
GuardSec: A Multi-Modal Web Platform for Real-Time Digital Fraud Detection, Entity Verification, and Connection Security Analysis in the African Context
Source: arXiv:2605.02502 · Published 2026-05-04 · By Gilda Rech Bansimba, Regis Freguin Babindamana
TL;DR
GuardSec is presented as a production-deployed, browser-based fraud verification platform aimed at ordinary users in African contexts where cybercrime, mobile-money scams, and connection-level exposure are common, but existing tools are aimed at SOC analysts and require technical literacy. The system covers five external entity types (URL, website/domain, phone number, email, business entity) and adds two notable user-facing modules: Mon Empreinte, which audits the visitor’s own connection and digital exposure, and Gilda, a conversational assistant that explains verdicts and recommends actions in plain language.
The paper’s main novelty is less about a new detection model than about packaging heterogeneous threat intelligence into a deployable, low-friction web service with an explicit latency budget and accessibility constraints. Empirically, the authors evaluate a manually annotated subset of 312 entities drawn from 5,520 production interactions and report overall F1 = 0.890 and AUC-ROC = 0.927, with per-type F1 ranging from 0.864 for phone numbers to 0.923 for domain names. The authors frame these results as meaningfully better in practice than higher-benchmark systems that are not shipped or accessible to end users.
Key findings
- The evaluation uses a small labeled set, Neval = 312, sampled from 5,520 production interactions, with two cybersecurity annotators and Cohen’s κ = 0.87 for agreement.
- Overall detection performance is reported as F1 = 0.890 and AUC-ROC = 0.927 on the labeled evaluation subset.
- Per-entity F1 varies by type: URL 0.907, email 0.888, phone 0.864, domain 0.923, business 0.870.
- For URL/domain queries, the system uses a 4.5 s global budget with four external subqueries each capped at 1.5 s, and failed sub-vectors fall back to zero vectors instead of failing the request.
- The cost model is asymmetric with cFN = 3 × cFP, which pushes the decision threshold below 0.5 to favor recall over precision.
- Mon Empreinte analyzes 12 security indicators plus connection attributes such as IP geolocation, ISP/ASN, browser/user-agent, cookies, JavaScript status, and DNS leak / VPN / Tor signals.
- The platform is publicly deployed at guardsec.io and requires no registration or API key, which is central to the paper’s utility claim rather than a side detail.
Threat model
The adversary is a fraud operator or impersonator using malicious URLs, counterfeit domains, phishing emails, fraudulent phone numbers, or fake business identities, and potentially leveraging network-level manipulation such as DNS hijacking, proxies, VPN leaks, or interception on insecure mobile/public connections. The system assumes the attacker can vary surface features to evade simple lexical rules and may exploit data sparsity or reputation-feed lag, but cannot directly tamper with the user’s browser/runtime beyond what is observable through headers, external lookups, and reputation services. GuardSec also implicitly assumes the user is an honest querier rather than an active adversary, though the service is exposed publicly and therefore must tolerate noisy, incomplete, or maliciously crafted requests.
Methodology — deep read
GuardSec is framed as a security and usability problem rather than a pure ML benchmark problem. The authors’ threat model is implicitly a fraudster or malicious entity trying to impersonate legitimate URLs, domains, emails, phone numbers, and businesses, plus a broader network adversary capable of DNS manipulation, proxy/VPN leakage, and traffic interception on public or poorly managed mobile networks. The system is designed for non-technical end users in Africa who may be on shared or low-bandwidth connections; the platform assumes users can open a browser but cannot be expected to interpret raw WHOIS records, DNS traces, or scanner dashboards. The paper also assumes that external reputation feeds and community reports can be queried during verification, but it explicitly plans for those calls to fail and uses zero-vector fallbacks so the service remains available under partial information.
The data source is production telemetry from the deployed GuardSec service. The paper says the platform has accumulated N = 5,520 logged interactions since public launch, spanning African source IPs and including verified Googlebot traffic, user verification queries across all supported modalities, and community-submitted reports. For evaluation, the authors create a labeled subset Neval = 312 consisting of URL and domain queries selected by stratified sampling across threat-prevalence strata; these were submitted to VirusTotal’s 70+ scanner aggregate as a reference oracle. Two independent annotators with professional cybersecurity backgrounds resolved disagreements, yielding Cohen’s κ = 0.87. The paper states that the complete annotation protocol is in internal records, so the public description is incomplete. For the connection-audit subsystem, the same production interaction corpus is used to build a longitudinal “Visiteur” dataset with 32 attributes per interaction, including IP address, geolocation, ISP/ASN, connection type, device/browser details, and the security indicators computed by Mon Empreinte.
Architecturally, GuardSec is a Django (Python 3.10) web application using the MVT pattern, hosted on PythonAnywhere with PostgreSQL 13. The system is split into a presentation layer, an application layer, a data layer, and an external-intelligence layer. The application layer exposes service functions such as analyse_url(), verifier_telephone(), verifier_email(), verifier_entreprise(), signaler(), gilda_chat(), and emprunte(). The URL/domain pipeline is the most fully specified: an input entity is normalized and parsed, then five feature subspaces are assembled or queried—lexical features locally, plus WHOIS, SSL certificate inspection, host information, and reputation data via external calls. The external calls are parallelized in the figure description, each with a 1.5 s timeout; failures revert to zero vectors. The final classifier f(x) outputs a score compared against a threshold θ* chosen under an asymmetric cost function with cFN = 3·cFP, explicitly biasing the system toward recall. The business-entity path changes the feature mix: WHOIS and SSL are replaced by name-matching and company-registration features, and reputation/community reports are weighted more heavily. Mon Empreinte is separate from the external verifier: it builds a visitor vector v from request headers, GeoIP, ASN, browser/device parsing, VPN/proxy/Tor detection, DNS leak checks, and twelve binary security indicators, then emits a structured audit report rather than a binary verdict. Gilda is implemented as a Django view that routes user prompts to an LLM inference endpoint with a domain-specific system prompt; the paper says it is constrained to cybersecurity topics and grounded in the platform’s live threat intelligence, but it does not specify the underlying model, decoding settings, retrieval mechanism, or safety filter details.
The evaluation protocol focuses on held-out detection performance on the labeled subset, not on adversarial robustness or longitudinal generalization. Metrics are precision, recall, F1, and AUC-ROC, with recall treated as an operational priority because false negatives are assigned triple the cost of false positives. Table III reports per-entity performance: URL precision/recall/F1/AUC of 0.891/0.923/0.907/0.941, email 0.876/0.901/0.888/0.921, phone 0.843/0.887/0.864/0.903, domain 0.912/0.934/0.923/0.958, and business 0.861/0.879/0.870/0.912. The paper also references a latency distribution figure and percentile latency profiles, and states a service objective of ≤5 s end-to-end at P99 on 3G with a 4.5 s pipeline budget, but the extracted text does not provide the actual percentile values. Baseline comparisons are not clearly spelled out in the provided excerpt beyond references to systems like VirusTotal, PhishTank, URLScan.io, and prior academic URL/phishing models; the paper appears to compare itself conceptually more than via a controlled benchmark table. Reproducibility is mixed: the platform is public, but the labeled data are only partially described, the annotation procedure is summarized rather than published in full, and the LLM assistant implementation is underspecified.
Technical innovations
- A five-type, entity-conditioned verification framework that treats URLs, domains, emails, phone numbers, and business entities as separate but related fraud targets instead of forcing one universal feature set.
- Mon Empreinte, a connection-security audit module that turns the visitor’s own IP, ASN, browser, DNS, VPN/Tor, and fingerprint signals into a user-facing security report rather than a binary fraud verdict.
- An operational pipeline with aggressive timeout management and zero-vector fallback so partial failure of external intelligence sources does not break the service.
- A conversational security assistant (Gilda) embedded into the verification flow to explain verdicts and generate tailored advice for non-technical users.
- An asymmetric decision rule with cFN = 3·cFP, explicitly biasing the system toward recall in a fraud-detection deployment setting.
Datasets
- Production interaction corpus — 5,520 logged interactions — GuardSec production deployment
- Evaluation subset (Neval) — 312 labeled URL/domain entities — stratified sample from production interactions, annotated against VirusTotal 70+ scanners
- Visiteur longitudinal corpus — 5,520 interactions, 32 attributes per interaction — GuardSec production logs
Baselines vs proposed
- No explicit numeric baseline table is provided in the extracted text for classical ML, VirusTotal, PhishTank, or URLScan.io.
- URL detection on Neval: precision = 0.891, recall = 0.923, F1 = 0.907, AUC = 0.941
- Email detection on Neval: precision = 0.876, recall = 0.901, F1 = 0.888, AUC = 0.921
- Phone detection on Neval: precision = 0.843, recall = 0.887, F1 = 0.864, AUC = 0.903
- Domain detection on Neval: precision = 0.912, recall = 0.934, F1 = 0.923, AUC = 0.958
- Business detection on Neval: precision = 0.861, recall = 0.879, F1 = 0.870, AUC = 0.912
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.02502.
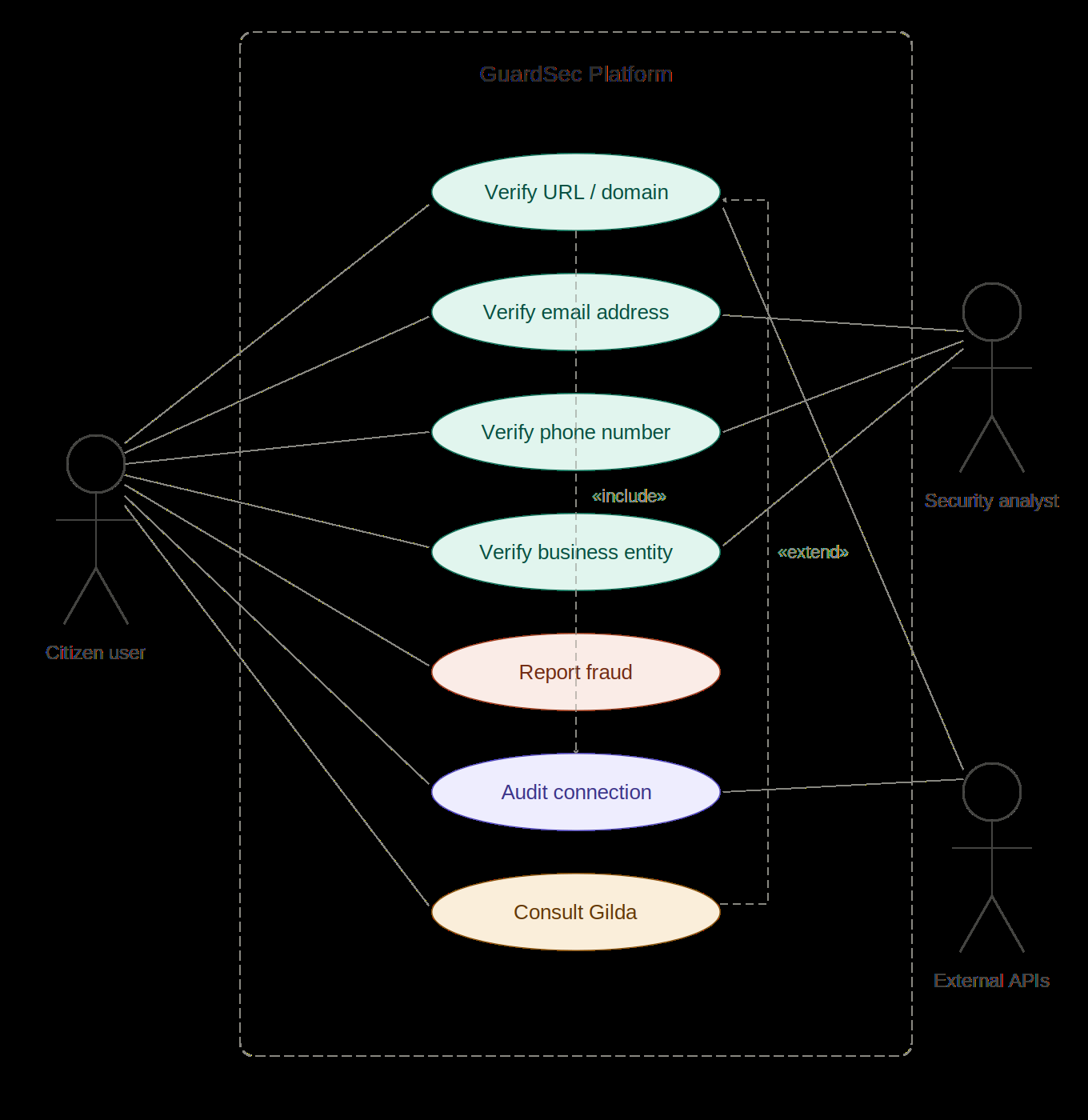
Fig 1: GuardSec use case diagram. Three actor types interact with seven
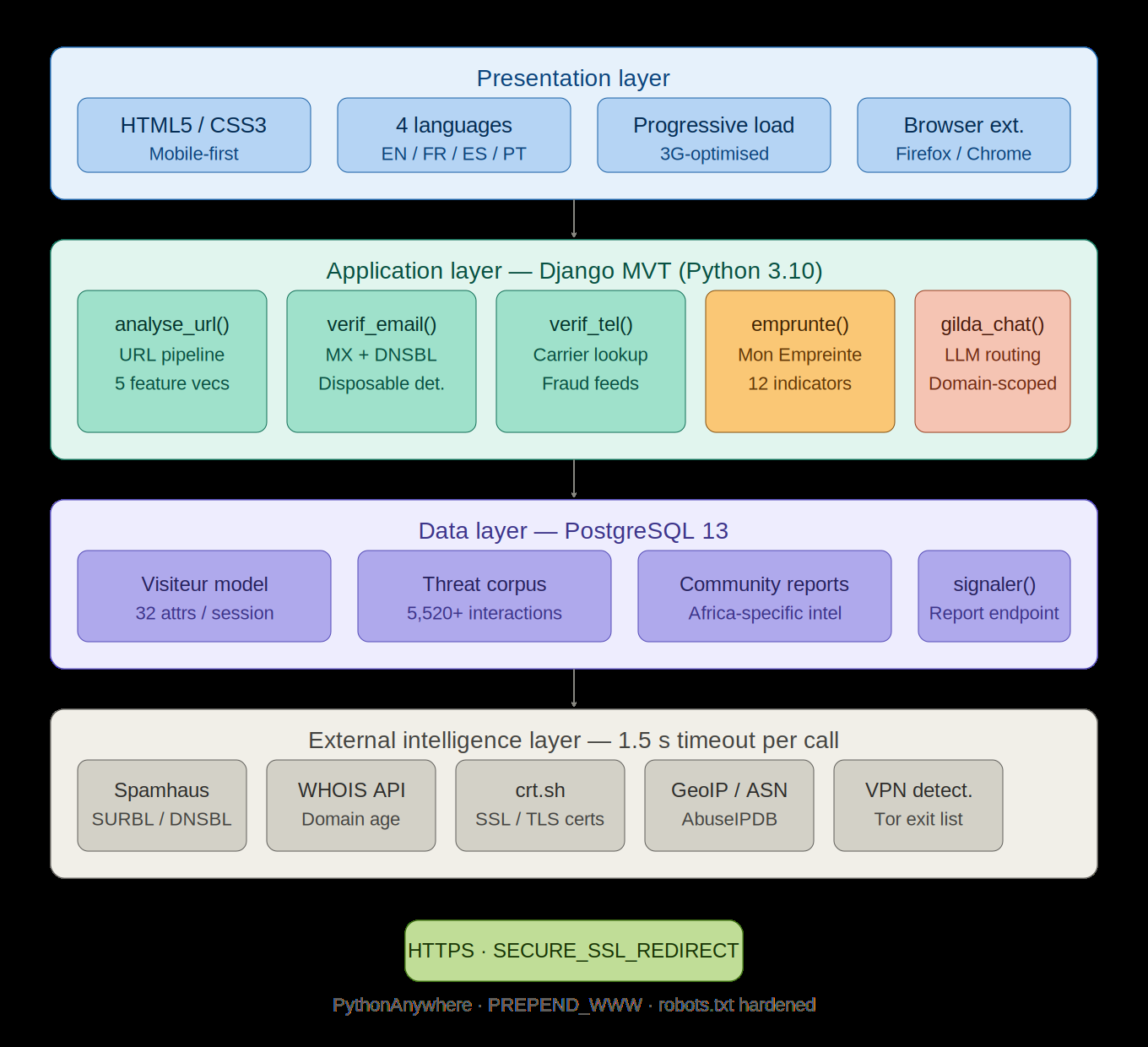
Fig 2: GuardSec four-layer system architecture. The presentation layer serves
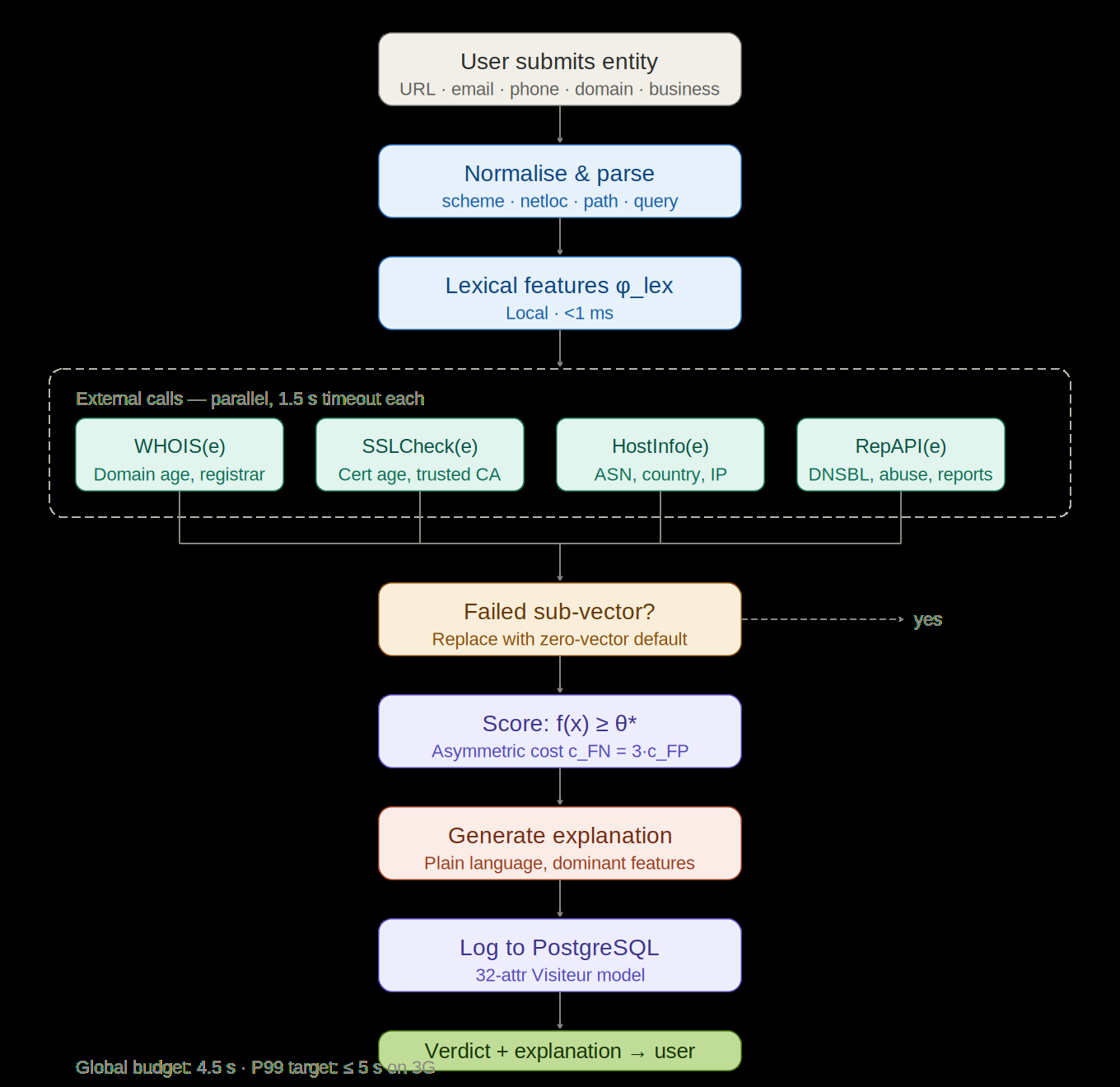
Fig 3: URL/domain threat assessment pipeline. Four external sub-queries
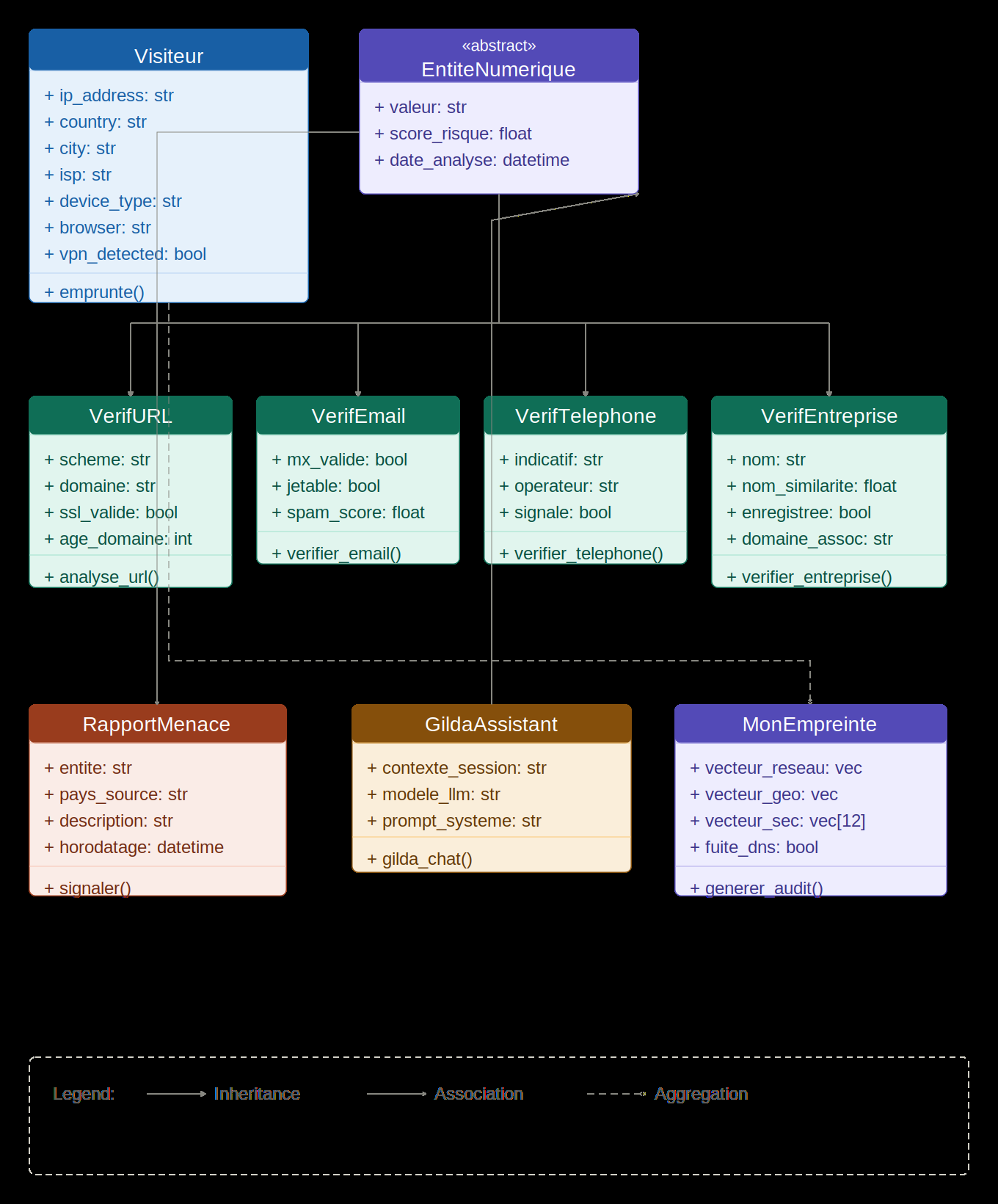
Fig 4: GuardSec UML class diagram. EntiteNumerique is the abstract base class for the five verification subtypes. Visiteur aggregates
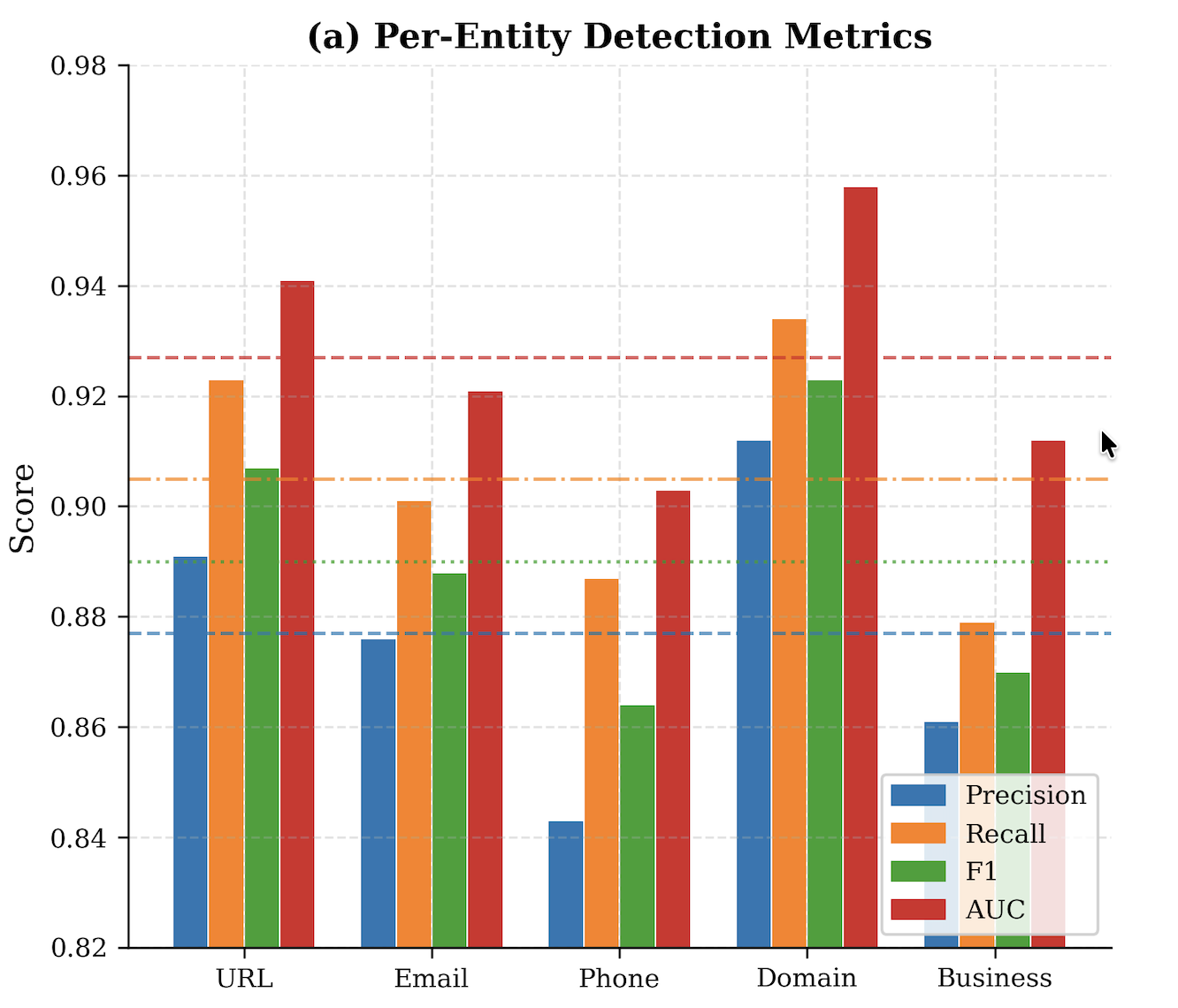
Fig 5: Per Entity Detection Metrics
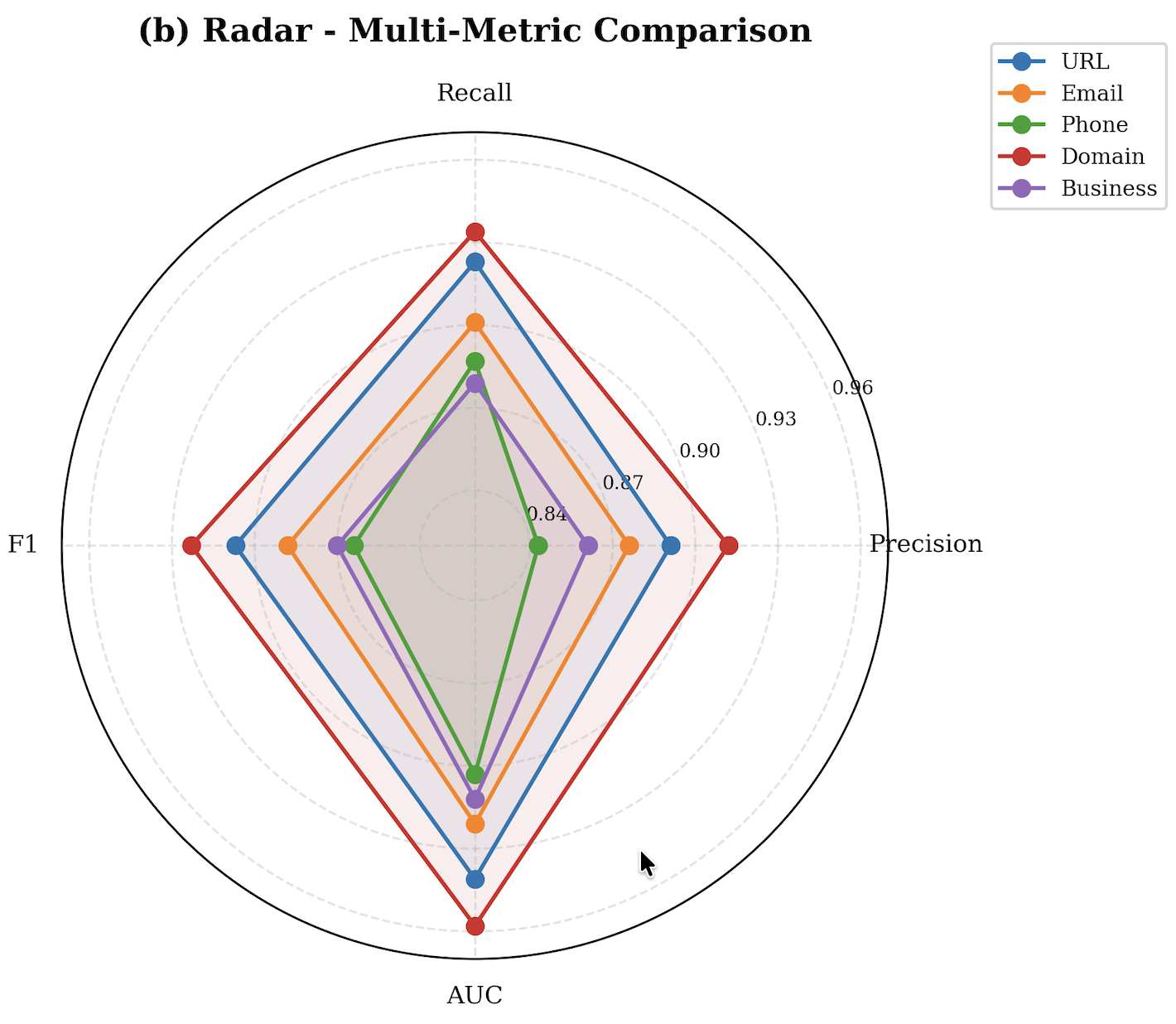
Fig 6: Radar Multimetrics Comparison
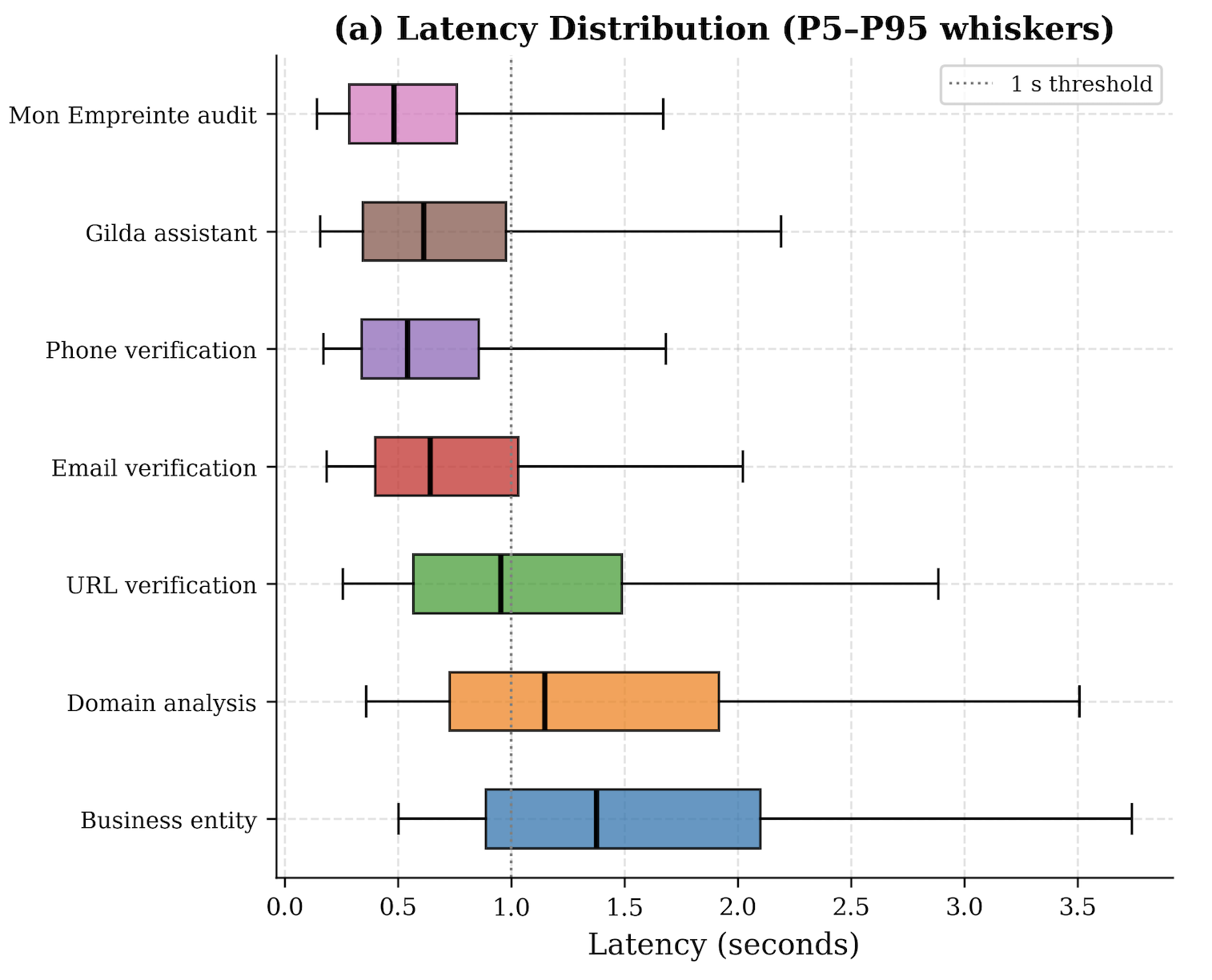
Fig 7: Latency Distribution
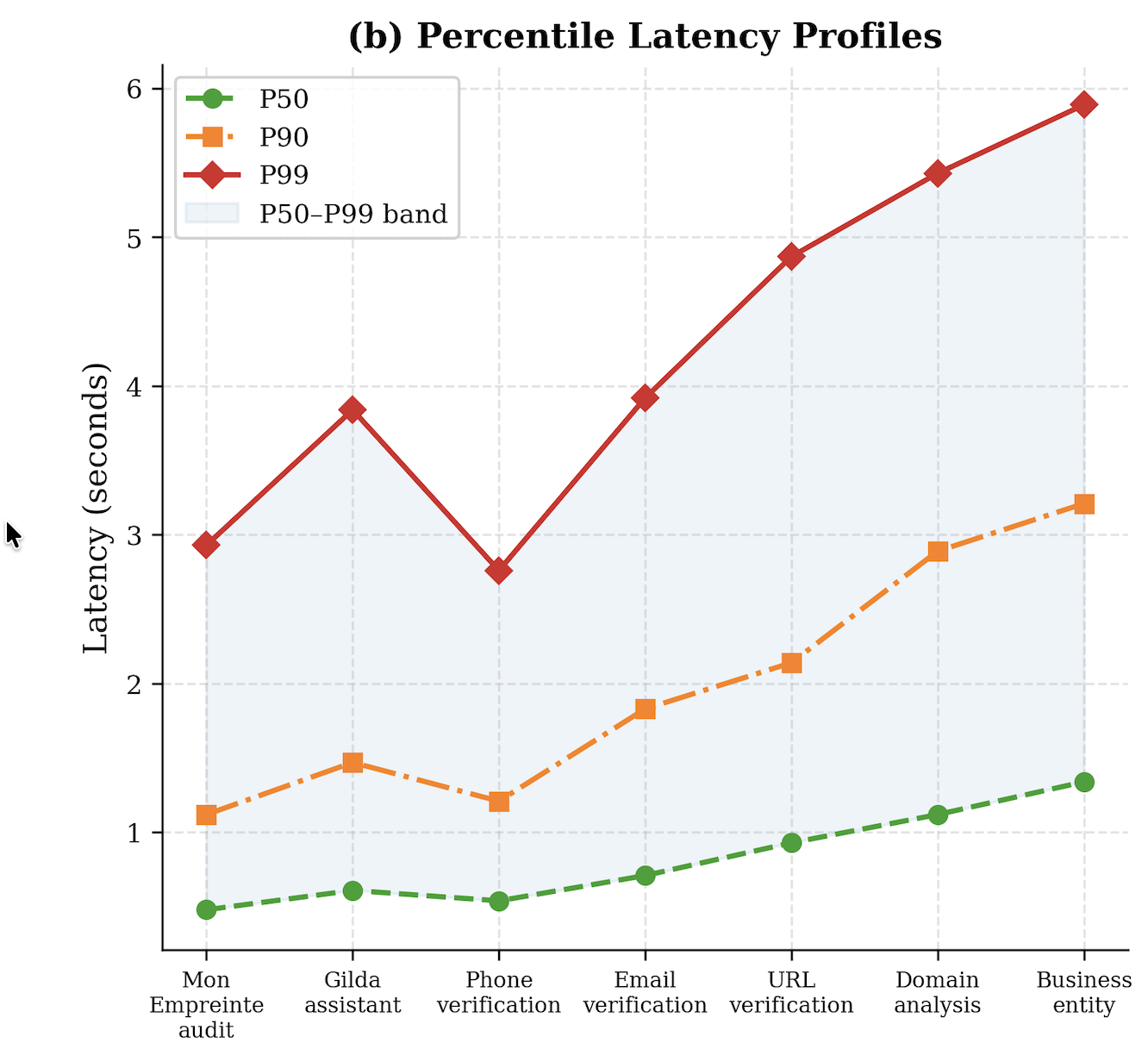
Fig 8: Percentile Latency Profiles
Limitations
- The labeled evaluation set is very small (Neval = 312), so confidence intervals and variance under resampling are important but not reported in the excerpt.
- The evaluation appears to rely on a VirusTotal aggregate oracle plus two annotators; that is useful, but it is not a ground-truth gold standard and may inherit scanner biases.
- The paper does not provide a clean, explicit baseline comparison against prior methods in the extracted results section, making it hard to quantify the gain over existing approaches.
- Gilda’s underlying model, prompts, retrieval strategy, and safety controls are not specified in enough detail to reproduce or audit the assistant.
- The performance numbers are reported on production-derived data, but the excerpt does not show adversarial testing, temporal drift tests, or cross-region generalization within Africa.
- Mon Empreinte reports potentially sensitive connection and device attributes; the excerpt does not discuss privacy safeguards, retention policy, or consent flow in detail.
Open questions / follow-ons
- How stable are the reported metrics under temporal drift, given that fraud tactics and reputation feeds change quickly in production?
- What happens to recall and false positives when external intelligence sources are unavailable, rate-limited, or regionally inconsistent?
- Can Mon Empreinte be validated against ground-truth network traces or controlled leakage experiments rather than only inferred indicators?
- How well does Gilda improve user outcomes versus a static explanation layer, and can that be measured with task success or reduced fraud-loss rates?
Why it matters for bot defense
For a bot-defense or CAPTCHA practitioner, GuardSec is interesting less as a detection benchmark and more as a deployment pattern for low-friction trust signals. The paper’s strongest lesson is that useful fraud defense in consumer settings is often a systems problem: tight latency budgets, graceful degradation, multilingual UX, explainability, and connection-level diagnostics matter as much as the classifier. If you build anti-abuse or challenge flows for African or mobile-first users, the Mon Empreinte idea suggests that a security product can add value by explaining network exposure and misconfiguration, not just judging a single URL or account.
At the same time, GuardSec also highlights a caution: production deployment without strong reproducibility, explicit baselines, and privacy details can make a system hard to trust scientifically even if it is useful operationally. A CAPTCHA or bot-defense team could borrow the architecture—multi-signal fusion, timeouts, partial-failure tolerance, and plain-language contextualization—but would still want stronger experimental controls, drift evaluation, and data governance before treating the approach as validated beyond its own deployment environment.
Cite
@article{arxiv2605_02502,
title={ GuardSec: A Multi-Modal Web Platform for Real-Time Digital Fraud Detection, Entity Verification, and Connection Security Analysis in the African Context },
author={ Gilda Rech Bansimba and Regis Freguin Babindamana },
journal={arXiv preprint arXiv:2605.02502},
year={ 2026 },
url={https://arxiv.org/abs/2605.02502}
}