
Conditional Diffusion Sampling
Source: arXiv:2605.04013 · Published 2026-05-05 · By Francisco M. Castro-Macías, Pablo Morales-Álvarez, Saifuddin Syed, Daniel Hernández-Lobato, Rafael Molina, José Miguel Hernández-Lobato
TL;DR
This paper addresses the challenging problem of sampling from complex, unnormalized multimodal distributions when density evaluations are costly. Traditional methods like Parallel Tempering (PT) perform global exploration but can be computationally expensive and slow to converge when the overlap between reference and target distributions is limited. Diffusion-based approaches offer continuous transport but require costly neural network training to approximate transport dynamics. To overcome these limitations, the authors introduce Conditional Diffusion Sampling (CDS), a novel framework that leverages exact, closed-form stochastic differential equations (SDEs) derived from Conditional Interpolants. Unlike prior diffusion samplers, CDS does not require neural approximations and combines the strong global exploration of PT with efficient local transport via diffusion.
CDS performs sampling in two stages: first, PT is used to sample from a conditional distribution close to a reference distribution to leverage strong initial overlap; second, samples are transported via integrating a closed-form SDE to the target distribution. The authors provide both theoretical and empirical analysis showing that initializing at a small positive time t0 > 0 allows efficient sampling of the initial distribution and reduces transport cost. Extensive experiments on eight benchmark tasks including synthetic Gaussian mixtures, molecular systems (Alanine Dipeptide), and high-dimensional Bayesian neural network posteriors demonstrate that CDS achieves superior trade-offs between sample quality and density evaluation cost compared to state-of-the-art MCMC baselines such as Non-Reversible PT, Annealed SMC, Diffusive Gibbs Sampling, HMC, and MALA.
Key findings
- CDS achieves a mean Hypervolume Ratio (HVR) of 0.9863 across eight tasks, outperforming strong baselines including Non-Reversible PT (NRPT), HMC, and MALA.
- Decreasing the initialization time t0 from 1.0 boosts communication efficiency in PT, increasing Round Trips (RTs) and improving sample quality, with an optimal small t0 balancing overlap and concentration (Fig. 4).
- Using SDE integration for transport (Stage 2) consistently outperforms directly applying inverse interpolation maps to transport samples from νt0|z to the target (Fig. 5).
- CDS maintains strong performance on medium-dimensional Gaussian mixture benchmarks (GM-16), where competing methods like DiGS degrade due to Gibbs sampling inefficiency.
- In complex physical systems like Alanine Dipeptide (ALDP), CDS and NRPT capture all modes successfully within a fixed computational budget of 2×10^5 density evaluations (Fig. 2).
- For high-dimensional Bayesian neural network posteriors (dimension 550), CDS significantly outperforms all other MCMC methods in test negative log-likelihood metrics.
- Theoretical results show that the initialization sample distribution νt0|z contracts toward the reference distribution as t0 → 0, allowing efficient PT sampling with provably reduced transport cost (Eq. 18, 19).
- Careful tuning of the computational budget split between Stage 1 PT steps (K) and Stage 2 SDE integration steps (N) is necessary to balance global exploration and accurate transport.
Methodology — deep read
The authors consider the problem of sampling from an unnormalized target distribution ν on a space X, where only an unnormalized density ˜π is accessible. They assume that evaluation of ˜π is expensive, making efficient sampling critical.
Threat Model & Assumptions: The goal is to sample independent draws from the target ν given access only to the unnormalized density ˜π. No prior samples from ν are assumed, and the adversary is not explicitly modeled since this is a sampling methodology paper.
Data: The evaluation is conducted on eight target distributions across four tasks covering synthetic Gaussian mixtures, Lennard-Jones molecular clusters, Alanine Dipeptide protein folding conformations, and Bayesian neural network posteriors. Dimensionalities range from 2 to 550. Tasks have varying multimodality and challenging energy landscapes with computationally costly density/score evaluations. Detailed dataset construction and label generation for evaluating sample quality metrics like Wasserstein-2 distance, KL divergence of Ramachandran histograms, and test log-likelihood are described in appendices.
Architecture / Algorithm: The authors introduce Conditional Interpolants, a class of stochastic interpolants defined via a conditional interpolation map Ft|z, where z is a sample from a simple reference distribution νref. The interpolation path νt|z bridges from a Dirac delta at z (t=0) to the target ν at t=1. They derive exact closed-form stochastic differential equations (SDEs) governing transport along this path, where the drift comprises a velocity field ut|z plus a score correction term based on ∇log πt|z. Uniquely, the score is computed directly via change-of-variable formulas without neural network approximation.
Training Regime: As no learned components exist, no training in the neural network sense occurs. Instead, CDS combines two algorithmic stages: (1) Sampling near t0 > 0 using Parallel Tempering (PT) to draw from νt0|z, leveraging high overlap with the reference and mode exploration; (2) Integrating the closed-form SDE from t0 to 1 using Euler–Maruyama discretization with MCMC correctors to transport samples accurately to the target. The computational budget is divided between these stages to optimize performance.
Evaluation Protocol: Performance is measured by sampling error metrics (Wasserstein-2, KL divergences, negative log-likelihood) versus density evaluation counts. Round trips (RTs) quantify PT communication efficiency. Comparisons are made with strong MCMC baselines (NRPT, OASMC, DiGS, HMC, MALA). Average Pareto fronts and Mean Hypervolume Ratio (HVR) summarize the trade-off between sample quality and computation over repeated runs.
Reproducibility: The authors release code at a public GitHub repository for Conditional Diffusion Sampling. Detailed experimental parameters, algorithmic pseudocode (Algorithm 1), and ablation studies are provided in appendices. Some datasets like molecular simulations and Bayesian neural network posteriors are publicly documented or synthesized from standard benchmarks; no closed datasets are used.
Example End-to-End: Using the linear interpolant, the algorithm starts by drawing a reference sample z from νref (e.g., standard Gaussian). Stage 1 runs K steps of Parallel Tempering targeting the conditional distribution νt0|z with a small t0 (e.g., 0.1), yielding approximate samples local to z but expanded to cover modes. Next, Stage 2 integrates the conditional diffusion SDE with noise schedule σt and velocity plus score drift terms from t0 to 1 with N integration steps and M MCMC correction steps. This continuously transforms samples from νt0|z into accurate draws from the target distribution ν without any learned transport map. Throughout, the method balances computational effort and achieves better mixing and sample quality than baseline MCMC and diffusion samplers.
Technical innovations
- Introduction of Conditional Interpolants, stochastic interpolants defined conditionally on reference samples, admitting closed-form exact SDE transport dynamics without neural approximations.
- Two-stage Conditional Diffusion Sampling (CDS) that couples Parallel Tempering-based sampling of a near-reference initialization distribution with closed-form SDE transport to the target.
- Theoretical analysis proving that the transport cost and sampling error decrease as the initialization time t0 approaches zero, enabling efficient approximate initial sampling.
- Integration of global exploration via annealing and Parallel Tempering with efficient local refinement via exact conditional diffusion, overcoming limitations of prior marginal/interpolant methods requiring neural score approximations.
Datasets
- GM-2 — 2D Gaussian Mixtures — synthetic benchmark
- GMNU-2 — 2D Non-Uniform Gaussian Mixtures — synthetic benchmark
- GM-16 — 16D Gaussian Mixtures — synthetic benchmark
- GMNU-16 — 16D Non-Uniform Gaussian Mixtures — synthetic benchmark
- LJ-13 — 39D Lennard-Jones 13 atom cluster — molecular physics benchmark
- LJ-55 — 165D Lennard-Jones 55 atom cluster — molecular physics benchmark
- ALDP — 66D Alanine Dipeptide Ramachandran angles — molecular dynamics benchmark
- BNN — 550D Bayesian Neural Network posterior — high dimensional Bayesian inference benchmark
Baselines vs proposed
- HMC: task-dependent metric W2 or test NLL values consistently worse than CDS across all tasks
- MALA: similar to HMC, generally worse sample quality than CDS (e.g., W2 on GM-16 and KL on ALDP)
- NRPT (Non-Reversible PT): competitive but CDS outperforms in medium/high dimension benchmarks and complex targets, mean HVR CDS = 0.9863 > NRPT (see Table 2)
- OASMC: outperformed by CDS and NRPT on several tasks, especially ALDP and BNN
- DiGS: strong in low dimension but performance degrades on GM-16 and GMNU-16, CDS remains stable and better
- Inverse interpolation mapping (without SDE transport): performs worse than CDS with SDE, especially in complex tasks (Fig. 5)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.04013.

Fig 1: Overview of CDS. In the first stage, Parallel Tempering

Fig 2: Ramachandran histograms of Alanine Dipeptide (ALDP) in vacuum at T = 300K. All methods utilize a fixed budget of
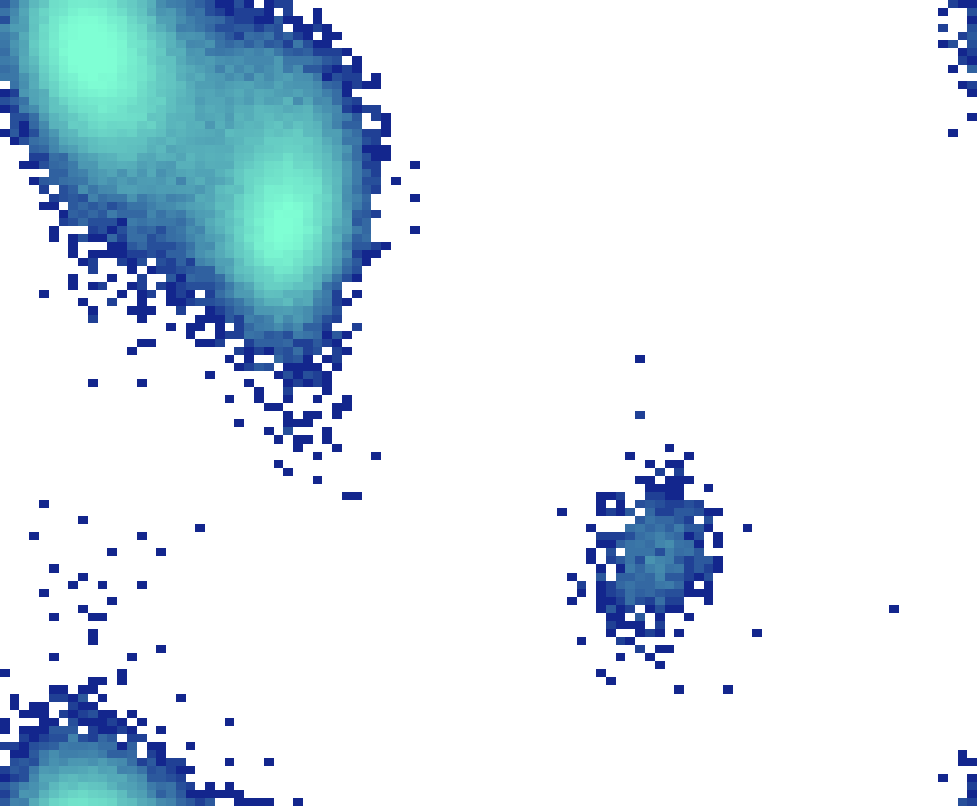
Fig 3: Density evolution and exact samples from πt|z. This plot illustrates the linear interpolant for a fixed z sampled from N(0, I).
Fig 4 (page 2).
Fig 5 (page 2).
Fig 6 (page 2).
Fig 7 (page 2).

Fig 8 (page 2).
Limitations
- Initialization requires careful tuning of the near-zero time t0 to balance overlap and sample concentration; too small t0 can reduce mixing efficiency.
- The method relies on a suitable choice of interpolant map; the linear interpolant can induce adverse geometry in some tasks (e.g., ALDP with LJ potential) affecting performance.
- Scalability beyond 550 dimensions was not explored; performance and mixing in very high-dimensional spaces remain open.
- CDS requires calling Parallel Tempering for each new reference sample, which may limit amortization benefits compared to neural samplers.
- Application to very large-scale models or non-smooth target densities remains untested.
- The approach assumes exact access to gradients of log-densities; noisy or approximate gradients may impact effectiveness.
Open questions / follow-ons
- How to optimally select or adapt the initialization time t0 automatically during sampling to maximize overlap and minimize mixing time.
- Extensions of Conditional Interpolants beyond linear maps to more flexible interpolants that preserve tractable conditional densities and closed-form transport.
- Integration of learned components or amortized inference with CDS to scale to higher dimensions or address scenarios with partially observed or noisy gradients.
- Robustness and performance of CDS under approximate density evaluations or stochastic gradients common in practical scientific applications.
Why it matters for bot defense
Sampling multimodal distributions efficiently with limited density queries is conceptually adjacent to bot defense tasks involving high-dimensional probability landscapes, such as CAPTCHA challenges that adapt dynamically to user interactions or bot behavior models. The Conditional Diffusion Sampling framework offers insights into combining global exploration via annealing (Parallel Tempering) with exact local refinements without expensive neural approximations. For CAPTCHA engineers, ideas analogous to conditional interpolation and two-stage sampling could inspire defenses that are robust to adversaries exploring the challenge space and improve generation of diverse challenge instances with fewer computational resources. Furthermore, the principle of careful initialization at distributions closer to reference samples to enable more efficient global-local transport suggests strategies to optimize challenge generation pipelines under budget constraints. While CDS is a sampling method primarily for continuous distributions, the underlying approach of combining annealing and exact transport dynamics could be adapted to discrete or hybrid challenge spaces relevant to bot detection and mitigation.
Cite
@article{arxiv2605_04013,
title={ Conditional Diffusion Sampling },
author={ Francisco M. Castro-Macías and Pablo Morales-Álvarez and Saifuddin Syed and Daniel Hernández-Lobato and Rafael Molina and José Miguel Hernández-Lobato },
journal={arXiv preprint arXiv:2605.04013},
year={ 2026 },
url={https://arxiv.org/abs/2605.04013}
}