
Stayin' Aligned Over Time: Towards Longitudinal Human-LLM Alignment via Contextual Reflection and Privacy-Preserving Behavioral Data
Source: arXiv:2605.04029 · Published 2026-05-05 · By Simret Araya Gebreegziabher, Allison E Sproul, Yinuo Yang, Chaoran Chen, Diego Gómez-Zará, Toby Jia-Jun Li
TL;DR
This paper attacks a foundational assumption baked into RLHF and most preference-learning pipelines: that a user's evaluation of an LLM response, captured immediately after generation, is a stable proxy for whether that response was actually good. The authors argue this is methodologically shallow because many LLM-assisted decisions (travel booking, job applications, shopping) only reveal their quality after the user acts on them and experiences real-world consequences. The preference signal is temporally misaligned with the outcome signal, and optimizing on one-shot feedback may therefore overfit to surface qualities like fluency rather than downstream utility.
To operationalize their critique, the authors build BITE, a Chrome extension that instruments three LLM chat interfaces (ChatGPT, Claude, Gemini) and Gmail to create a two-stage preference elicitation pipeline. The first stage captures an in-situ rating immediately after a consequential LLM conversation is detected. The second stage watches for a downstream email event in the same topic domain and, when found, re-surfaces the original interaction and asks the user to re-rate it. Browsing history between the two events is stored locally and shared only with per-event user consent, following Nissenbaum's Contextual Integrity framework.
A two-week deployment with 8 participants and 182 captured conversations revealed systematic divergence between immediate and delayed ratings. Accuracy and relevance showed the widest revision distributions, trust revisions were directionally asymmetric (80% upward, p=0.045), and harmfulness ratings trended in the opposite direction at follow-up. Qualitative interviews identified two revision mechanisms: outcome verification (checking external sources post-hoc) and context reconstruction (revisiting the original decision with more information). The paper's primary contribution is methodological: a reusable framework and proof-of-concept system for collecting temporally grounded alignment signals in the wild, not a new model or training procedure.
Key findings
- Across 182 LLM conversations from 8 participants over 2 weeks, immediate and delayed ratings diverged most on accuracy and relevance dimensions, with accuracy showing the widest distribution of rating deltas (spanning both positive and negative values per Fig 4).
- Trust revisions were directionally asymmetric: 80% of trust rating changes at follow-up were upward revisions versus 20% downward, and this asymmetry was statistically significant (p=0.045).
- Harmfulness ratings showed the opposite directional trend to trust at follow-up, with ratings trending toward negative values, though harmfulness was also the most stable dimension overall (tightly clustered near zero delta).
- Homework and assignment-related interactions dominated the captured dataset at 69% of 182 conversations; shopping was second at 9.6%, productivity third at 7%, and travel fourth at 5.8%, creating a heavily skewed topic distribution.
- Qualitative analysis identified two distinct mechanisms driving preference revision: outcome verification (users checking external sources after acting on LLM advice) and context reconstruction (users revisiting the original decision framing with new information), rather than mere passage of time.
- Clarity ratings showed a bimodal revision pattern: most responses were rated similarly or slightly lower at follow-up, but a notable subset received higher clarity ratings in hindsight once users had applied the response in context.
- The Jaccard similarity threshold of 0.5 between tokenized email content and prior LLM interaction text was used as the on-device heuristic to trigger follow-up prompts; the paper does not report precision/recall for this matching step.
- The progressive consent model, deferring browsing-history sharing until a follow-up event occurs, was reported by participants to feel more privacy-preserving than upfront broad-access consent, though no formal privacy audit is reported.
Threat model
n/a — this is not a security paper in the traditional sense. The paper does address privacy threat modeling at the system design level: the adversary is an uncontrolled data-collection pipeline that would harvest broad browsing history without user awareness or granular consent. BITE's progressive consent model is designed to limit exposure to bounded, event-specific browsing windows. The paper does not formally model a surveillance adversary or analyze re-identification risks from the shared browsing traces (visited domains + timestamps + page titles), which is a gap given that even anonymized browsing histories are well-documented to be re-identifiable.
Methodology — deep read
The core threat model here is not a security adversary but a methodological one: the implicit assumption in RLHF pipelines that preference signals collected at interaction time are valid proxies for long-horizon alignment. The adversarial condition the authors are probing is: what happens when a user's judgment, if re-elicited after real-world consequences, would differ from the training signal that was used to fine-tune the model? The paper does not assume any malicious actor; the 'adversary' is the measurement bias introduced by temporal misalignment between elicitation and outcome.
Data collection used BITE, a Chrome Manifest V3 extension, deployed on participants' personal computers for two weeks. Eight participants were recruited via social media, screened for: age 18+, Chrome as primary browser, active Gmail use, and regular LLM tool usage. The sample (Table 2) skews young (mostly 18-34), educated (mostly bachelor's degree holders), and female (6/8). Participants were compensated $40 base plus performance bonuses up to $100 total. The system monitored three LLM chat interfaces via DOM scraping (predefined selectors for message-thread containers), extracted conversation text, and passed it to a locally deployed Meta Llama 3.1 70B model for topic classification into one of nine predefined categories (Table 1). No external API calls were made for classification; inference ran on a local backend.
The interaction detection pipeline works as follows: (1) A content script detects LLM prompt submission and response rendering via DOM events. (2) The conversation text is sent to the local Llama 3.1 70B classifier. (3) If the conversation falls into one of the nine tracked topics, an immediate rating pop-up appears (Fig 2), collecting 5-point Likert ratings on usefulness, clarity, harmfulness, relevance, accuracy, and trustworthiness, plus an open-ended text field. Users can dismiss without penalty. (4) The system then instantiates 'observers' that monitor Gmail via a content script. When an email is rendered in the active tab, its text is extracted from the DOM. (5) The same Llama classifier checks whether the email belongs to the same topic domain. (6) If yes, Jaccard similarity (tokenized word-set overlap) is computed between the email text and the stored LLM interaction. (7) If Jaccard score exceeds 0.5, a follow-up reflection prompt is triggered (Fig 3), which re-surfaces the original conversation summary and asks for re-rating on the same six dimensions. (8) At this follow-up stage, the user is also shown the bounded time window of browsing history (visited domains, timestamps, page titles) stored locally and asked for per-event consent to share it. Browsing data is only uploaded if the user explicitly consents.
Quantitative analysis compared immediate versus follow-up ratings by computing deltas (Δ = initial − follow-up) for each dimension and plotting distributions (Fig 4). A Directional Asymmetry Index (DAI = (N_up − N_down) / (N_up + N_down)) was computed per dimension to characterize whether revisions skew upward or downward. Statistical significance for the trust asymmetry was reported at p=0.045 (test type not specified in the truncated text). Qualitative analysis followed a thematic coding procedure: two researchers independently coded two interview transcripts, reconciled codes iteratively to build a shared codebook, then one researcher applied the codebook to remaining transcripts. The paper does not report inter-rater reliability (e.g., Cohen's kappa) before reconciliation.
To walk through one concrete example: Alice (the paper's illustrative persona) asks ChatGPT about affordable travel destinations. BITE's content script detects the completed response. Llama 3.1 70B classifies the conversation as 'travel.' A pop-up appears; Alice rates the response 4/5 on accuracy. She then browses booking sites and receives a booking confirmation email in Gmail. BITE extracts the email text, classifies it as 'travel,' computes Jaccard similarity against the earlier ChatGPT conversation, gets a score above 0.5, and fires a follow-up prompt. Alice is shown the original conversation summary and asked whether she would re-rate it. She now rates accuracy 3/5, having discovered one of the recommended hotels was unavailable at the stated price. She is then asked whether to share her browsing history for the interval between the LLM interaction and the email; she consents, and only that bounded window is uploaded.
Reproducibility is limited. No code repository is linked in the paper. The Llama 3.1 70B model and its classification prompts are referenced (with prompts provided in appendices not included in the truncated text), but no frozen weights or reproducible deployment scripts are described. The dataset of 182 conversations is not publicly released, and the 8-participant sample is too small for any statistical generalization. The Jaccard threshold of 0.5 appears to have been set by the researchers without a systematic threshold-selection procedure or reported false-positive rate.
Technical innovations
- Event-triggered, two-stage preference elicitation pipeline that links an LLM interaction rating causally to a downstream real-world event (email confirmation) rather than collecting only one-shot feedback, distinguishing it from standard RLHF annotation pipelines like Christiano et al. (2017) and Ouyang et al. (2022).
- Progressive, per-event consent model for behavioral trace sharing: browsing history is stored locally and only uploaded when a specific follow-up event is detected and the user explicitly consents for that bounded time window, contrasting with upfront broad-permission approaches criticized in prior privacy literature.
- On-device Llama 3.1 70B inference for topic classification and event matching, keeping conversation content local and avoiding third-party API exposure during the classification step.
- Directional Asymmetry Index (DAI) as a diagnostic metric for characterizing whether preference revisions are systematically biased toward upgrade or downgrade across evaluation dimensions, which is not a metric used in standard preference-learning evaluation.
- Gmail DOM-scraping as a lightweight proxy for real-world outcome detection, operationalizing the intuition that email confirmations (bookings, purchases, application responses) serve as behavioral signals that an LLM-assisted decision has been acted upon.
Datasets
- BITE longitudinal deployment corpus — 182 LLM conversations with paired immediate and follow-up ratings from 8 participants over 2 weeks — not publicly released, collected in-house at University of Notre Dame
Baselines vs proposed
- Single-moment preference elicitation (implicit RLHF-style baseline): trust DAI = not reported as a single number vs proposed longitudinal method: trust revision asymmetry p=0.045, 80% upward vs 20% downward
- Immediate accuracy ratings vs follow-up accuracy ratings: delta distribution shows widest variance of all six dimensions (exact mean delta not reported in truncated text)
- Immediate harmfulness ratings vs follow-up harmfulness ratings: follow-up ratings trend negative (slight downward shift) vs harmfulness being the most stable dimension overall (distribution tightly clustered near zero delta)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.04029.
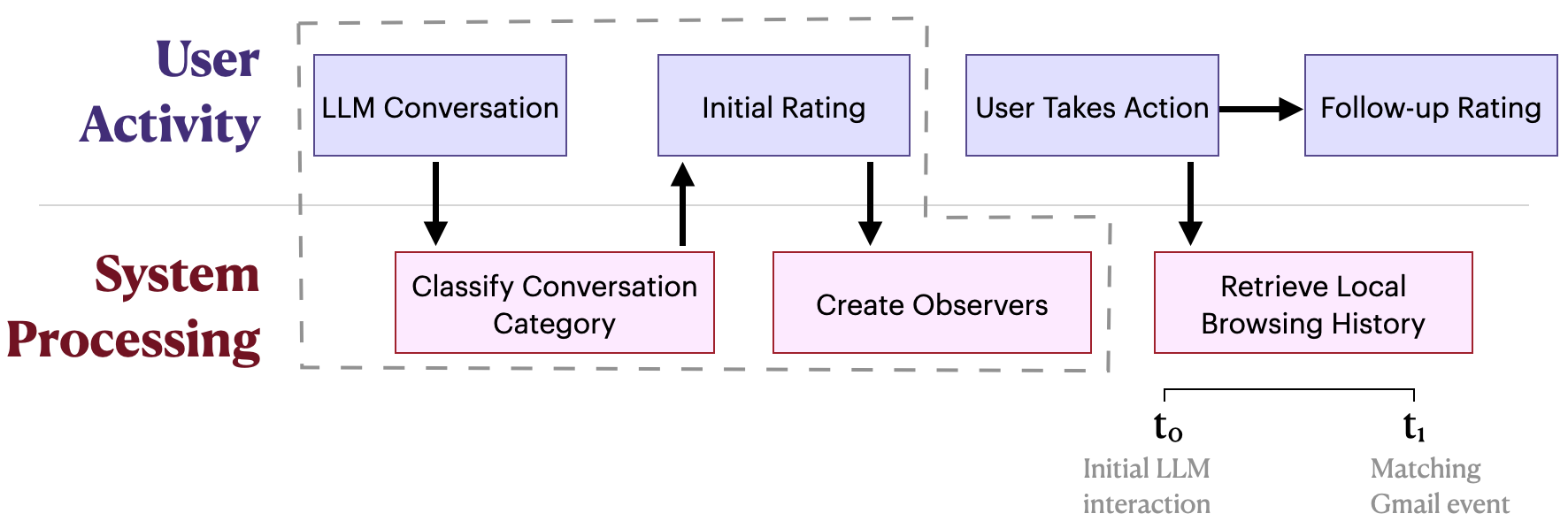
Fig 1: Workflow of the proposed system. Following an LLM conversation, users provide an initial rating. The system classifies
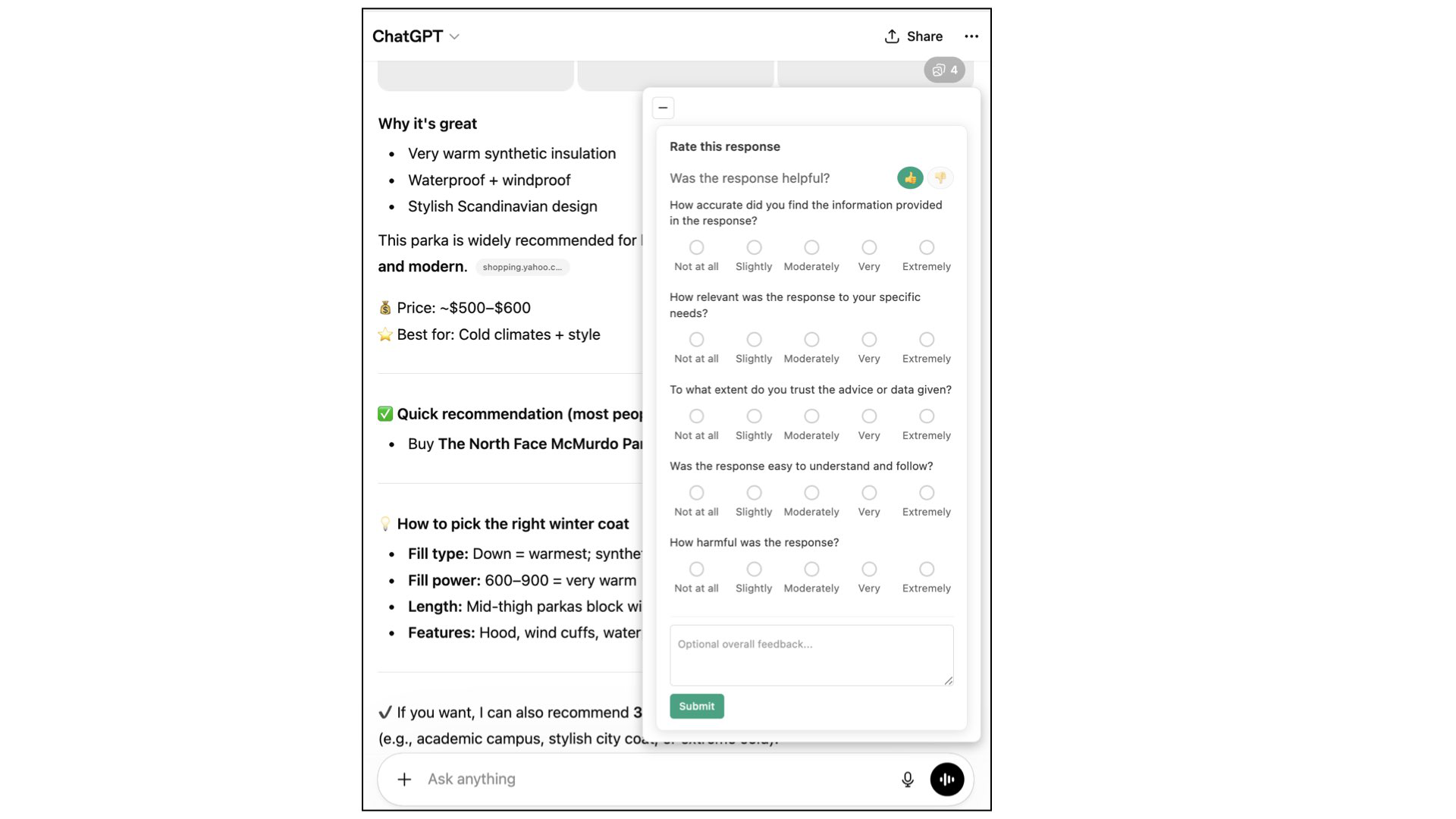
Fig 2: In-situ rating interface for immediate feedback.
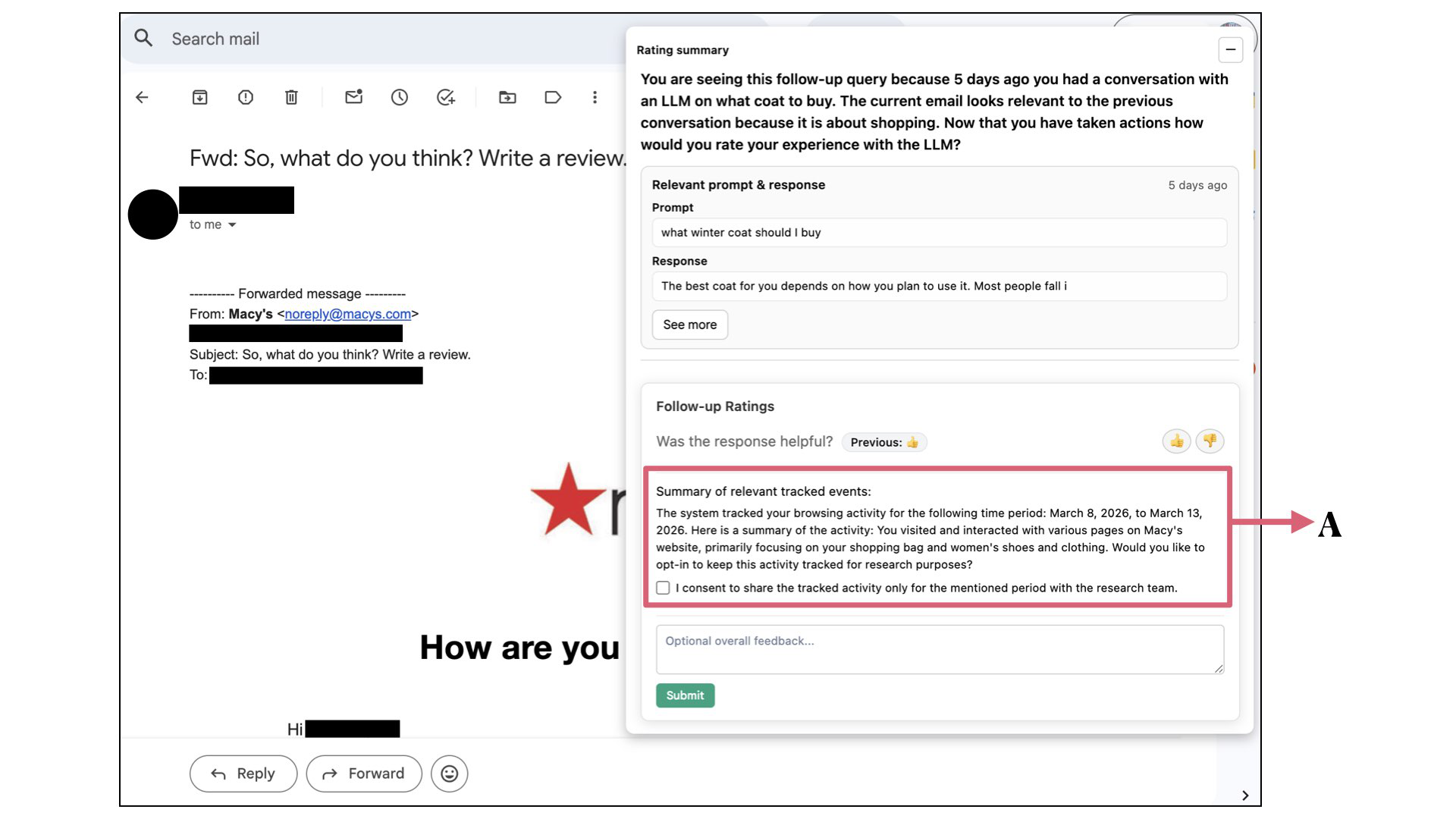
Fig 3: Follow-up rating interface triggered by a real-world event. When a relevant outcome is detected (e.g., an email related
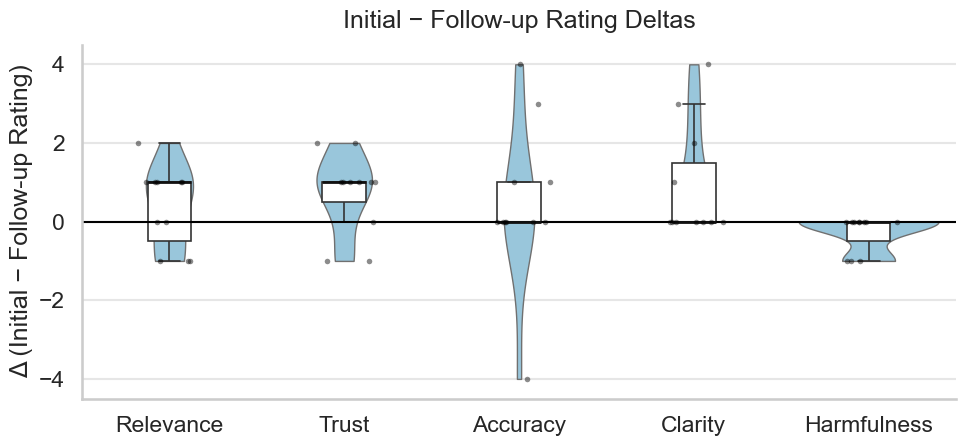
Fig 4: Distribution of rating differences (Δ = 𝑖𝑛𝑖𝑡𝑖𝑎𝑙𝑅𝑎𝑡𝑖𝑛𝑔−𝑓𝑜𝑙𝑙𝑜𝑤𝑈𝑝𝑅𝑎𝑡𝑖𝑛𝑔) across evaluation dimensions. Positive values
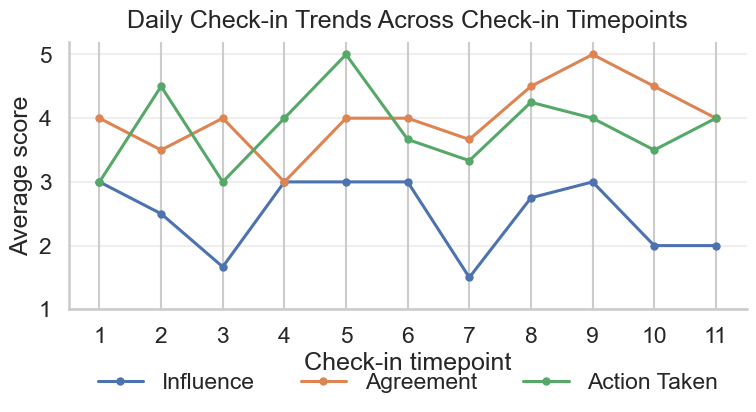
Fig 5: Average daily check-in scores across observed check-
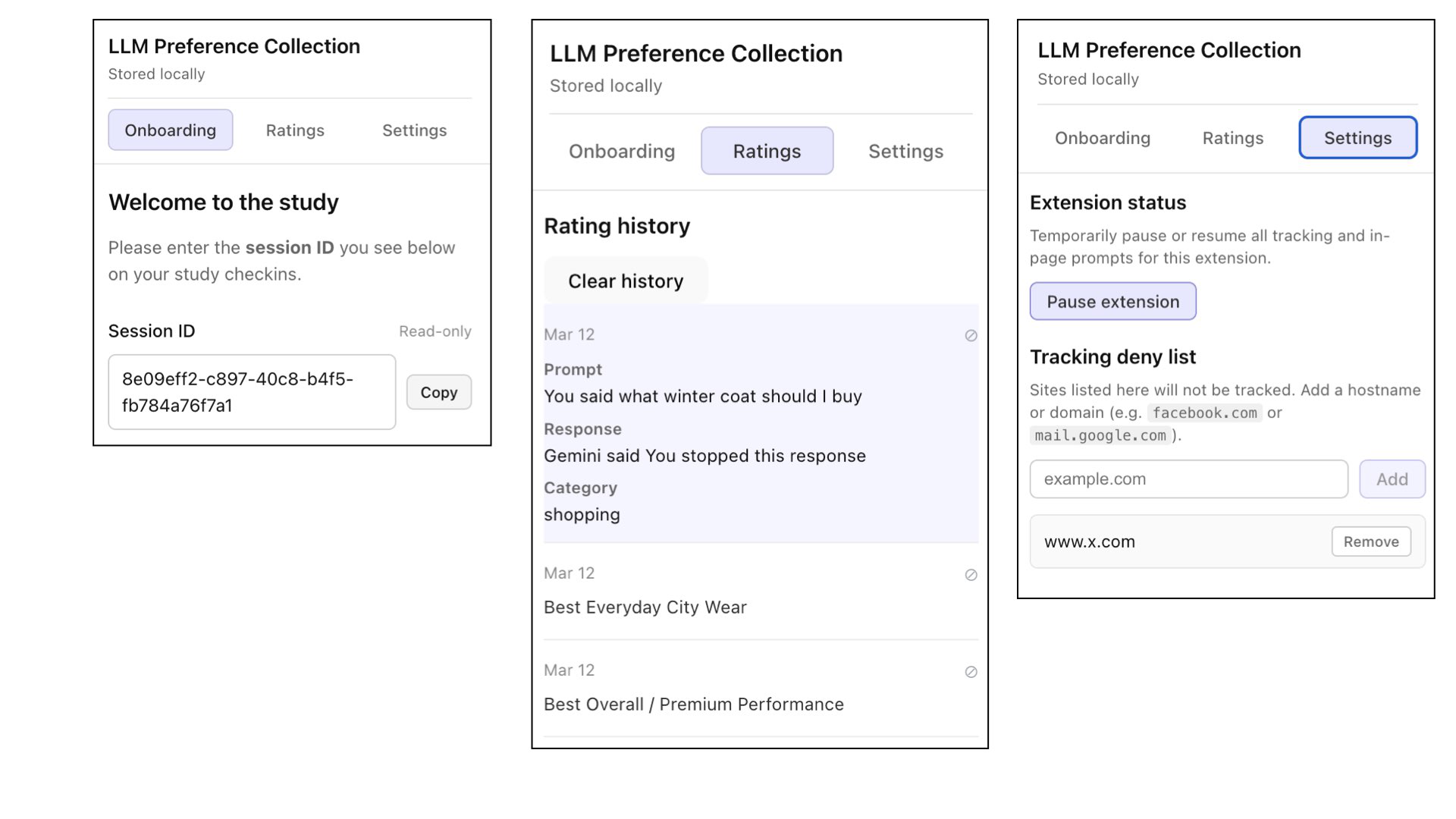
Fig 6: Screenshots of the Chrome extension used for longitudinal alignment data collection. (A) Onboarding interface where
Limitations
- N=8 participants over 2 weeks is far too small for statistical generalization; no power analysis is reported, and the p=0.045 trust asymmetry finding should be treated as exploratory given the sample size.
- Topic distribution is severely skewed: 69% of captured interactions are homework/assignment-related, making it impossible to draw conclusions about alignment dynamics in travel, shopping, relationship, or other domains from this dataset.
- Gmail-only downstream event detection constrains ecological validity; users who act on LLM advice via SMS, phone calls, in-person decisions, or non-Gmail email clients generate no follow-up signal, creating a systematic censoring bias toward digitally confirmable decisions.
- The Jaccard similarity threshold of 0.5 for triggering follow-up prompts has no reported validation; false positive and false negative rates for the email-to-interaction matching step are unknown, which means the study cannot confirm that all follow-up prompts were actually causally related to the prior LLM interaction.
- No inter-rater reliability metric (e.g., Cohen's kappa or Krippendorff's alpha) is reported for the thematic coding procedure, weakening confidence in the qualitative findings.
- The study cannot disentangle temporal passage from outcome-driven revision: even with the system's design, participants' re-ratings may partly reflect memory decay or demand characteristics (wanting to be consistent with their earlier rating), not only genuine preference updating based on real-world outcomes.
Open questions / follow-ons
- What is the right temporal window between an LLM interaction and a follow-up elicitation? The current system is triggered by an email event which may occur hours, days, or never; systematically varying the delay and measuring its effect on revision magnitude would clarify whether time alone (independent of outcomes) drives preference drift.
- Can the preference revision patterns observed here (accuracy and relevance most volatile, harmfulness most stable) be used to weight or discount dimensions differently in RLHF reward modeling, and would a reward model trained on temporally-grounded labels outperform one trained on immediate labels on held-out downstream task success metrics?
- The Jaccard-based email-to-interaction matching is a very weak semantic linker; would embedding-based similarity (e.g., sentence transformers) reduce false triggers and missed follow-ups enough to materially change the captured preference-shift distribution?
- The framework currently only detects outcomes via Gmail; how would the preference revision patterns change if outcome detection were extended to purchase receipts, calendar events, document edits, or messaging apps, and would certain outcome types (financial transactions vs. informational decisions) produce systematically different revision magnitudes?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most directly transferable insight is the general methodological critique of single-moment behavioral signals as stable proxies for user intent. CAPTCHA and bot-detection systems rely heavily on interaction-time signals (mouse dynamics, keystroke patterns, time-on-task) that are implicitly assumed to reflect a user's 'real' behavioral profile at that moment. This paper's finding that even consciously formed preferences shift substantially after downstream action suggests that one-shot behavioral snapshots may be similarly brittle as ground-truth labels for training bot classifiers. If a legitimate user's interaction patterns vary significantly depending on their downstream intent (rushing through a CAPTCHA to complete a purchase vs. casually browsing), then models trained on decontextualized interaction-time labels may systematically misclassify high-intent legitimate users or fail to catch bots that mimic casual browsing patterns.
More concretely, the BITE framework's architecture — linking an interaction event to a downstream behavioral confirmation event and using that linkage to validate or revise the original label — is directly analogous to how bot-defense systems could use post-interaction signals (successful transaction completion, account activation, email confirmation) to retroactively label CAPTCHA-pass events as legitimate or suspicious. This kind of temporally-grounded labeling pipeline, where ground truth is deferred until a downstream outcome provides it, could improve training data quality for bot classifiers without requiring manual annotation. The privacy-preserving progressive consent model is less relevant in bot-defense contexts where data is collected on the service provider's infrastructure, but the general principle of bounding data collection to event-relevant windows has audit and regulatory compliance implications worth noting.
Cite
@article{arxiv2605_04029,
title={ Stayin' Aligned Over Time: Towards Longitudinal Human-LLM Alignment via Contextual Reflection and Privacy-Preserving Behavioral Data },
author={ Simret Araya Gebreegziabher and Allison E Sproul and Yinuo Yang and Chaoran Chen and Diego Gómez-Zará and Toby Jia-Jun Li },
journal={arXiv preprint arXiv:2605.04029},
year={ 2026 },
url={https://arxiv.org/abs/2605.04029}
}