
cotomi Act: Learning to Automate Work by Watching You
Source: arXiv:2605.03231 · Published 2026-05-04 · By Masafumi Oyamada, Kunihiro Takeoka, Kosuke Akimoto, Ryoma Obara, Masafumi Enomoto, Haochen Zhang et al.
TL;DR
cotomi Act tackles two distinct but complementary deficiencies in current computer-using agents (CUAs): unreliable multi-step web task execution, and complete ignorance of the tacit organizational knowledge that defines how real workplaces operate. The paper comes from NEC Corporation and is positioned as a system demonstration paper for CAIS '26. Rather than treating these as one problem, the authors build two largely independent subsystems—an agent scaffold for execution and a behavior-to-knowledge pipeline for organizational grounding—and connect them through a shared workspace that both the human user and the agent can read and edit.
For execution, the authors engineer a ReAct-style agent scaffold around four mechanisms: adaptive lazy observation (only viewport-visible DOM elements are sent by default, with full accessibility tree on demand), verbal-diff-based history compression (natural-language descriptions of DOM-level changes replace raw past page states), coarse-grained actions (e.g., scrollInto(element) instead of pixel-level scrollBy), and test-time scaling via best-of-N majority-voted action selection and LLM-driven task decomposition into parallel sub-agents. On the 179-task human-evaluation subset of WebArena, this scaffold achieves 80.4% (base scaffold alone: 76.5%), exceeding the reported human baseline of 78.2%. For organizational knowledge, a background browser extension captures site-level actions and periodic screenshots, then an agentic LLM-based ETL pipeline segments, summarizes, and aggregates these events into three artifact types—activity timelines, task boards, and wiki pages—stored in a shared workspace. The agent queries this workspace on demand via a search_workspace tool.
The behavioral-knowledge component is validated on WorkArena-L1, a benchmark of repetitive knowledge-work tasks in enterprise UIs. A controlled study varying domain coverage from 0% to 100% shows task success improves by up to +10 percentage points over a zero-coverage baseline of approximately 51%. Critically, the most effective knowledge format depends on coverage: raw trajectories initially hurt performance at low coverage (−2 pp at 17% coverage) before becoming the strongest format at high coverage, while abstracted scripts and insights remain stable throughout. The paper is explicit that the behavioral-knowledge evaluation uses clean agent trajectories as a proxy for noisy real user behavior, and that full deployment validation remains future work.
Key findings
- cotomi Act achieves 80.4% success rate on the 179-task WebArena human-evaluation subset (base scaffold alone: 76.5%), exceeding the reported human baseline of 78.2% and the prior best agent (OpAgent) at 74.9% on the same subset.
- Adding test-time scaling (best-of-N action selection + task decomposition) to the base scaffold yields a +3.9 percentage-point gain (76.5% → 80.4%) on the 179-task human-evaluation subset.
- Verbal-diff-based current observation yields the largest single ablation improvement: +12.7 pp over the full-accessibility-tree baseline (40.6% → 53.3%) on WebArena-Verified (Gemma-4-31B-IT, 82 tasks, 3 runs per configuration, 39 configurations total), outperforming positional change markers (+7.3 pp).
- Replacing stale full-page observations in the execution history with verbal diffs reduces per-step token cost by 3.8× (23.9K → 6.3K tokens) while maintaining comparable accuracy (+1.1 pp), as shown in Fig 2.
- Adaptive lazy observation (viewport-only elements by default) reduces end-to-end response time from 471 s to 184 s per task (~2.6× faster) on WebArena-Verified with only marginal accuracy trade-off.
- Behavioral knowledge accumulated via the behavior-to-knowledge pipeline improves WorkArena-L1 task success by up to +10 pp over a zero-coverage baseline of ~51%, as shown in Fig 4; in the catalog-ordering domain specifically, success jumps from ~75% to ~99% after 48 procedural scripts become available.
- Raw trajectory knowledge degrades performance at low domain coverage (−2 pp at 17% coverage) before recovering at high coverage, while script and insight formats remain stable across all coverage levels—motivating progressive ETL abstraction.
- An agentic ETL pipeline for behavior abstraction outperforms a fixed-rule pipeline in a blind evaluation by two annotators across 50 browsing sessions (direction of win reported; magnitude not quantified).
Threat model
The paper does not define a formal threat model. Implicitly, the system assumes a fully cooperative, authenticated user who has opted in to behavior logging; no adversarial user, malicious enterprise document, or external attacker is modeled. The agent operates within the user's authenticated browser sessions, meaning its action surface is bounded by the user's own permissions. The behavior logger's PII masking is mentioned but not specified or evaluated. The shared workspace, if writable by the agent, represents an injection surface: a crafted webpage encountered during browsing could potentially produce a maliciously abstracted wiki artifact that influences future agent actions (prompt injection via the ETL pipeline), but this vector is not discussed. In summary, the threat model is n/a as a formal construct, though the system's deployment in enterprise environments implies non-trivial unaddressed attack surfaces around workspace poisoning and behavior logger manipulation.
Methodology — deep read
Threat model and assumptions: This is not a security paper in the traditional sense, but the system implicitly assumes a cooperative, consenting user who opts in to behavior logging. The adversarial surface is not analyzed—there is no discussion of what happens if the observed behavior is malicious, if the workspace artifacts are tampered with, or if an attacker can inject into the behavior logger stream. The agent is assumed to operate in a sandboxed browser environment where its actions are bounded to the user's authenticated sessions.
Data—execution evaluation: The execution scaffold is evaluated on WebArena (812 tasks across five domains: e-commerce, forums, CMS, maps, GitLab). The primary comparison uses a 179-task human-evaluation subset, chosen to match the subset used in the original human performance study. Every automatic WebArena scorer judgment was manually re-verified by three annotators using a custom tool (WebArena Mod, publicly available on GitHub), addressing a known false-positive/false-negative problem in the automatic scorer. The authors also report full-benchmark scores (cotomi Act base: 74.4%, +TTS: 75.7%). All competing baselines except cotomi Act use site-specific UI/navigation hints; cotomi Act uses only answer-format clarifications, making comparisons somewhat favorable to cotomi Act but also arguably more realistic.
Data—behavioral knowledge evaluation: WorkArena-L1 is used, which contains repetitive knowledge-work tasks across six categories (e.g., filtering records, filling forms, ordering catalog items). Instead of real user traces, the authors collect successful agent trajectories as a controlled proxy. They vary 'domain coverage'—the fraction of the six categories for which behavioral knowledge is available—from 0% (no knowledge) to 100% (all six categories, approximately 277 hints total at full coverage). Each coverage level is averaged over six random category orderings to reduce selection bias. The critical caveat, explicitly acknowledged by the authors, is that real user traces would contain failures, interruptions, and exploratory detours that this clean-trajectory proxy does not model.
Architecture and novel components: The agent scaffold wraps a reasoning LLM (not named in the full text for the main evaluation, though Gemma-4-31B-IT is used for ablations on WebArena-Verified) in a ReAct loop. Four mechanisms are layered on top: (1) Adaptive lazy observation—the prompt includes only viewport-visible accessibility tree elements by default; the model can invoke a tool to request the full tree, avoiding token bloat on simple pages while retaining capability for complex UIs. (2) Verbal-diff history compression—instead of retaining raw page states from prior steps, the scaffold replaces them with natural-language change descriptions (e.g., 'New element: [42] button Submit') generated by rule-based DOM diffing. These are the same format as the current-observation diffs but applied to history. (3) Coarse-grained actions—the action space is defined at the highest abstraction level that still covers common interactions; the specific example given is scrollInto(element) replacing pixel-level scrollBy(x,y), collapsing multi-step scroll sequences to one step. (4) Test-time scaling—at each ReAct step, N candidate actions are sampled and the majority-voted action is executed (N ≤ 5 in practice); additionally, when the reasoning model emits a structured multi-goal plan, the scaffold spawns parallel sub-agents each with a focused context window.
The behavior logger operates as a browser extension that captures site-level actions, tab transitions, and periodic screenshots. A diff-based compression scheme deduplicates consecutive observations on the same site before storage. An agentic LLM-based ETL pipeline then processes compressed events in three stages: (1) segment raw events into task-level episodes using inactivity timeouts; (2) summarize each segment into a structured record and classify by activity category; (3) aggregate summaries into typed knowledge artifacts—task items, wiki pages, and activity timelines. The agentic variant (LLM decides segmentation, abstraction level, and routing autonomously) was compared against a fixed-rule pipeline via blind annotation over 50 sessions; the agentic variant was preferred on accuracy and coherence, but no quantitative score is reported.
Training regime: No model training is performed or described. The system is entirely inference-time, relying on a pre-trained reasoning LLM for both the agent scaffold and the ETL pipeline. The backbone LLM is not named in the main evaluation results (the ablation uses Gemma-4-31B-IT). Hyperparameters disclosed: N ≤ 5 for best-of-N; no learning rate, batch size, or epoch information is applicable.
Evaluation protocol: For execution, the primary metric is task success rate (SR), manually verified by three annotators. No statistical significance tests are reported. Baselines are SteP (33.5% all tasks), OpenAI Operator (58.1%), CUGA/IBM (61.7%), and OpAgent (71.6% all tasks / 74.9% human subset)—all using site-specific hints. For behavioral knowledge, the metric is change in SR relative to zero-coverage baseline, plotted as a function of domain coverage (Fig 4). Three knowledge formats are compared: trajectory (full trace), script (procedural steps), insight (abstract summary). Ablations for the scaffold design are run on WebArena-Verified (82 tasks, 3 runs, 39 configurations) with Gemma-4-31B-IT, visualized in accuracy–token-cost space (Fig 2). No held-out adversarial evaluation, no distribution shift test, and no cross-user generalization study are performed.
Reproducibility: WebArena Mod (the re-evaluation tool) is publicly available on GitHub. The main backbone LLM and N value for the reported 80.4% are not fully specified in the truncated text. No model weights or behavior-logger code appear to be released. The behavioral-knowledge evaluation dataset (agent trajectories on WorkArena-L1) is not released. The ablation model (Gemma-4-31B-IT) is publicly available, but the 39-configuration sweep is not packaged for reproduction.
Technical innovations
- Verbal-diff-based dual-channel context management: the same natural-language DOM-change description format is used both for the current observation (improving accuracy +12.7 pp) and for compressing stale history (reducing token cost 3.8×), with the two channels partially substituting each other rather than simply stacking.
- Adaptive lazy observation: the agent receives only viewport-visible DOM elements by default and invokes a tool to request the full accessibility tree on demand, reducing end-to-end latency from 471 s to 184 s per task versus always-full-tree observation, unlike prior agents (e.g., SteP, OpAgent) which feed full trees unconditionally.
- Behavior-to-knowledge agentic ETL pipeline: an LLM autonomously decides segmentation boundaries, abstraction level, and artifact routing for raw browsing logs, producing typed wiki/task/timeline artifacts rather than agent-internal memory blobs as in MemGPT or Voyager.
- Shared knowledge workspace as boundary object: knowledge artifacts are simultaneously human-editable task-management interfaces and agent-queryable retrieval targets, enabling bidirectional curation without explicit synchronization—contrasting with prior memory architectures (Agent Workflow Memory, ExpeL) where memory is agent-internal and opaque to users.
- Coverage-sensitive format selection finding: the empirical result that raw trajectories degrade at low coverage (−2 pp at 17%) but dominate at high coverage motivates the progressive abstraction design, which prior work on agent memory did not systematically study.
Datasets
- WebArena — 812 tasks across 5 domains (e-commerce, forums, CMS, maps, GitLab); 179-task human-evaluation subset used for primary comparison — public (web-arena-x/webarena on GitHub)
- WebArena-Verified — 82-task verified subset of WebArena — public (openreview.net/forum?id=94tlGxmqkN)
- WorkArena-L1 — 6 task categories of repetitive enterprise knowledge-work tasks (filtering, form-filling, catalog ordering) — public (arXiv:2403.07718)
Baselines vs proposed
- SteP (site hints): All tasks SR = 33.5%, Human subset SR = 40.8% vs cotomi Act (+TTS, fmt hints): All tasks SR = 75.7%, Human subset SR = 80.4%
- OpenAI Operator (site hints): All tasks SR = 58.1%, Human subset = not reported vs cotomi Act (+TTS, fmt hints): All tasks SR = 75.7%, Human subset SR = 80.4%
- CUGA/IBM (site hints): All tasks SR = 61.7%, Human subset SR = 64.3% vs cotomi Act (+TTS, fmt hints): All tasks SR = 75.7%, Human subset SR = 80.4%
- OpAgent (site hints): All tasks SR = 71.6%, Human subset SR = 74.9% vs cotomi Act (+TTS, fmt hints): All tasks SR = 75.7%, Human subset SR = 80.4%
- Human baseline (no hints): Human subset SR = 78.2% vs cotomi Act (+TTS, fmt hints): Human subset SR = 80.4%
- cotomi Act base scaffold (no TTS, fmt hints): All tasks SR = 74.4%, Human subset SR = 76.5% vs cotomi Act (+TTS): Human subset SR = 80.4% (+3.9 pp)
- WebArena-Verified ablation — full accessibility tree, no diffs (baseline): SR = 40.6% vs verbal-diff current observation: SR = 53.3% (+12.7 pp) on 82 tasks / 3 runs / Gemma-4-31B-IT
- WorkArena-L1 zero-coverage baseline (no behavioral knowledge): SR ≈ 51% vs 100% coverage (all formats, ~277 hints): up to +10 pp improvement (best format at high coverage)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.03231.
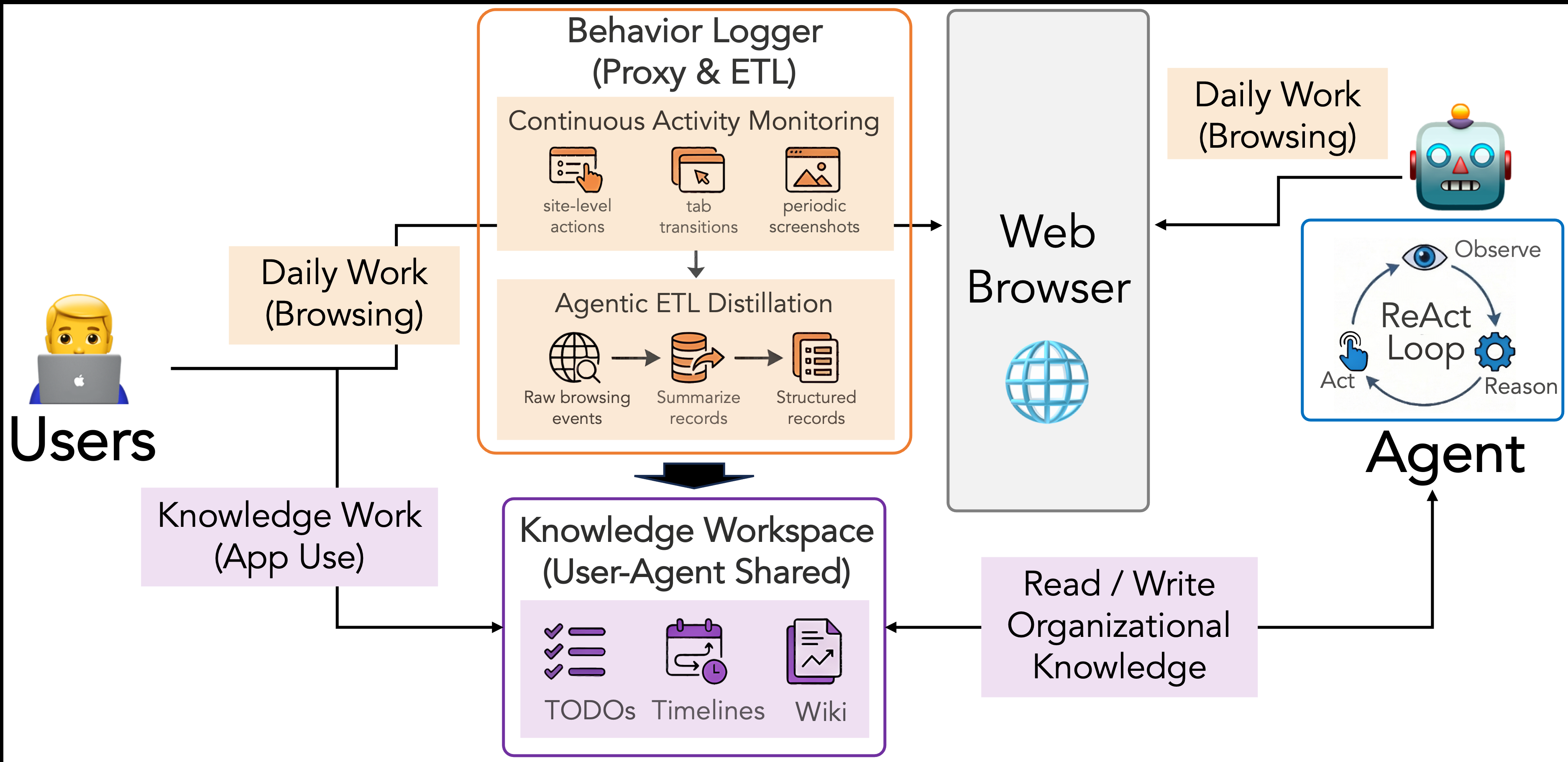
Fig 1: Unlike conventional computer-using agents that
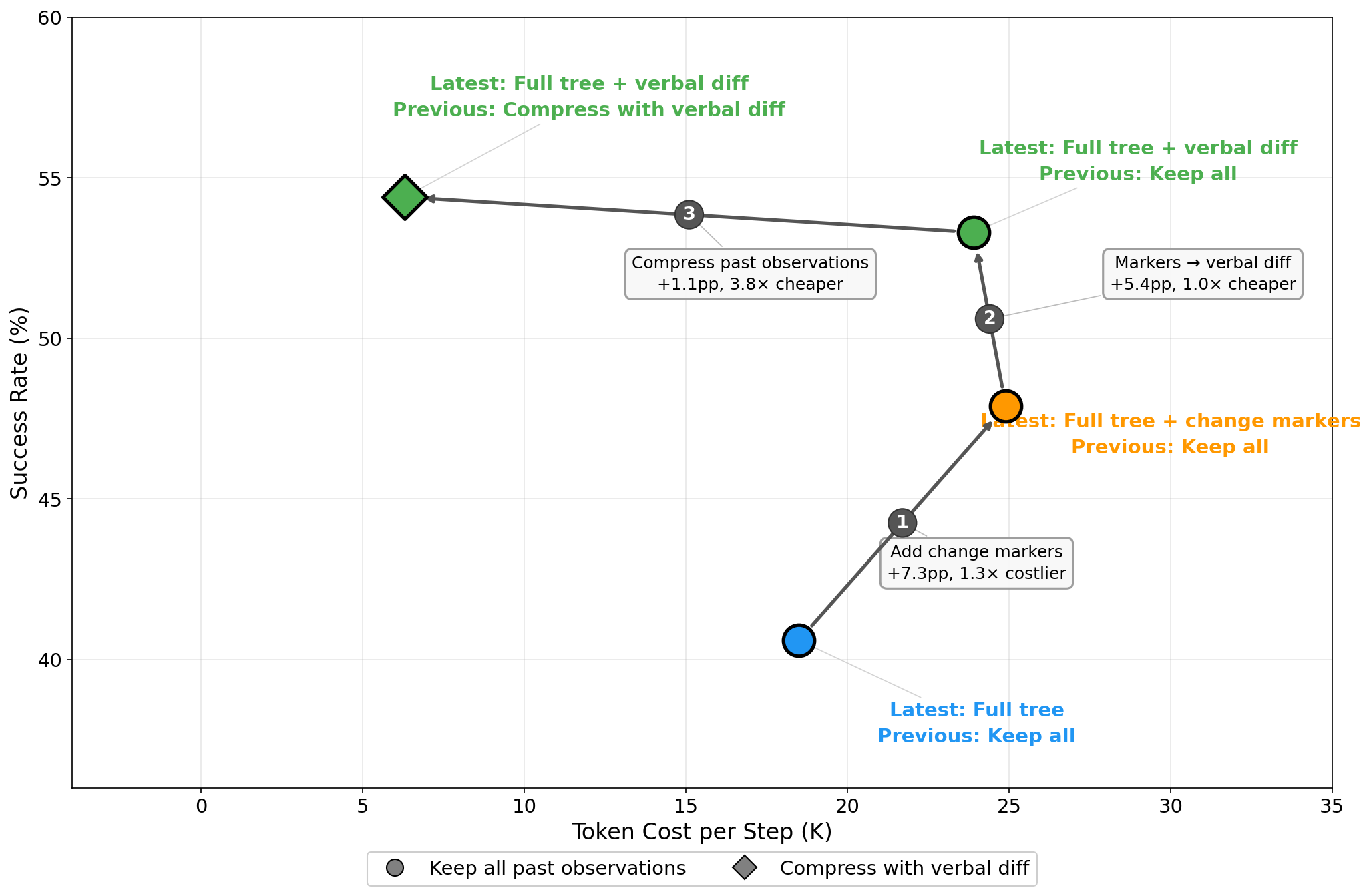
Fig 2: Observation and history design trajectory on
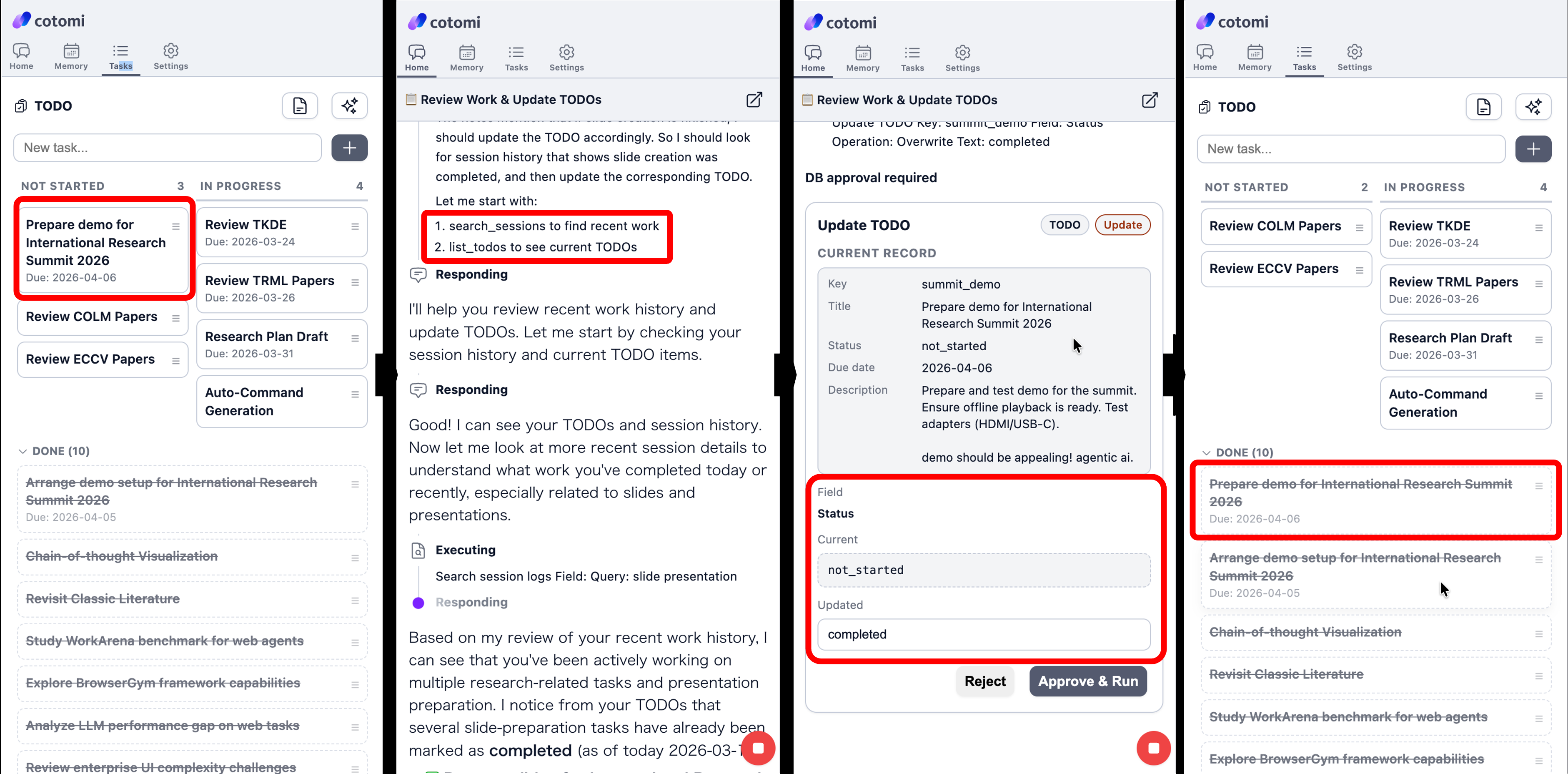
Fig 3: Bidirectional workspace curation in action. The
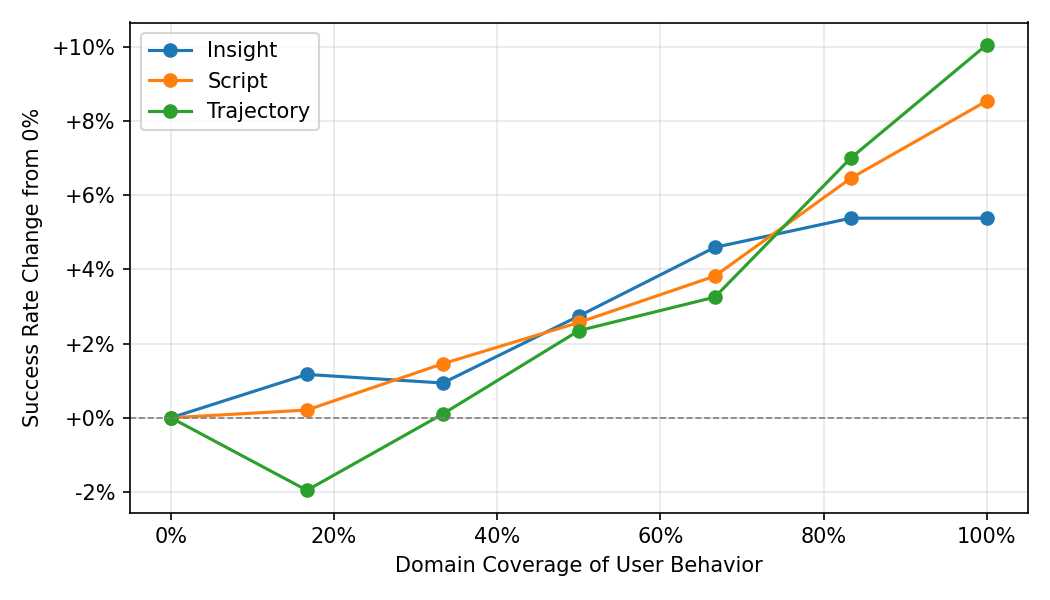
Fig 4: Change in success rate relative to the zero-coverage
Limitations
- Proxy evaluation for behavioral knowledge uses clean, successful agent trajectories rather than real user browsing, which would contain failures, interruptions, and exploratory detours; the pipeline's robustness to such noise is explicitly acknowledged as unvalidated.
- The backbone LLM used for the reported 80.4% result is not named in the available text, making independent reproduction of the headline number difficult; only the ablation model (Gemma-4-31B-IT) is specified.
- No statistical significance testing is reported for any result, including the WebArena human-subset comparison where the margin over the human baseline is only 2.2 pp (80.4% vs 78.2%).
- The behavioral-knowledge evaluation covers only WorkArena-L1's narrow category of repetitive enterprise tasks; generalization to open-ended, less procedural organizational knowledge is not tested.
- No adversarial evaluation of the behavior logger or workspace: a malicious webpage, compromised enterprise document, or prompt-injection in a wiki artifact could plausibly poison the agent's organizational knowledge; this attack surface is not discussed.
- The comparison against other agents is not fully apples-to-apples: cotomi Act uses only format hints while all reported baselines use site-specific UI/navigation hints, which could disadvantage baselines or advantage cotomi Act depending on how much site-specific prompting matters per domain.
- Privacy protections (PII masking, opt-in) are described at a high level with no technical specification of the masking approach, no adversarial audit, and no evaluation of masking recall or precision.
Open questions / follow-ons
- How does the behavior-to-knowledge pipeline perform on real, noisy user browsing logs with failures, restarts, and multi-tasking interleaved across sessions—specifically, does the agentic ETL pipeline hallucinate plausible but incorrect procedural artifacts?
- What is the minimum N for best-of-N action selection before accuracy gains plateau, and can adaptive N selection (e.g., reducing N for high-confidence steps) match fixed N=5 performance at lower inference cost across diverse task distributions?
- Can the shared workspace serve as a prompt-injection attack surface—e.g., if a visited webpage injects text that the ETL pipeline abstracts into a wiki artifact containing adversarial instructions that later redirect agent actions?
- How does cross-user knowledge transfer work in a multi-user organizational deployment: can behavioral knowledge learned from one user's browsing improve task success for a different user with overlapping but non-identical workflows, and does this create privacy leakage between users?
Why it matters for bot defense
From a bot-defense perspective, cotomi Act is a significant data point because it represents a class of agents that are explicitly designed to mimic human browsing behavior—recording real user sessions, learning their navigation patterns, and reproducing them autonomously. The behavior logger captures site-level actions, tab transitions, and periodic screenshots, which is precisely the behavioral signal that many bot-detection systems use to distinguish humans from bots. An agent that has absorbed hundreds of real human browsing sessions and uses those trajectories to guide its own navigation will produce behavioral traces that are structurally much closer to human baselines than a naively scripted bot—including realistic dwell times, navigation paths, and interaction sequences. The 80.4% WebArena success rate, achieved without site-specific hints, suggests the agent can handle complex, dynamic web UIs that would defeat simpler automation tools, raising the floor for what bot-defense must detect.
For CAPTCHA and challenge designers, the coarse-grained action abstraction (e.g., scrollInto over scrollBy) and the best-of-N consensus mechanism mean that behavioral biometrics based on micro-movement patterns or precise scroll trajectories may be less reliable signals, since the agent does not operate at pixel-level granularity. The adaptive lazy observation design also implies the agent does not necessarily request or process the full DOM, which could affect fingerprinting approaches that measure which page elements trigger accessibility-tree queries. More broadly, the behavior-to-knowledge pipeline is a concrete demonstration that organizational knowledge—the kind that makes an agent look like a returning, context-aware human rather than a stateless executor—can be extracted passively from browsing history at scale. Bot-defense practitioners should treat this as evidence that replay-style and context-awareness signals are becoming less reliable human-discriminators, and should invest more heavily in challenge mechanisms that require genuine real-time cognitive novelty rather than pattern reproduction.
Cite
@article{arxiv2605_03231,
title={ cotomi Act: Learning to Automate Work by Watching You },
author={ Masafumi Oyamada and Kunihiro Takeoka and Kosuke Akimoto and Ryoma Obara and Masafumi Enomoto and Haochen Zhang and Daichi Haraguchi and Takuya Tamura },
journal={arXiv preprint arXiv:2605.03231},
year={ 2026 },
url={https://arxiv.org/abs/2605.03231}
}