
Algospeak, Hiding in the Open: The Trade-off Between Legible Meaning and Detection Avoidance
Source: arXiv:2605.06619 · Published 2026-05-07 · By Jan Fillies, Ronald E. Robertson, Jeffrey Hancock
TL;DR
This paper addresses the challenge posed by Algospeak—deliberate linguistic modulation by malicious actors to evade automated content moderation while preserving human understandability. The authors formalize the trade-off between the degree of Algospeak-induced text modulation, detection likelihood by classifiers, and comprehension by human or LLM interpreters. They introduce the concept of Majority Understandable Modulation (MUM), the modulation level at which further alterations improve evasion but reduce understanding for most recipients. To study this, the paper presents a novel, reproducible dataset of 700 COVID-19 misinformation statements across five modulation levels and seven distinct Algospeak strategies. Seven different large language models (both open- and closed-source) are evaluated as detectors and interpreters, using logistic curve fitting and rank correlation to quantitatively characterize the trade-off. The results demonstrate consistent monotonic declines in detection and understanding as modulation increases, with strategy-dependent effects and model-specific sensitivity variation. The work lays a formal foundation for Algospeak research, providing dataset, framework, and experimental protocols, and revealing insights about the evolving adversarial dynamics of language in LLM-moderated environments.
Key findings
- Increasing the level of Algospeak-style modulation systematically decreases LLM classifier detection rates across seven different modulation strategies and seven LLMs, with 86% of (model, strategy) pairs showing statistically significant monotonic decreases in detection accuracy (p < 0.05).
- The Majority Understandable Modulation (MUM) threshold, estimated via logistic curve inflection points, varies by strategy; e.g., only 2.7 introduced code words cause 50% misclassification of misinformation, while paraphrasing requires 4.4 modulations for the same effect.
- Understandability measured by LLM reconstruction drops with increased modulation; code word strategy crosses 50% understanding threshold at fewer than 1 modulation on average, whereas phonetic and spelling alterations often do not cross it within the studied modulation range.
- Some modulation strategies like phonetic resemblance and spelling alteration show poor sigmoid curve fitting and produce less consistent declines in detection and understanding, remaining detectable and understandable even at high modulation levels.
- Detection and comprehension rely on partially disjoint signals in LLMs: detectors can flag anomalous patterns without necessarily reconstructing meaning, e.g., emoticon strategies are correctly detected but harder to reconstruct meaning from.
- Cross-model variability is substantial; Claude achieves significant monotonic trends for all strategies in understanding, while models like Mistral and Qwen only for 43%, highlighting differences in semantic reconstruction ability.
- The choice of evasion strategy impacts detection and comprehension more than the specific classifier model employed, suggesting moderation efforts may benefit from targeting specific linguistic modulations.
- Code-word introduction strategy shows near-perfect logistic fit for detection decline (adj. R²=0.99) and reconstruction decline (adj. R²=0.99), validating the proposed sigmoid formalization of Algospeak dynamics.
Threat model
The adversary is a malicious content creator aware of automated LLM-based content moderation systems who deliberately modulates language (Algospeak) to evade detection algorithms while preserving intended meaning for a human audience sharing some common ground. They cannot fully encrypt the message away from humans without losing communicativeness, and lack perfect knowledge about specific deployed moderation models but know the general detection mechanisms operate on linguistic cues.
Methodology — deep read
The authors formalize Algospeak as deliberate message distortion designed to evade LLM-based content moderation while preserving human-understandable meaning. The threat model assumes a malicious actor aware of automated content filters who modulates linguistic signals to maximize reach and evade detectors, while the audience shares common ground enabling comprehension despite modulation.
They created a novel dataset of 700 English COVID-19 misinformation examples, derived from 20 base sentences, modulated in five levels (~10%, 20%, 30%, 40%, 50% distortion) and seven Algospeak strategies: altered spellings (to known and unknown words), abbreviations, emoticons, paraphrasing, code words, repurposed words, and phonetic substitutions. Sentences were incrementally distorted starting from the most classifier-relevant words.
Seven large language models (e.g., GPT-4o-mini, Claude, Llama, Mistral, Qwen, Grok) served as detectors and interpreters. Detection was framed as binary misinformation classification using prompts standardized across trials. Interpretation was operationalized as reconstruction of modulated words compared by similarity threshold (95%) with original terms.
Each model was evaluated at each modulation level and strategy through repeated trials with fixed temperature=0 prompting. Logistic sigmoid curves were fit to detection and understanding performance across modulation levels, with parameters estimating slope and inflection points (MUM/IMUM). Spearman rank correlations tested monotonicity of trends. Majority voting was applied over repeated trials for stability.
Reproducibility is supported by detailed dataset construction methodology, model prompts, and evaluation metrics, though the dataset and code are not publicly released due to ethical concerns. The authors explicitly characterize this as a proof-of-concept focusing on COVID-19 misinformation in English, acknowledging domain and language scope limitations.
One concrete example: A misinformation sentence was modulated by replacing the top 6 influential words identified by GPT-4o with code words progressively at increasing levels, creating five variants. The models were separately evaluated on their ability to detect misinformation and reconstruct original meaning at each variant. Logistic curve fits produced MUM estimates, showing how much distortion can degrade detection yet maintain interpretation up to a threshold.
Overall, the methodology combines rigorous theoretical formalization of linguistic modulation dynamics with extensive empirical LLM testing under controlled and realistic adversarial scenarios, enabling quantitative insights into Algospeak evasion and the detection-understanding trade-off.
Technical innovations
- Formalization of Algospeak linguistic evasion as a joint action model capturing the trade-off between modulation level, detector evasion, and human/LLM interpretability, extending Clark’s joint action theory to machine-adversarial communication contexts.
- Introduction of the Majority Understandable Modulation (MUM) metric quantifying the modulation inflection point at which additional message distortion improves evasion at the cost of majority comprehension loss, operationalized via logistic sigmoid modeling.
- Development of a reproducible framework to systematically generate meaning-preserving Algospeak variants across multiple strategies and tunable modulation intensity, enabling quantitative cross-strategy and cross-model comparison.
- Empirical evaluation methodology using seven diverse LLMs as both content detectors and interpretability models, coupling misinformation classification with semantic reconstruction as proxy for understanding.
- Demonstration that detection and semantic reconstruction rely on partially disjoint cues, suggesting current LLM detectors can flag anomalous patterns without full semantic comprehension, highlighting vulnerabilities in moderation pipelines.
Datasets
- COVID-19 Misinformation Modulated Dataset — 700 examples (20 base sentences × 5 modulation levels × 7 strategies) — researcher-generated, not publicly released
Baselines vs proposed
- Code word strategy detection with GPT-4o-mini: adjusted R² = 0.990 vs unknown-word strategy detection adj. R² = -1.065
- Understandability for code word strategy, GPT-4o-mini: adjusted R² = 0.995 vs phonetic strategy adjusted R² = -0.145
- Across models, detection Spearman correlations mostly above 0.98 for modulations increasing, with 86% of pairs significant (p < 0.05) vs understandability correlations significant in only 67% of pairs
- IMUM (Individual Majority Understandable Modulation) for code word strategy ~2.7 modulations to cause 50% detection failure vs 4.4 modulations for paraphrasing
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06619.
Fig 1: Results reveal the characteristic relationships between understandability

Fig 2: Example misinformation item with five levels of modulation.
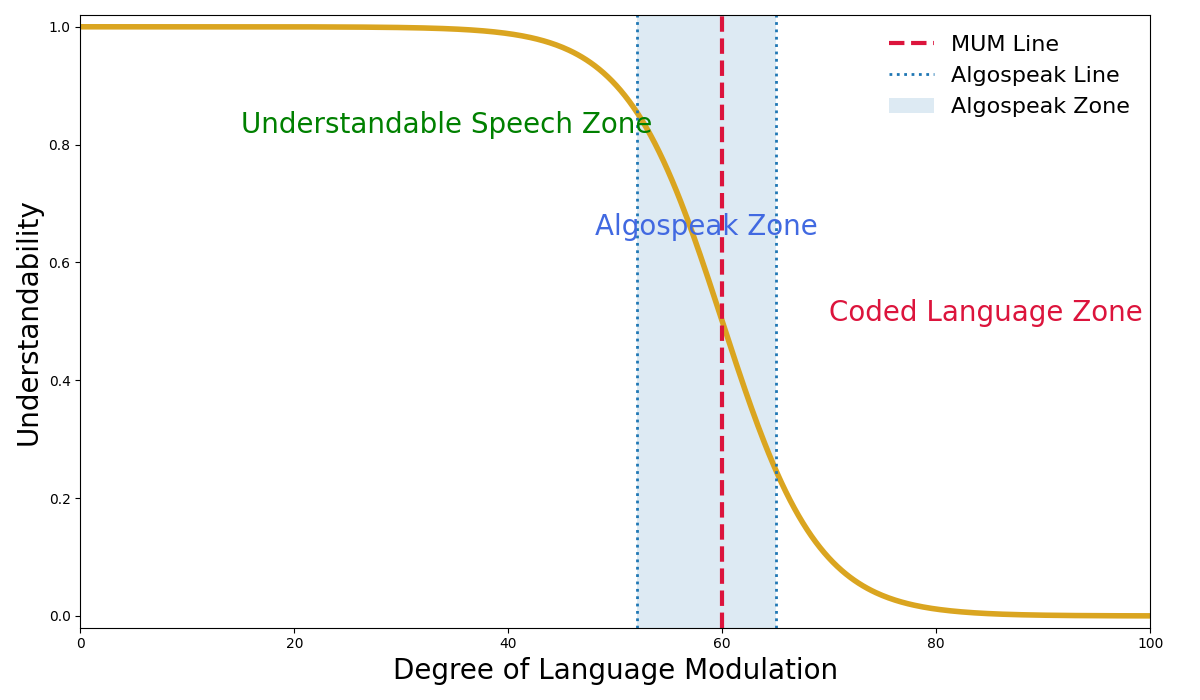
Fig 3: Overview of the relationship between modulation and understandability.
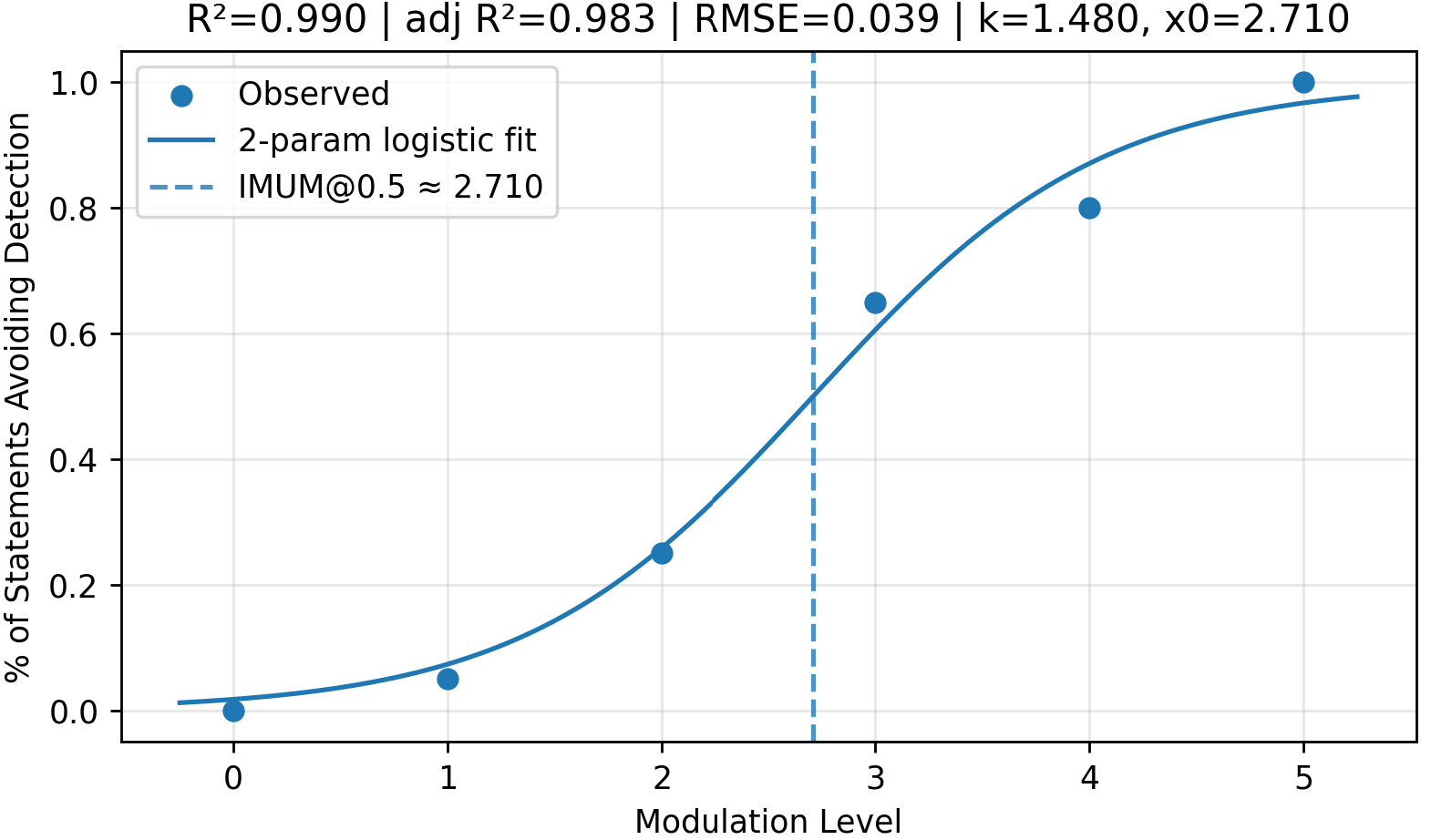
Fig 4: Example results for two of the seven Algospeak strategies for the model GPT-4o-mini.
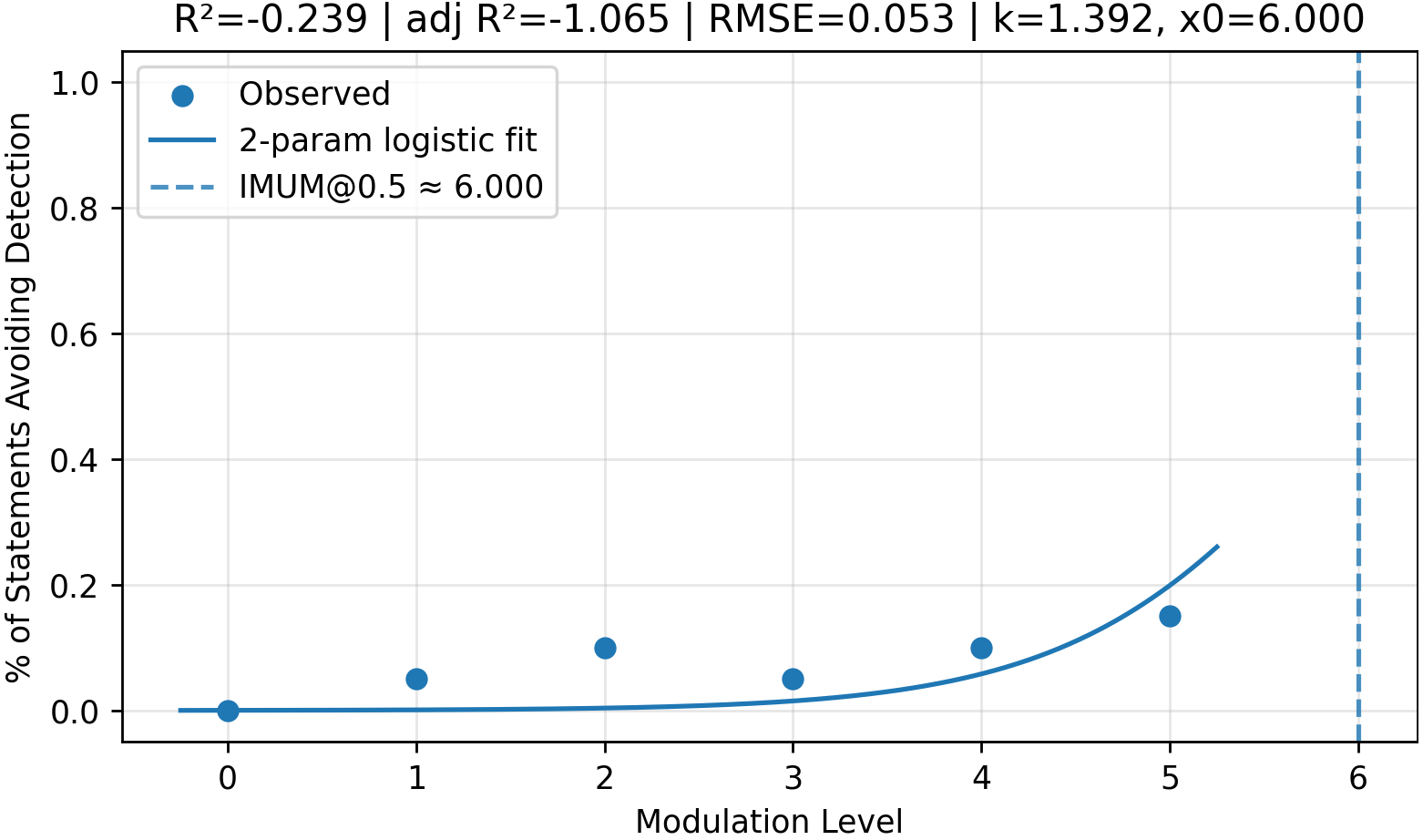
Fig 5 (page 5).
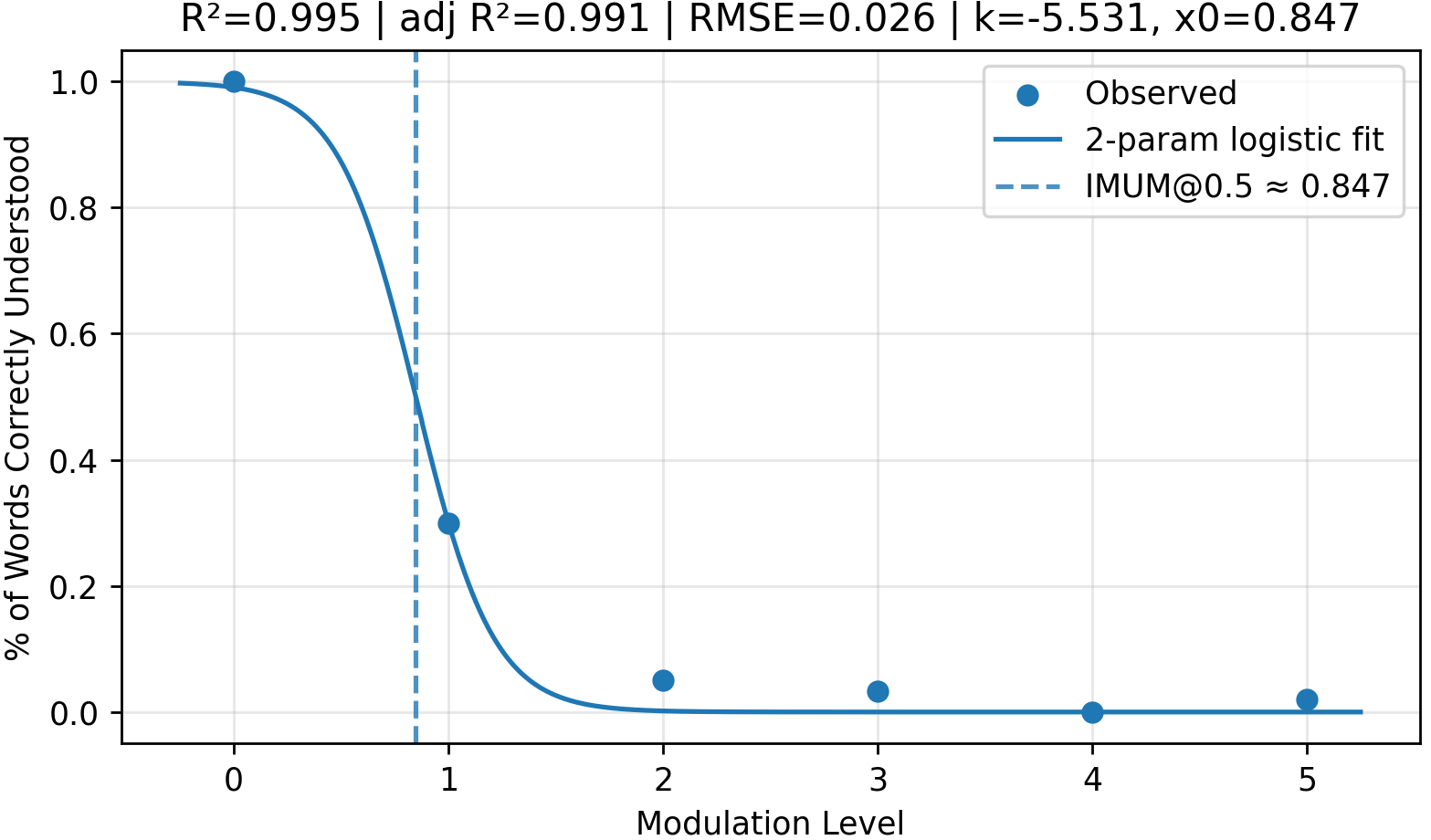
Fig 6 (page 5).
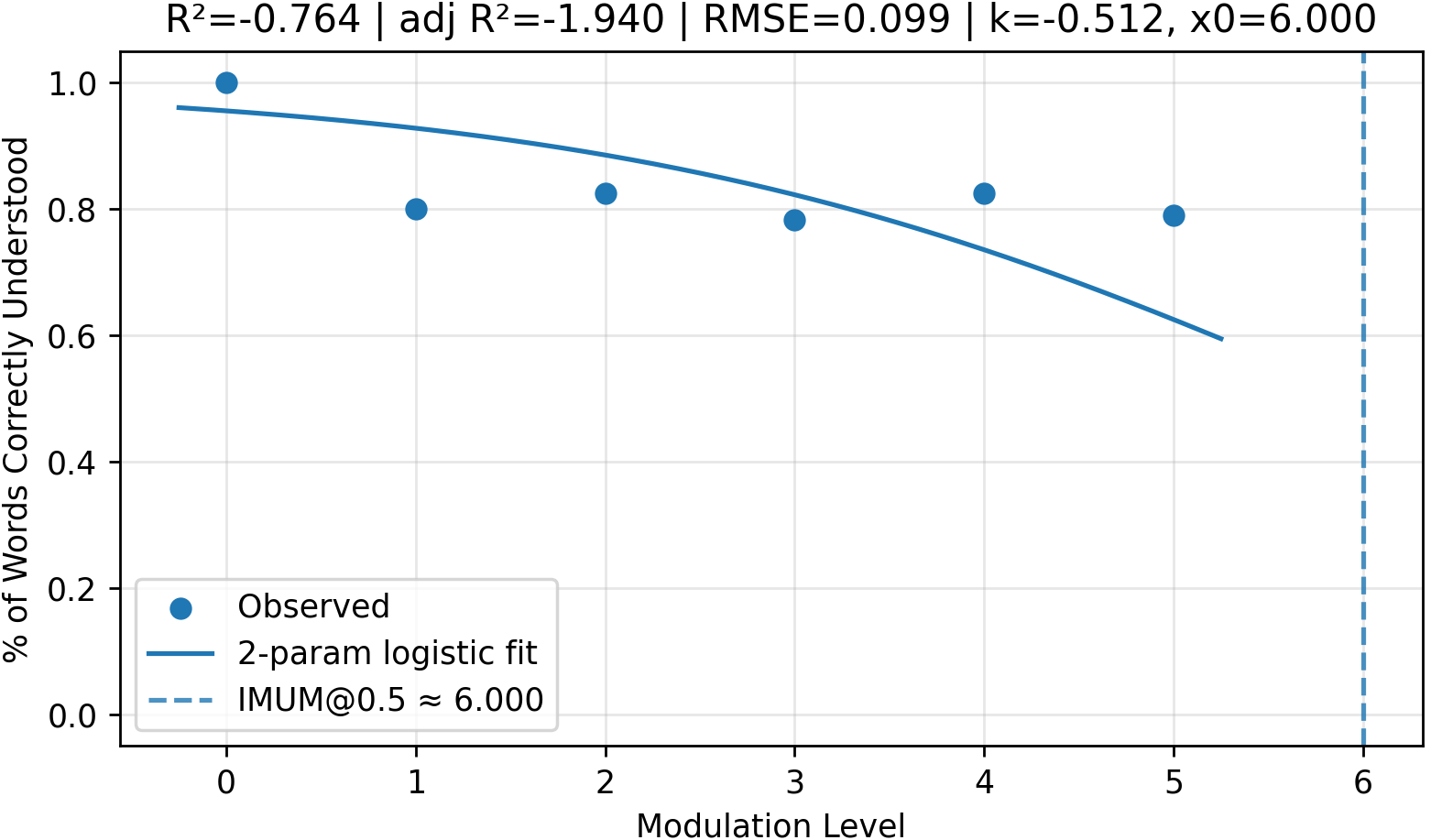
Fig 7 (page 5).
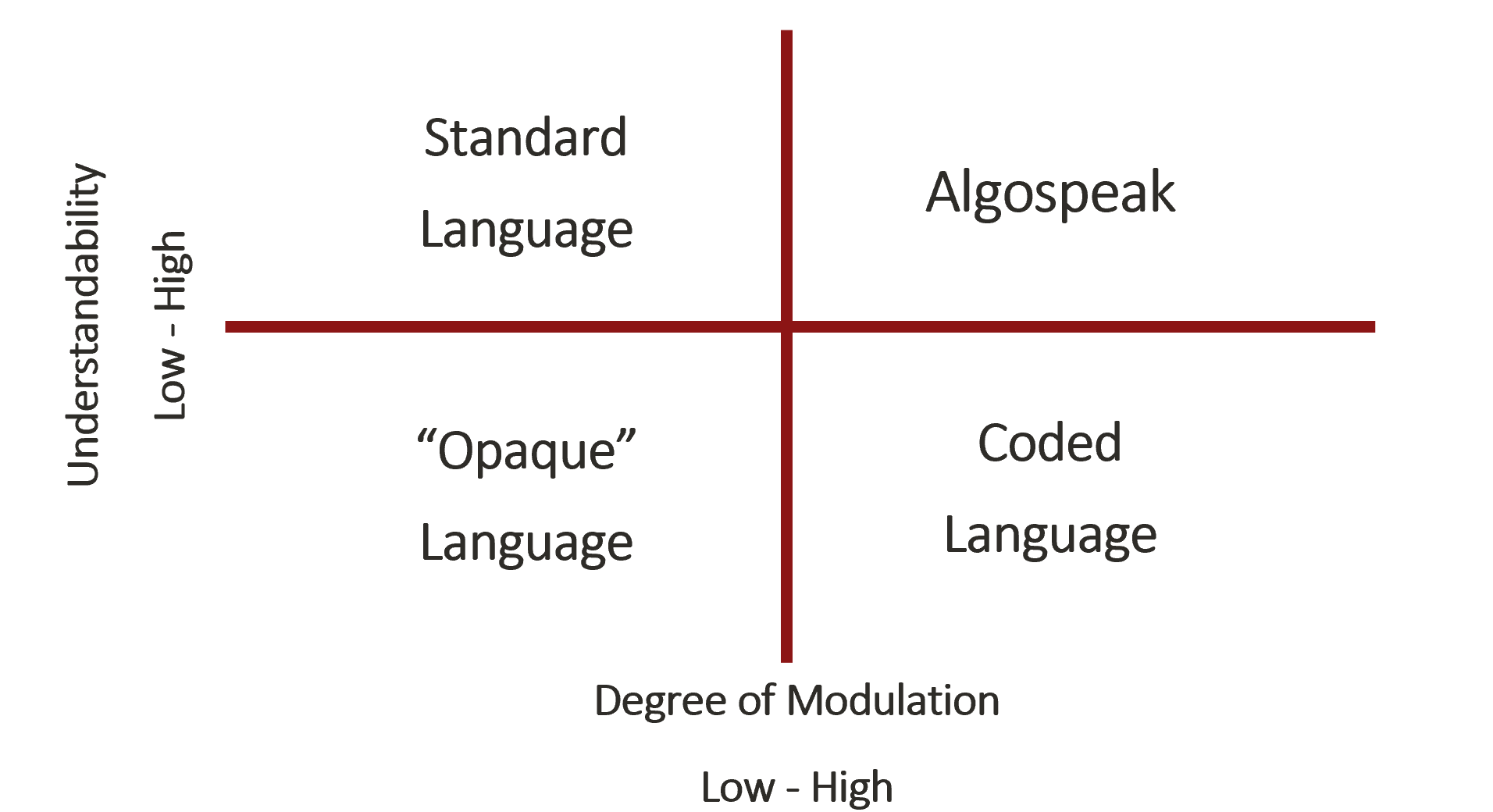
Fig 5: Classifications of language based on modulation and understandability.
Limitations
- Experiments conducted exclusively via LLM-based proxies for human comprehension; no human-subject validation yet to confirm cognitive interpretation versus LLM semantic reconstruction.
- Dataset limited to 20 base English COVID-19 misinformation sentences, constraining semantic and topical diversity and possibly inducing memorization effects.
- Human-authored modulations may differ from organic Algospeak variants seen in-the-wild, limiting ecological validity.
- Only English language evaluated; linguistic modulation and Algospeak strategies might vary substantially in other languages or cultures.
- Limited number of modulation levels (five) restricts granularity of threshold determinations and curve fitting precision.
- Detection and understandability relationship modeled primarily through logistic curve fits without robustness evaluation under adversarial or distribution shift scenarios.
Open questions / follow-ons
- How do human comprehension and cognitive effort correlate with LLM-based semantic reconstruction metrics across Algospeak modulation?
- Can Algospeak detection be enhanced by joint modeling of semantic reconstruction and classification, bridging the gap between detection and understanding cues?
- How do modulation strategies and MUM thresholds vary across different languages, cultural contexts, and content domains (e.g., hate speech, political manipulation)?
- What are the dynamics of Algospeak evolution over time under adversarial feedback loops with evolving moderation models?
Why it matters for bot defense
This work offers bot-defense and CAPTCHA practitioners a rigorous framework for understanding how adversarial linguistic evasion (Algospeak) degrades the efficacy of LLM-based content detectors while maintaining human-legible meaning. The formal definition of Majority Understandable Modulation (MUM) provides an operationalizable boundary for the trade-off between evasion success and communicative reach, informing thresholds at which automated moderation systems might fail.
From a defensive stance, the findings highlight that detection models need to incorporate robustness not only against explicit textual alterations but also subtler semantic-preserving modulations that evade surface-level cues. The dataset and multi-strategy evaluation methodology can guide red-teaming analyses and robustness evaluation for content moderation. Moreover, the insight that detection and semantic understanding differ supports developing defenses leveraging both anomaly detection and semantic reconstruction signals to reduce false negatives in adversarial settings. This paper thus deepens practitioner knowledge about the evolving linguistic game between malicious actors and automated detectors, critical to designing resilient bot and content moderation pipelines.
Cite
@article{arxiv2605_06619,
title={ Algospeak, Hiding in the Open: The Trade-off Between Legible Meaning and Detection Avoidance },
author={ Jan Fillies and Ronald E. Robertson and Jeffrey Hancock },
journal={arXiv preprint arXiv:2605.06619},
year={ 2026 },
url={https://arxiv.org/abs/2605.06619}
}