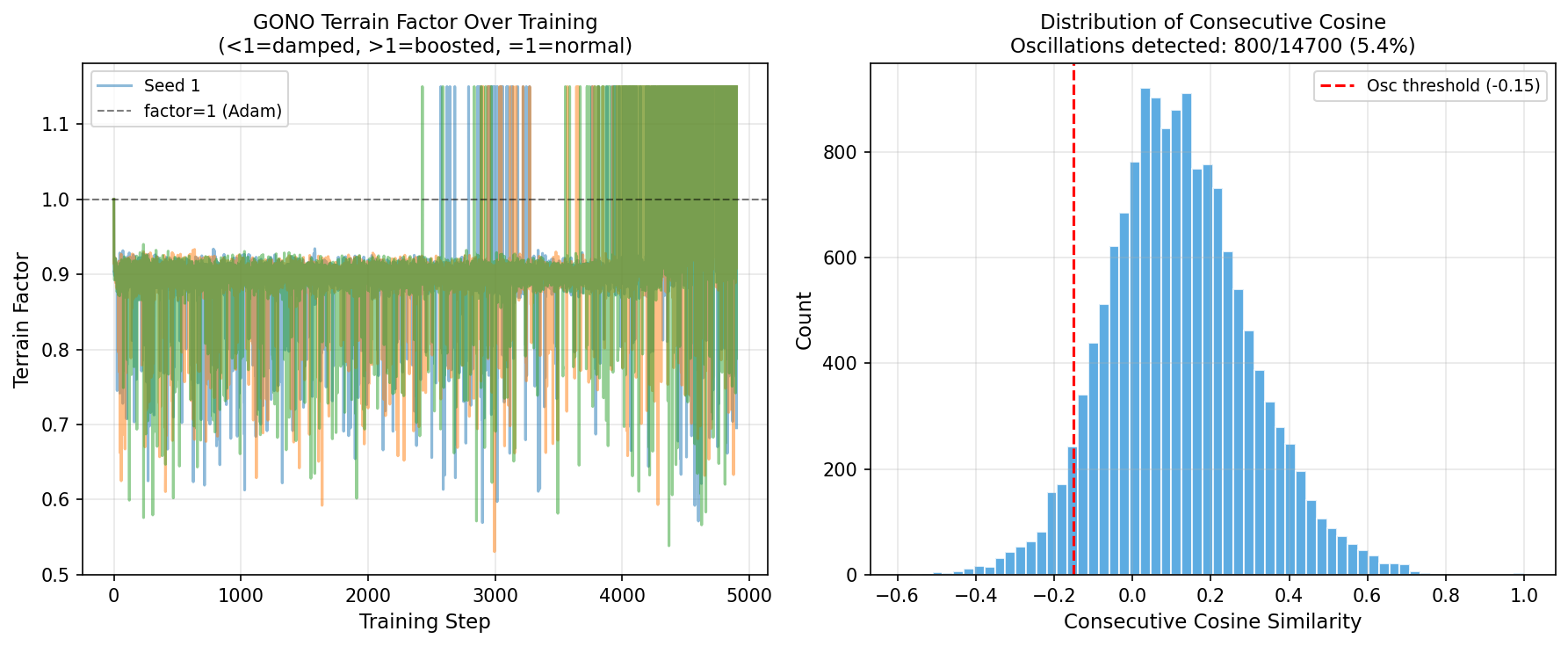
Fig 4: GONO adaptive behavior on MNIST. Left: Terrain factor (β1,t/β1) over training steps.
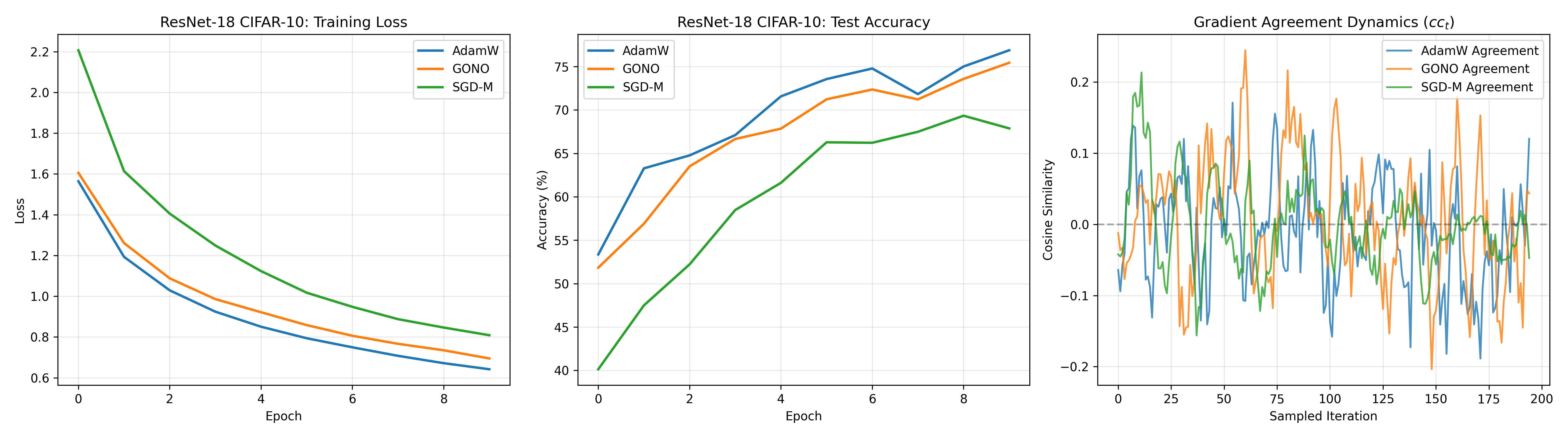
Fig 5: ResNet-18 on CIFAR-10 (Experiment 5). Left: Training loss. Center: Test accuracy.
Limitations
- GONO is demonstrated mainly as a complementary signal; no claim it's universally better than Adam or AdamW in all settings.
- Empirical gains on standard vision benchmarks are modest; directionality signal mostly improves dynamics in synthetic or oscillatory scenarios.
- Adaptive β1 requires storing and computing previous gradient; slight added overhead and slightly more hyperparameters (λ, β1,min, β1,max).
- Bias correction in adapting β1,t uses base β1 and not exact adaptive decay, introducing scaling errors in early steps—though asymptotic rates hold.
- No adversarial or distribution shift robustness evaluation to test the optimizer’s behavior under different real deployment challenges.
- Experiments average over small number of seeds (3-5), limiting full statistical power.
Open questions / follow-ons
- Can directional consistency signals improve large-scale training with state-of-the-art architectures beyond ResNet-18?
- How does adaptive momentum based on consecutive cosine similarity interact with other adaptive optimizers like Lion or AMSGrad?
- Can the consecutive cosine signal be leveraged for adaptive learning rate or second-moment tuning beyond momentum?
- How robust is GONO under real-world noisy gradients, adversarially perturbed training, or data distribution shifts?
Why it matters for bot defense
For bot-defense practitioners focused on training robust machine learning models underlying CAPTCHA or bot risk scoring, this work highlights a new complementary optimization signal to improve training dynamics. Directional consistency offers a theoretically grounded signal beyond gradient magnitude for controlling optimizer momentum, which may help navigate plateaus or oscillations common in complex models. Practitioners might consider monitoring consecutive cosine similarity during training as a health metric or integrate adaptive momentum schemes like GONO to potentially accelerate convergence or stabilize training regimes susceptible to oscillation. While improvements on standard datasets are incremental, the framework provides novel insight into optimizing the training process itself, which can indirectly benefit CAPTCHA model robustness and efficiency. However, extensive testing in deployed bot-defense models and adversarial scenarios remains needed.
Cite
@article{arxiv2605_06575,
title={ Directional Consistency as a Complementary Optimization Signal: The GONO Framework },
author={ Victor Daniel Gera },
journal={arXiv preprint arXiv:2605.06575},
year={ 2026 },
url={https://arxiv.org/abs/2605.06575}
}