
PHALAR: Phasors for Learned Musical Audio Representations
Source: arXiv:2605.03929 · Published 2026-05-05 · By Davide Marincione, Michele Mancusi, Giorgio Strano, Luca Cerovaz, Donato Crisostomi, Roberto Ribuoli et al.
TL;DR
This paper addresses the problem of stem retrieval in musical audio, where given a partial mix, the goal is to identify the missing complementary stems that coherently fit it both harmonically and temporally. Traditional audio representation learning approaches rely on aggregation techniques like global average pooling that enforce translation invariance, discarding crucial temporal and phase alignment information necessary for such tasks. The authors propose PHALAR, a contrastive learning framework that explicitly models temporal alignment by leveraging complex-valued phasor embeddings derived from a Learned Spectral Pooling layer and processed by a phase-equivariant complex-valued neural network (CVNN) head. This contrasts with prior magnitude-based or semantic embedding approaches and enforces pitch-equivariant and phase-equivariant inductive biases.
PHALAR achieves up to a 70% relative accuracy improvement over the prior state-of-the-art stem retrieval model (COCOLA) on several benchmarks (MoisesDB, Slakh, ChocoChorales) while using less than half the parameters and providing a 7× speedup in training time. It also correlates significantly better with human judgments of musical coherence than semantic or perceptual similarity baselines. Interestingly, beyond retrieval, PHALAR supports zero-shot beat tracking and linear chord probing, indicating it captures robust rhythmic and harmonic musical structures without explicit supervision. Ablation studies confirm the critical importance of phase equivariance and pitch-equivariance for performance gains.
Key findings
- PHALAR achieves up to 70.87% top-1 retrieval accuracy on MoisesDB K=64, a +69% relative improvement over COCOLA's 41.84%.
- PHALAR uses 2.3M parameters, less than half COCOLA's 5.2M, and trains 7× faster (50 GPU-hours vs 340 GPU-hours).
- Semantic similarity foundation models like CLAP and CDPAM perform near random chance (≈1.2% at K=64) on stem retrieval, highlighting dissociation between semantic similarity and structural coherence.
- Human listening test of 22 participants over 880 ratings shows PHALAR embeddings have highest correlation with perceived coherence (Pearson ρ=0.387, Spearman rs=0.414), significantly outperforming COCOLA and others (p < 0.05).
- Replacing spectral pooling with global average pooling drops accuracy by ~19%; removing phase equivariance causes a 10.3% drop, demonstrating importance of phase information.
- Replacing CQT inputs with Mel-spectrogram reduces accuracy by 1.66%, underscoring benefits of pitch-equivariant input representations.
- Zero-shot beat tracking yields F1=0.627 on GTZAN dataset without rhythm supervision, confirming implicit rhythmic structure capture.
- The learned complex similarity metric (parametrized Hermitian form) that encodes phase alignment outperforms magnitude-only or complex cosine similarity metrics by 9-10% accuracy on retrieval.
Threat model
The adversary is an entity attempting to identify musically coherent stem combinations from partial mixes, where naive matching could rely on trivial timbral or semantic cues. The model aims to prevent errors arising from ignoring temporal misalignments (e.g., out-of-phase stems). The adversary cannot observe internal model weights but may attempt general retrieval based on audio similarity. The threat does not involve active adversarial manipulation or fooling attacks.
Methodology — deep read
The core methodology revolves around representing musical audio in a way that preserves harmonic content and, crucially, temporal alignment (phase) information necessary for coherence-based tasks.
Threat Model & Assumptions: The adversary here is modeled as the challenge of identifying if the missing stems to a partial mix are temporally and harmonically coherent. The model assumes access to multi-track dataset samples, with ground-truth stems and submixes. The adversary cannot rely on trivial timbral identity mappings due to mutually exclusive instrument sets during training pairs.
Data: The authors construct a composite dataset combining MoisesDB, Slakh2100, and ChocoChorales. Training/validation/test splits are random at the track level (80/10/10%). Training inputs consist of dynamic paired submixes per track, generated to be temporally aligned and mutually disjoint in instrument composition (e.g., vocals vs. drums + bass). This prevents shortcuts based on timbre. Inputs are 2-10s audio clips processed into Constant-Q Transform (CQT) spectrograms.
Architecture/Algorithm:
- Harmonic Backbone: A lightweight 10-layer axial CNN processes input CQT spectrograms with spectro-temporal separable convolutions (3×1 freq-wise, 1×3 time-wise, 1×1 pointwise), applying strided convolutions to reduce temporal resolution by 32×.
- Learned Spectral Pooling: Instead of standard global average pooling, a learned projection matrix projects flattened backbone features along frequency channels to a D=80 dimensional space followed by an RFFT along the temporally-compressed axis (length T'/32), truncating to C=8 frequency bins. This transforms temporal sequences into spectral phasors (complex embeddings), where magnitude encodes harmonic strength and phase encodes temporal shifts.
- Complex-Valued Head: A phase-equivariant CVNN head (two complex linear layers with Complex RMSNorm and modReLU) projects the 640-dimensional complex embeddings to 512 complex outputs, preserving phase structure.
- Similarity Metric: A learnable Hermitian inner product with a complex weight matrix W evaluates similarity as the real part of z_x^H W z_y, capturing relative phase shifts between embeddings. For retrieval symmetry, the score is averaged with its transpose.
Training Regime: The model trains with a contrastive InfoNCE objective, using batches of 64 on two NVIDIA A100 GPUs for 80k steps (~50 GPU-hours). Label smoothing (positive target probability = 0.9) is used to reduce gradient noise from potential semantically similar but distinct negatives. Data augmentations include identical random crops (2-10s) for pairs, gain variation ±6dB, and noise injections.
Evaluation Protocol: Models are compared on K-way stem retrieval accuracy (K=8,16,64) across MoisesDB, Slakh2100, and ChocoChorales. Baselines include COCOLA (state-of-the-art real-valued CNN with GAP), large foundation models (MERT, CLAP), and perceptual metrics (CDPAM, ViSQOL). Human coherence judgments are collected via a blind listening study with 22 participants rating stem coherence on a Likert scale, to compute correlation metrics (Pearson, Spearman) with model scores. Ablation studies test removal of spectral pooling, phase equivariance, and input representation changes.
Reproducibility: Code, checkpoints, and human evaluation data are publicly released at github.com/gladia-research-group/phalar. The composite dataset uses public or commonly used datasets (MoisesDB, Slakh2100, ChocoChorales).
Example end-to-end: For a MoisesDB track, two disjoint, temporally aligned submixes are sampled, converted to CQT, fed to the harmonic backbone CNN to extract features. These are projected via a learned basis and RFFT to complex spectral embeddings encoding timing via phase. The CVNN head refines these phase-equivariant embeddings. The similarity between a query’s embedding and candidate embeddings is computed with the Hermitian inner product score. The candidate with highest symmetric score is retrieved. Training enforces contrastive loss to push coherent pairs closer and incoherent pairs apart in this complex latent space.
Technical innovations
- Introduction of a Learned Spectral Pooling layer that projects learned harmonic features into the complex frequency domain, transforming temporal sequences into phase-encoded spectral embeddings.
- Use of a phase-equivariant complex-valued neural network projection head that preserves phase information, enabling temporal alignment sensitivity.
- Parametrization of similarity as a learnable Hermitian inner product in the complex domain, incorporating phase rotations to model micro-timing deviations.
- Explicit enforcement of pitch-equivariant inductive bias via CQT input and axial CNN structure, allowing the model to decouple harmonic intervals from absolute pitch and improving generalization.
Datasets
- MoisesDB — size not explicitly stated — public dataset
- Slakh2100 — 2100 tracks — publicly available synthetic multi-track dataset
- ChocoChorales — several hundred tracks — public dataset
Baselines vs proposed
- COCOLA: MoisesDB K=64 accuracy = 41.84% vs PHALAR 70.87%
- MERT† (phase-aware spectral pooled): MoisesDB K=64 accuracy = 45.85% vs PHALAR 70.87%
- CLAP: MoisesDB K=64 accuracy = 1.24% vs PHALAR 70.87%
- CDPAM: MoisesDB K=64 accuracy = 1.15% vs PHALAR 70.87%
- PHALAR human rating correlation (Pearson ρ) = 0.387 vs COCOLA 0.181
- PHALAR training GPU hours = 50 hrs vs COCOLA 340 hrs
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.03929.
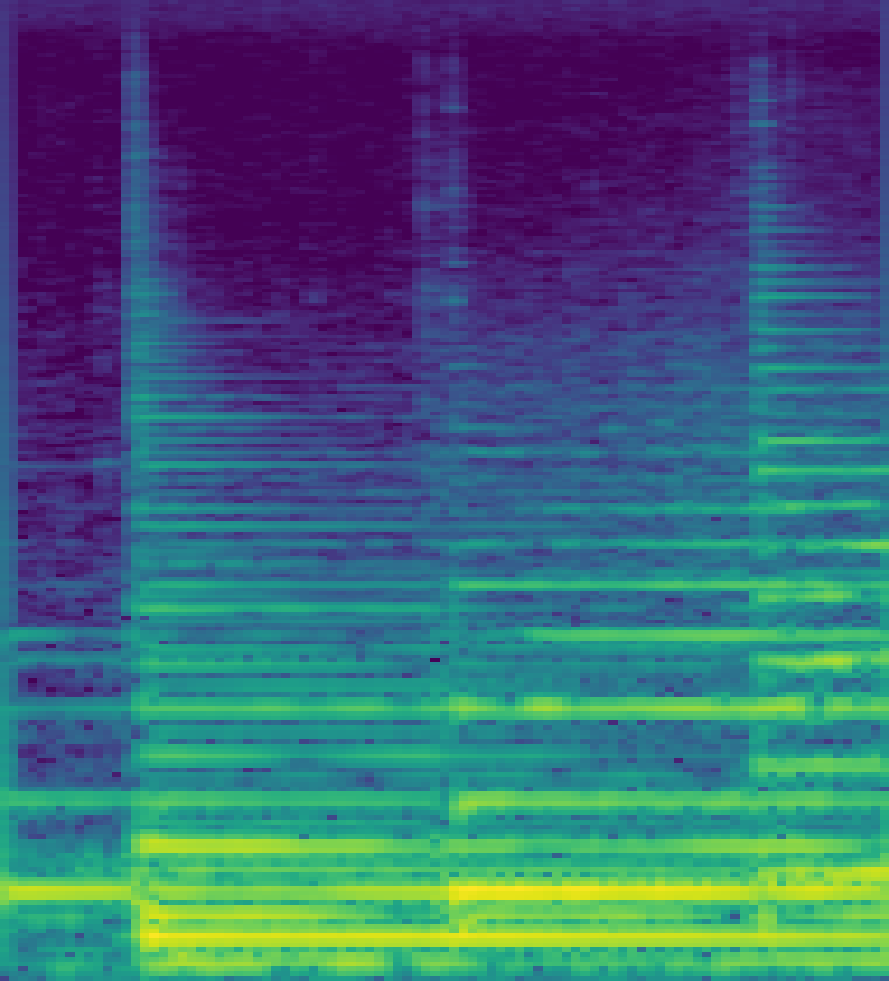
Fig 1: Emergent Phase-Equivariance. Our model’s Learned
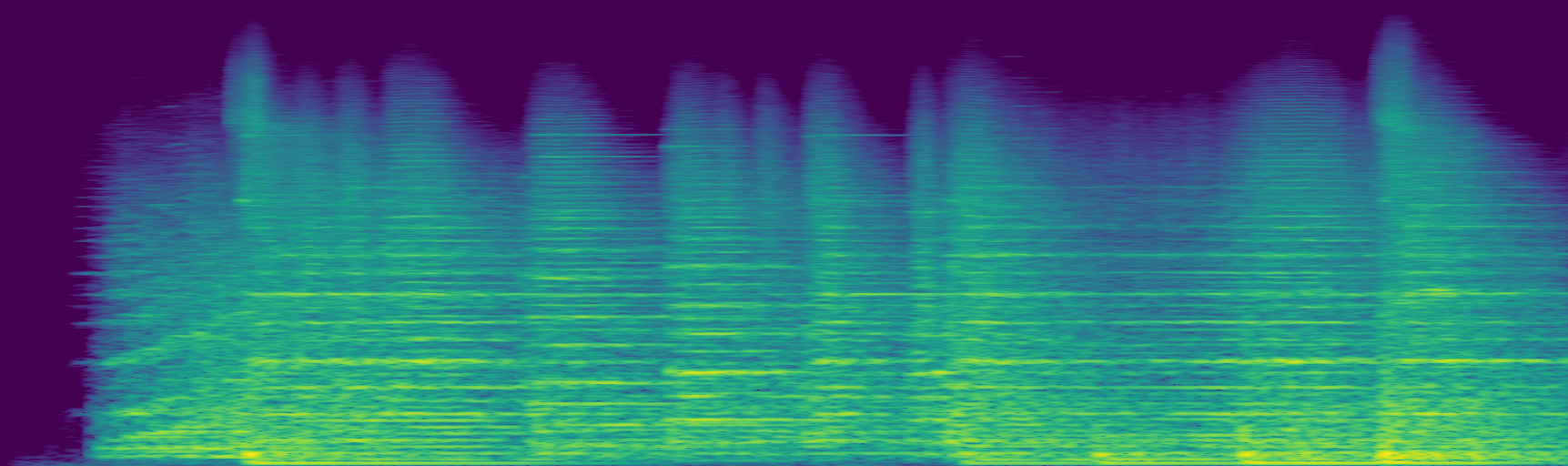
Fig 2: Depiction of PHALAR’s architecture: a spectrogram is fed to the CNN, the resulting feature map is projected onto a learned

Fig 4: Time-expanded polar plots reveal how the model par-

Fig 6: ∆t v. ∠z over the top-5 dimensions by |ρ|
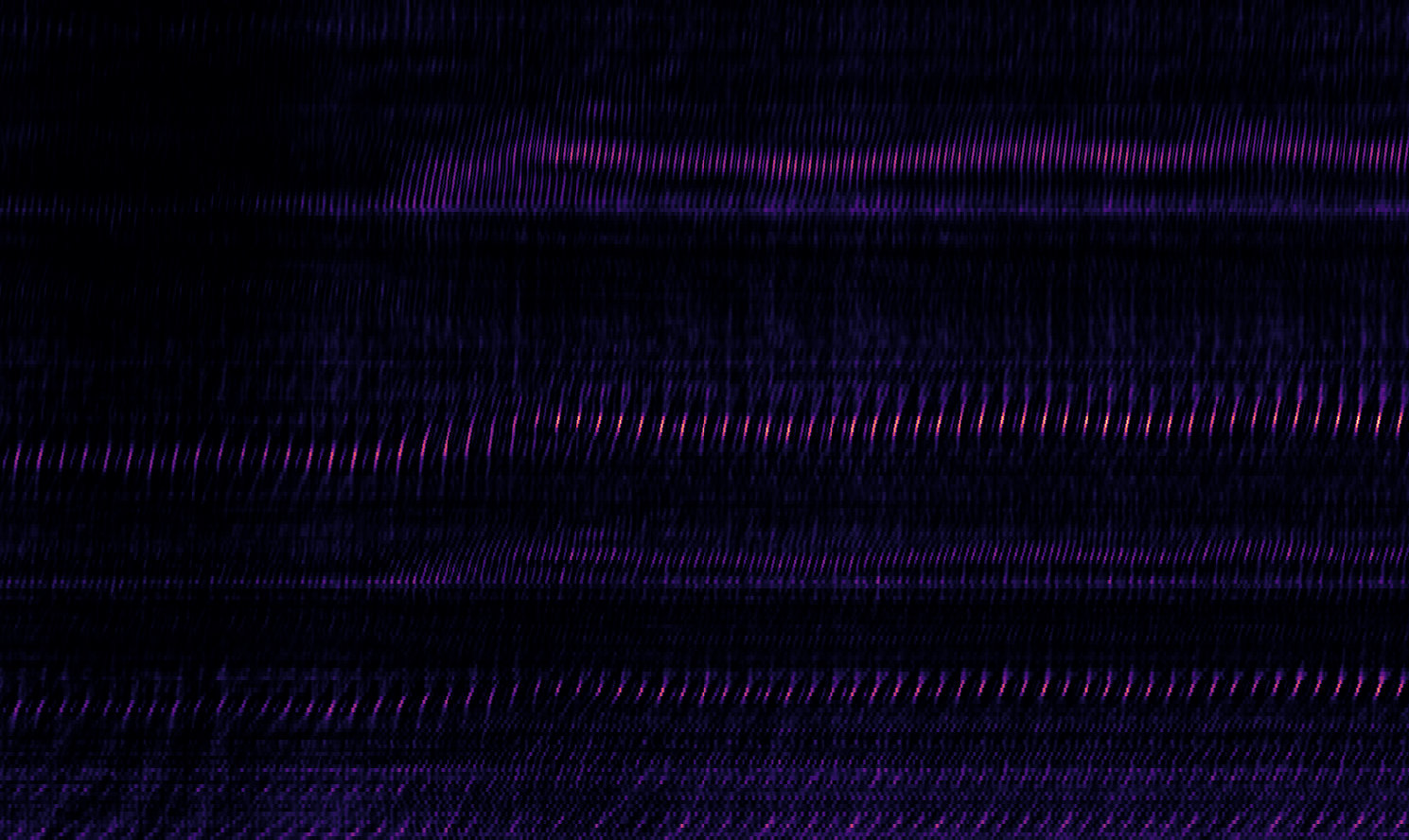
Fig 7: BPM of “Money” (Waters, 1973)
Limitations
- Evaluation focuses primarily on stem retrieval; robustness to real-world noisy or out-of-distribution recordings is not assessed.
- Lack of explicit adversarial evaluation against maliciously crafted perturbed inputs or automated bot attacks.
- Human coherence evaluation sample size (22 participants over 98 audio snippets) is relatively small; more diverse populations could strengthen conclusions.
- The method relies on availability of multi-track stems with perfect temporal alignment, which may limit applicability in more loosely aligned or live settings.
- Ablation shows architecture-dependent gains, so generalization to very different model backbones or audio types is uncertain.
- No cross-dataset distribution shift tests reported to evaluate generalization beyond datasets combined here.
Open questions / follow-ons
- How well does PHALAR generalize to live, imperfectly aligned, or noisy music recordings?
- Can the complex-valued representation and phase-equivariant design be extended to other audio tasks like source separation or transcription?
- What are the limits of the pitch-equivariant inductive bias when handling non-Western scales or microtonal music?
- Can adversarial robustness be improved to defend against attacks targeting phase or temporal misalignment vulnerabilities?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, PHALAR offers insights into how explicitly modeling temporal and phase information can dramatically improve discrimination in audio-based retrieval tasks. While not directly a captcha solution, the architectural principles—especially Learned Spectral Pooling to capture phase equivariance and complex-valued neural representations—highlight techniques that preserve fine-grained structural information beyond simple semantic embeddings. This has potential implications for designing audio-based CAPTCHAs that require understanding rhythmic and harmonic coherence rather than simple audio classification, making them more robust against naïve bot or replay attacks that rely on semantic similarity alone.
Additionally, PHALAR’s demonstration that large semantic foundation models fail on coherence tasks warns practitioners to carefully consider temporal and phase biases when developing audio challenge-response tests. The use of complex-valued similarity metrics can guide development of similarity functions that reject replays with slight temporal shifts. Overall, PHALAR’s principles show how geometric and algebraic biases aligned with the physics of sound can yield more sophisticated and robust audio representations for security-relevant applications.
Cite
@article{arxiv2605_03929,
title={ PHALAR: Phasors for Learned Musical Audio Representations },
author={ Davide Marincione and Michele Mancusi and Giorgio Strano and Luca Cerovaz and Donato Crisostomi and Roberto Ribuoli and Emanuele Rodolà },
journal={arXiv preprint arXiv:2605.03929},
year={ 2026 },
url={https://arxiv.org/abs/2605.03929}
}