
Unpaired Image Deraining Using Reward-Guided Self-Reinforcement Strategy
Source: arXiv:2605.00719 · Published 2026-05-01 · By Yinghao Chen, Yeying Jin, Xiang Chen, Yanyan Wei, Ziyang Yan, Yaowen Fu
TL;DR
This paper addresses the challenge of unsupervised single-image deraining, where paired rainy-clean training data is unavailable, making optimization difficult due to under-constrained objectives and diverse rain patterns. The authors propose RGSUD (Reward-Guided Self-Reinforcement Unsupervised Image Deraining), a novel two-stage framework that leverages high-quality intermediate deraining outputs during training as dynamic rewards to guide network optimization. This is achieved through a VLM-based Image Quality Assessment (IQA) mechanism that evaluates synthetic outputs and recycles the best results as supervision signals in subsequent training. The self-reinforcement stage integrates these rewards to refine pseudo-paired data synthesis and introduces a novel self-reinforced loss that constrains the optimization space for improved convergence and alignment with clean images.
Extensive experiments on seven paired synthetic and real-world deraining datasets plus two unpaired real datasets demonstrate that RGSUD consistently outperforms prior unsupervised methods by significant margins (up to 1.37 dB PSNR improvement on Rain100L) and even approaches supervised state-of-the-art methods on certain benchmarks. Ablation studies confirm the efficacy and transferability of the reward recycling and self-reinforcement components. Qualitative results and downstream task evaluations also show superior rain removal and detail preservation. Overall, this work introduces a practical paradigm that exploits implicit supervision signals hidden in intermediate outputs to stabilize and boost unsupervised deraining performance.
Key findings
- RGSUD improves PSNR by 1.37 dB on Rain100L and 0.72 dB on SPA-Data compared to best prior unsupervised method CSUD.
- In no-reference IQA on unpaired datasets (SIRR, Real3000), RGSUD surpasses existing unsupervised baselines with notably lower DACLIP-IQA scores (better perceptual quality).
- Self-Reinforcement (SR) strategy integration improves PSNR by up to 1 dB on multiple datasets (Rain100L, DID-Data, RealRain1K-L).
- SR strategy is transferable: applying it to different supervised derainers (Restormer, DRSformer, NeRD-Rain) yields PSNR gains between 0.42 and 0.78 dB.
- SR strategy also benefits other unsupervised methods (e.g., adds 0.68 dB PSNR gain to CSUD), showing plug-in ability.
- DACLIP-IQA metric outperforms other no-reference IQAs (MUSIC, NIMA, CLIP-IQA) for reward selection, enabling better self-reinforcement.
- Incorporating adversarial loss and reward-augmented degradation estimation improves training stability and final PSNR from 29.45 dB to 34.41 dB on Rain100L.
- RGSUD achieves lower FLOPs (16.3G) and faster inference (0.11s per 256×256 image) than competing methods while delivering SOTA deraining quality.
Threat model
n/a — This work is focused on unsupervised image restoration (deraining) rather than security threats or adversarial capabilities. The 'adversary' concept is not applicable; the technical challenge is learning from unpaired data without ground truth supervision.
Methodology — deep read
The authors propose a two-stage unsupervised deraining framework exploiting intermediate high-quality outputs as self-reinforcement rewards.
(1) Threat model & assumptions: The adversary model is 'n/a' as this is a restoration learning task, but the method assumes access only to unpaired rainy and clean images with no direct paired supervision. The model must learn to separate rain from real-world data whose rain patterns are highly diverse.
(2) Data: They evaluate on multiple publicly available synthetic paired datasets (Rain100L, Rain200L, DID-Data, DDN-Data), real paired datasets (SPA-Data, RealRain1K-L, Night-Rain), and real unpaired datasets (SIRR, Real3000). Training uses unpaired random 256×256 crops. Clean and rainy images are treated as distinct domains with no pairing.
(3) Architecture: RGSUD consists of four main parts: a NAFNet-based Derainer, a U-Net based Degradation Estimation Module (DEM), a ResNet generator G (6 residual blocks), and a PatchGAN discriminator D. The core novelty is the dynamic Reward Recycling Mechanism: VLM-based DACLIP-IQA evaluates derained outputs per rainy image and stores the highest quality output as a reward. During training, pseudo-paired data synthesis is guided by DEM which incorporates these rewards to extract accurate rain degradation maps used to better generate rainy images from clean ones. This forms a positive feedback loop where better rewards enable better pseudo-pairs, leading to improved deraining.
(4) Training regime: The process has two training stages. Stage 1 (Reward Recycling) trains the Derainer on unpaired images and collects high-quality derained images as rewards without backpropagating through them (detached). Stage 2 (Self-Reinforcement) jointly trains the whole network incorporating the dynamic rewards into the gradient flow by adding a self-reinforcement loss that measures distance to rewards and constrains the optimization for sharper, cleaner outputs. Adam optimizer with lr=2e-4, β1=0.9, β2=0.999. Multiple NVIDIA V100 GPUs.
(5) Evaluation protocol: Metrics include PSNR/SSIM for paired synthetic and real sets, and multiple no-reference IQA metrics (CLIP-IQA, MUSIQ, NIMA, Q-Align, DeQA-Score) on unpaired data. Baselines include several recent unsupervised deraining methods (CycleGAN, DerainCycleGAN, NLCL, DCD-GAN, CSUD) and supervised models (Restormer, DRSformer, NeRD-Rain). Ablations explore SR strategy, IQA metric choice, loss weights, DEM incorporation, and training stability. Transition from stage 1 to 2 triggered when validation PSNR/SSIM stabilizes.
(6) Reproducibility: The paper mentions supplementary material with detailed algorithms and structures but does not explicitly confirm open-source code or reproducible scripts. Datasets used are publicly available. Trained weights are not indicated to be released.
Concrete example: Given a rainy image xi, the Derainer outputs xrec_i. The DACLIP-IQA evaluates xrec_i against current reward xr_i. If the new output has higher IQA score, it replaces the stored reward for that sample. These rewards are later used by the DEM module to extract improved rain features for synthesizing pseudo-paired rainy images from clean images, thus improving the deraining network's training guidance through self-reinforced loss, e.g. ||Brw - Br||^2_F, where Brw is reward-clean image, Br is network output. This loop iteratively tightens the optimization space toward better rain removal.
Overall, the method innovatively leverages intermediate best outputs as a form of dynamic implicit supervision via VLM-based image quality evaluation, combined with a degradation estimation module for precise rain modeling, integrated into a two-stage training schedule with adversarial and reconstruction losses to yield stable and superior unsupervised deraining.
Technical innovations
- Introduction of a VLM-based dynamic reward recycling mechanism that selects and updates high-quality derained outputs during training to serve as supervision rewards in unsupervised deraining.
- Design of a self-reinforcement loss that incorporates recycled rewards to constrain optimization, enhancing convergence to a compact solution space aligned with clean image distributions.
- Integration of a Degradation Estimation Module (DEM) that leverages reward-clean feature representations instead of extraction network features for more accurate rain information during pseudo-paired data synthesis.
- Application of DACLIP-IQA, a vision-language-model-based no-reference image quality assessment metric, as a zero-shot reliable reward evaluator guiding model optimization.
Datasets
- Rain100L — ~2000 paired synthetic rainy-clean images — public
- Rain200L — synthetic paired dataset — public
- DID-Data — synthetic paired dataset — public
- DDN-Data — synthetic paired dataset — public
- SPA-Data — real paired rainy-clean dataset — public
- RealRain1K-L — real paired dataset — public
- Night-Rain — real paired nighttime rainy images dataset — public
- SIRR — unpaired real rainy dataset without ground truth — public
- Real3000 — unpaired real rainy dataset without ground truth — public
Baselines vs proposed
- CSUD: PSNR on Rain100L = 33.28 dB vs RGSUD = 34.41 dB (+1.13 dB)
- DCD-GAN: PSNR on Rain100L = 31.82 dB vs RGSUD = 34.41 dB (+2.59 dB)
- DerainCycleGAN: PSNR on Rain100L = 32.31 dB vs RGSUD = 34.41 dB (+2.1 dB)
- NLCL: PSNR on RealRain1K-L = 23.06 dB vs RGSUD = 30.54 dB (+7.48 dB)
- RGSUD outperforms Fr-Diff, TP-Diff, and DehazeSB retrained for deraining task.
- Supervised NeRD-Rain-S on Rain100L: PSNR = 42.00 dB; RGSUD achieves 34.41 dB but outperforms other unsupervised baselines significantly.
- SR strategy adds up to +1.37 dB PSNR gain when integrated to baseline RGSUD alone on Rain100L.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.00719.
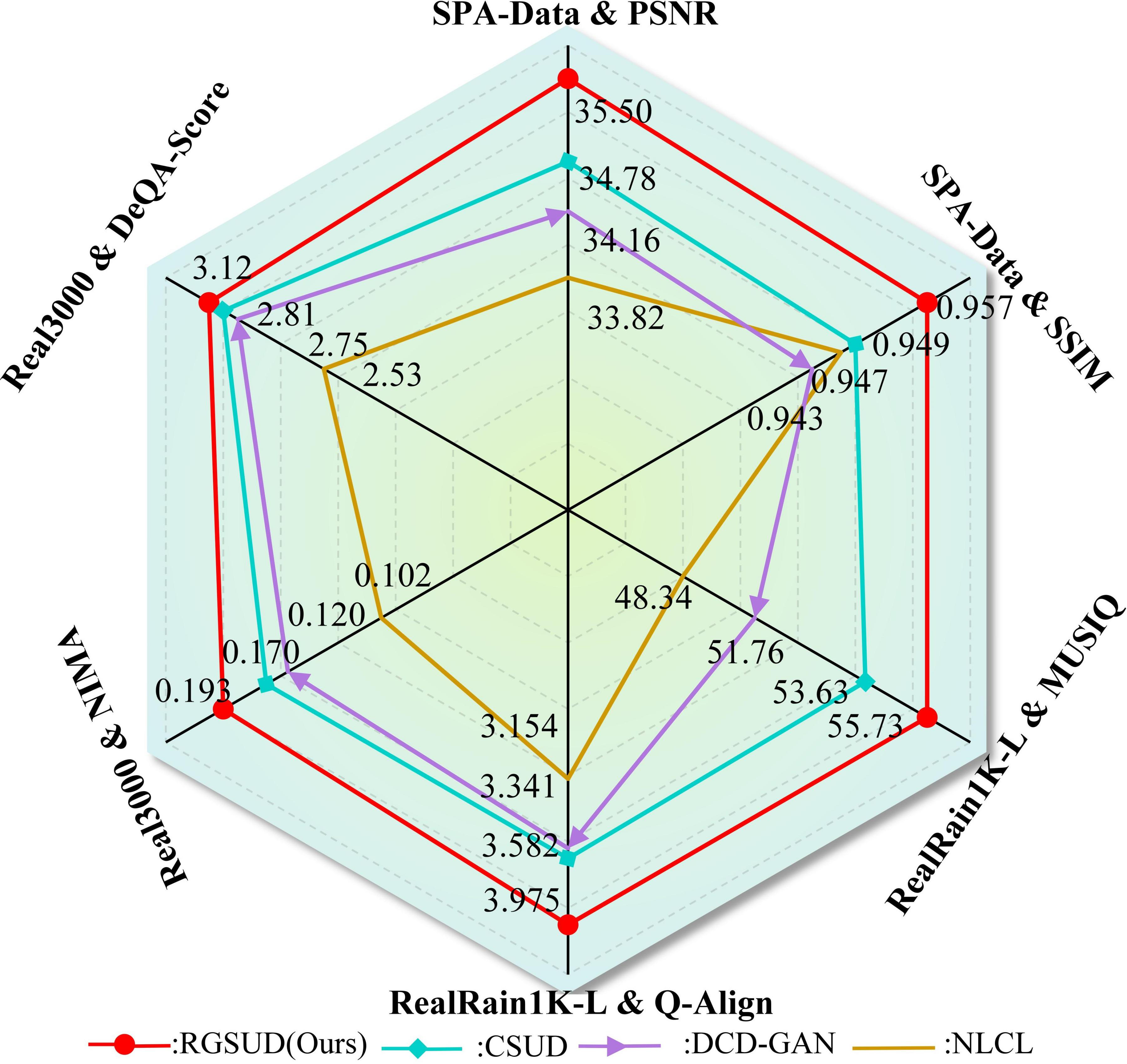
Fig 1: Observation, Motivation, Methodology, and Performance of Our Work. (a) PSNR statistics of deraining results during
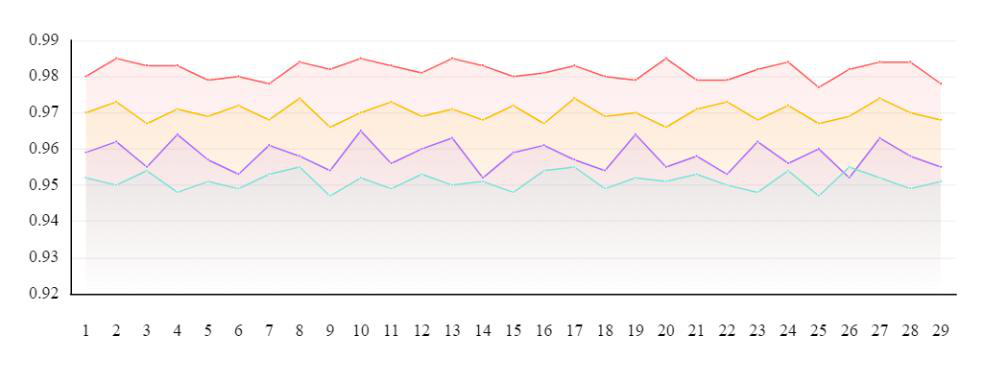
Fig 2 (page 1).
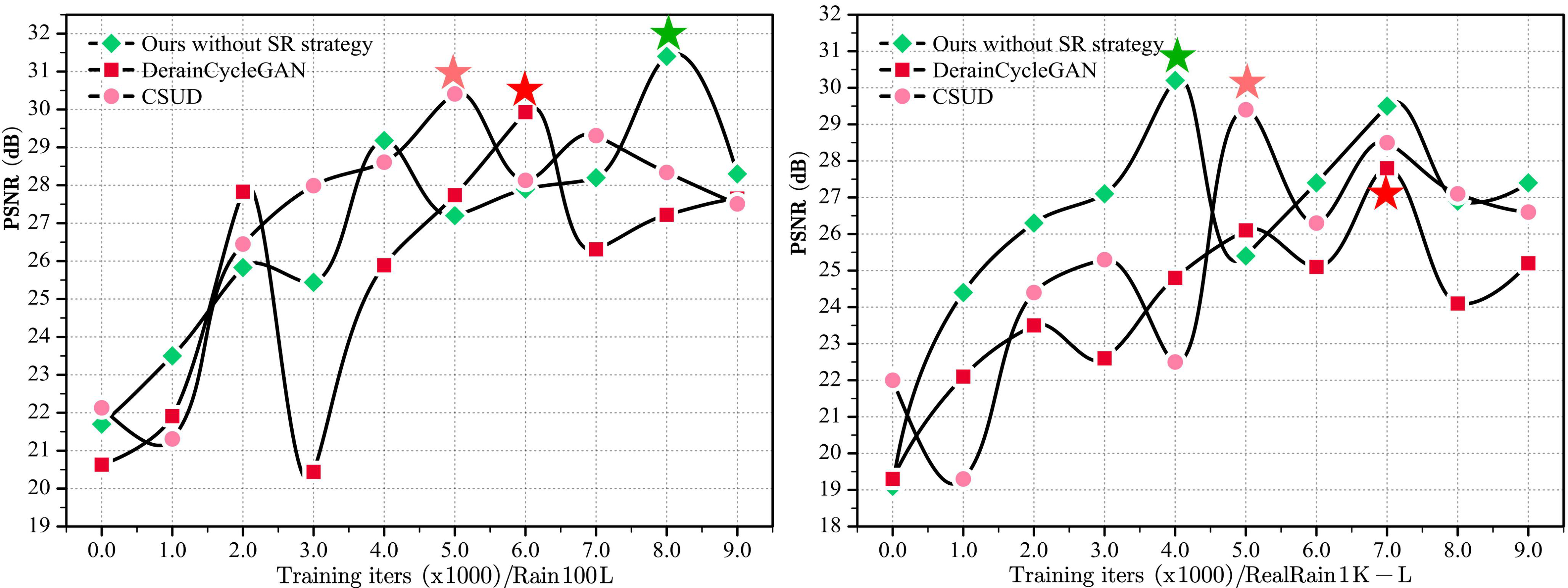
Fig 3 (page 1).
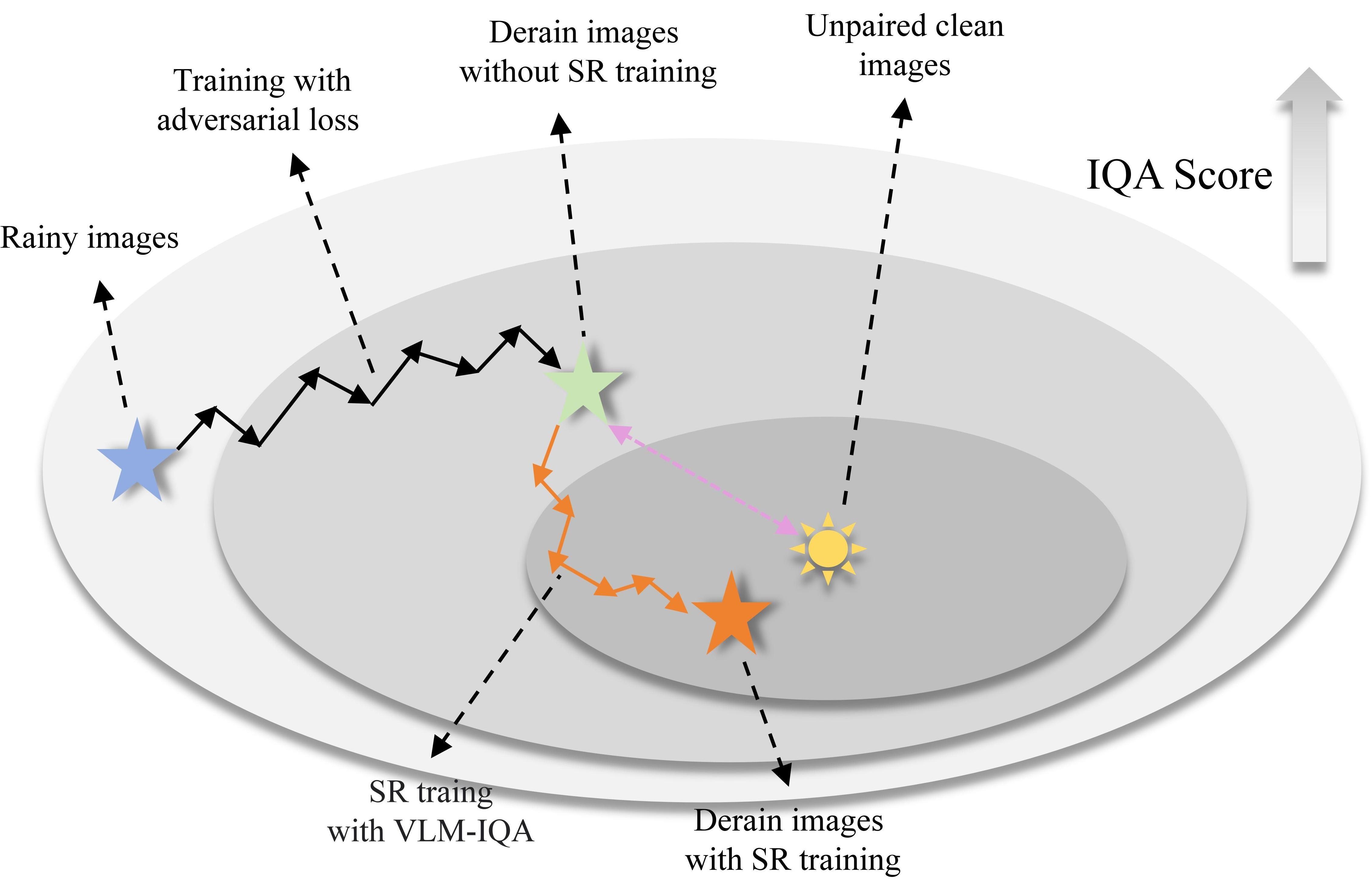
Fig 4 (page 1).
Fig 2: The framework of the proposed RGSUD. (a) Overview of the network architecture, illustrating the Reward Recycling and Self-

Fig 3: Qualitative deraining performance comparisons on Rain200L, DID-Data, and RealRain1K-L datasets. Our RGSUD achieves

Fig 4: Compared with derained results on the SIRR datasets, and Real3000 datasets, RGSUD recovers clearer images. In outdoor

Fig 5: The application performance of derained images in
Limitations
- The method relies on a pretrained VLM-based IQA metric (DACLIP-IQA), which may have biases or limitations unrelated to deraining that affect reward quality.
- Effectiveness depends on the initial generation of sufficiently good derained images; poor initial outputs yield weak rewards compromising later self-reinforcement.
- No explicit adversarial or adaptive adversarial robustness evaluation is provided; resilience to intentional attacks on reward mechanism is untested.
- The framework is empirically validated on static single images only; extension to video or temporal consistency not addressed in this work.
- Transition between stages requires monitoring validation metrics and setting thresholds, implying some hyperparameter tuning or heuristic choice.
- Code release, trained weights, and full reproducibility details are not explicitly provided, so external validation and adoption may be limited.
Open questions / follow-ons
- Can the reward-guided self-reinforcement mechanism be extended and adapted for video deraining, incorporating temporal consistency?
- How robust is the reward recycling mechanism against potential noisy or adversarially corrupted inputs affecting reward quality?
- What benefits or challenges arise from applying this framework to more complex weather degradations such as fog, snow, or mixed weather conditions?
- Would combining the reward recycling with semi-supervised or weakly supervised paired data further improve real-world performance?
Why it matters for bot defense
The RGSUD framework introduces a novel way to improve unsupervised learning of image restoration tasks by dynamically extracting and recycling implicit high-quality signals to guide training. For bot-defense and CAPTCHA engineers, this approach is relevant in contexts where generating clear images from corrupted inputs is important but paired training data is unavailable—such as defending against automated image manipulation attacks or verifying human visual capability under noise.
The use of a zero-shot VLM-based perceptual IQA metric to self-evaluate intermediate outputs offers a practical method to stabilize training without explicit labels. This paradigm can inspire new CAPTCHA robustness methods that adaptively evaluate image transformations or degrade bot-generated images dynamically. Additionally, the idea of self-reinforcement from intermediate trusted outputs could be incorporated into CAPTCHA validation pipelines to iteratively refine challenge difficulties or detect unnatural image patterns.
However, since the proposed technique hinges on large pretrained models and complex feedback loops, integration would require attention to computational cost and latency. Overall, the paper exemplifies how leveraging implicit semantic quality measures and self-supervised feedback loops can enhance visual tasks under unpaired data constraints, a concept potentially transferrable to CAPTCHA design and bot-detection systems aiming for robust image-based challenges.
Cite
@article{arxiv2605_00719,
title={ Unpaired Image Deraining Using Reward-Guided Self-Reinforcement Strategy },
author={ Yinghao Chen and Yeying Jin and Xiang Chen and Yanyan Wei and Ziyang Yan and Yaowen Fu },
journal={arXiv preprint arXiv:2605.00719},
year={ 2026 },
url={https://arxiv.org/abs/2605.00719}
}