
The Single-File Test: A Longitudinal Public-Interface Evaluation of First-Output LLM Web Generation with Social Reach Tracking
Source: arXiv:2605.06707 · Published 2026-05-06 · By Diego Cabezas Palacios
TL;DR
This paper presents an eight-week longitudinal observational study comparing four frontier LLM families (GPT, Gemini, Grok, Claude) on one-shot single-file HTML/CSS/JavaScript generation tasks. The study, conducted through public chat interfaces without API access or iterative prompting, is motivated by the gap between standard coding benchmarks and the realistic challenge of producing a complete, usable, interactive web application in a single pass. It also layers on a social-media distribution protocol and uses the resulting tracker data to fit two exploratory predictive models.
The evaluation framework combines a partially blinded human scorer and a video-based Gemini LLM-as-a-judge layer, both scoring rendered browser recordings (not source code) along three dimensions: Prompt Adherence (PA, weight 0.40), Functional Correctness (FC, weight 0.35), and UI Quality (UI, weight 0.25). Across 17 experiments and 68 total generations, Claude was the strongest and most consistent family by human weighted score, winning 9 of 17 prompts outright. Notably, longer visible reasoning time was not positively correlated with quality overall (Spearman rho = -0.094, p = 0.443), and within the Gemini family the correlation was actively negative.
Two supervised predictive analyses were run on the 17-experiment tracker. A Lasso-screened Ridge regression for predicting 24-hour X (Twitter) impressions failed under leave-one-out cross-validation (MAE = 46,874, R² = -0.377), indicating that pre-publication technical and audio variables carry little predictive signal for social reach at this sample size. A generation-level Ridge model predicting HTML line count performed materially better (MAE = 135.2, R² = 0.576), with a model-family-only baseline outperforming prompt-aware alternatives, indicating that code verbosity is determined far more by model family identity than by prompt wording.
Key findings
- Claude led all three human sub-scores and the weighted overall performance score (mean 8.51/10), winning 9/17 prompts outright and beating GPT on 10/17 paired comparisons (mean gap +0.55) and Grok on 15/17 (mean gap +2.44, Wilcoxon p = 0.003).
- Longer visible reasoning time did not predict higher quality across the full 68-generation dataset (Spearman rho = -0.094, p = 0.443); the slowest quartile of generations performed worse on average than faster groups.
- Within the Gemini family specifically, longer response time was negatively correlated with human-rated performance (Spearman rho = -0.577, p = 0.015) and longer reasoning time was also negatively correlated (Spearman rho = -0.540, p = 0.025), suggesting extra latency was a struggle signal rather than a quality signal for Gemini.
- Gemini as a video-based judge was systematically more lenient than the human evaluator, with the largest gap on Functional Correctness (human mean 7.58 vs. Gemini mean 8.37, Wilcoxon p = 0.0016) and Overall Performance (7.63 vs. 8.18, p = 0.0162); self-favoring bias was not ruled in or out due to underpowering (n = 17 experiment-level comparisons).
- Gemini produced nearly identical mean human performance to GPT (7.97 vs. 7.96) while using only 14.65 s of mean reasoning time versus 80.71 s for GPT, yielding the highest mean reasoning efficiency (0.67) among all families.
- GPT and Claude were the two verbose families, averaging 714.94 and 732.65 HTML lines respectively, while Grok was the most compact (193.76 lines) and also the weakest performer (mean 6.07/10).
- The X-impressions predictive model failed under leave-one-out cross-validation (MAE = 46,874, R² = -0.377), while the HTML-lines model succeeded with a family-only baseline (MAE = 135.2, R² = 0.576), showing model family is a strong driver of verbosity but tracked variables do not predict social reach.
- The first principal component of the 68-generation score matrix explained 92.8% of total variance across PA, FC, and UI, indicating strong co-movement of the three rubric dimensions—though this may reflect rubric overlap or halo effects from a single partially unblinded scorer rather than a true latent quality construct.
Methodology — deep read
Threat model and assumptions: This is not a security paper in the adversarial sense, but the study's internal validity rests on a fixed-protocol assumption: that public chat interfaces deliver comparable model access across the eight-week window. The paper explicitly acknowledges that 'public model availability, provider-side interface behavior, and platform context could not be experimentally randomized or held constant.' The adversary to validity here is interface drift, access-path heterogeneity (Claude was accessed via LMArena rather than Anthropic's native interface), and scorer partiality. Claude Opus was accessed through LMArena (opus-4.5-thinking-32k) rather than claude.ai, introducing a distinct confound relative to the other three families which used their native public interfaces.
Data provenance, size, and structure: The dataset comprises 68 model-level generations across 17 experiments collected between December 10, 2025 and February 4, 2026. Each experiment consists of one natural-language prompt issued to four model families (GPT, Gemini, Grok, Claude), producing four HTML artifacts. Prompts ranged from 10 to 123 words (median 20 words) and were identical across families within each experiment. No retries, repair prompts, or iterative steering were allowed; the first delivered output was treated as final. The tracker contains 48 columns per row covering timing, artifact metadata, human and Gemini sub-scores, social packaging variables, and 24-hour platform metrics. Social metrics (X impressions, likes, shares; TikTok and YouTube views and likes) were recorded manually 24 hours after each post. The dataset is not publicly released as a standalone artifact but is available through the GitHub repository alongside the tracker, notebook, and figures.
Scoring architecture: Human scoring was performed by the sole author on a 0–10 continuous scale across PA, FC, and UI. Critically, the author was not consistently blinded to model identity during scoring, which is a significant internal validity limitation. Gemini served as a secondary judge using a fixed prompt template generated by the Data Collection Program; Gemini scored the rendered browser recording video (not source code) in four separate blind chat sessions per experiment on a 1–10 integer scale, without being told which model produced each video. The weighted performance score S_i = 0.40·PA + 0.35·FC + 0.25·UI was computed automatically in the tracker from sub-scores; neither evaluator directly assigned the composite. The weights are author-specified heuristics, and sensitivity analyses using equal-weight, adherence-heavy, function-heavy, and UI-heavy alternatives are reported as the primary robustness check. PCA on the 68×3 score matrix revealed that the first eigenvalue explained 92.8% of variance, indicating strong co-movement across dimensions, though the paper appropriately flags potential halo effects.
Architecture and algorithm for predictive models: Two supervised regression models were fit on tracker data. For the X-impressions task (experiment level, n=17), a Lasso regression was first used to screen candidate predictors from pre-publication technical and audio variables (including video duration, BPM, reasoning time, HTML line count, and follower count), and then a Ridge regression was fit on the screened variables. Evaluation used leave-one-out cross-validation (LOOCV) given the tiny sample, producing MAE = 46,874 and R² = -0.377 — a negative R² indicating the model performs worse than predicting the mean. For the HTML-lines task (generation level, n=68), Ridge regression pipelines were compared under leave-one-experiment-out cross-validation. The key finding is that a model-family-only baseline (encoding family as a categorical predictor) achieved MAE = 135.2 and R² = 0.576, outperforming prompt-aware alternatives that added prompt wording features. The paper is transparent that these are diagnostic models, not deployed forecasting systems.
Training regime and hardware: No GPU training is involved in the predictive models; these are small linear regressions fit on at most 68 observations. The Data Collection Program (a local Python tool) handled workflow standardization, timing measurement, scoring prompt generation, and social template preparation. Timing was measured via a custom Python timing tool while using public web interfaces, capturing user-visible interaction phases rather than provider-internal compute time. The study explicitly notes that API-based measurements would likely differ.
Evaluation protocol: For model comparison, the primary metric is the human weighted performance score with Wilcoxon signed-rank tests for pairwise family comparisons. Prompt-level win counts (Table 3) and paired comparisons (Table 2) supplement the aggregate means. The sensitivity analysis across four weighting schemes serves as the main robustness check, and Claude remained the top family under all schemes. For the judge comparison, paired Wilcoxon signed-rank tests compare Gemini-minus-human differences per sub-score across outputs. There is no held-out test set for the model comparison itself — all 17 experiments constitute the full observational corpus. For predictive models, LOOCV is used but acknowledged to be unstable at n=17. The paper appropriately warns that the R² estimates should be read as 'unstable descriptive evidence of limited predictive signal.'
Reproducibility: The repository (https://github.com/diegocp01/html_ai_battle) contains the tracker, notebook, figures, prompt templates, and scoring prompt templates. The raw HTML outputs, browser recordings, and social media posts were preserved as part of the public experimental record on X/Twitter threads. However, exact model weights underlying the public interface responses are not reproducible, and interface drift means replication would access different model versions. One concrete end-to-end example: for a given experiment prompt, the author submits it to GPT-5.2 Extended Thinking via chatgpt.com, records reasoning time and total response time with the Python timer, saves the raw HTML, runs it in a browser, records a video, scores it on PA/FC/UI (0–10 scale), then sends the video to Gemini in a blind chat with the standard judging template to get a second set of PA/FC/UI scores (1–10 integer). The tracker auto-computes the weighted composite. The same steps repeat for Gemini, Grok, and Claude, and the four recordings are assembled into a 2×2 composite video posted to X with an AI-generated Suno soundtrack.
Technical innovations
- Fixed first-output-only public-interface protocol with no repair prompts or iterative steering, operationalizing a realistic end-user interaction condition that standard API-based benchmarks cannot replicate.
- Video-based LLM-as-a-judge evaluation where Gemini scores rendered browser recordings rather than source code, extending prior LLM-as-a-judge work (e.g., MT-Bench style) to a visually grounded, execution-based setting.
- Reasoning efficiency metric E_i = S_i / t_reason_i that makes the quality-latency tradeoff explicit and exposes nonlinear penalties for added reasoning time, distinguishing it from raw performance rankings used in prior coding leaderboards.
- Integrated social-distribution protocol with 48-column tracker linking technical generation metadata to 24-hour public platform outcomes, enabling exploratory predictive modeling of social reach from pre-publication variables.
- Standardized 2×2 composite video social post format with AI-generated soundtrack encoding human scores and observations, creating a replicable public audit trail for each experiment beyond what typical model comparison demos provide.
Datasets
- HTML AI Battle Tracker — 68 model-level generations across 17 experiments, 48 columns per row — non-public proprietary collection by the author, partially reproducible via GitHub repository at https://github.com/diegocp01/html_ai_battle
Baselines vs proposed
- Grok vs. Claude (human weighted performance, paired): Grok mean = 6.07/10 vs. Claude mean = 8.51/10; Claude wins 15/17 paired comparisons, mean gap +2.44, Wilcoxon p = 0.003
- GPT vs. Claude (human weighted performance, paired): GPT mean = 7.96/10 vs. Claude mean = 8.51/10; Claude wins 10/17 paired comparisons, mean gap +0.55
- Gemini vs. Claude (human weighted performance, paired): Gemini mean = 7.97/10 vs. Claude mean = 8.51/10; Claude wins 12/17 with 1 tie, mean gap +0.54
- Human vs. Gemini judge on Functional Correctness: human mean = 7.58 vs. Gemini mean = 8.37, gap +0.78, Wilcoxon p = 0.0016
- Human vs. Gemini judge on Overall Performance: human mean = 7.63 vs. Gemini mean = 8.18, gap +0.56, Wilcoxon p = 0.0162
- X-impressions Lasso+Ridge model (LOOCV, n=17): MAE = 46,874, R² = -0.377 — worse than predicting the mean
- HTML-lines model-family-only Ridge baseline (leave-one-experiment-out, n=68): MAE = 135.2, R² = 0.576 — outperforms prompt-aware alternatives
- GPT vs. Gemini reasoning efficiency: GPT mean reasoning efficiency = 0.31 vs. Gemini = 0.67, despite nearly identical mean human performance scores (7.96 vs. 7.97)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.06707.

Fig 1: Protocol overview of the fixed public-interface workflow and subsequent 24-hour platform-metrics
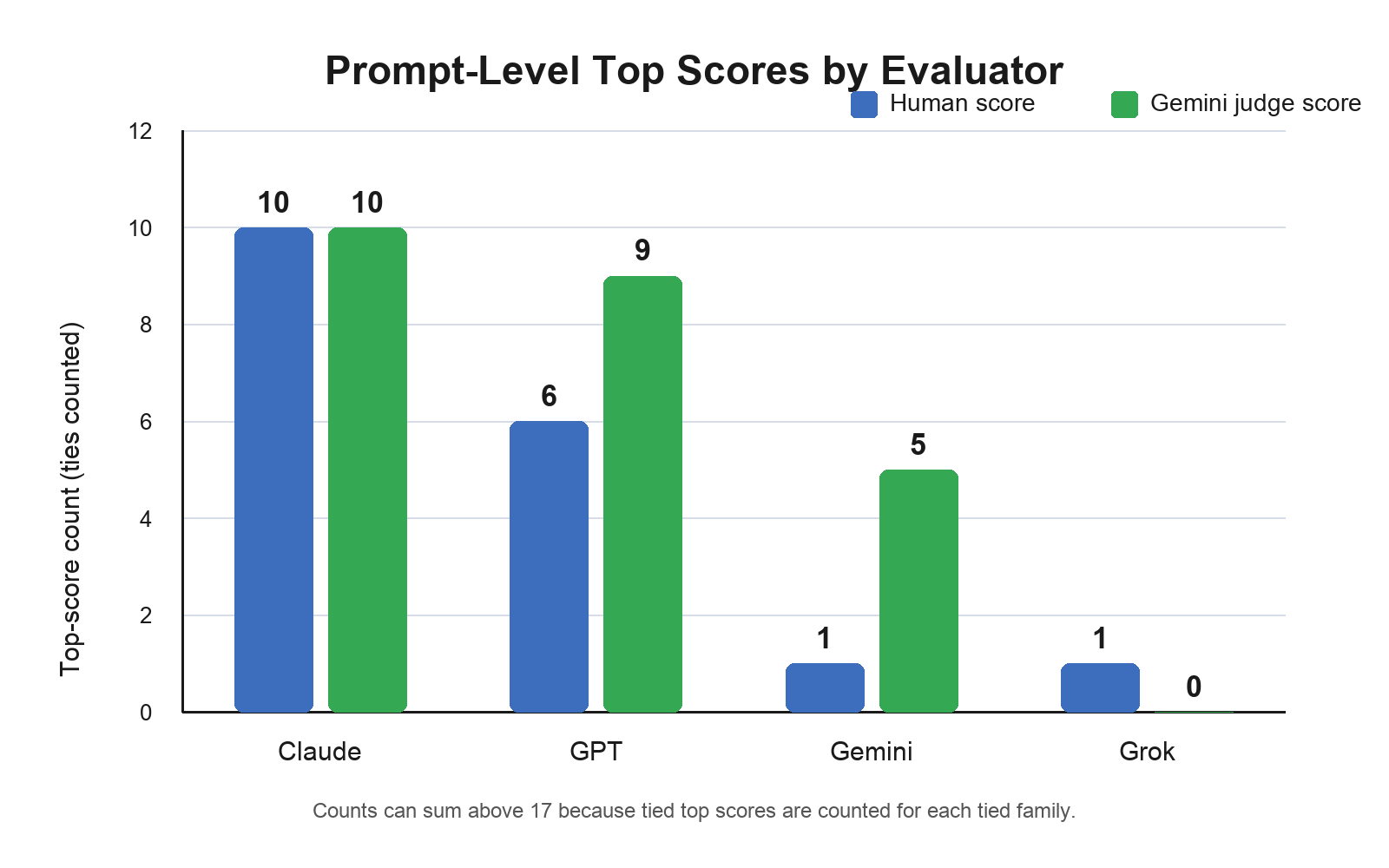
Fig 2: Prompt-level top-score counts by evaluator on weighted performance scores. Counts can sum above
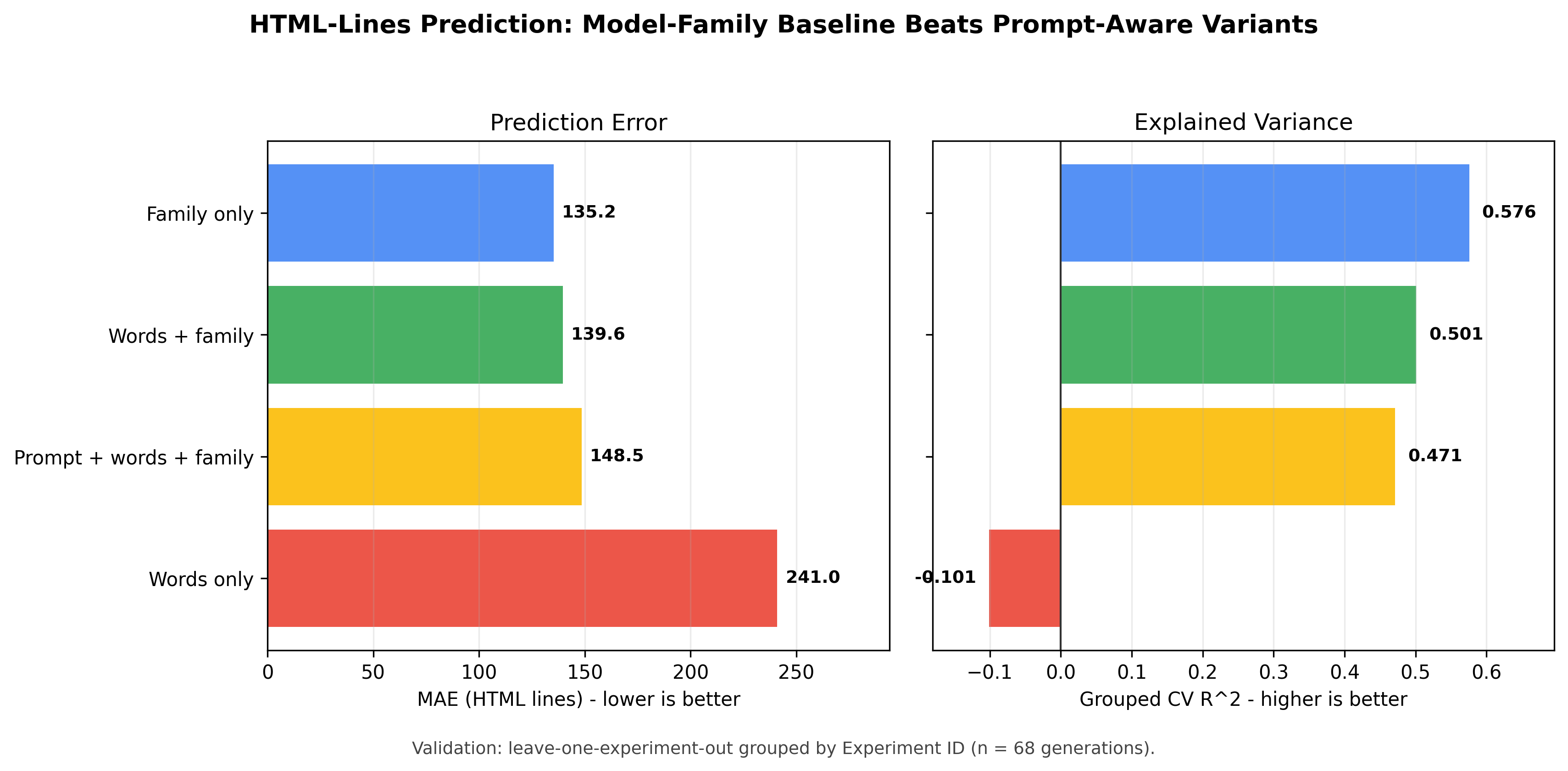
Fig 3: HTML-lines model comparison under leave-one-experiment-out evaluation.
Limitations
- Single partially unblinded human scorer: the author was not consistently blinded to model identity during scoring, introducing potential confirmation or familiarity bias that directly undermines the validity of the primary outcome measure; the 92.8% first-PC variance figure may partly reflect this halo effect rather than genuine rubric coherence.
- Severely underpowered sample: n=17 experiments and n=68 generations are far too small to support stable regression estimates, family-level Wilcoxon tests with adequate power, or resolution of the self-favoring bias question; the negative R² on the X-impressions model is a direct symptom of this.
- Claude accessed via LMArena rather than Anthropic's native interface, while GPT, Gemini, and Grok used their own native public interfaces — this access-path confound means differences attributed to 'Claude the model' may partly reflect LMArena's interface behavior, context window defaults, or system prompt differences.
- Public interface drift: model versions evolved across the eight-week window (GPT shifted from 5.1 to 5.2 Extended Thinking during collection), meaning early and late experiments may not be comparing the same underlying models, and the study cannot fully account for this version heterogeneity.
- No adversarial or distribution-shift evaluation: all prompts were chosen by the author and reflect a narrow range of web-toy/game/simulation tasks; generalizability to other prompt domains, languages, or application types is untested.
- Social reach confound: X follower count grew from 3,570 to 5,143 over the study period and was strongly negatively correlated with impressions (Pearson r = -0.828), meaning earlier experiments had different reach dynamics than later ones; the predictive model cannot disentangle account growth effects from content or technical quality effects.
- No inter-rater reliability measurement: only one human scorer and one automated judge are used with no second independent human annotator, making it impossible to quantify true human scoring reliability or to validate the Gemini judge against a gold standard.
Open questions / follow-ons
- Would a fully blinded, multi-rater human evaluation panel with formal inter-rater reliability measurement (e.g., ICC or Krippendorff's alpha) change the family rankings, particularly the GPT-vs-Gemini comparison which was close and weight-sensitive?
- Can the Gemini self-favoring bias question be resolved with a larger, pre-registered experiment using a broader set of LLM judges (e.g., GPT-4o, Claude as judge) scoring the same video recordings in a full factorial design?
- What drives code verbosity differences across model families at the architecture or training level — is it RLHF-induced verbosity, context window defaults, or instruction-tuning objectives — and does verbosity causally affect user-perceived quality or only correlate with it?
- Is there a causal relationship between reasoning time and quality, or does the negative-within-Gemini correlation reflect selection effects (harder prompts trigger longer reasoning and also produce worse outputs), and can this be separated with prompt-difficulty controls?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most operationally relevant finding is the systematic leniency of LLM-as-a-judge evaluation, particularly on functional correctness. If an automated judge (here Gemini, scoring rendered video) rates 'it runs' as equivalent to 'it fully satisfies the prompt,' then any quality gate or CAPTCHA-adjacent task that relies on LLM judgment to distinguish competent from superficial task completion will be miscalibrated. The gap was 0.78 points on a 10-point scale for functional correctness (p = 0.0016), which in a real deployment could translate to non-trivial false-pass rates for automated solvers that produce plausible-looking but functionally incomplete outputs. The unresolved self-favoring bias question is also directly relevant: if a CAPTCHA evaluation pipeline uses the same LLM family that is also a potential solver, the judge may systematically underestimate solver failure rates.
The finding that reasoning time does not predict quality — and within Gemini actively anti-predicts it — is relevant to latency-based bot detection heuristics. A naive assumption that 'more compute time implies human-like deliberation' is not supported here; Gemini achieved near-GPT performance in roughly 14 seconds of visible reasoning versus GPT's 80 seconds. Conversely, Grok spent 73.4% of response time in reasoning mode and produced the weakest outputs, so high reasoning-time fraction is not a reliable quality or humanity signal. Bot-defense engineers evaluating whether extended chain-of-thought is a meaningful behavioral signal for distinguishing human from automated task completion should treat this finding as a caution against over-indexing on reasoning duration as a proxy for task authenticity.
Cite
@article{arxiv2605_06707,
title={ The Single-File Test: A Longitudinal Public-Interface Evaluation of First-Output LLM Web Generation with Social Reach Tracking },
author={ Diego Cabezas Palacios },
journal={arXiv preprint arXiv:2605.06707},
year={ 2026 },
url={https://arxiv.org/abs/2605.06707}
}