
Label-Efficient School Detection from Aerial Imagery via Weakly Supervised Pretraining and Fine-Tuning
Source: arXiv:2605.03968 · Published 2026-05-05 · By Zakarya Elmimouni, Fares Fourati, Mohamed-Slim Alouini
TL;DR
This work addresses the challenge of detecting school infrastructure from aerial imagery in contexts with scarce manual annotations, a critical problem for global education and connectivity initiatives such as the Giga project. Official school location data is often incomplete or noisy, and manual annotation of bounding boxes on high-resolution aerial images is laborious and costly. The authors propose a weakly supervised, label-efficient pipeline leveraging sparse school geolocations combined with semantic segmentation to automatically generate bounding boxes as noisy labels. They pretrain object detectors on this large noisy dataset and then fine-tune on a small, manually annotated high-quality subset (the golden dataset). Evaluations focus on extremely low-data regimes (50–100 manually labeled images), showing the two-stage training significantly boosts detection metrics compared to training solely on limited clean data.
Their results demonstrate that pretraining on auto-labeled data learns meaningful school-related representations, while fine-tuning corrects noise and improves precision. For example, with only 50 manually labeled images, a YOLO26n detector achieves 0.705 mAP@50 and 0.707 F1-score, outperforming training only on clean labels by +0.403 mAP@50. Increasing manual labels to 100 images raises mAP@50 to 0.868 (+0.546 vs baseline). This approach offers a scalable, practical solution for mapping school infrastructure globally from aerial imagery using minimal human annotation, facilitating infrastructure planning for underserved communities.
Key findings
- With only 50 manually labeled images, YOLO26n trained with weakly supervised pretraining and fine-tuning achieves 0.705 mAP@50 and 0.707 F1-score, improving by +0.403 mAP@50 over training only on labeled data (Table III).
- Pretraining on the large automatically labeled dataset alone yields strong initial representation: YOLO obtains 0.51 recall, F.R-CNN achieves 0.60 mAP@50 on golden test set, surpassing some fully supervised baselines trained on limited data.
- Increasing manually labeled training images to 100 raises YOLO mAP@50 to 0.868 and F1-score to 0.817, a +0.546 mAP@50 improvement compared to training on labeled data only (Table V).
- SatlasNet pretrained on large-scale aerial data achieves high recall (0.833) but very low precision (0.019) when trained on only 50 labeled images, showing a tendency to overdetect buildings non-specifically.
- Automatic filtering of raw geolocation data via vegetation, desert, and sea ratio thresholds removes noisy images, improving quality of auto-generated labels.
- Using multiple semantic prompts ('building', 'roof', 'school') with LangSAM segmentation improves robustness of bounding box generation vs single prompt.
- Data augmentations that include translation prevent center bias during training on auto-labeled data, improving detector generalization.
- ECP (Every Call is Precious) hyperparameter optimization efficiently tunes fine-tuning models under limited compute budgets, improving performance.
Threat model
Not applicable—this work does not focus on adversarial threats or security attacks. The main challenge is data scarcity and label noise in remote sensing school detection, rather than adversarial manipulation.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly defined since this is a remote sensing detection task rather than security-sensitive. The main challenge is scarcity and noise in manual annotations and geolocation labels. They assume access to sparse but approximate geolocated school centers and high resolution aerial imagery. The model does not assume perfect labels, and must learn robust detection despite noisy auto-generated bounding boxes. There is no adversarial attacker modifying imagery or labels.
Data:
- Raw school location points sourced from the GIGA initiative for the U.S. (~12,000 images).
- Non-school negatives sampled from OpenStreetMap features in built-up areas to encourage learning fine-grained discrimination.
- Images are 500×500 pixels (~0.6m resolution) from NAIP aerial imagery.
- A manually labeled 'golden' dataset (~443 images) with exact bounding boxes is created for evaluation, split into train/val/test.
- The training subsets for golden data are stratified into low-data regimes (50, 100, 300 images) plus full 443.
- Automatic filtering removes images with non-sense geolocations (water, deserts, forests) via vegetation, desert, sea coverage metrics computed on 200×200 crops.
- Automatic Labeling:
- Crop a 400×400 patch around each geolocated school center.
- Use LangSAM, a state-of-the-art segmentation approach conditioned on text and image, to obtain segmentation masks based on prompts: “building,” “roof,” and “school.”
- Select candidate masks filtered by size thresholds.
- Choose the two masks whose centroid is closest to center point.
- Optionally fuse masks if spatial overlap is sufficient.
- Use shape heuristics like solidity to validate masks as building-like.
- Compute convex hull bounding boxes of accepted masks.
- Model Training:
- Multiple detector backbones evaluated: YOLO family (specifically YOLO26n), Faster R-CNN, and SatlasNet pretrained on aerial imagery.
- Models initialized either from COCO weights (YOLO, Faster R-CNN) or large aerial pretraining (SatlasNet).
- Train initially on the large, automatically labeled noisy dataset with data augmentation including translation to avoid center bias.
- Evaluation all done on clean manually annotated test set.
- Fine-Tuning:
- The pretrained detectors are fine-tuned on small golden datasets of sizes 50, 100, 300, and 443 images.
- Hyperparameters tuned via ECP, a black-box optimization method tailored to expensive model training evaluations.
- Fine-tuning reduces labeling noise artefacts and improves localization precision and overall metrics.
- Evaluation:
- Metrics include Precision, Recall, F1-score, mAP@50, mAP@50:95.
- Intersection over Union (IoU) threshold set at 0.5 for true positives.
- Validation and test sets fixed across all experiments.
- Comparisons of three training regimes: training on only golden (clean) labels, only auto-labeled data, and the proposed two-stage pipeline.
- Experiments focus on low-data regimes (50-100 images) reflecting practical annotation scarcity.
- Qualitative visualizations support quantitative results (Fig 2).
- Reproducibility:
- Code, trained model weights, and automatically generated labels are publicly released, enabling verification and extension.
- Evaluation datasets and splits are fixed and described for reproducibility.
Concrete end-to-end example: A school coordinate is collected from GIGA; a 400×400 pixel aerial crop centers that location; LangSAM segments buildings prompted with "school" and "roof"; valid masks near center are fused and bounding boxes computed; these auto-labels form noisy training data for a YOLO detector pretrained on COCO; after pretraining on thousands of these auto-labeled images, the detector is fine-tuned on 50 manually annotated golden images with ECP hyperparameter tuning; final evaluation on held-out golden test set shows improved mAP and F1-score over training only on golden labels.
Technical innovations
- A novel automatic labeling pipeline that converts sparse geolocated school center points into bounding box annotations via multi-prompt semantic segmentation using LangSAM.
- A two-stage training framework combining weakly supervised pretraining on noisy auto-labeled data followed by fine-tuning on small, clean manually annotated datasets to boost low-data object detection.
- Use of multiple textual prompts ('building', 'roof', 'school') with LangSAM segmentation to increase robustness of auto-labels for aerial school detection.
- Incorporation of translation data augmentation during training on auto-labeled data to prevent degenerate center-biased predictions.
- Application of efficient black-box hyperparameter optimization (Every Call is Precious - ECP) to tune fine-tuning models under computational constraints.
Datasets
- GIGA dataset - ~12,000 geo-located school center images (auto-labeled) - publicly available via GIGA initiative
- Golden dataset - 443 high-quality manually annotated images with bounding boxes - collected and released by authors
- Non-school negative images - ~2,985 geo-locations from OpenStreetMap with imagery downloaded from NAIP
Baselines vs proposed
- YOLO26n trained only on 50 golden images: mAP@50 = 0.302 vs proposed (pretrain + fine-tune): 0.705
- Faster R-CNN trained only on 50 golden images: lower precision and recall vs with pretraining + fine-tuning gains of ~+0.38 mAP@50
- SatlasNet pretrained on aerials trained only on 50 golden images: recall=0.833 but precision=0.019, F1=0.037; improved to F1=0.179 with ECP tuning but still low precision
- YOLO26n with 100 golden images: mAP@50 = 0.322 golden-only vs 0.868 with pretraining + fine-tuning (+0.546 delta)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.03968.
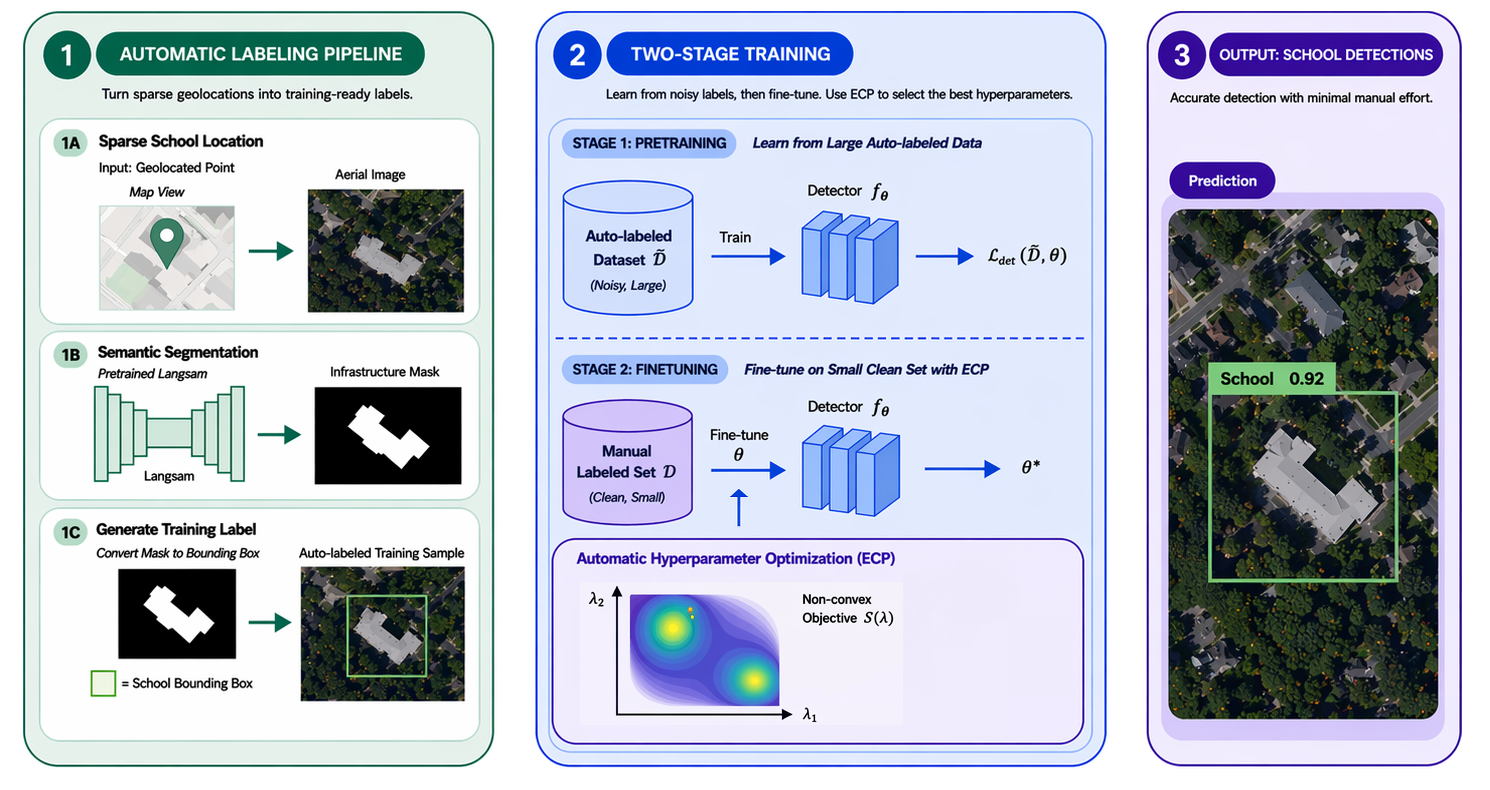
Fig 1: Overview of the proposed weakly supervised pipeline for school detection from aerial imagery. Sparse geolocated points are first
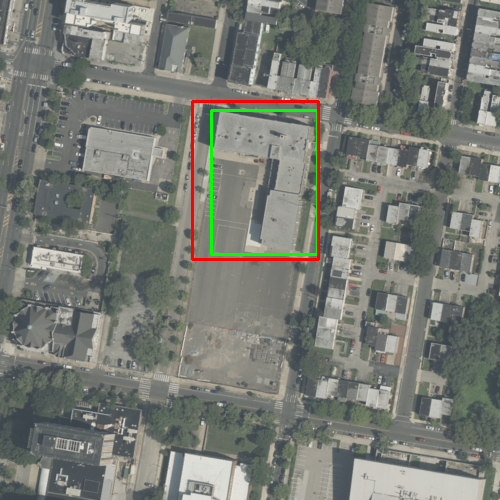
Fig 2: Qualitative predictions of a detector across four examples. Ground truth is shown in green; predictions in red.
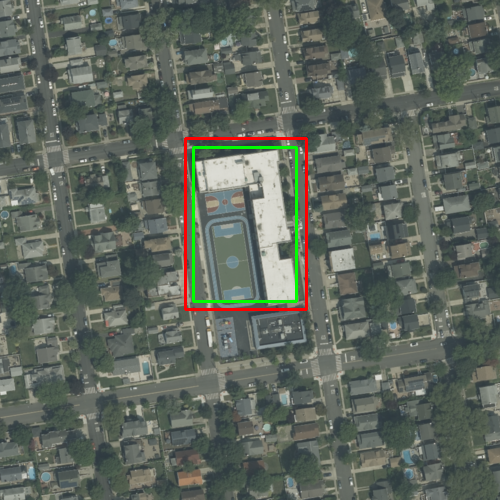
Fig 3: Segmentation process: from crop to segmentation mask
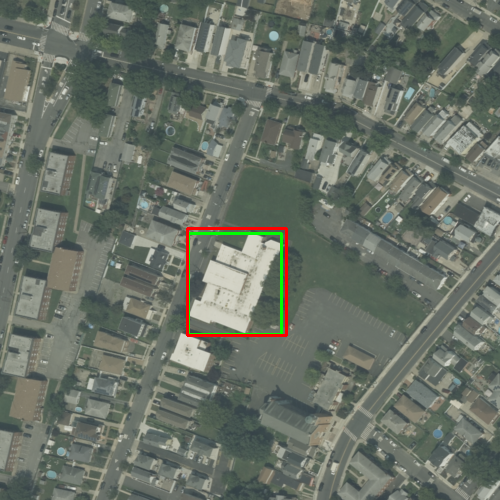
Fig 4 (page 3).
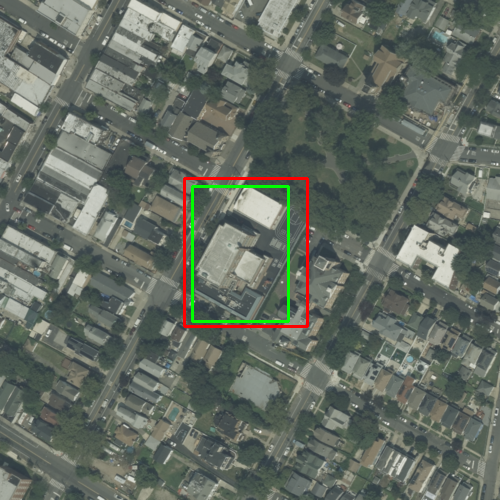
Fig 5 (page 3).

Fig 6 (page 4).

Fig 7 (page 4).
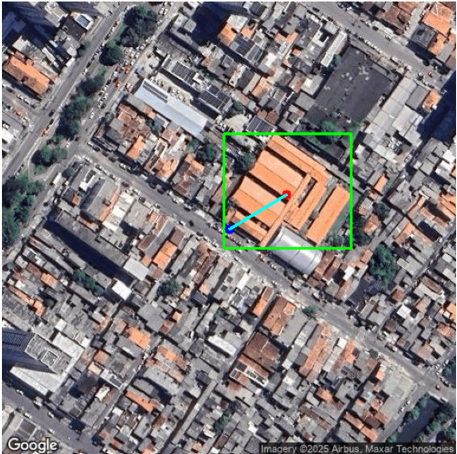
Fig 8 (page 4).
Limitations
- Automatic labeling pipeline depends on quality and accuracy of geolocated center points which can occasionally be noisy or misaligned.
- Semantic segmentation masks used for bounding boxes can contain noise and occasional misses, limiting label quality.
- Evaluations are primarily conducted on U.S. aerial imagery; generalization to other countries or satellite imagery with differing resolutions/licensing is not empirically demonstrated.
- No adversarial robustness or adversarial attack evaluation conducted against malicious manipulation of images or labels.
- Fine-tuning primarily tested on a maximum of 443 manually labeled images; behavior on truly large datasets or very different domains not explored.
- Model comparisons limited to certain architectures; emerging or transformer-based detectors not analyzed.
Open questions / follow-ons
- How well does the weakly supervised pipeline generalize to non-U.S. regions with different building styles, vegetation, and roof materials?
- Can the automatic labeling approach be extended or adapted to detect other infrastructure types beyond schools, such as hospitals or community centers?
- What is the impact on performance of incorporating temporal or multi-spectral satellite imagery rather than single-date aerial RGB imagery?
- Could transformer-based segmentation and detection architectures improve robustness or accuracy in low-data regimes compared to CNN-based YOLO or Faster R-CNN variants?
Why it matters for bot defense
From a bot-defense or CAPTCHA perspective, this paper offers important insights into leveraging weak supervision with minimal high-quality labels to robustly detect structured objects in complex, noisy visual data. The method of combining sparse geolocations with semantic segmentation to generate noisy pseudo-labels could inspire similar labeling strategies for detecting suspicious or anomalous user interface elements or bot interactions where large-scale manual annotation is impractical. The two-stage training approach—pretraining on noisy auto-generated labels then fine-tuning on a small trusted set—provides a generalizable recipe for improving detection accuracy under data scarcity, a common challenge in bot-detection due to changing tactics and limited labeled attacks. While the domain is different, the methodology and challenges around limited annotation and noisy labels resonate with bot defense AI where high-quality labels are expensive and attackers adapt rapidly. Thus, the concepts here can guide label-efficient model training and scalable dataset construction for real-world CAPTCHA or anomaly detection systems.
Cite
@article{arxiv2605_03968,
title={ Label-Efficient School Detection from Aerial Imagery via Weakly Supervised Pretraining and Fine-Tuning },
author={ Zakarya Elmimouni and Fares Fourati and Mohamed-Slim Alouini },
journal={arXiv preprint arXiv:2605.03968},
year={ 2026 },
url={https://arxiv.org/abs/2605.03968}
}