
SEI-SHIELD: Robust Specific Emitter Identification Under Label Noise Via Self-Supervised Filtering and Iterative Rescue
Source: arXiv:2605.04721 · Published 2026-05-06 · By Ruixiang Zhang, Zinan Zhou, Yezhuo Zhang, Guangyu Li, Xuanpeng Li
TL;DR
SEI-SHIELD tackles a practical weakness in specific emitter identification: deep SEI models can look strong on clean data yet collapse when training labels are noisy due to channel ambiguity, annotation mistakes, or deliberate poisoning. The paper’s core claim is that prior noise-robust SEI methods still use corrupted supervision too early, so they learn contaminated features and then make noise filtering decisions from those same contaminated features. SEI-SHIELD tries to break that cycle by first learning representations without labels using MoCo on raw complex I/Q signals, then filtering noisy samples in that label-independent space, and finally rescuing some discarded hard-but-correct samples with confidence plus prototype similarity.
The reported result is that this decoupled pipeline gives state-of-the-art accuracy on the POWDER and ORACLE datasets across multiple synthetic noise rates, outperforming prior SEI noise-robust methods such as SSR and NR-SEI as well as several generic noisy-label baselines. The most important methodological novelty is not a new classifier head, but the sequencing: self-supervised feature learning first, then KNN-based label consistency filtering, then iterative recovery of clean hard cases. That ordering is what the authors argue reduces confirmation bias and makes the later sample selection steps much more reliable under heavy corruption.
Key findings
- SEI-SHIELD explicitly removes label information from the feature-learning stage by pretraining a MoCo encoder on raw complex-valued I/Q signals before any noise filtering or classifier training.
- The noise model is symmetric label noise with transition matrix T_{jk}=1-η on the diagonal and η/(C-1) off-diagonal; the paper evaluates robustness under varying noise rates η on POWDER and ORACLE.
- KNN filtering operates in the frozen self-supervised embedding space using neighborhood label consistency s_i = (1/k)∑1[ỹ_j=ỹ_i], which the authors use to partition samples into D_clean^(0) and D_discard^(0).
- The rescue mechanism is iterative: a lightweight classifier is retrained each round on the current clean set, and discarded samples are recovered using both maximum softmax confidence and cosine similarity to class prototypes.
- The paper claims the iterative rescue prevents irreversible loss of hard samples near decision boundaries, which is a known failure mode of one-pass sample selection methods like SSR.
- The authors report state-of-the-art accuracy under various noise rates on POWDER and ORACLE, but the excerpt provided does not include the exact percentages, so the magnitude of the gain cannot be stated from the supplied text.
- The framework is designed for complex-valued RF data, and the backbone uses complex convolution to preserve I/Q amplitude-phase coupling rather than treating I and Q as independent real channels.
Threat model
The adversary is a label-corrupting process in a non-cooperative SEI pipeline: channel-induced ambiguity, annotation mistakes, or deliberate poisoning by intelligent jammers that inject misleading signals into the training set. The learner does not know which labels are corrupted, does not know the noise transition matrix, and does not have a clean validation set. The paper assumes the adversary can corrupt labels but does not assume control over the full training procedure or the ability to directly tamper with the frozen self-supervised representation after pretraining.
Methodology — deep read
SEI-SHIELD is framed as a robustness problem in non-cooperative SEI, where an adversary or noisy pipeline can corrupt labels through channel-induced ambiguity, annotation error, or intentional poisoning. The paper’s threat model is not a white-box adversary against the learned classifier; it is a training-time label corruption setting. The authors assume the learner only sees a noisy labeled dataset D={(r_i, \tilde y_i)} and does not know the noise transition matrix T, does not have a clean validation set, and must still learn a device-authentication model that reflects true emitter identity rather than memorized noise. In the paper’s own emphasis, the harmful failure mode is confirmation bias: once the representation space is trained under noisy supervision, any later filtering based on that space is already biased.
The data are raw complex-valued RF I/Q captures from two real-world SEI benchmarks: POWDER and ORACLE. The excerpt does not give the exact sample counts, device counts, or train/test split ratios, so those details cannot be reconstructed reliably from the provided text alone. What is clear is that each received waveform is treated as a length-L sequence r in R^{2×L}, with the two channels corresponding to in-phase and quadrature components. The paper defines synthetic symmetric label noise via a transition matrix T: with probability 1-η a label stays correct, otherwise it is uniformly flipped to one of the other C-1 classes. The experiments are organized around varying η, and the method is intended to work without any access to clean labels for representation learning. Preprocessing is implicit in the signal framing: sampled RF signals are digitized I/Q arrays, then augmented with RF-specific transformations before contrastive training.
The architecture has three main stages. First is self-supervised contrastive pretraining with MoCo. The encoder is a complex-valued neural network (CVNN) built from Nb complex convolution blocks; each complex convolution uses real and imaginary kernels W_re and W_im and combines them so that both channels interact, preserving amplitude-phase coupling. After each block come ReLU, batch norm over the concatenated real-valued channels, and max pooling, followed by flattening and a fully connected embedding layer z_i=f_θ(r_i). On top of that embedding sits a 3-layer projection MLP g(z)=W3 σ(W2 σ(W1 z)). MoCo uses a query encoder f_q and a momentum-updated key encoder f_k, with parameters updated by EMA θ_k ← m θ_k + (1-m) θ_q. Positive pairs are two independently augmented views of the same RF sample, and negatives come from a FIFO queue of size K. The loss is standard InfoNCE. The RF augmentations are a notable design choice: seven operations simulate amplitude, temporal, and window-based distortions relevant to wireless channels, including amplitude scaling, magnitude warping, sign flip with channel permutation, temporal permutation, time warping, window slicing, and window warping. Each training sample is turned into two views by applying n_aug randomly chosen augmentations without replacement, with n_aug sampled uniformly from 2 to 4. The point is to preserve hardware fingerprints while varying channel-like nuisance factors.
Second is KNN-based noise identification in the frozen self-supervised embedding space. After pretraining, the projection head is discarded and only the encoder backbone is retained. Every training sample is mapped to an ℓ2-normalized feature vector on the unit hypersphere. For each point, the method finds its k nearest neighbors by cosine similarity and computes a neighborhood label consistency score s_i=(1/k)∑_{j∈N_k(i)}1[\tilde y_j=\tilde y_i]. Samples with s_i≥θ_knn are provisionally clean; the rest are discarded. The paper also adds a class-floor safeguard: if a class has fewer than n_min retained samples, some discarded samples from that class with the highest s_i are restored so every class remains trainable. The logic is that because the space is learned without labels, local neighborhoods should reflect emitter similarity rather than noisy annotations, making this filtering step less prone to confirmation bias than supervised sample selection.
Third is the iterative hard-sample rescue stage, which tries to undo over-aggressive filtering. At each round r, a lightweight classifier h_φ is trained only on the current clean subset D_clean^(r-1), again using the frozen self-supervised features as input. From this classifier the method derives a confidence score \hat p_i=max_c p_{i,c} and a predicted label \hat y_i. Separately, it constructs class prototypes μ_c^(r) by averaging the clean features of class c and renormalizing the centroid. For each discarded sample, the rescue decision combines the classifier confidence and the cosine similarity between the sample embedding and the prototype of the predicted class, sim_i=\hat z_i·μ_{\hat y_i}^{(r)}. The excerpt cuts off before the exact thresholding rule is fully visible, so the precise acceptance criterion is not recoverable here; however, the intended design is clear: samples supported by both a trustworthy classifier and geometric proximity to a class center are re-admitted. One concrete end-to-end example: a sample from an emitter class that was mislabeled due to channel confusion may be pushed out by KNN because its local neighborhood disagrees with its noisy label; after one or more rescue rounds, if the clean-set-trained classifier predicts its true class with high confidence and the feature is close to that class prototype, it is brought back into training rather than being permanently discarded.
For evaluation, the paper compares SEI-SHIELD against prior SEI-specific noise-robust methods, especially SSR and NR-SEI, and also against broader robust-learning paradigms such as regularization-based and sample-selection-based approaches. The metrics are classification accuracy under different noise rates, with the claim of SOTA across POWDER and ORACLE. The excerpt does not report any statistical significance testing, cross-validation, or held-out attacker evaluation details, so those aspects remain unclear. Likewise, the training hyperparameters are only partially visible in the provided text: MoCo has momentum m, queue size K, temperature τ, and the rescue loop runs for R rounds, but the exact numeric values, optimizer, epoch count, batch size, and seed strategy are not present in the excerpt. Reproducibility is therefore only partially assessable from the supplied material; the paper appears to be an arXiv preprint with a methods description, but the excerpt does not state whether code, weights, or splits were released.
Technical innovations
- A decoupled SEI pipeline that learns label-independent RF embeddings with MoCo before any noisy-label filtering is attempted, rather than using supervised features to decide what is clean.
- RF-tailored contrastive augmentations designed for raw complex I/Q signals, including amplitude-, temporal-, and window-based perturbations that simulate channel variation while preserving emitter fingerprints.
- A KNN-based noise detector that uses neighborhood label consistency in the learned embedding space to identify likely mislabeled samples.
- An iterative rescue mechanism that combines classifier confidence with prototype cosine similarity to recover correctly labeled hard samples that would otherwise be permanently discarded.
- A complex-valued CNN backbone used both for contrastive pretraining and final classification so the model preserves I/Q amplitude-phase coupling instead of flattening RF signals into unrelated real-valued channels.
Datasets
- POWDER — size not specified in the provided text — public/real-world RF dataset
- ORACLE — size not specified in the provided text — public/real-world RF dataset
Baselines vs proposed
- SSR: accuracy = not specified in the provided text vs proposed: SOTA accuracy under various noise rates
- NR-SEI: accuracy = not specified in the provided text vs proposed: SOTA accuracy under various noise rates
- advanced regularization techniques: accuracy = not specified in the provided text vs proposed: better accuracy under noisy-label conditions
- sample selection frameworks: accuracy = not specified in the provided text vs proposed: better accuracy under noisy-label conditions
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.04721.
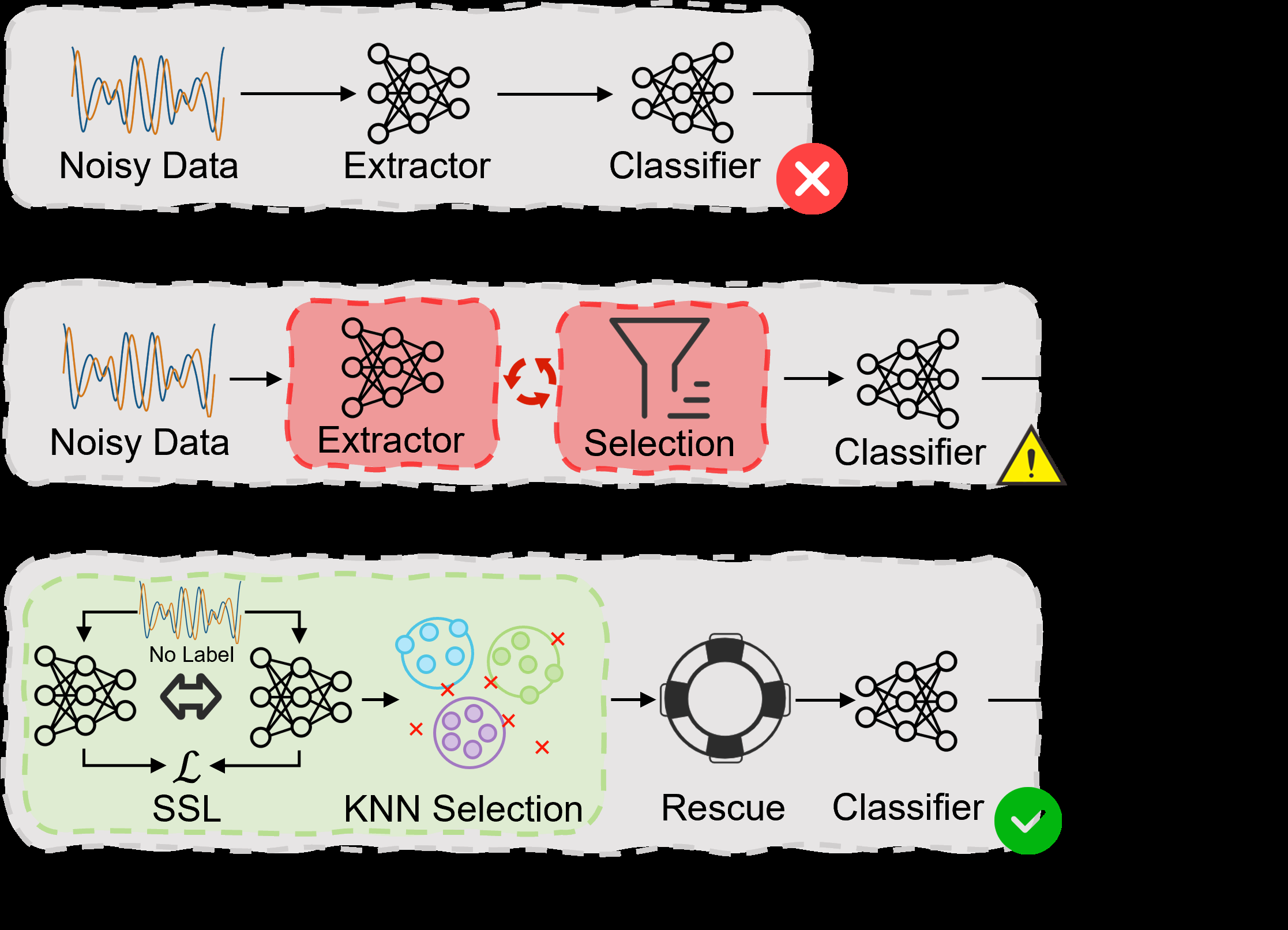
Fig 1: The paradigm evolution of label-noise robust SEI methods. (a) Tra-
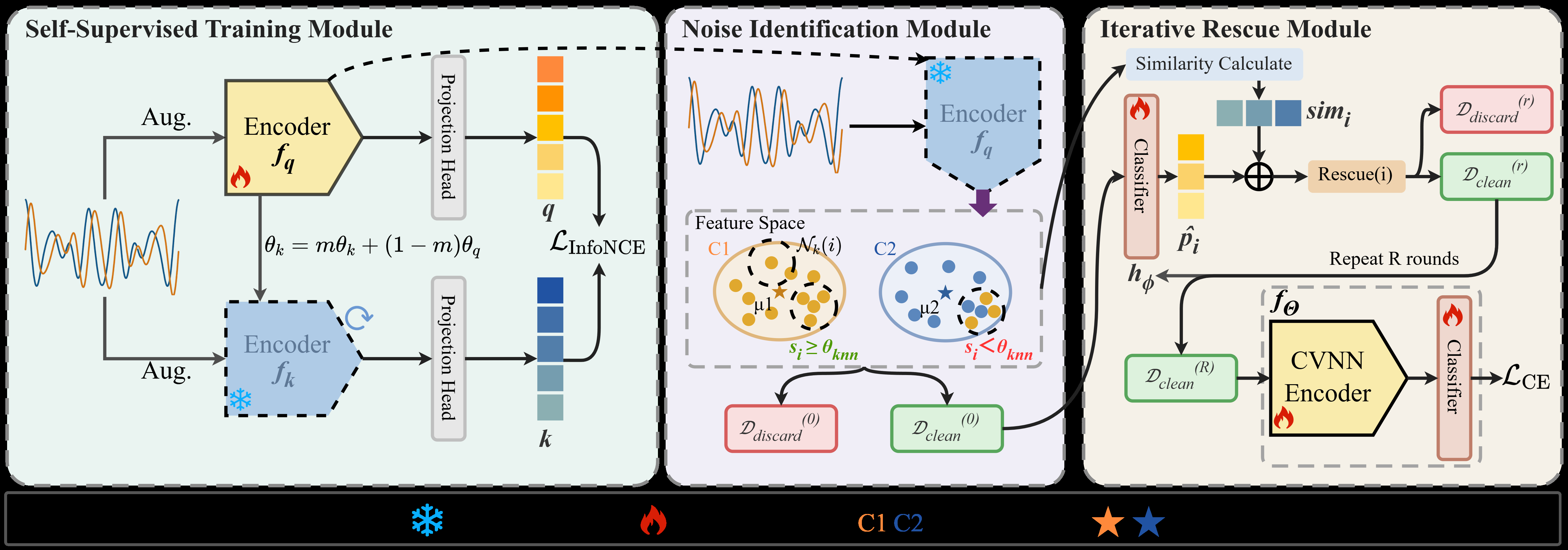
Fig 2: Framework of the proposed SEI-SHIELD. A self-supervised training module first learns label-independent signal representations from augmented raw

Fig 3 (page 14).
Limitations
- The excerpt does not provide the exact numerical results, so the size of the improvement over SSR, NR-SEI, or other baselines cannot be verified from the supplied text.
- Key experimental details are missing from the excerpt: exact dataset sizes, train/test splits, batch size, optimizer, learning rate, epoch counts, k in KNN, θ_knn, n_min, R, and the MoCo queue/momentum/temperature values.
- The evaluation described is primarily under symmetric label noise; robustness to asymmetric noise, class-dependent corruption, or realistic targeted poisoning patterns is not established in the excerpt.
- The method assumes the frozen self-supervised space is sufficiently clusterable for KNN filtering and prototype-based rescue; if classes overlap strongly or channel effects are highly nonstationary, this assumption may weaken.
- No adversarial evaluation against an adaptive attacker is described in the excerpt, so it is unclear how well the filtering/rescue pipeline would hold up if an attacker optimized poison samples against the learned representation.
- The excerpt does not show statistical uncertainty, confidence intervals, or repeated-seed variance, so robustness claims may depend on a single experimental run or undisclosed protocol.
Open questions / follow-ons
- How sensitive is the KNN filtering and rescue behavior to the choice of k, θ_knn, and the class-floor n_min, especially when class imbalance is severe?
- Does the self-supervised embedding remain stable under asymmetric or source-specific poisoning, where label noise is not uniform but correlated with device identity or channel conditions?
- Would a stronger iterative scheme, such as re-estimating prototypes with uncertainty weighting or using multiple embedding views, improve recovery of hard samples near class boundaries?
- How much of the gain comes from the MoCo pretraining versus the rescue stage alone, and how do those gains transfer to other RF tasks beyond SEI?
Why it matters for bot defense
For bot-defense practitioners, the main takeaway is not SEI itself but the training recipe: separate representation learning from noisy label cleanup. In CAPTCHA and abuse-detection systems, label contamination is common when human review is imperfect or attackers intentionally skew feedback signals. SEI-SHIELD suggests a practical pattern: first learn a label-independent embedding with self-supervision, then perform sample filtering in that feature space, and only then train the downstream classifier. That sequence is especially relevant when you suspect your current feature extractor is already overfitting to noisy moderation labels.
A second relevant idea is the rescue stage. In real anti-abuse systems, aggressive filtering often removes minority or boundary cases that matter for recall, especially when adversaries mimic legitimate users. The paper’s confidence-plus-prototype recovery strategy is a reminder to treat filtering as reversible, not final. For CAPTCHA-like defense, that could translate into re-admitting borderline examples if they are consistent with a trustworthy clean subset and a stable class prototype, instead of permanently discarding them after one noisy pass. The caveat is that this depends on having a feature space that is actually label-independent enough for neighborhoods and prototypes to mean something.
Cite
@article{arxiv2605_04721,
title={ SEI-SHIELD: Robust Specific Emitter Identification Under Label Noise Via Self-Supervised Filtering and Iterative Rescue },
author={ Ruixiang Zhang and Zinan Zhou and Yezhuo Zhang and Guangyu Li and Xuanpeng Li },
journal={arXiv preprint arXiv:2605.04721},
year={ 2026 },
url={https://arxiv.org/abs/2605.04721}
}