
Fast, accurate, high-resolution simulation of large-scale Fermi-Hubbard models on a digital quantum processor
Source: arXiv:2605.04025 · Published 2026-05-05 · By Gavin S. Hartnett, Khadijeh Sona Najafi, Aleksei Khindanov, Haoran Liao, Michael Schutzman, Michael R. Hush et al.
TL;DR
This paper tackles a very practical bottleneck in digital quantum simulation: how to run large, long-time Fermi-Hubbard dynamics on real hardware without the circuit cost and noise overwhelming the signal. The authors’ core idea is not a new physics result so much as an execution stack: an application-aware Jordan–Wigner layout, a fermionic SWAP network, mirrored Trotterization, and runtime error-suppression/post-processing designed to keep the circuits shallow enough for IBM Heron devices while preserving measurable accuracy.
The headline result is that they push 1D Fermi-Hubbard simulations to 120 qubits, 90 Trotter steps, and evolution times up to t=9 in natural units. On an L=31 chain with a vacancy defect in a Néel state, they directly observe spin-charge separation and extract velocity ratios vc/vs that match TDVP-classical benchmarks over multiple U values. On a larger L=60 system, hardware outputs agree with TDVP to about 1% RMSE up to about t≈5.2 when TDVP uses χ=4096, after which the two methods diverge; in that regime the authors claim quantum wall-clock runtime can be up to 3000× faster than the optimized TDVP run they benchmark against.
Key findings
- The deepest experiment uses L=31 sites, 62 qubits, t=9, and 90 Trotter steps; the widest uses L=60 sites, 120 qubits, t=6, and 30 Trotter steps.
- For the L=31 vacancy-quench study, the authors directly observe spin-charge separation and extract velocity ratios vc/vs across U/th ∈ {0,2,4,6,8,10,12,14} that agree with TDVP within the reported error bars.
- Fig. 2(g–i) reports charge velocities vc from about 2.06 to 1.83 (in th units) and spin velocities vs from about 2.41 down to 0.58 as U/th increases from 2 to 14.
- For the L=60 benchmarks, RMSE between quantum hardware and TDVP remains around 1% up to about t≈5.2 with χ=4096, then rises to about 4% by t=6.
- The paper reports >13,800 two-qubit gates for the deepest circuit and 9,057 two-qubit gates over 152 layers for the largest-qubit-count circuits, with 20,000 shots per circuit on ibm boston.
- Relative to a baseline Qiskit Nature Jordan–Wigner + Qiskit transpiler (level-3), the specialized compilation reduces overall circuit depth by >80% and two-qubit gate count by >60% for the largest circuits.
- Relative to the interleaved ordering in Ref. [48] under comparable conditions (equivalent to L=52 and 10 second-order Trotter steps), the authors claim 40.5% fewer two-qubit gates and 60% lower circuit depth.
- For t≳5 in the TDVP χ=4096 benchmark regime, the authors report quantum hardware is up to 3000× faster in wall-clock time than the optimized TDVP implementation they used.
Methodology — deep read
The threat model is not adversarial in the cybersecurity sense; this is a numerical physics paper. The relevant “challenge” is computational: exact statevector methods are infeasible beyond modest sizes, and tensor-network methods such as TDVP become expensive as entanglement grows after a quench. The authors explicitly position the hardware as competing against classical approximations rather than against an attacker. They assume a 1D homogeneous Fermi-Hubbard chain, open boundary conditions as implied by the chain indexing, and initial states that are Fock states—mostly Néel states, sometimes with a localized vacancy defect.
The data are generated experimentally on IBM’s 156-qubit Heron device ibm boston. The main experimental regimes are L=31 (62 qubits) and L=60 (120 qubits). For the L=31 study, they vary U/th over {0,2,4,6,8,10,12,14} and use 45, 60, or 90 Trotter steps depending on the coupling, reaching t=9. For the L=60 study, they run a Néel state and a Néel-plus-vacancy state at U/th=-2 to t=6 with up to 30 Trotter steps. Each circuit is executed with 20,000 shots. The observables are measured in the occupation/Fock basis, giving per-site spin-up and spin-down occupations, local charge density, and a spin correlator built from Sz_i=(ni,↑−ni,↓)/2. For benchmarking, they compare to TDVP simulations on a smaller L=23 lattice for the spin/charge velocity extraction and on the full L=60 lattice for the occupation dynamics. The TDVP sweeps use bond dimensions up to χ=4096, and the paper also mentions comparisons to Pauli path propagation (PPP) in the supplement. Preprocessing includes a lightweight correction for readout error and incoherent decay; the authors also use bootstrap resampling (2000 samples) to estimate uncertainty on extracted velocities.
The algorithmic contribution starts with a Jordan–Wigner mapping chosen specifically to minimize nonlocality on the hardware topology. They use a pair-interleaved fermion ordering, {c0↓, c0↑, c1↑, c1↓, c2↓, c2↑, ...}, which makes nearest-neighbor hopping map into a mixture of “short-hop” weight-2 terms (XX+YY) and “long-hop” weight-4 terms (XZZX+YZZY). The onsite interaction becomes RZZ gates between the two spin orbitals on each site, plus single-qubit RZ terms from the chemical potential and interaction decomposition. To avoid costly nonlocal routing, they introduce an fSWAP network that exchanges spin-up and spin-down fermions each layer; this turns the long-hop terms into short-hop terms in alternating layers. The Trotter circuit is then built as a mirrored sequence: RZ layer, short-hop RXX+YY, RZZ onsite interaction, fSWAP layer, another RXX+YY layer, and a symmetrized RZ layer, with subsequent layers mirrored to improve error scaling. The important nuance is that the authors rely on a first-order per-step decomposition, but the mirrored pairing of adjacent steps yields effective second-order accuracy over two-step blocks, reducing Trotter error without changing the hardware gate set.
Training is not applicable in the ML sense; instead, the “regime” is circuit execution. They select the Trotter step size Δt empirically to balance algorithmic and hardware error, with Δt=0.2, 0.15, or 0.1 depending on U in the L=31 study, and a similar parameter choice for the L=60 runs. Compilation uses Q-CTRL Fire Opal on IBM Heron native gates (RZZ, RZ, CZ, X, √X), embeds the qubit chain as a snaking path on the heavy-hex graph, and avoids poorly performing qubits via layout selection. The paper says deterministic error suppression and randomized compiling are used, plus dynamical decoupling and a lightweight post-processing step to compensate readout and decay. The authors emphasize that these error-reduction methods do not require extra circuit executions, which matters because they are trying to preserve any runtime advantage over TDVP. Concrete execution details given in the text include 9,057 two-qubit gates and 152 layers for the largest-qubit circuits, and >13,800 two-qubit gates for the deepest L=31, t=9 circuits.
Evaluation is split into two core experiments. First, for spin-charge separation, they prepare a Néel state with a central vacancy on L=31 and track the time evolution of the charge tracer Cc_i(t)=⟨ni,↑+ni,↓⟩−⟨ni,↑(0)+ni,↓(0)⟩ and the spin tracer Cs_i(t)=4(⟨Sz_i(t)Sz_i*(t)⟩−⟨Sz_i(t)⟩⟨Sz_i*(t)⟩), where i* is the vacancy site. They identify wavefronts using a simple detection protocol described in the supplement, then fit velocities vc and vs. The result in Fig. 2(g–i) is a velocity ratio vc/vs that matches TDVP across U/th values. Second, for the L=60 benchmark, they compare occupation dynamics site-by-site against TDVP for bond dimensions χ∈{64,…,4096}. Fig. 4(a–c) shows that larger χ extends the time window of agreement, with RMSE computed over all 120 spin orbitals. The paper explicitly marks a noise floor around RMSE=0.01 and notes a divergence region beyond t≈5.2 where neither method can be asserted to be the true dynamics from the data alone. Fig. 4(d) then compares wall-clock runtime, claiming roughly 2 minutes 46 seconds total QPU runtime for all quantum circuits versus >100 hours for TDVP near the divergence point and >160 hours for the longest χ=4096 TDVP run to t=6.
Reproducibility is partial rather than complete. The paper clearly specifies the hardware platform, gate set, circuit structure, shot count, and several key parameter sweeps, but the full details are in the supplementary material, which is not included here. The authors mention use of ITensor/ITensorMPS.jl, AWS c7i.8xlarge hardware for classical runs, and an optimized TDVP implementation in consultation with the ITensor developers. They do not provide frozen weights because this is not a learned model. They also note that the accuracy/cost tradeoff depends on chosen Trotter step sizes, device calibration, and error-suppression pipeline, so exact replication likely requires the same compilation stack and hardware class.
Technical innovations
- A pair-interleaved Jordan–Wigner encoding plus fSWAP network that keeps all hopping and interaction terms local enough for heavy-hex hardware.
- Mirrored Trotter layering that turns a first-order step into an effectively second-order block without changing the hardware primitive set.
- A no-overhead error-reduction pipeline combining deterministic suppression, randomized compiling, dynamical decoupling, and light post-processing.
- An application-aware compilation flow that co-optimizes fermion ordering, device layout, and native gate decomposition for large 1D Fermi-Hubbard circuits.
Datasets
- Experimental circuit outputs on ibm boston — 20,000 shots per circuit — non-public hardware runs
- TDVP benchmark trajectories — not specified in size; L=23 for velocity extraction and L=60 for occupation benchmarks — classical simulations run with ITensor/ITensorMPS.jl
- PPP comparison data — not specified — supplementary classical benchmark
Baselines vs proposed
- TDVP (L=23, χ=1024) for velocity extraction: qualitative/quantitative agreement with hardware across U/th ∈ {0,2,4,6,8,10,12,14}; the paper reports matching vc/vs trends, but no single aggregate metric is given.
- TDVP (L=60, χ=64 to 4096): RMSE ≲ 1% up to about t≈5.2 for χ=4096 vs proposed quantum outputs; RMSE reaches ~4% at t=6.
- Baseline Qiskit Nature Jordan–Wigner + Qiskit transpiler (level-3): two-qubit gate count reduced by >60% vs proposed for the largest circuits; circuit depth reduced by >80%.
- Interleaved ordering from Ref. [48] under comparable conditions: 40.5% fewer two-qubit gates and 60% lower circuit depth vs proposed.
- Optimized TDVP wall-clock: >100 hours at t≈5.2, χ=4096 vs proposed quantum runtime around 2 minutes; at t=6, TDVP exceeds 160 hours vs proposed quantum runtime roughly unchanged order of minutes.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.04025.

Fig 2: Spin-charge separation exhibited in the evolution of a central vacancy in a N´eel initial state for L = 31 over a
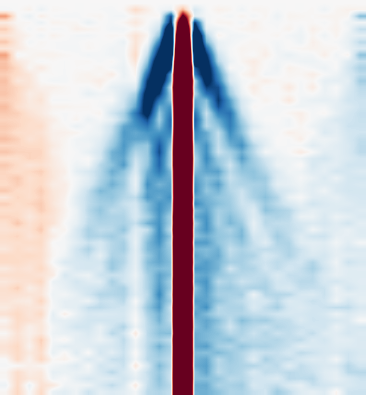
Fig 3: Digital quantum simulation of the Fermi-Hubbard model for two initial states of an L = 60 chain with interaction
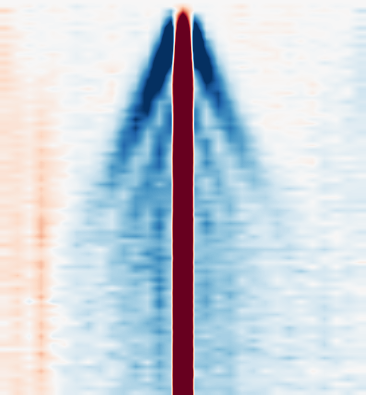
Fig 4: Quantum simulator outputs benchmarked

Fig 4 (page 5).
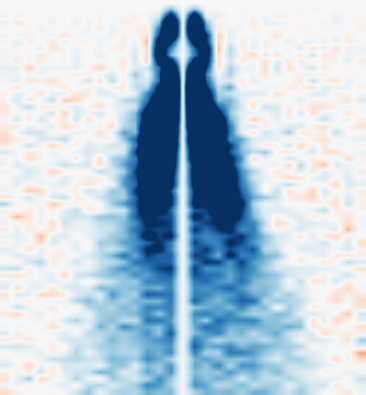
Fig 5 (page 5).
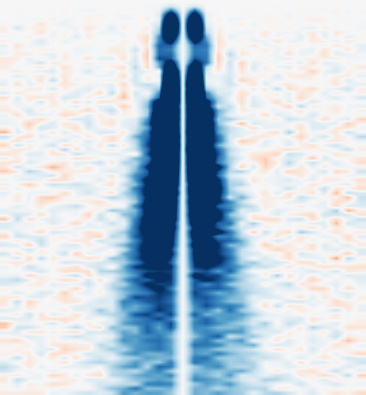
Fig 6 (page 5).

Fig 7 (page 6).

Fig 8 (page 6).
Limitations
- The paper’s strongest claims rely on comparison to approximate classical methods; beyond t≈5.2 in the L=60 study, the authors explicitly say it is indeterminate which method is more correct.
- Error mitigation is helpful but not free from interpretation risk: the paper uses lightweight post-processing for readout/decay, but the exact residual bias after correction is not fully resolved in the excerpt.
- Benchmarking is limited to 1D chains and specific initial states (Néel and vacancy defects), so generalization to higher-dimensional or more entangled settings is not demonstrated here.
- The classical baseline is TDVP, which is strong in 1D but not exact; no exact solver exists at these sizes, so the most important results remain benchmark-relative.
- The runtime comparison is tied to a specific ITensor implementation on a specific CPU instance; future GPU or algorithmic improvements could narrow the claimed speedup.
- The supplement is required for several procedural details (Trotter-error analysis, wavefront detection, error suppression, and classical benchmarking), so full reproducibility from the excerpt alone is incomplete.
Open questions / follow-ons
- How far can the same compilation and error-suppression stack be pushed before hardware noise or Trotter error dominates for truly nonintegrable 1D dynamics?
- Can the no-overhead error-reduction approach be generalized to two-dimensional Hubbard dynamics or to circuits with less favorable fermion connectivity?
- What is the quantitative breakdown between Trotter error, coherent hardware error, and post-processing bias in the regimes where hardware and TDVP diverge?
- Can an exact or near-exact classical benchmark be developed for some intermediate regimes to validate claims beyond TDVP agreement?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most relevant lesson is architectural rather than domain-specific: if the workload has strong structure, the biggest gains come from aligning representation, circuit layout, and error-reduction with the target hardware, not from generic optimization. The authors get their speed and accuracy by removing nonlocality from the mapping, minimizing routing overhead, and keeping mitigation overhead close to zero. That is a useful pattern for any adversarial or high-throughput verification system that relies on expensive physical or cryptographic primitives.
A second takeaway is about benchmarking discipline. The paper is careful to compare against the strongest classical method it can practically run, then explicitly marks the region where the benchmark itself becomes unreliable. For CAPTCHA and fraud teams, that’s analogous to knowing when a detector’s offline ROC curve no longer reflects production reality because the attack distribution or compute budget changes. The paper is a reminder to benchmark against adaptive, high-end baselines, report the divergence region honestly, and separate algorithmic wins from hardware-specific runtime wins.
Cite
@article{arxiv2605_04025,
title={ Fast, accurate, high-resolution simulation of large-scale Fermi-Hubbard models on a digital quantum processor },
author={ Gavin S. Hartnett and Khadijeh Sona Najafi and Aleksei Khindanov and Haoran Liao and Michael Schutzman and Michael R. Hush and Michael J. Biercuk and Yuval Baum },
journal={arXiv preprint arXiv:2605.04025},
year={ 2026 },
url={https://arxiv.org/abs/2605.04025}
}