
Reward-Decomposed Reinforcement Learning for Immersive Video Role-Playing
Source: arXiv:2605.04733 · Published 2026-05-06 · By Miao Wang, Yuling Shi, Yijiang Li, Yeheng Chen, Xiaodong Gu, Bin Li et al.
TL;DR
This paper addresses a gap in role-playing agents: most systems can imitate a character’s style from text, but they remain weak at using visual scene context to modulate tone, tension, and situational appropriateness. The authors argue that in immersive settings like VR games or interactive narratives, a character’s response should be constrained not just by persona, but by what is visibly happening in the scene. To target that problem, they introduce EBM-RL (Eye-Brain-Mouth Reinforcement Learning), a decoupled GRPO-based framework that forces the model to produce three explicit stages: <perception> for observable visual facts, <think> for intermediate reasoning, and <answer> for the final role-play utterance.
The main novelty is a reward decomposition scheme that separately optimizes visual grounding, intermediate cognitive usefulness, answer faithfulness, and output formatting. The paper reports that this setup improves both visual-atmosphere consistency and character authenticity on a new video-grounded role-playing benchmark built from Harry Potter and Lord of the Rings movie scenes. They also claim that the model transfers zero-shot to out-of-domain VideoQA benchmarks without additional fine-tuning, suggesting the learned decomposition is not only helpful for role-play but also for general video understanding. The authors additionally release an open-source dataset and construction scripts for video-grounded dialogue.
Key findings
- The constructed dataset contains approximately 32k video-grounded role-playing samples, split by session id to prevent scene/topic leakage across train/test.
- EBM-RL's best variant (Char-EBM-CLIP-Max) reaches VEG 74.25, SPC 70.37, and CN 74.78, for an average of 73.13, beating Qwen2.5-VL-7B (69.17 avg) by +3.96 points.
- On SPC, Char-EBM-CLIP-Max improves over Qwen2.5-VL-7B by +5.32 points (70.37 vs 65.05), which the authors use as evidence that the decoupled 'think' stage helps situational persona control.
- On VEG, Char-EBM-CLIP-Max matches or exceeds much larger VLMs: it scores 74.25 vs 74.61 for Qwen2.5-VL-32B and 74.95 for InternVL3-38B, i.e. within 0.36 and 0.70 points respectively.
- Pairwise human/LLM-judge comparisons show Char-EBM-CLIP-Max beats Qwen2.5-VL-7B on VEG with 51.4% wins vs 26.8% losses (net +24.6%, decisive win rate 65.7%, p = 4.96 × 10^-10).
- Against Haruhi, Char-EBM-CLIP-Max wins VEG 65.0% vs 18.4% losses (net +46.6%, decisive win rate 77.9%, p = 1.42 × 10^-31), indicating a large margin over a strong text-only role-playing baseline.
- The CLIP-Max aggregation outperforms CLIP-SentTopK in Table 1: average 73.13 vs 72.37, suggesting sharp frame-level visual triggers matter more than diffuse sentence-frame averaging for dialogue scenes.
- The training recipe uses 2.3k high-quality CoT exemplars for a near-3-epoch SFT warm start, then one RL epoch on 8 NVIDIA H800 GPUs with Qwen2.5-VL-7B as the base model.
Threat model
The relevant adversary is a failure mode of the model itself: a role-playing agent that over-relies on static persona labels, ignores the current scene, or hallucinates visual context. The paper assumes the model can see the provided video clip and read the character profiles and dialogue history, but it should not access future frames or leaked subtitles from the target response window. In the open-ended expansion setting, the model may also need to handle off-screen but scene-present participants; however, it is not designed to defend against malicious users who intentionally prompt policy violations or adversarial multimedia perturbations.
Methodology — deep read
Threat model and task assumptions: the paper is not framed as a security problem, but it does define an implicit interaction setting. The adversary is not a malicious attacker so much as the failure mode of a role-playing agent that overfits persona tags and ignores the current scene. The authors assume access to a video clip V, a user profile Pu, an assistant/character profile Pa, and dialogue history H. They also assume the assistant role is physically present in the scene or, for the augmented data, follows an 'off-screen witness' assumption where the role can react to events it perceives but may not be visible on camera. The model is not supposed to hallucinate unseen scene details in <perception>, and the training pipeline explicitly aims to prevent leakage from subtitles or future frames.
Data provenance and labeling: the core dataset is built primarily from Harry Potter and Lord of the Rings film series. The script-grounded pipeline uses the open-source simple-subtitling toolkit to extract timestamps, speaker identities, and dialogue text from subtitles, followed by manual verification of raw utterances and line-level speaker labels. They build alternating dialogue sessions for 17 main characters and 111 minor characters, then apply a sliding-window procedure (citing MMRole) to turn sessions into turn-level training samples. Leakage prevention is handled carefully in two different ways: for canonical script samples, the input video is truncated so it only covers dialogue history duration and does not include frames overlapping the target utterance; for LLM-generated samples, they crop the subtitle region from videos. They further split train/test by session id so that multiple samples derived from the same clip do not appear across splits. The final dataset size is approximately 32k samples. The paper says character profiles come from public sources, but the exact profile schema is not fully enumerated in the main text.
A second data pipeline expands coverage using Gemini 3 Pro. For each clip, the authors feed a structured visual description, the canonical raw dialogue as topical reference, and character profiles to generate new interactions grounded in the same scene. They deliberately resample the user role, including a special 'fan' role, to increase diversity. The key conceptual addition is the 'Off-Screen Witness Assumption': participants are treated as present in the event even when not on camera, allowing cross-franchise role-play and more open-ended reactions than strict reenactment. This is intended to make the benchmark closer to VR/NPC interaction than to subtitle-conditioned dialogue reconstruction.
Architecture and algorithm: EBM-RL wraps a video-language policy model in a structured output format with three mandatory segments: <perception>, <think>, and <answer>. The perception stage must list observable facts only, organized around core event, key objects, and atmosphere/emotional pressure. The think stage must combine those visual observations with dialogue history and character profiles to infer the dialogue state and draft possible reply directions from the assistant character’s viewpoint. The answer stage then produces the final in-character utterance, constrained both by persona and by the scene’s emotional pressure. The base model is Qwen2.5-VL-7B. Before RL, they perform stage-1 SFT on 2.3k high-quality CoT exemplars generated with Gemini 3 Pro for nearly three epochs, apparently to reduce format collapse and teach the tagged output convention.
The reinforcement-learning core uses GRPO with a group of G sampled completions per input. Each completion is scored on four dimensions: semantic answer quality, format compliance, visual grounding, and perceptual-cognitive gain. The visual reward has two variants. CLIP-Max samples N representative frames, embeds them with CLIP, embeds the generated <perception> text, and uses the maximum cosine similarity over frames. CLIP-SentTopK instead splits the perception text into sentences, computes a frame-sentence similarity matrix, averages the top-K frame scores per sentence, and then averages across sentences. The PCG reward is more unusual: it measures whether the extracted perception+think text increases the frozen reference policy’s log-likelihood of the ground-truth answer, i.e. GT-LL(dgt | x ⊕ z(y)) − GT-LL(dgt | x), where z(y)=yv⊕yt. This is intended to reward intermediate reasoning that is causally useful for predicting the correct answer, not merely fluent or visually aligned. The final answer is scored by clipped BERTScore-F1 against the reference answer, and the format reward gives dense credit for correct tag existence, order, and boundaries. Raw reward dimensions are z-score normalized across the sampled group, then combined with weights [1.0, 1.0, 0.8, 0.8] for semantic, format, visual, and PCG rewards, respectively. The full GRPO objective includes a KL regularizer, but the appendix is needed for exact implementation details.
Evaluation protocol and one concrete example: evaluation is organized around three metrics. VEG (Visual Evidence Grounding) checks whether the model correctly perceives environment, atmosphere, and visible cues without hallucination. SPC (Situational Persona Compatibility) extends character fidelity by requiring persona-consistent but situation-appropriate behavior under environmental risk/stress. CN (Conversational Naturalism) measures whether the reply sounds human and colloquial rather than templated. GPT-5-mini is used as an automatic judge, and model identities are anonymized before scoring. Baselines include general VLMs (InternVL3-8B/14B/38B, Qwen2.5-VL-7B/32B), text-only RP baselines (RoleMRC-dpo, Crab, Haruhi), and a Qwen2.5-VL-7B-SFT model trained on the authors’ CoT data. A concrete end-to-end example described in the paper is the Harry Potter / giant spider scene: the perception stage should note the spider, dark tense atmosphere, and urgent danger; the think stage should infer that humor is inappropriate and that the character should shift toward bravery/responsiveness; the answer stage should become a short, urgent supportive line rather than a joke. This example is used to motivate why static persona consistency can be the wrong objective in high-stakes scenes.
Reproducibility: the paper says it releases the dataset construction scripts and the open-source dataset, and it provides Appendix details for dataset statistics, prompt templates, and reward specifics. It does not clearly state whether model checkpoints or frozen weights are released in the excerpt provided. Training was done on 8 NVIDIA H800 GPUs, but the main text excerpt does not give batch size, learning rate, number of GRPO groups G, KL coefficient, or random seed strategy, so those details remain unclear from the source shown.
Technical innovations
- EBM-RL decomposes multimodal role-play into explicit <perception>, <think>, and <answer> stages instead of letting a VLM produce a single undifferentiated response.
- The paper introduces a CLIP-based scene-text alignment reward for open-ended dialogue, with both frame-max and sentence-to-top-K aggregation variants.
- It proposes a Perceptual-Cognitive Gain reward that measures whether intermediate perception/thinking text increases the frozen reference policy's likelihood of the ground-truth answer.
- It frames role-play evaluation as situational consistency rather than static persona adherence, introducing VEG and SPC to separate visual grounding from persona appropriateness.
- It builds a video-grounded role-playing dataset from real movie subtitles plus an LLM-augmented expansion pipeline, rather than relying only on synthetic dialogue.
Datasets
- Video-grounded role-playing benchmark — approximately 32k samples — constructed from Harry Potter and Lord of the Rings movie clips; dataset construction scripts released
- CoT warm-start set — 2.3k samples — generated with Gemini 3 Pro
- Script-grounded dialogue sessions — 17 main characters and 111 minor characters — extracted from movie subtitles via simple-subtitling and manual verification
Baselines vs proposed
- Qwen2.5-VL-7B: Avg. = 69.17 vs proposed Char-EBM-CLIP-Max: Avg. = 73.13
- Qwen2.5-VL-7B: SPC = 65.05 vs proposed Char-EBM-CLIP-Max: SPC = 70.37
- Qwen2.5-VL-7B: VEG = 70.75 vs proposed Char-EBM-CLIP-Max: VEG = 74.25
- Qwen2.5-VL-32B: VEG = 74.61 vs proposed Char-EBM-CLIP-Max: VEG = 74.25
- InternVL3-38B: VEG = 74.95 vs proposed Char-EBM-CLIP-Max: VEG = 74.25
- Haruhi: VEG net win rate = -46.6% for baseline vs proposed (win/loss/tie 65.0/18.4/16.6)
- Qwen2.5-VL-7B: VEG win/loss/tie = 51.4/26.8/21.8 vs proposed, decisive win rate 65.7%, p = 4.96 × 10^-10
- Qwen2.5-VL-7B: SPC win/loss/tie = 51.6/27.4/21.0 vs proposed, decisive win rate 65.3%, p = 1.17 × 10^-9
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.04733.

Fig 1: From Static Persona to Situational Consis-

Fig 2: The Detailed Training Pipeline of the EBM-RL Framework with Stage-Specific GRPO Rewards. This

Fig 3 (page 2).
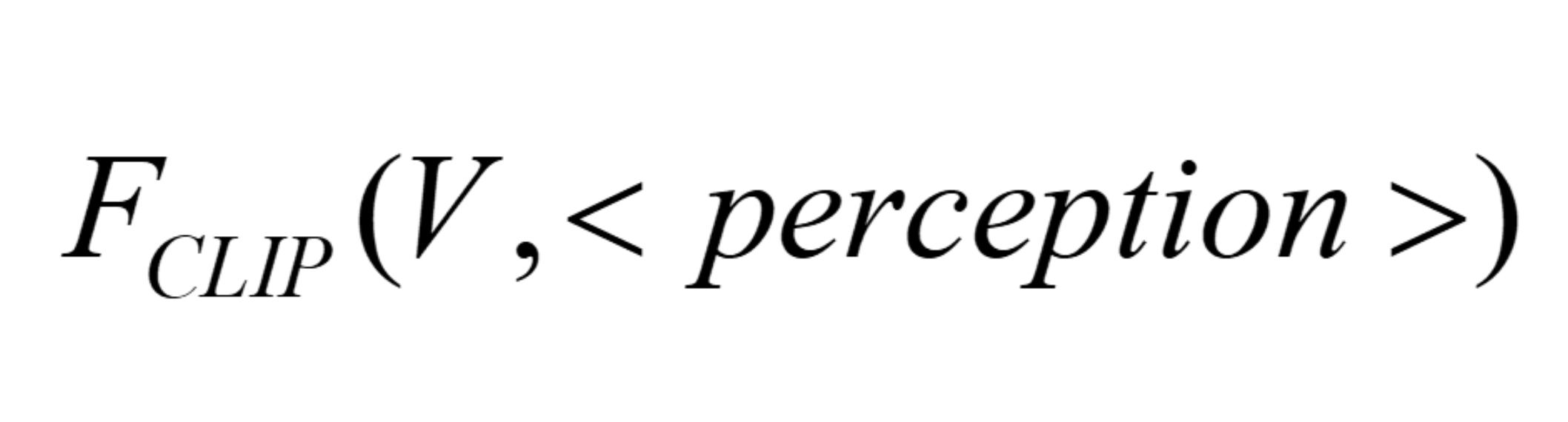
Fig 4 (page 4).
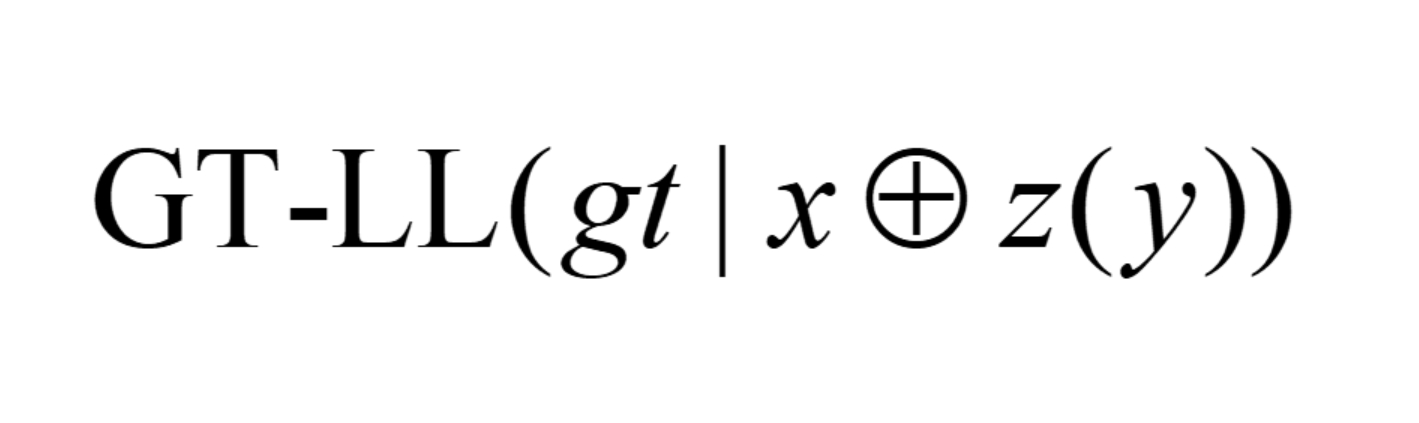
Fig 5 (page 4).
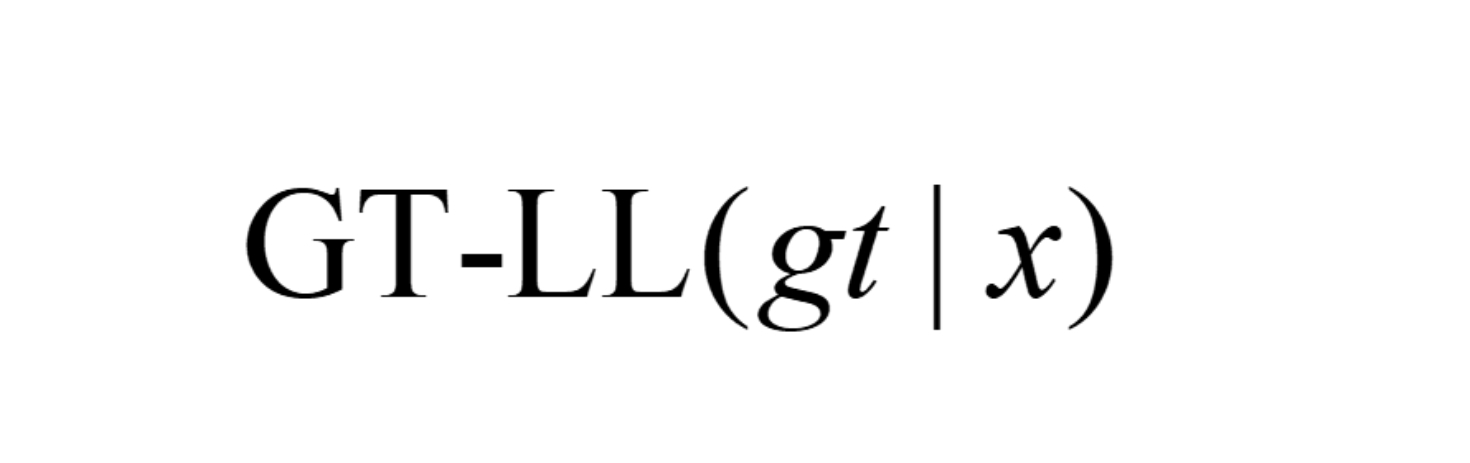
Fig 6 (page 4).
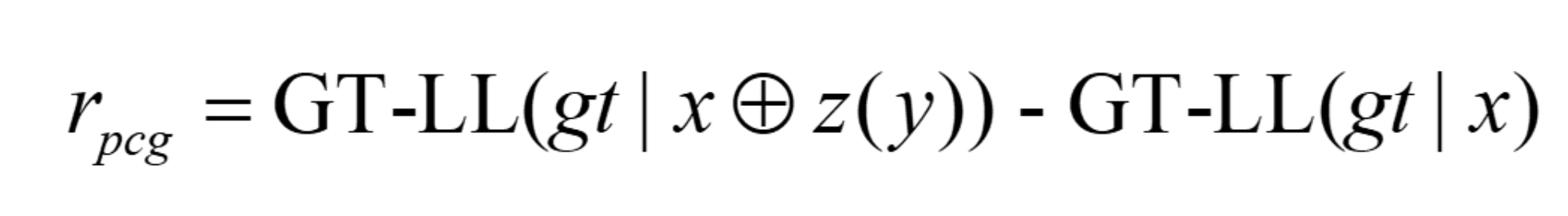
Fig 7 (page 4).
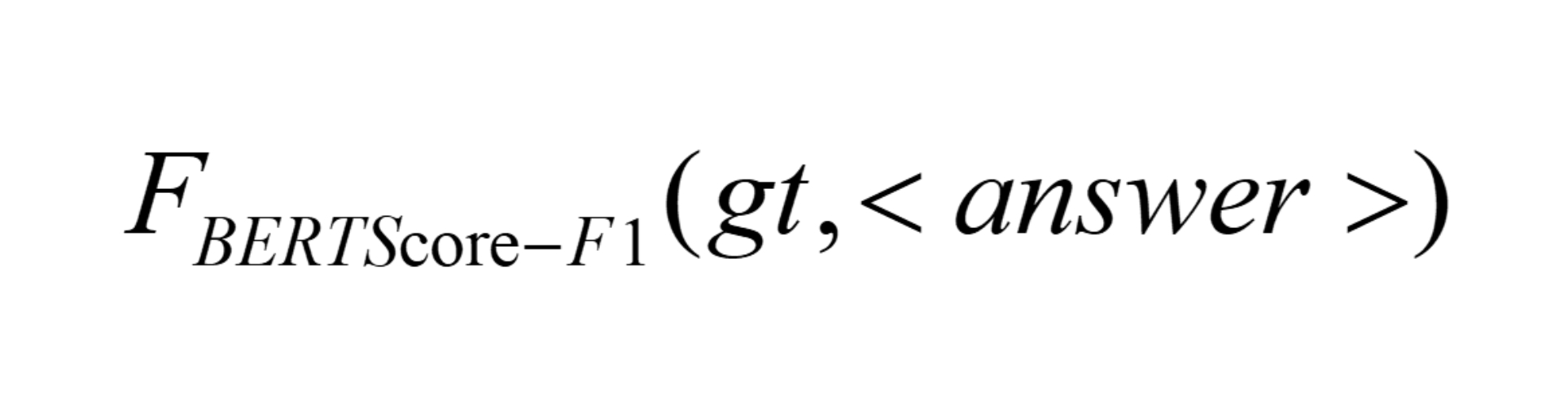
Fig 8 (page 4).
Limitations
- The main excerpt does not provide full implementation details such as batch size, learning rate, GRPO group size G, KL coefficient, or random seed strategy.
- Evaluation relies on GPT-5-mini as an automatic judge; even with anonymization, this can introduce judge bias and make the results sensitive to prompting.
- The benchmark is built mainly from two film franchises, so scene types, character relationships, and linguistic style may be narrower than claimed general immersion settings.
- The paper emphasizes in-domain and some zero-shot VideoQA transfer, but the excerpt does not show strong distribution-shift tests across unrelated real-world videos.
- The off-screen witness assumption is useful for open-ended RP, but it weakens strict grounding because the assistant may react to events not visually present to a conventional camera viewpoint.
- The excerpt does not report statistical variance across multiple runs for the main averaged metrics, so robustness to RL instability is unclear.
Open questions / follow-ons
- Would the reward decomposition still work if the scene generator were not a movie clip but a noisy real-world VR capture with camera motion, occlusion, and unconstrained audio?
- How sensitive are VEG and SPC to the choice of LLM judge, and would human ratings agree on cases where static persona and situational appropriateness conflict?
- Can the PCG reward be replaced with a cheaper proxy that does not require scoring ground-truth likelihood under a frozen reference policy?
- Does the structured <perception>/<think>/<answer> format improve interpretability enough to support debugging and selective intervention at test time?
Why it matters for bot defense
For bot-defense practitioners, the most relevant lesson is not the movie-domain content itself but the training/evaluation pattern: decompose a hard, open-ended behavior into subskills with different reward signals, then judge the system on multiple axes instead of a single aggregate score. The paper’s separation of perception, intermediate reasoning, and final action is analogous to building a bot detector that separately scores sensor plausibility, temporal consistency, and response fidelity rather than collapsing everything into one black-box classifier.
The dataset construction details are also practically useful. The authors are careful about leakage by session-level splitting and by removing subtitle regions or truncating input windows so the model cannot peek at the answer. That maps well to CAPTCHA and abuse-detection settings where label leakage, near-duplicate scenes, or prompt/template overlap can make an evaluation look much better than it really is. Finally, the CLIP-Max result is a reminder that in interactive systems, a sharp event trigger can matter more than dense averaging: if the wrong frame or the wrong moment is missed, downstream dialogue or policy can become tone-deaf even when the average visual understanding looks good.
Cite
@article{arxiv2605_04733,
title={ Reward-Decomposed Reinforcement Learning for Immersive Video Role-Playing },
author={ Miao Wang and Yuling Shi and Yijiang Li and Yeheng Chen and Xiaodong Gu and Bin Li and Bo Gao and Yaduan Ruan },
journal={arXiv preprint arXiv:2605.04733},
year={ 2026 },
url={https://arxiv.org/abs/2605.04733}
}