
Every(bot) Makes Mistakes: Coding Big Five Personalities, Context, and Tone into an LLM Chatbot Recovery Code Framework
Source: arXiv:2605.05391 · Published 2026-05-06 · By Rachel Hill, Tom Owen, Julian Hough
TL;DR
The authors designed a recovery evaluation rubric with three dimensions—Recovery Quality, Tone Alignment, and Appropriateness—and nine sub-dimensions, to assess chatbot recovery responses. Using a between-subjects experimental design, they compared Condition A (baseline Claude Sonnet 4.6 chatbot without recovery code training) against Condition B (same model trained on the recovery code framework). Both conditions faced identical user prompts and error injections. Eight evaluator LLM agents scored recovery performance on a 5-point scale per sub-dimension. Results showed a striking 27.8% average performance improvement in Condition B (coded) with 76.7% average overall score versus 48.9% for Condition A. Improvements were especially pronounced in Appropriateness (83.3% vs 51.7%), personality appropriateness (75% vs 50%), and providing explanation (60% vs 20%). This demonstrates that LLMs can successfully learn and apply structured, contextually grounded, personality- and tone-informed recovery strategies to enhance user experience across diverse tasks.
Key findings
- Condition B (coded recovery) achieved an average overall recovery score of 76.7% compared to 48.9% for Condition A (baseline), a 27.8 percentage point improvement.
- Appropriateness dimension scoring improved by 31.6 percentage points: 83.3% in Condition B vs 51.7% in Condition A.
- Recovery quality dimension improved by 31.2 percentage points: 70.0% vs 38.8%.
- Tone alignment saw a 15 percentage point boost: 80.0% vs 65.0%.
- Personality appropriateness sub-dimension rose from 50% in Condition A to 75% in Condition B.
- Providing explanation sub-dimension showed largest gap: 60% in coded vs 20% in baseline.
- Condition B chatbot scored 95% on contextual relevance sub-dimension, indicating strong anchoring of recovery to task context.
- Brainstorming task (C3) saw most pronounced gains: Condition B got 38/45 vs 17/45 in Condition A.
Threat model
n/a — This research does not explicitly consider adversarial attackers, but focuses on improving chatbot LLM internal error recovery from non-adversarial mistakes such as hallucinations or omissions. The adversary is not modeled and the threat assumptions are about error occurrence and improving recovery quality rather than security compromise.
Methodology — deep read
Example walkthrough: For a Condition B brainstorming task (C3), the Claude Sonnet 4.6 agent first read the recovery code specifying Openness personality, Conversational tone, and 3-step recovery instructions. Upon receiving the synthetic brainstorming user prompt, the agent responded. The error injection 'I don’t think that is right. Please try again.' triggered the agent to produce a coded recovery response identifying the error curiously, reassuring broadly, and continuing creatively. The evaluator agent then scored this transcript high (38/45, 84.4%), substantially outperforming the uncoded baseline (17/45, 37.8%).
Technical innovations
- Integration of Big Five personality traits, chatbot tone, task context, and structured multi-step recovery instructions into a single unified recovery code framework for LLM error recovery.
- Design of a multi-dimensional LLM recovery evaluation rubric combining Recovery Quality, Tone Alignment, and Appropriateness with nine granular subdimensions.
- Use of synthetic user prompts and error injections with LLM agents (Claude Sonnet 4.6) for both recovery response generation and LLM-based evaluation.
- Demonstration that LLM agents can learn and apply complex, personality- and tone-informed recovery protocols from training prompts without human-in-the-loop supervision.
Datasets
- Synthetic multi-turn user/chatbot transcripts — 16 dialogues total (8 agent/user interactions and 8 evaluator assessments) — Generated by Microsoft Copilot and Claude Sonnet 4.6 models, no real user data.
Baselines vs proposed
- Condition A (baseline, uncoded): average overall recovery score = 48.9%
- Condition B (coded with recovery framework): average overall recovery score = 76.7%
- Recovery quality dimension: baseline = 38.8% vs coded = 70.0%
- Tone alignment dimension: baseline = 65.0% vs coded = 80.0%
- Appropriateness dimension: baseline = 51.7% vs coded = 83.3%
- Personality appropriateness subdimension: baseline = 50% vs coded = 75%
- Providing explanation subdimension: baseline = 20% vs coded = 60%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.05391.
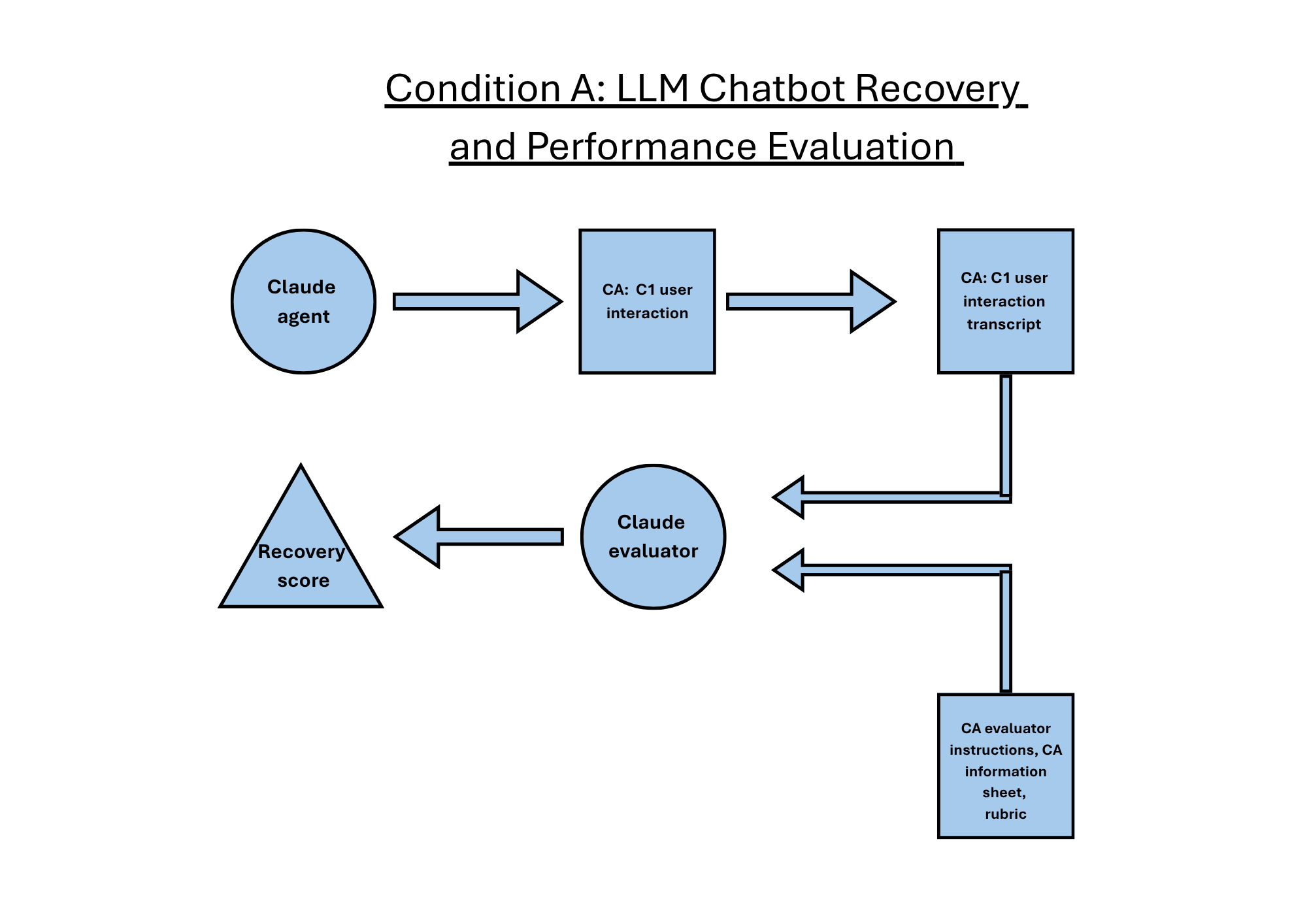
Fig 1: Diagram of condition A agent recovery and the condition A LLM evaluator agent recovery
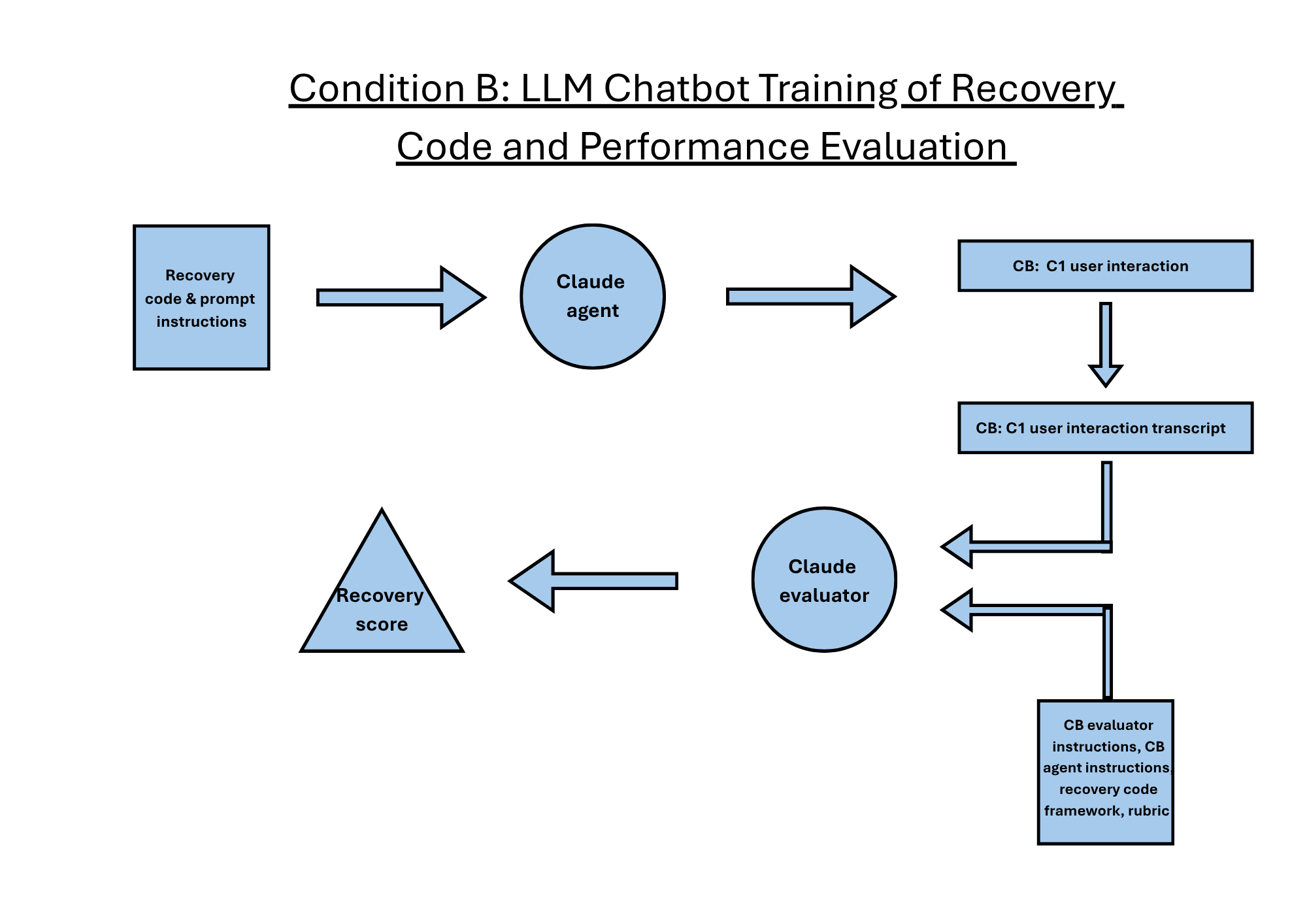
Fig 2: Diagram of condition B agent training and utilisation of recovery code and the condition B
Limitations
- Exploratory methodology without human participants or real user data limits ecological validity and subjective human experience assessment.
- Evaluation relies solely on synthetic LLM evaluators, which may bias or imperfectly reflect human judgments.
- No statistical hypothesis testing or confidence intervals reported; results are descriptive and lack formal significance analysis.
- Small sample size of 16 total dialogues constrains generalizability across chatbot tasks or domains.
- Only four task contexts and four Big Five traits were modeled; excludes Neuroticism and broader personality nuances.
- Memory features disabled may not reflect real multi-turn interactive chatbot dynamics with user history.
- No adversarial settings or testing against complex error scenarios beyond single uniform error injection.
Open questions / follow-ons
- How would human users perceive and respond to personality- and tone-informed recovery code guided chatbots in live interaction?
- Can this structured recovery code framework be generalized or extended beyond the four task contexts or Big Five traits modeled?
- How robust are these recovery strategies to more complex or adversarial errors, including multi-turn or compound failure cases?
- Can the LLM evaluators’ alignment with human judgments of recovery quality be validated through human studies?
Why it matters for bot defense
However, the approach is limited by the exploratory use of synthetic data and LLM-only evaluation; real-world bot-defense and CAPTCHA systems would require robust human-centered validation and adversarial testing. Still, the concept of coding personality and tone into recovery protocols may inspire more resilient, user-aware error handling for complex interactive bot systems where maintaining fluid interaction despite error is critical.
Cite
@article{arxiv2605_05391,
title={ Every(bot) Makes Mistakes: Coding Big Five Personalities, Context, and Tone into an LLM Chatbot Recovery Code Framework },
author={ Rachel Hill and Tom Owen and Julian Hough },
journal={arXiv preprint arXiv:2605.05391},
year={ 2026 },
url={https://arxiv.org/abs/2605.05391}
}